 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema-Guided Culture-Aware Complex Event Simulation with Multi-Agent Role-Play
Oct 24, 2024



Complex news events, such as natural disasters and socio-political conflicts, require swift responses from the government and society. Relying on historical events to project the future is insufficient as such events are sparse and do not cover all possible conditions and nuanced situations. Simulation of these complex events can help better prepare and reduce the negative impact. We develop a controllable complex news event simulator guided by both the event schema representing domain knowledge about the scenario and user-provided assumptions representing case-specific conditions. As event dynamics depend on the fine-grained social and cultural context, we further introduce a geo-diverse commonsense and cultural norm-aware knowledge enhancement component. To enhance the coherence of the simulation, apart from the global timeline of events, we take an agent-based approach to simulate the individual character states, plans, and actions. By incorporating the schema and cultural norms, our generated simulations achieve much higher coherence and appropriateness and are received favorably by participants from a humanitarian assistance organization.
MentalArena: Self-play Training of Language Models for Diagnosis and Treatment of Mental Health Disorders
Oct 09, 2024



Mental health disorders are one of the most serious diseases in the world. Most people with such a disease lack access to adequate care, which highlights the importance of training models for the diagnosis and treatment of mental health disorders. However, in the mental health domain, privacy concerns limit the accessibility of personalized treatment data, making it challenging to build powerful models. In this paper, we introduce MentalArena, a self-play framework to train language models by generating domain-specific personalized data, where we obtain a better model capable of making a personalized diagnosis and treatment (as a therapist) and providing information (as a patient). To accurately model human-like mental health patients, we devise Symptom Encoder, which simulates a real patient from both cognition and behavior perspectives. To address intent bias during patient-therapist interactions, we propose Symptom Decoder to compare diagnosed symptoms with encoded symptoms, and dynamically manage the dialogue between patient and therapist according to the identified deviations. We evaluated MentalArena against 6 benchmarks, including biomedicalQA and mental health tasks, compared to 6 advanced models. Our models, fine-tuned on both GPT-3.5 and Llama-3-8b, significantly outperform their counterparts, including GPT-4o. We hope that our work can inspire future research on personalized care. Code is available in https://github.com/Scarelette/MentalArena/tree/main
Self-Correction is More than Refinement: A Learning Framework for Visual and Language Reasoning Tasks
Oct 05, 2024



While Vision-Language Models (VLMs) have shown remarkable abilities in visual and language reasoning tasks, they invariably generate flawed responses. Self-correction that instructs models to refine their outputs presents a promising solution to this issue. Previous studies have mainly concentrated on Large Language Models (LLMs), while the self-correction abilities of VLMs, particularly concerning both visual and linguistic information, remain largely unexamined. This study investigates the self-correction capabilities of VLMs during both inference and fine-tuning stages. We introduce a Self-Correction Learning (SCL) approach that enables VLMs to learn from their self-generated self-correction data through Direct Preference Optimization (DPO) without relying on external feedback, facilitating self-improvement. Specifically, we collect preferred and disfavored samples based on the correctness of initial and refined responses, which are obtained by two-turn self-correction with VLMs during the inference stage. Experimental results demonstrate that although VLMs struggle to self-correct effectively during iterative inference without additional fine-tuning and external feedback, they can enhance their performance and avoid previous mistakes through preference fine-tuning when their self-generated self-correction data are categorized into preferred and disfavored samples. This study emphasizes that self-correction is not merely a refinement process; rather, it should enhance the reasoning abilities of models through additional training, enabling them to generate high-quality responses directly without further refinement.
GUNet: A Graph Convolutional Network United Diffusion Model for Stable and Diversity Pose Generation
Sep 18, 2024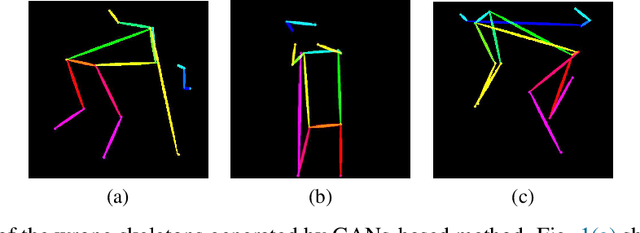
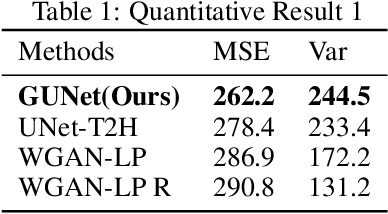


Pose skeleton images are an important reference in pose-controllable image generation. In order to enrich the source of skeleton images, recent works have investigated the generation of pose skeletons based on natural language. These methods are based on GANs. However, it remains challenging to perform diverse, structurally correct and aesthetically pleasing human pose skeleton generation with various textual inputs. To address this problem, we propose a framework with GUNet as the main model, PoseDiffusion. It is the first generative framework based on a diffusion model and also contains a series of variants fine-tuned based on a stable diffusion model. PoseDiffusion demonstrates several desired properties that outperform existing methods. 1) Correct Skeletons. GUNet, a denoising model of PoseDiffusion, is designed to incorporate graphical convolutional neural networks. It is able to learn the spatial relationships of the human skeleton by introducing skeletal information during the training process. 2) Diversity. We decouple the key points of the skeleton and characterise them separately, and use cross-attention to introduce textual conditions. Experimental results show that PoseDiffusion outperforms existing SoTA algorithms in terms of stability and diversity of text-driven pose skeleton generation. Qualitative analyses further demonstrate its superiority for controllable generation in Stable Diffusion.
MLR-Copilot: Autonomous Machine Learning Research based on Large Language Models Agents
Aug 26, 2024



Machine learning research, crucial for technological advancements and innovation, often faces significant challenges due to its inherent complexity, slow pace of experimentation, and the necessity for specialized expertise. Motivated by this, we present a new systematic framework, autonomous Machine Learning Research with large language models (MLR-Copilot), designed to enhance machine learning research productivity through the automatic generation and implementation of research ideas using Large Language Model (LLM) agents. The framework consists of three phases: research idea generation, experiment implementation, and implementation execution. First, existing research papers are used to generate hypotheses and experimental plans vis IdeaAgent powered by LLMs. Next, the implementation generation phase translates these plans into executables with ExperimentAgent. This phase leverages retrieved prototype code and optionally retrieves candidate models and data. Finally, the execution phase, also managed by ExperimentAgent, involves running experiments with mechanisms for human feedback and iterative debugging to enhance the likelihood of achieving executable research outcomes. We evaluate our framework on five machine learning research tasks and the experimental results show the framework's potential to facilitate the research progress and innovations.
$\textit{L+M-24}$: Building a Dataset for Language + Molecules @ ACL 2024
Feb 22, 2024Language-molecule models have emerged as an exciting direction for molecular discovery and understanding. However, training these models is challenging due to the scarcity of molecule-language pair datasets. At this point, datasets have been released which are 1) small and scraped from existing databases, 2) large but noisy and constructed by performing entity linking on the scientific literature, and 3) built by converting property prediction datasets to natural language using templates. In this document, we detail the $\textit{L+M-24}$ dataset, which has been created for the Language + Molecules Workshop shared task at ACL 2024. In particular, $\textit{L+M-24}$ is designed to focus on three key benefits of natural language in molecule design: compositionality, functionality, and abstraction.
Chem-FINESE: Validating Fine-Grained Few-shot Entity Extraction through Text Reconstruction
Jan 25, 2024Fine-grained few-shot entity extraction in the chemical domain faces two unique challenges. First, compared with entity extraction tasks in the general domain, sentences from chemical papers usually contain more entities. Moreover, entity extraction models usually have difficulty extracting entities of long-tailed types. In this paper, we propose Chem-FINESE, a novel sequence-to-sequence (seq2seq) based few-shot entity extraction approach, to address these two challenges. Our Chem-FINESE has two components: a seq2seq entity extractor to extract named entities from the input sentence and a seq2seq self-validation module to reconstruct the original input sentence from extracted entities. Inspired by the fact that a good entity extraction system needs to extract entities faithfully, our new self-validation module leverages entity extraction results to reconstruct the original input sentence. Besides, we design a new contrastive loss to reduce excessive copying during the extraction process. Finally, we release ChemNER+, a new fine-grained chemical entity extraction dataset that is annotated by domain experts with the ChemNER schema. Experiments in few-shot settings with both ChemNER+ and CHEMET datasets show that our newly proposed framework has contributed up to 8.26% and 6.84% absolute F1-score gains respectively.
Name Tagging Under Domain Shift via Metric Learning for Life Sciences
Jan 19, 2024



Name tagging is a key component of Information Extraction (IE), particularly in scientific domains such as biomedicine and chemistry, where large language models (LLMs), e.g., ChatGPT, fall short. We investigate the applicability of transfer learning for enhancing a name tagging model trained in the biomedical domain (the source domain) to be used in the chemical domain (the target domain). A common practice for training such a model in a few-shot learning setting is to pretrain the model on the labeled source data, and then, to finetune it on a hand-full of labeled target examples. In our experiments we observed that such a model is prone to mis-labeling the source entities, which can often appear in the text, as the target entities. To alleviate this problem, we propose a model to transfer the knowledge from the source domain to the target domain, however, at the same time, to project the source entities and target entities into separate regions of the feature space. This diminishes the risk of mis-labeling the source entities as the target entities. Our model consists of two stages: 1) entity grouping in the source domain, which incorporates knowledge from annotated events to establish relations between entities, and 2) entity discrimination in the target domain, which relies on pseudo labeling and contrastive learning to enhance discrimination between the entities in the two domains. We carry out our extensive experiments across three source and three target datasets, and demonstrate that our method outperforms the baselines, in some scenarios by 5\% absolute value.
Learning to Generate Novel Scientific Directions with Contextualized Literature-based Discovery
May 23, 2023



Literature-Based Discovery (LBD) aims to discover new scientific knowledge by mining papers and generating hypotheses. Standard LBD is limited to predicting pairwise relations between discrete concepts (e.g., drug-disease links). LBD also ignores critical contexts like experimental settings (e.g., a specific patient population where a drug is evaluated) and background knowledge and motivations that human scientists consider (e.g., to find a drug candidate without specific side effects). We address these limitations with a novel formulation of contextualized-LBD (C-LBD): generating scientific hypotheses in natural language, while grounding them in a context that controls the hypothesis search space. We present a new modeling framework using retrieval of ``inspirations'' from a heterogeneous network of citations and knowledge graph relations, and create a new dataset derived from papers. In automated and human evaluations, our models improve over baselines, including powerful large language models (LLMs), but also reveal challenges on the road to building machines that generate new scientific knowledge.
Multimedia Generative Script Learning for Task Planning
Aug 25, 2022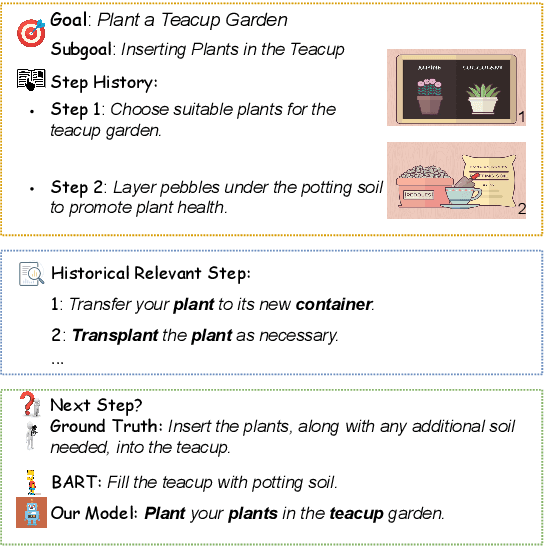
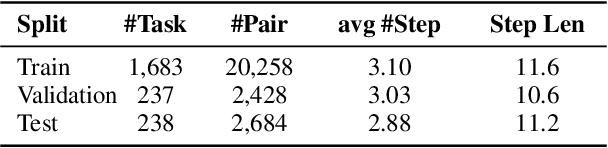
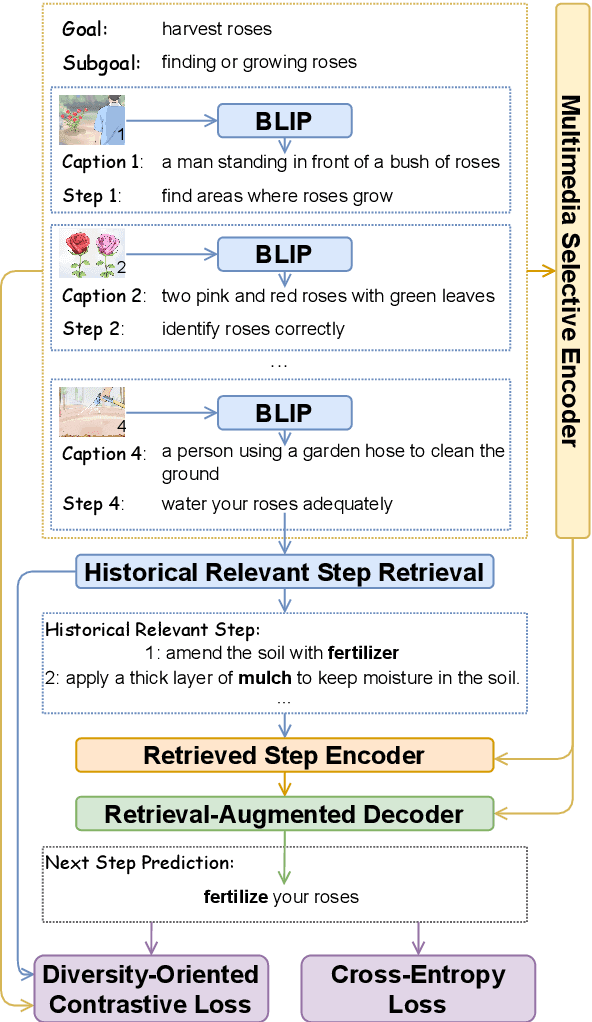
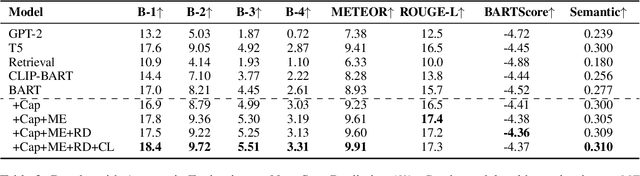
Goal-oriented generative script learning aims to generate subsequent steps based on a goal, which is an essential task to assist robots in performing stereotypical activities of daily life. We show that the performance of this task can be improved if historical states are not just captured by the linguistic instructions given to people, but are augmented with the additional information provided by accompanying images. Therefore, we propose a new task, Multimedia Generative Script Learning, to generate subsequent steps by tracking historical states in both text and vision modalities, as well as presenting the first benchmark containing 2,338 tasks and 31,496 steps with descriptive images. We aim to generate scripts that are visual-state trackable, inductive for unseen tasks, and diverse in their individual steps. We propose to encode visual state changes through a multimedia selective encoder, transferring knowledge from previously observed tasks using a retrieval-augmented decoder, and presenting the distinct information at each step by optimizing a diversity-oriented contrastive learning objective. We define metrics to evaluate both generation quality and inductive quality. Experiment results demonstrate that our approach significantly outperforms strong baselines.