 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Transfer of User Preferences for Cross-domain Recommendation
Oct 22, 2021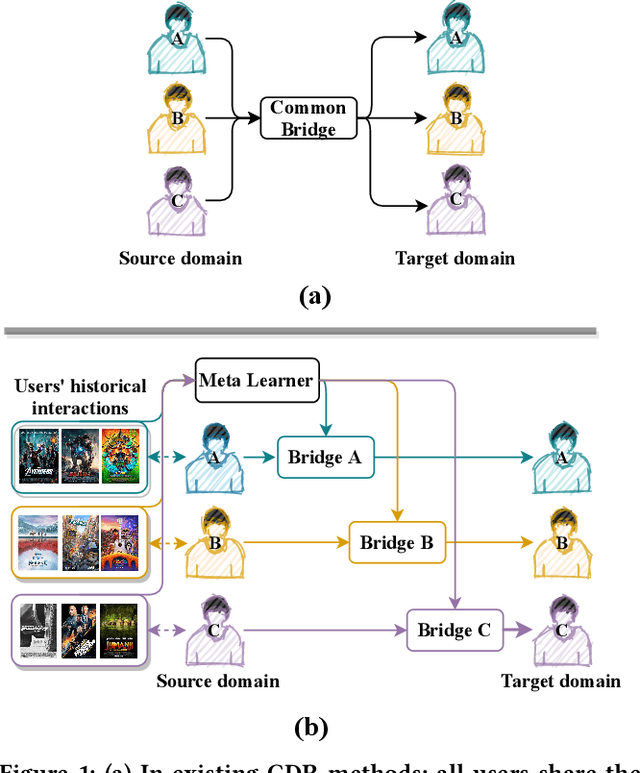

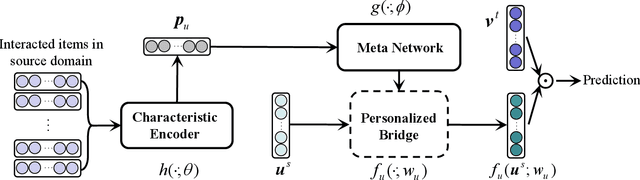
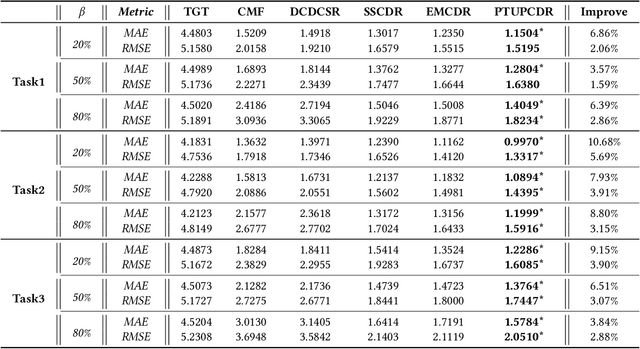
Cold-start problem is still a very challenging problem in recommender systems. Fortunately, the interactions of the cold-start users in the auxiliary source domain can help cold-start recommendations in the target domain. How to transfer user's preferences from the source domain to the target domain, is the key issue in Cross-domain Recommendation (CDR) which is a promising solution to deal with the cold-start problem. Most existing methods model a common preference bridge to transfer preferences for all users. Intuitively, since preferences vary from user to user, the preference bridges of different users should be different. Along this line, we propose a novel framework named Personalized Transfer of User Preferences for Cross-domain Recommendation (PTUPCDR). Specifically, a meta network fed with users' characteristic embeddings is learned to generate personalized bridge functions to achieve personalized transfer of preferences for each user. To learn the meta network stably, we employ a task-oriented optimization procedure. With the meta-generated personalized bridge function, the user's preference embedding in the source domain can be transformed into the target domain, and the transformed user preference embedding can be utilized as the initial embedding for the cold-start user in the target domain. Using large real-world datasets, we conduct extensive experiments to evaluate the effectiveness of PTUPCDR on both cold-start and warm-start stages. The code has been available at \url{https://github.com/easezyc/WSDM2022-PTUPCDR}.
ConRPG: Paraphrase Generation using Contexts as Regularizer
Sep 01, 2021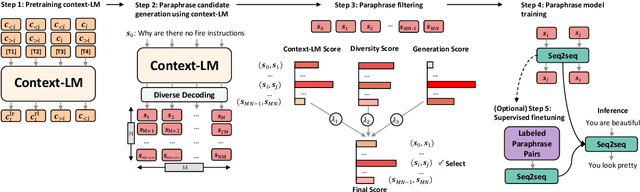
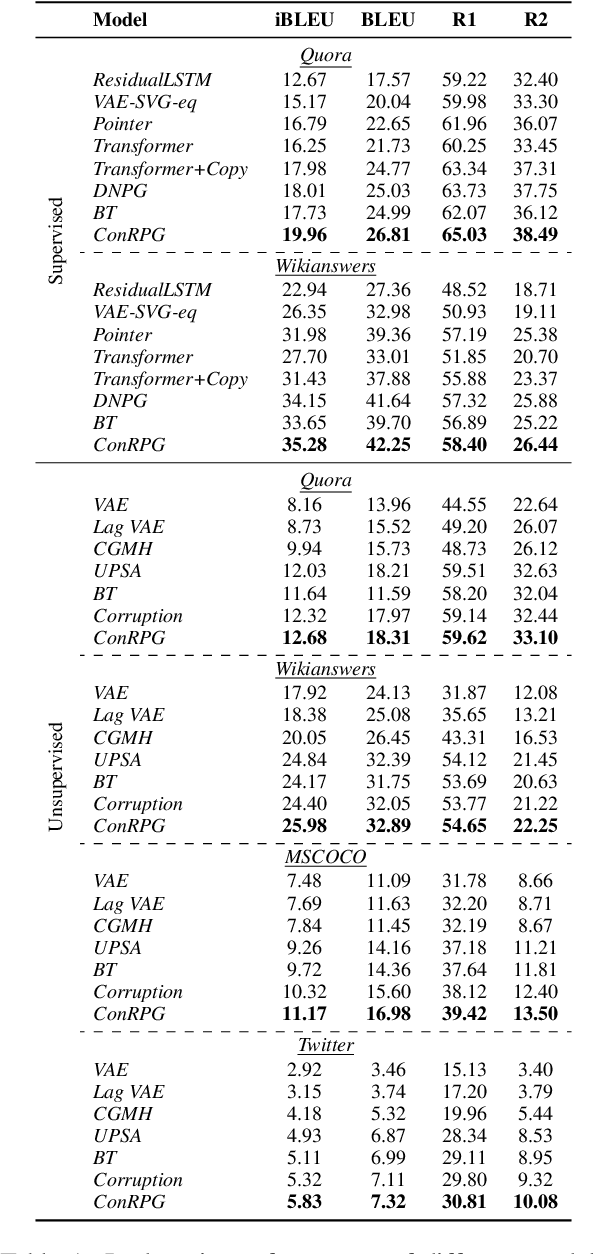
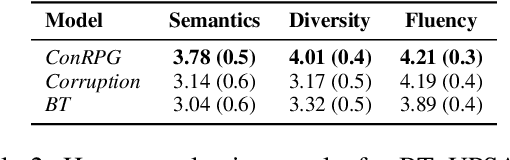
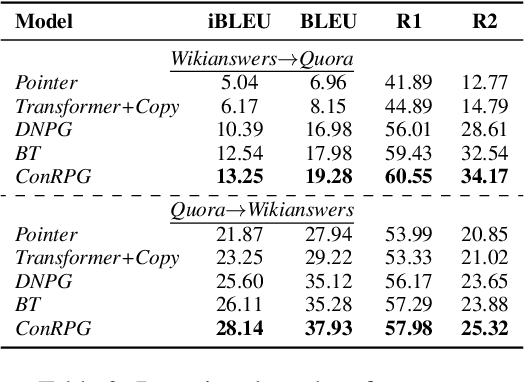
A long-standing issue with paraphrase generation is how to obtain reliable supervision signals. In this paper, we propose an unsupervised paradigm for paraphrase generation based on the assumption that the probabilities of generating two sentences with the same meaning given the same context should be the same. Inspired by this fundamental idea, we propose a pipelined system which consists of paraphrase candidate generation based on contextual language models, candidate filtering using scoring functions, and paraphrase model training based on the selected candidates. The proposed paradigm offers merits over existing paraphrase generation methods: (1) using the context regularizer on meanings, the model is able to generate massive amounts of high-quality paraphrase pairs; and (2) using human-interpretable scoring functions to select paraphrase pairs from candidates, the proposed framework provides a channel for developers to intervene with the data generation process, leading to a more controllable model. Experimental results across different tasks and datasets demonstrate that the effectiveness of the proposed model in both supervised and unsupervised setups.
Follow the Prophet: Accurate Online Conversion Rate Prediction in the Face of Delayed Feedback
Aug 13, 2021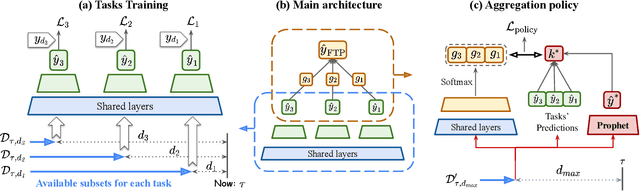
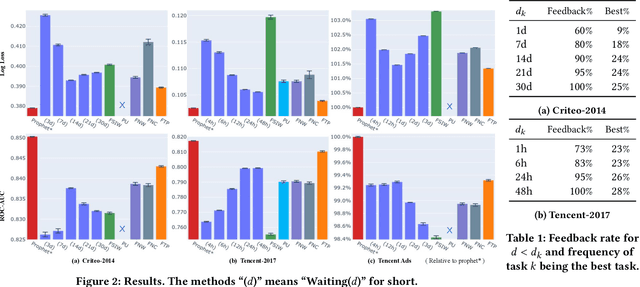
The delayed feedback problem is one of the imperative challenges in online advertising, which is caused by the highly diversified feedback delay of a conversion varying from a few minutes to several days. It is hard to design an appropriate online learning system under these non-identical delay for different types of ads and users. In this paper, we propose to tackle the delayed feedback problem in online advertising by "Following the Prophet" (FTP for short). The key insight is that, if the feedback came instantly for all the logged samples, we could get a model without delayed feedback, namely the "prophet". Although the prophet cannot be obtained during online learning, we show that we could predict the prophet's predictions by an aggregation policy on top of a set of multi-task predictions, where each task captures the feedback patterns of different periods. We propose the objective and optimization approach for the policy, and use the logged data to imitate the prophet. Extensive experiments on three real-world advertising datasets show that our method outperforms the previous state-of-the-art baselines.
GuideBoot: Guided Bootstrap for Deep Contextual Bandits
Jul 18, 2021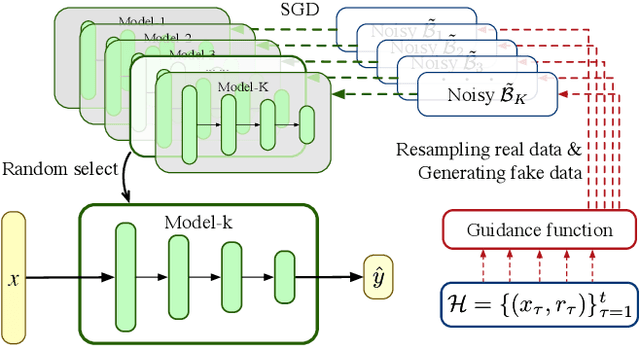
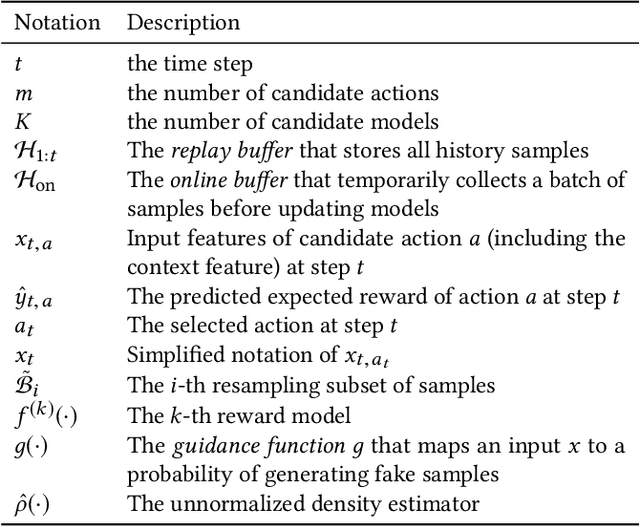
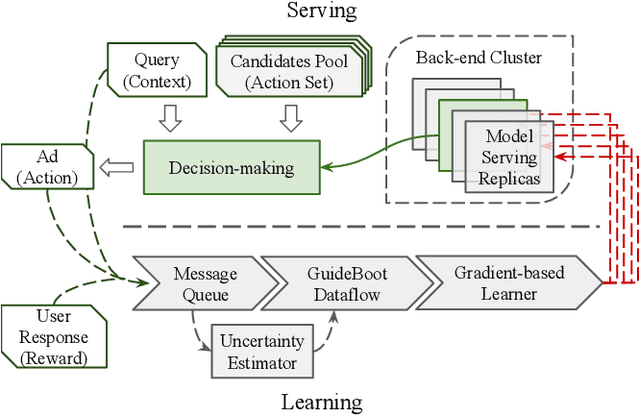
The exploration/exploitation (E&E) dilemma lies at the core of interactive systems such as online advertising, for which contextual bandit algorithms have been proposed. Bayesian approaches provide guided exploration with principled uncertainty estimation, but the applicability is often limited due to over-simplified assumptions. Non-Bayesian bootstrap methods, on the other hand, can apply to complex problems by using deep reward models, but lacks clear guidance to the exploration behavior. It still remains largely unsolved to develop a practical method for complex deep contextual bandits. In this paper, we introduce Guided Bootstrap (GuideBoot for short), combining the best of both worlds. GuideBoot provides explicit guidance to the exploration behavior by training multiple models over both real samples and noisy samples with fake labels, where the noise is added according to the predictive uncertainty. The proposed method is efficient as it can make decisions on-the-fly by utilizing only one randomly chosen model, but is also effective as we show that it can be viewed as a non-Bayesian approximation of Thompson sampling. Moreover, we extend it to an online version that can learn solely from streaming data, which is favored in real applications. Extensive experiments on both synthetic task and large-scale advertising environments show that GuideBoot achieves significant improvements against previous state-of-the-art methods.
Direct speech-to-speech translation with discrete units
Jul 12, 2021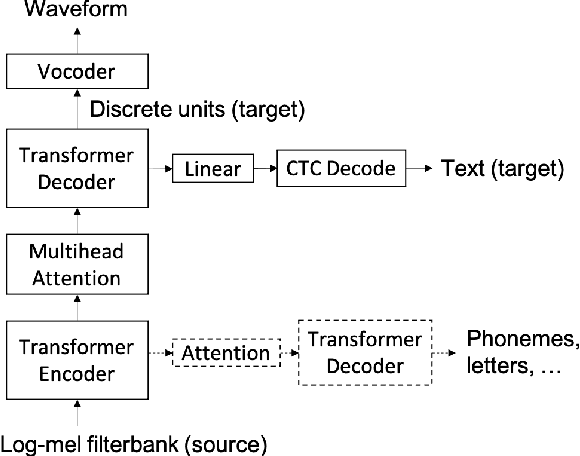
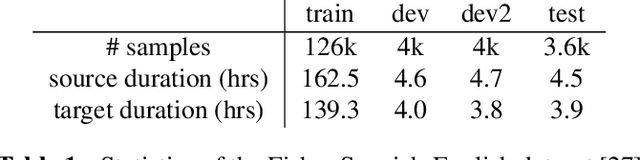
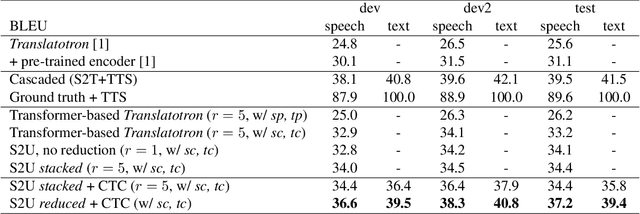
We present a direct speech-to-speech translation (S2ST) model that translates speech from one language to speech in another language without relying on intermediate text generation. Previous work addresses the problem by training an attention-based sequence-to-sequence model that maps source speech spectrograms into target spectrograms. To tackle the challenge of modeling continuous spectrogram features of the target speech, we propose to predict the self-supervised discrete representations learned from an unlabeled speech corpus instead. When target text transcripts are available, we design a multitask learning framework with joint speech and text training that enables the model to generate dual mode output (speech and text) simultaneously in the same inference pass. Experiments on the Fisher Spanish-English dataset show that predicting discrete units and joint speech and text training improve model performance by 11 BLEU compared with a baseline that predicts spectrograms and bridges 83% of the performance gap towards a cascaded system. When trained without any text transcripts, our model achieves similar performance as a baseline that predicts spectrograms and is trained with text data.
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
Jun 30, 2021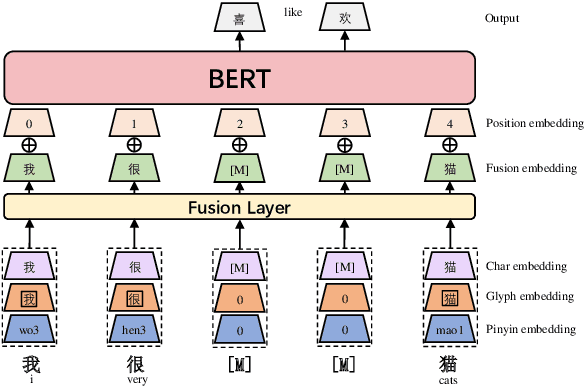

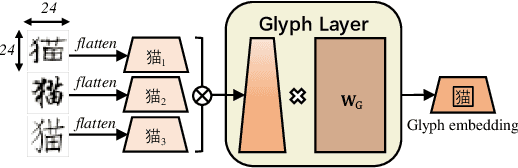
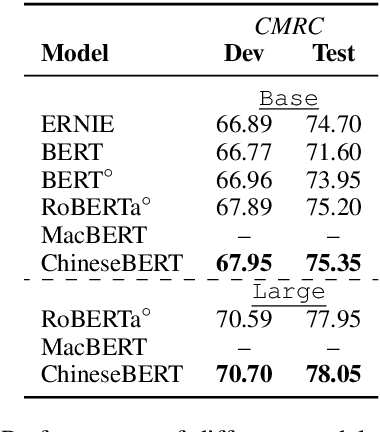
Recent pretraining models in Chinese neglect two important aspects specific to the Chinese language: glyph and pinyin, which carry significant syntax and semantic information for language understanding. In this work, we propose ChineseBERT, which incorporates both the {\it glyph} and {\it pinyin} information of Chinese characters into language model pretraining. The glyph embedding is obtained based on different fonts of a Chinese character, being able to capture character semantics from the visual features, and the pinyin embedding characterizes the pronunciation of Chinese characters, which handles the highly prevalent heteronym phenomenon in Chinese (the same character has different pronunciations with different meanings). Pretrained on large-scale unlabeled Chinese corpus, the proposed ChineseBERT model yields significant performance boost over baseline models with fewer training steps. The porpsoed model achieves new SOTA performances on a wide range of Chinese NLP tasks, including machine reading comprehension, natural language inference, text classification, sentence pair matching, and competitive performances in named entity recognition. Code and pretrained models are publicly available at https://github.com/ShannonAI/ChineseBert.
Deep Subdomain Adaptation Network for Image Classification
Jun 17, 2021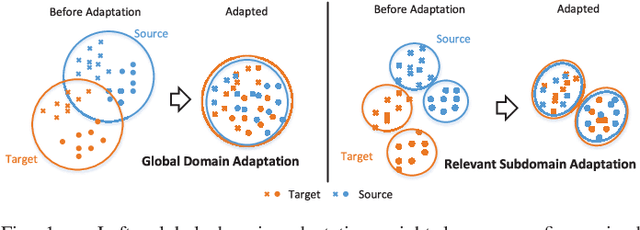
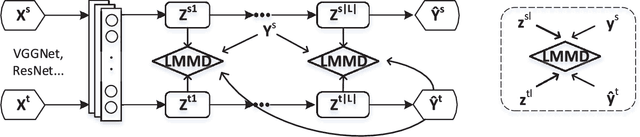
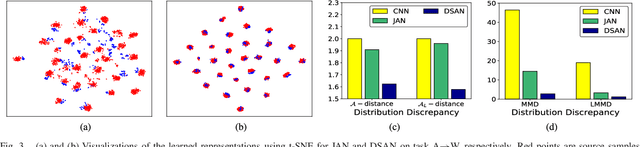
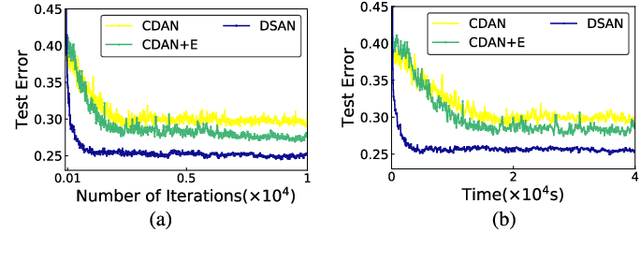
For a target task where labeled data is unavailable, domain adaptation can transfer a learner from a different source domain. Previous deep domain adaptation methods mainly learn a global domain shift, i.e., align the global source and target distributions without considering the relationships between two subdomains within the same category of different domains, leading to unsatisfying transfer learning performance without capturing the fine-grained information. Recently, more and more researchers pay attention to Subdomain Adaptation which focuses on accurately aligning the distributions of the relevant subdomains. However, most of them are adversarial methods which contain several loss functions and converge slowly. Based on this, we present Deep Subdomain Adaptation Network (DSAN) which learns a transfer network by aligning the relevant subdomain distributions of domain-specific layer activations across different domains based on a local maximum mean discrepancy (LMMD). Our DSAN is very simple but effective which does not need adversarial training and converges fast. The adaptation can be achieved easily with most feed-forward network models by extending them with LMMD loss, which can be trained efficiently via back-propagation. Experiments demonstrate that DSAN can achieve remarkable results on both object recognition tasks and digit classification tasks. Our code will be available at: https://github.com/easezyc/deep-transfer-learning
AMA-GCN: Adaptive Multi-layer Aggregation Graph Convolutional Network for Disease Prediction
Jun 16, 2021
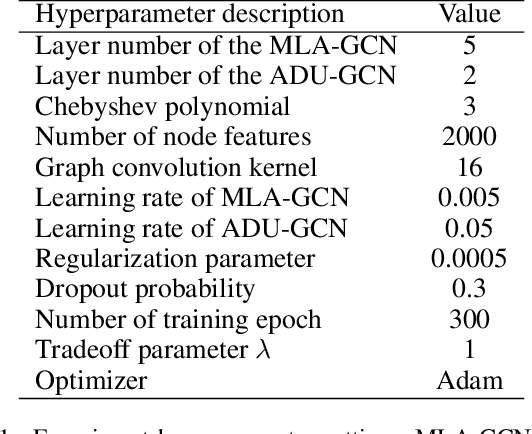
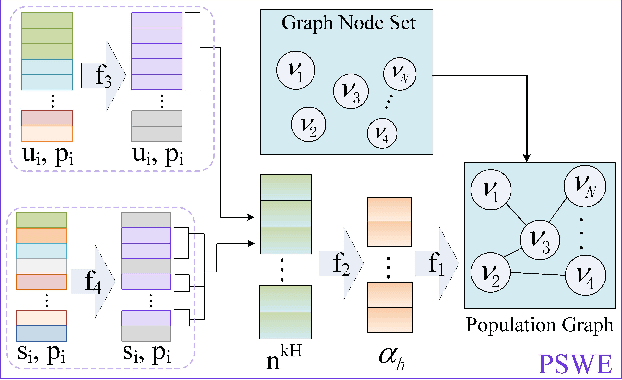
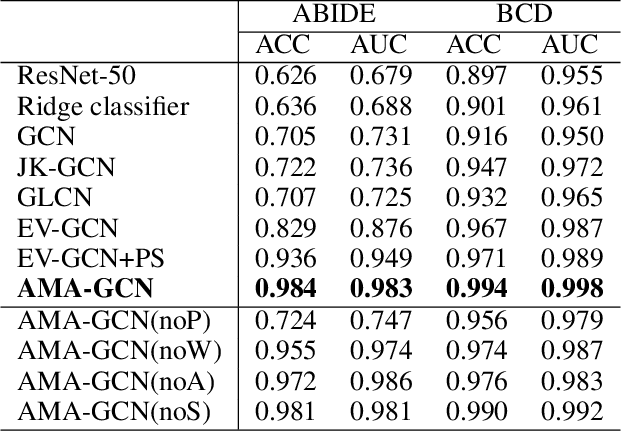
Recently, Graph Convolutional Networks (GCNs) have proven to be a powerful mean for Computer Aided Diagnosis (CADx). This approach requires building a population graph to aggregate structural information, where the graph adjacency matrix represents the relationship between nodes. Until now, this adjacency matrix is usually defined manually based on phenotypic information. In this paper, we propose an encoder that automatically selects the appropriate phenotypic measures according to their spatial distribution, and uses the text similarity awareness mechanism to calculate the edge weights between nodes. The encoder can automatically construct the population graph using phenotypic measures which have a positive impact on the final results, and further realizes the fusion of multimodal information. In addition, a novel graph convolution network architecture using multi-layer aggregation mechanism is proposed. The structure can obtain deep structure information while suppressing over-smooth, and increase the similarity between the same type of nodes. Experimental results on two databases show that our method can significantly improve the diagnostic accuracy for Autism spectrum disorder and breast cancer, indicating its universality in leveraging multimodal data for disease prediction.
Transfer-Meta Framework for Cross-domain Recommendation to Cold-Start Users
May 11, 2021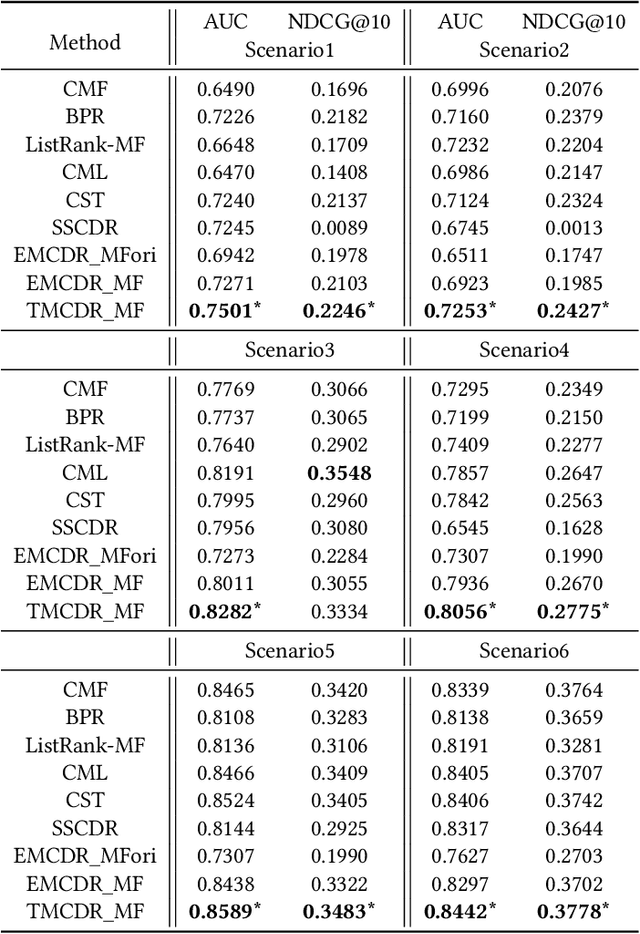
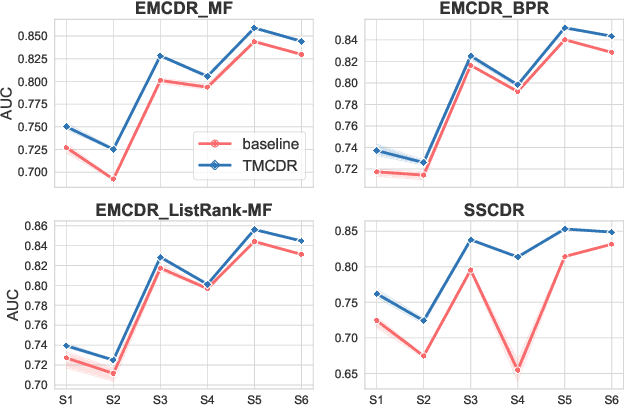
Cold-start problems are enormous challenges in practical recommender systems. One promising solution for this problem is cross-domain recommendation (CDR) which leverages rich information from an auxiliary (source) domain to improve the performance of recommender system in the target domain. In these CDR approaches, the family of Embedding and Mapping methods for CDR (EMCDR) is very effective, which explicitly learn a mapping function from source embeddings to target embeddings with overlapping users. However, these approaches suffer from one serious problem: the mapping function is only learned on limited overlapping users, and the function would be biased to the limited overlapping users, which leads to unsatisfying generalization ability and degrades the performance on cold-start users in the target domain. With the advantage of meta learning which has good generalization ability to novel tasks, we propose a transfer-meta framework for CDR (TMCDR) which has a transfer stage and a meta stage. In the transfer (pre-training) stage, a source model and a target model are trained on source and target domains, respectively. In the meta stage, a task-oriented meta network is learned to implicitly transform the user embedding in the source domain to the target feature space. In addition, the TMCDR is a general framework that can be applied upon various base models, e.g., MF, BPR, CML. By utilizing data from Amazon and Douban, we conduct extensive experiments on 6 cross-domain tasks to demonstrate the superior performance and compatibility of TMCDR.
Multi-rate attention architecture for fast streamable Text-to-speech spectrum modeling
Apr 01, 2021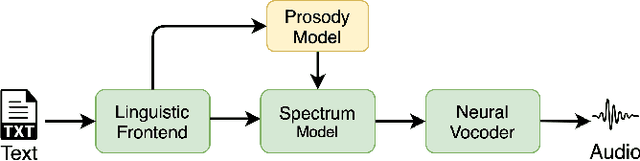
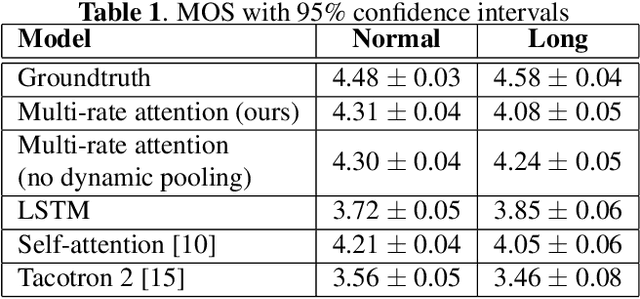
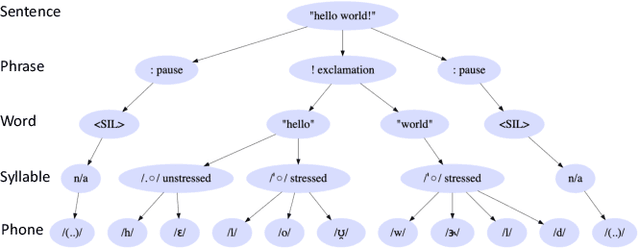
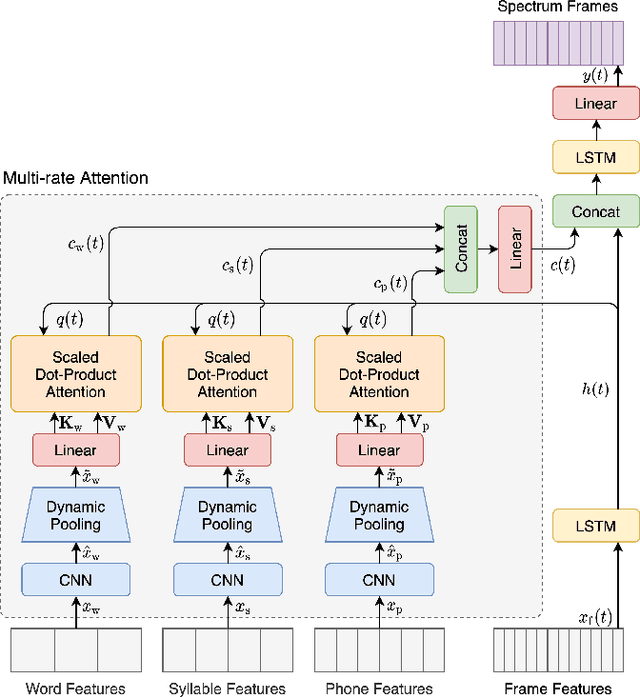
Typical high quality text-to-speech (TTS) systems today use a two-stage architecture, with a spectrum model stage that generates spectral frames and a vocoder stage that generates the actual audio. High-quality spectrum models usually incorporate the encoder-decoder architecture with self-attention or bi-directional long short-term (BLSTM) units. While these models can produce high quality speech, they often incur O($L$) increase in both latency and real-time factor (RTF) with respect to input length $L$. In other words, longer inputs leads to longer delay and slower synthesis speed, limiting its use in real-time applications. In this paper, we propose a multi-rate attention architecture that breaks the latency and RTF bottlenecks by computing a compact representation during encoding and recurrently generating the attention vector in a streaming manner during decoding. The proposed architecture achieves high audio quality (MOS of 4.31 compared to groundtruth 4.48), low latency, and low RTF at the same time. Meanwhile, both latency and RTF of the proposed system stay constant regardless of input lengths, making it ideal for real-time applications.