 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument-Level Tabular Numerical Cross-Checking: A Coarse-to-Fine Approach
Jun 16, 2025Numerical consistency across tables in disclosure documents is critical for ensuring accuracy, maintaining credibility, and avoiding reputational and economic risks. Automated tabular numerical cross-checking presents two significant challenges: (C1) managing the combinatorial explosion of candidate instances at the document level and (C2) comprehending multi-faceted numerical semantics. Previous research typically depends on heuristic-based filtering or simplified context extraction, often struggling to balance performance and efficiency. Recently, large language models (LLMs) have demonstrated remarkable contextual understanding capabilities that helps address C2 at the instance level, yet they remain hampered by computational inefficiency (C1) and limited domain expertise. This paper introduces CoFiTCheck, a novel LLM-based coarse-to-fine framework that addresses these challenges through two sequential stages: embedding-based filtering and discriminative classification. The embedding-based filtering stage introduces an instructional parallel encoding method to efficiently represent all numerical mentions in a table with LLMs, as well as a decoupled InfoNCE objective to mitigate the isolated mention problem. The discriminative classification stage employs a specialized LLM for fine-grained analysis of the remaining candidate pairs. This stage is further enhanced by our crosstable numerical alignment pretraining paradigm, which leverages weak supervision from cross-table numerical equality relationships to enrich task-specific priors without requiring manual annotation. Comprehensive evaluation across three types of real-world disclosure documents demonstrates that CoFiTCheck significantly outperforms previous methods while maintaining practical efficiency.
Domain Adaptation with Category Attention Network for Deep Sentiment Analysis
Dec 31, 2021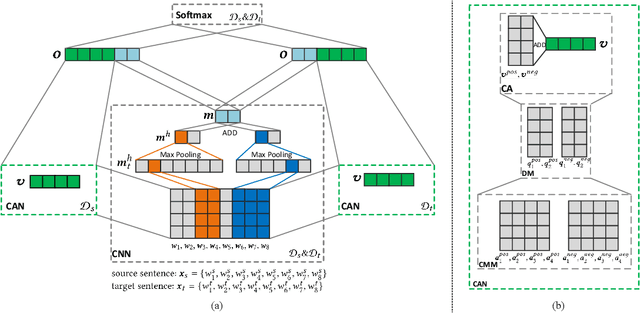
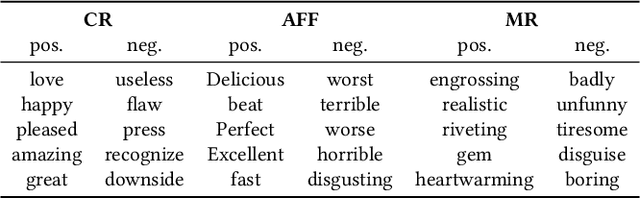
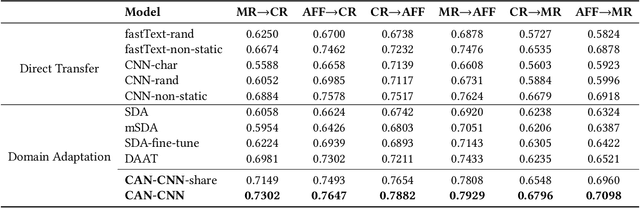
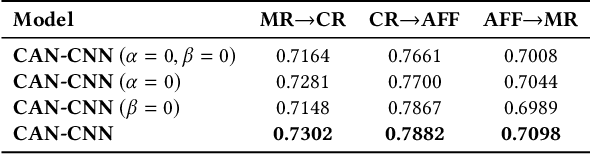
Domain adaptation tasks such as cross-domain sentiment classification aim to utilize existing labeled data in the source domain and unlabeled or few labeled data in the target domain to improve the performance in the target domain via reducing the shift between the data distributions. Existing cross-domain sentiment classification methods need to distinguish pivots, i.e., the domain-shared sentiment words, and non-pivots, i.e., the domain-specific sentiment words, for excellent adaptation performance. In this paper, we first design a Category Attention Network (CAN), and then propose a model named CAN-CNN to integrate CAN and a Convolutional Neural Network (CNN). On the one hand, the model regards pivots and non-pivots as unified category attribute words and can automatically capture them to improve the domain adaptation performance; on the other hand, the model makes an attempt at interpretability to learn the transferred category attribute words. Specifically, the optimization objective of our model has three different components: 1) the supervised classification loss; 2) the distributions loss of category feature weights; 3) the domain invariance loss. Finally, the proposed model is evaluated on three public sentiment analysis datasets and the results demonstrate that CAN-CNN can outperform other various baseline methods.
Extracting Variable-Depth Logical Document Hierarchy from Long Documents: Method, Evaluation, and Application
May 14, 2021
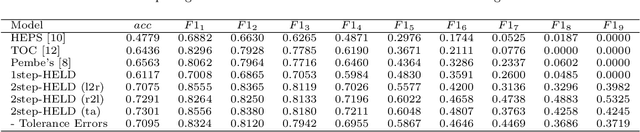
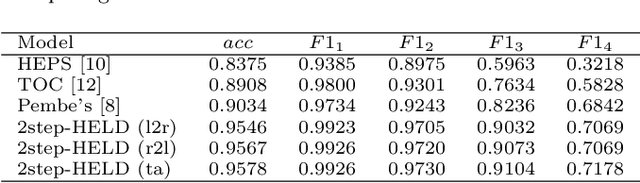
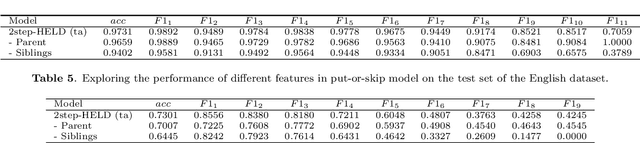
In this paper, we study the problem of extracting variable-depth "logical document hierarchy" from long documents, namely organizing the recognized "physical document objects" into hierarchical structures. The discovery of logical document hierarchy is the vital step to support many downstream applications. However, long documents, containing hundreds or even thousands of pages and variable-depth hierarchy, challenge the existing methods. To address these challenges, we develop a framework, namely Hierarchy Extraction from Long Document (HELD), where we "sequentially" insert each physical object at the proper on of the current tree. Determining whether each possible position is proper or not can be formulated as a binary classification problem. To further improve its effectiveness and efficiency, we study the design variants in HELD, including traversal orders of the insertion positions, heading extraction explicitly or implicitly, tolerance to insertion errors in predecessor steps, and so on. The empirical experiments based on thousands of long documents from Chinese, English financial market and English scientific publication show that the HELD model with the "root-to-leaf" traversal order and explicit heading extraction is the best choice to achieve the tradeoff between effectiveness and efficiency with the accuracy of 0.9726, 0.7291 and 0.9578 in Chinese financial, English financial and arXiv datasets, respectively. Finally, we show that logical document hierarchy can be employed to significantly improve the performance of the downstream passage retrieval task. In summary, we conduct a systematic study on this task in terms of methods, evaluations, and applications.
* 23 pages, 10 figures, Journal of computer science and technology
Atom Responding Machine for Dialog Generation
May 15, 2019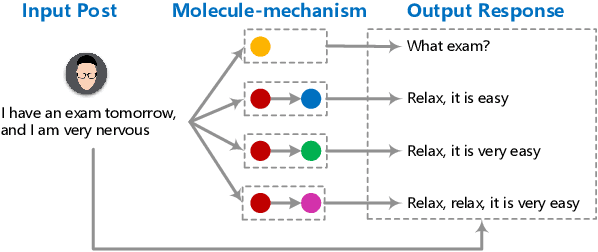
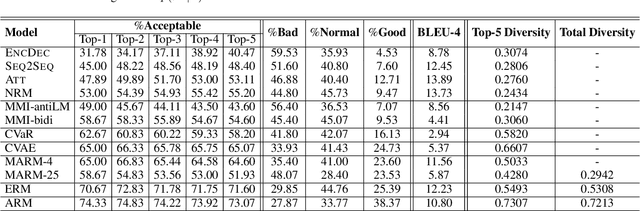
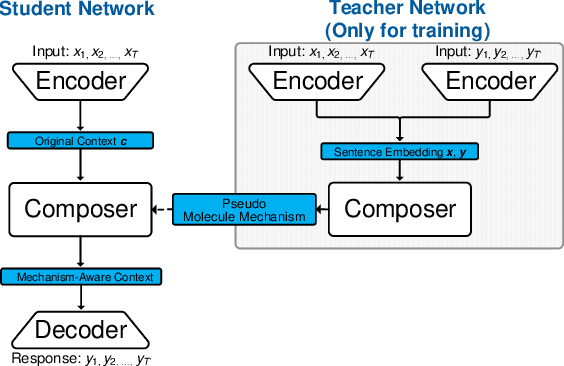
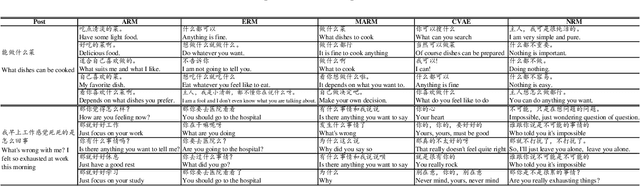
Recently, improving the relevance and diversity of dialogue system has attracted wide attention. For a post x, the corresponding response y is usually diverse in the real-world corpus, while the conventional encoder-decoder model tends to output the high-frequency (safe but trivial) responses and thus is difficult to handle the large number of responding styles. To address these issues, we propose the Atom Responding Machine (ARM), which is based on a proposed encoder-composer-decoder network trained by a teacher-student framework. To enrich the generated responses, ARM introduces a large number of molecule-mechanisms as various responding styles, which are conducted by taking different combinations from a few atom-mechanisms. In other words, even a little of atom-mechanisms can make a mickle of molecule-mechanisms. The experiments demonstrate diversity and quality of the responses generated by ARM. We also present generating process to show underlying interpretability for the result.
Hierarchical Neural Network for Extracting Knowledgeable Snippets and Documents
Aug 22, 2018

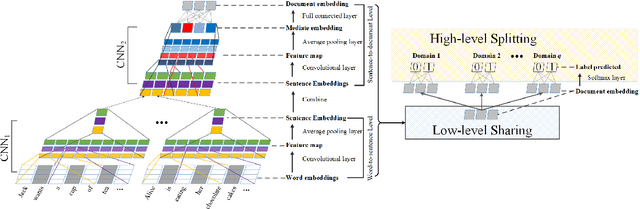

In this study, we focus on extracting knowledgeable snippets and annotating knowledgeable documents from Web corpus, consisting of the documents from social media and We-media. Informally, knowledgeable snippets refer to the text describing concepts, properties of entities, or relations among entities, while knowledgeable documents are the ones with enough knowledgeable snippets. These knowledgeable snippets and documents could be helpful in multiple applications, such as knowledge base construction and knowledge-oriented service. Previous studies extracted the knowledgeable snippets using the pattern-based method. Here, we propose the semantic-based method for this task. Specifically, a CNN based model is developed to extract knowledgeable snippets and annotate knowledgeable documents simultaneously. Additionally, a "low-level sharing, high-level splitting" structure of CNN is designed to handle the documents from different content domains. Compared with building multiple domain-specific CNNs, this joint model not only critically saves the training time, but also improves the prediction accuracy visibly. The superiority of the proposed method is demonstrated in a real dataset from Wechat public platform.
Tree-Structured Neural Machine for Linguistics-Aware Sentence Generation
Jan 03, 2018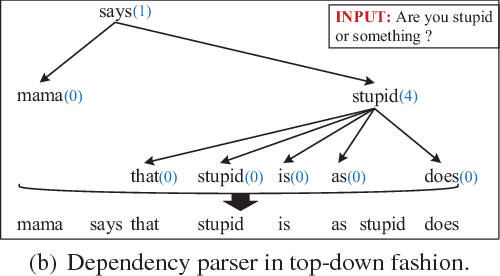
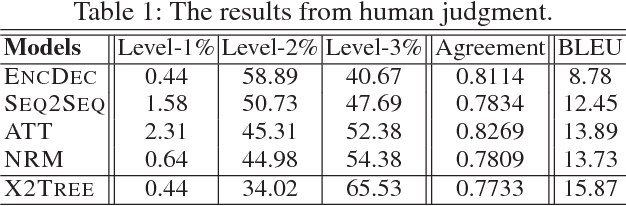
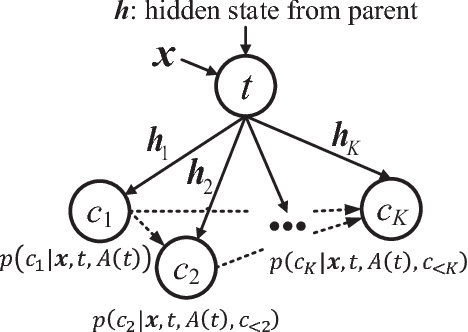
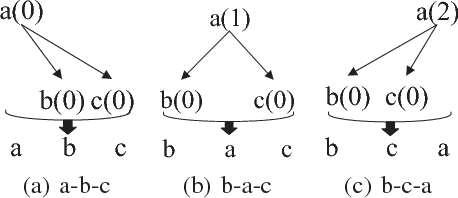
Different from other sequential data, sentences in natural language are structured by linguistic grammars. Previous generative conversational models with chain-structured decoder ignore this structure in human language and might generate plausible responses with less satisfactory relevance and fluency. In this study, we aim to incorporate the results from linguistic analysis into the process of sentence generation for high-quality conversation generation. Specifically, we use a dependency parser to transform each response sentence into a dependency tree and construct a training corpus of sentence-tree pairs. A tree-structured decoder is developed to learn the mapping from a sentence to its tree, where different types of hidden states are used to depict the local dependencies from an internal tree node to its children. For training acceleration, we propose a tree canonicalization method, which transforms trees into equivalent ternary trees. Then, with a proposed tree-structured search method, the model is able to generate the most probable responses in the form of dependency trees, which are finally flattened into sequences as the system output. Experimental results demonstrate that the proposed X2Tree framework outperforms baseline methods over 11.15% increase of acceptance ratio.