 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Analogical Learning using Language Models
Feb 03, 2025



Large language models have been shown to suffer from reasoning inconsistency issues. That is, they fail more in situations unfamiliar to the training data, even though exact or very similar reasoning paths exist in more common cases that they can successfully solve. Such observations motivate us to propose methods that encourage models to understand the high-level and abstract reasoning processes during training instead of only the final answer. This way, models can transfer the exact solution to similar cases, regardless of their relevance to the pre-training data distribution. In this work, we propose SAL, a self-supervised analogical learning framework. SAL mimics the human analogy process and trains models to explicitly transfer high-quality symbolic solutions from cases that they know how to solve to other rare cases in which they tend to fail more. We show that the resulting models after SAL learning outperform base language models on a wide range of reasoning benchmarks, such as StrategyQA, GSM8K, and HotpotQA, by 2% to 20%. At the same time, we show that our model is more generalizable and controllable through analytical studies.
Analyzing Nobel Prize Literature with Large Language Models
Oct 22, 2024



This study examines the capabilities of advanced Large Language Models (LLMs), particularly the o1 model, in the context of literary analysis. The outputs of these models are compared directly to those produced by graduate-level human participants. By focusing on two Nobel Prize-winning short stories, 'Nine Chapters' by Han Kang, the 2024 laureate, and 'Friendship' by Jon Fosse, the 2023 laureate, the research explores the extent to which AI can engage with complex literary elements such as thematic analysis, intertextuality, cultural and historical contexts, linguistic and structural innovations, and character development. Given the Nobel Prize's prestige and its emphasis on cultural, historical, and linguistic richness, applying LLMs to these works provides a deeper understanding of both human and AI approaches to interpretation. The study uses qualitative and quantitative evaluations of coherence, creativity, and fidelity to the text, revealing the strengths and limitations of AI in tasks typically reserved for human expertise. While LLMs demonstrate strong analytical capabilities, particularly in structured tasks, they often fall short in emotional nuance and coherence, areas where human interpretation excels. This research underscores the potential for human-AI collaboration in the humanities, opening new opportunities in literary studies and beyond.
Open Domain Question Answering with Conflicting Contexts
Oct 16, 2024



Open domain question answering systems frequently rely on information retrieved from large collections of text (such as the Web) to answer questions. However, such collections of text often contain conflicting information, and indiscriminately depending on this information may result in untruthful and inaccurate answers. To understand the gravity of this problem, we collect a human-annotated dataset, Question Answering with Conflicting Contexts (QACC), and find that as much as 25% of unambiguous, open domain questions can lead to conflicting contexts when retrieved using Google Search. We evaluate and benchmark three powerful Large Language Models (LLMs) with our dataset QACC and demonstrate their limitations in effectively addressing questions with conflicting information. To explore how humans reason through conflicting contexts, we request our annotators to provide explanations for their selections of correct answers. We demonstrate that by finetuning LLMs to explain their answers, we can introduce richer information into their training that guide them through the process of reasoning with conflicting contexts.
From Instructions to Constraints: Language Model Alignment with Automatic Constraint Verification
Mar 10, 2024User alignment is crucial for adapting general-purpose language models (LMs) to downstream tasks, but human annotations are often not available for all types of instructions, especially those with customized constraints. We observe that user instructions typically contain constraints. While assessing response quality in terms of the whole instruction is often costly, efficiently evaluating the satisfaction rate of constraints is feasible. We investigate common constraints in NLP tasks, categorize them into three classes based on the types of their arguments, and propose a unified framework, ACT (Aligning to ConsTraints), to automatically produce supervision signals for user alignment with constraints. Specifically, ACT uses constraint verifiers, which are typically easy to implement in practice, to compute constraint satisfaction rate (CSR) of each response. It samples multiple responses for each prompt and collect preference labels based on their CSR automatically. Subsequently, ACT adapts the LM to the target task through a ranking-based learning process. Experiments on fine-grained entity typing, abstractive summarization, and temporal question answering show that ACT is able to enhance LMs' capability to adhere to different classes of constraints, thereby improving task performance. Further experiments show that the constraint-following capabilities are transferable.
PInKS: Preconditioned Commonsense Inference with Minimal Supervision
Jun 16, 2022

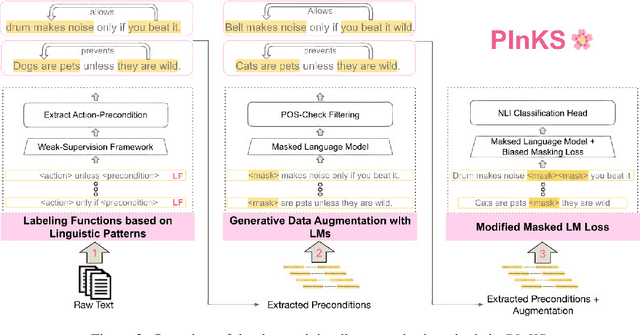
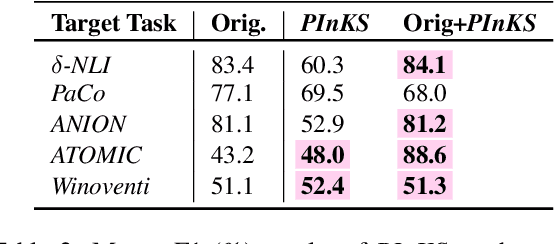
Reasoning with preconditions such as "glass can be used for drinking water unless the glass is shattered" remains an open problem for language models. The main challenge lies in the scarcity of preconditions data and the model's lack of support for such reasoning. We present PInKS, Preconditioned Commonsense Inference with WeaK Supervision, an improved model for reasoning with preconditions through minimum supervision. We show, both empirically and theoretically, that PInKS improves the results on benchmarks focused on reasoning with the preconditions of commonsense knowledge (up to 40% Macro-F1 scores). We further investigate PInKS through PAC-Bayesian informativeness analysis, precision measures, and ablation study.
Answer Consolidation: Formulation and Benchmarking
Apr 29, 2022


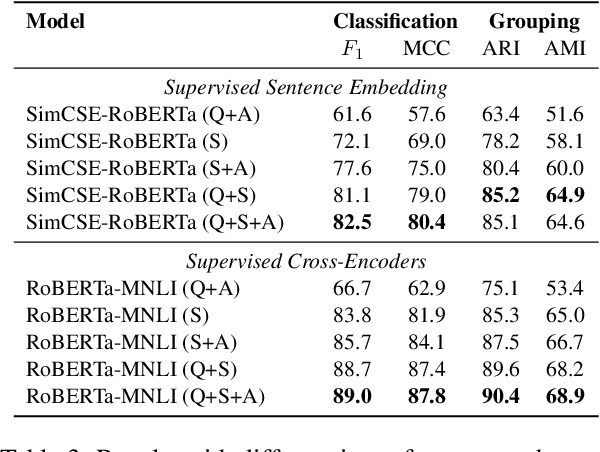
Current question answering (QA) systems primarily consider the single-answer scenario, where each question is assumed to be paired with one correct answer. However, in many real-world QA applications, multiple answer scenarios arise where consolidating answers into a comprehensive and non-redundant set of answers is a more efficient user interface. In this paper, we formulate the problem of answer consolidation, where answers are partitioned into multiple groups, each representing different aspects of the answer set. Then, given this partitioning, a comprehensive and non-redundant set of answers can be constructed by picking one answer from each group. To initiate research on answer consolidation, we construct a dataset consisting of 4,699 questions and 24,006 sentences and evaluate multiple models. Despite a promising performance achieved by the best-performing supervised models, we still believe this task has room for further improvements.
Extracting Temporal Event Relation with Syntactic-Guided Temporal Graph Transformer
Apr 19, 2021
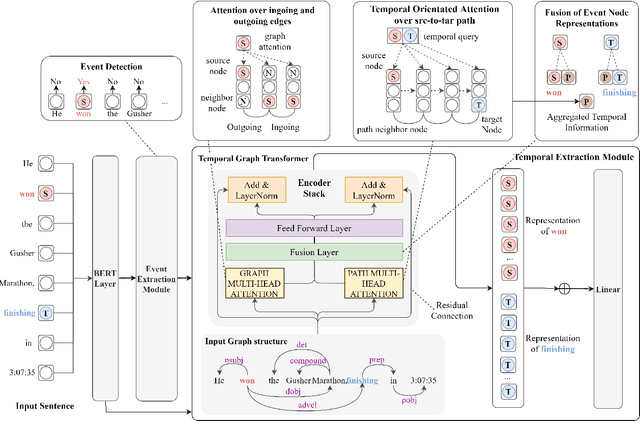
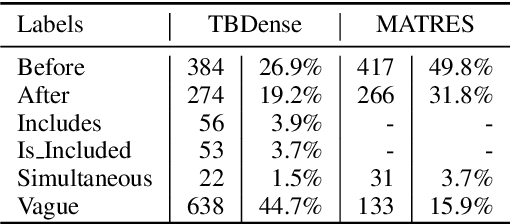
Extracting temporal relations (e.g., before, after, concurrent) among events is crucial to natural language understanding. Previous studies mainly rely on neural networks to learn effective features or manual-crafted linguistic features for temporal relation extraction, which usually fail when the context between two events is complex or wide. Inspired by the examination of available temporal relation annotations and human-like cognitive procedures, we propose a new Temporal Graph Transformer network to (1) explicitly find the connection between two events from a syntactic graph constructed from one or two continuous sentences, and (2) automatically locate the most indicative temporal cues from the path of the two event mentions as well as their surrounding concepts in the syntactic graph with a new temporal-oriented attention mechanism. Experiments on MATRES and TB-Dense datasets show that our approach significantly outperforms previous state-of-the-art methods on both end-to-end temporal relation extraction and temporal relation classification.
ESTER: A Machine Reading Comprehension Dataset for Event Semantic Relation Reasoning
Apr 16, 2021
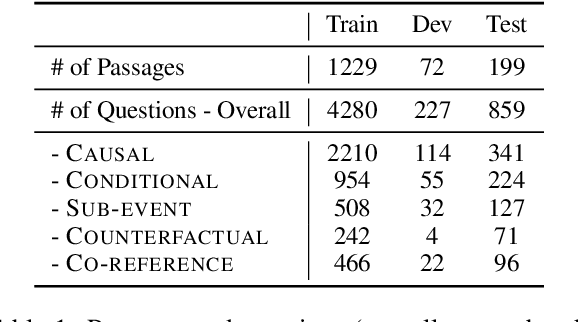
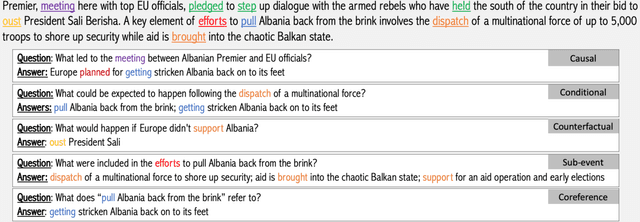
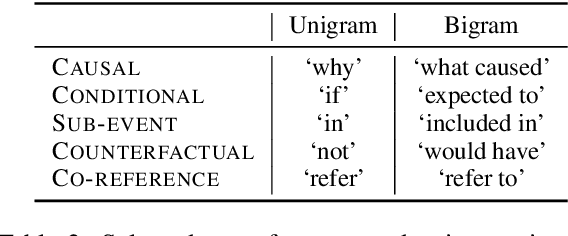
Stories and narratives are composed based on a variety of events. Understanding how these events are semantically related to each other is the essence of reading comprehension. Recent event-centric reading comprehension datasets focus on either event arguments or event temporal commonsense. Although these tasks evaluate machines' ability of narrative understanding, human like reading comprehension requires the capability to process event-based semantics beyond arguments and temporal commonsense. For example, to understand causality between events, we need to infer motivations or purposes; to understand event hierarchy, we need to parse the composition of events. To facilitate these tasks, we introduce ESTER, a comprehensive machine reading comprehension (MRC) dataset for Event Semantic Relation Reasoning. We study five most commonly used event semantic relations and formulate them as question answering tasks. Experimental results show that the current SOTA systems achieve 60.5%, 57.8%, and 76.3% for event-based F1, token based F1 and HIT@1 scores respectively, which are significantly below human performances.
SpartQA: : A Textual Question Answering Benchmark for Spatial Reasoning
Apr 12, 2021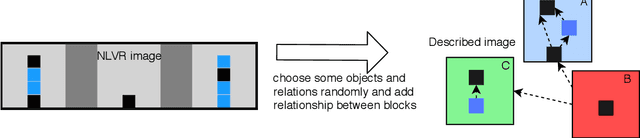
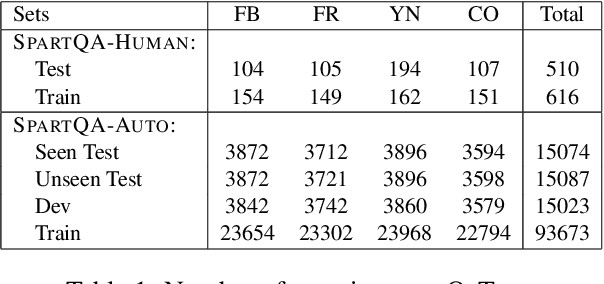
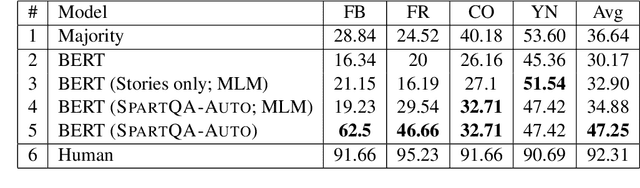
This paper proposes a question-answering (QA) benchmark for spatial reasoning on natural language text which contains more realistic spatial phenomena not covered by prior work and is challenging for state-of-the-art language models (LM). We propose a distant supervision method to improve on this task. Specifically, we design grammar and reasoning rules to automatically generate a spatial description of visual scenes and corresponding QA pairs. Experiments show that further pretraining LMs on these automatically generated data significantly improves LMs' capability on spatial understanding, which in turn helps to better solve two external datasets, bAbI, and boolQ. We hope that this work can foster investigations into more sophisticated models for spatial reasoning over text.
Temporal Reasoning on Implicit Events from Distant Supervision
Oct 24, 2020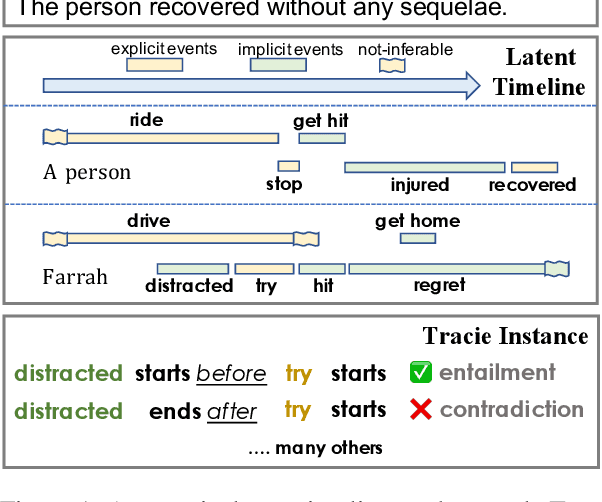
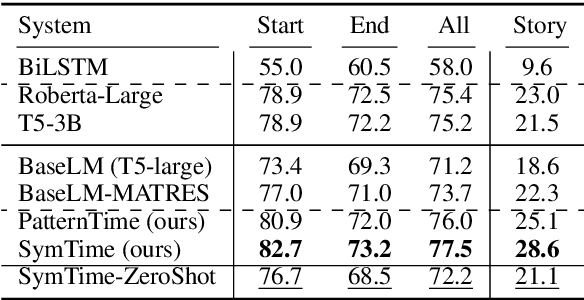

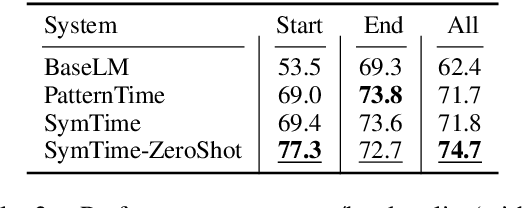
Existing works on temporal reasoning among events described in text focus on modeling relationships between explicitly mentioned events and do not handle event end time effectively. However, human readers can infer from natural language text many implicit events that help them better understand the situation and, consequently, better reason about time. This work proposes a new crowd-sourced dataset, TRACIE, which evaluates systems' understanding of implicit events - events that are not mentioned explicitly in the text but can be inferred from it. This is done via textual entailment instances querying both start and end times of events. We show that TRACIE is challenging for state-of-the-art language models. Our proposed model, SymTime, exploits distant supervision signals from the text itself and reasons over events' start time and duration to infer events' end time points. We show that our approach improves over baseline language models, gaining 5% on the i.i.d. split and 9% on an out-of-distribution test split. Our approach is also general to other annotation schemes, gaining 2%-8% on MATRES, an extrinsic temporal relation benchmark.