 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Pinching Antenna Array Design for Sum-Rate Maximization in Multi-User PASS
Jun 02, 2026Pinching antenna systems (PASS) have recently emerged as a promising architecture for flexible indoor wireless communications. However, most existing pinching antenna (PA) array designs for multi-user PASS either offer limited beam adaptation accuracy or require prohibitively high deployment cost. In this paper, we investigate a more practical constrained pinching antenna array (C-PAA)-assisted downlink PASS, where multiple PAs are grouped into a movable array and can be finely adjusted within the array at the wavelength scale. To improve the system spectral efficiency, a sum-rate maximization problem is formulated by jointly considering the array-center position and the fine-grained antenna distribution within the C-PAA. First, the structural properties of the C-PAA are characterized, and an explicit upper bound on the array aperture is derived. Then, tractable approximations for the effective channel gain and the achievable user rate are developed. Furthermore, the optimization problem of the multi-user sum-rate is analyzed, where the system sum-rate function is shown to exhibit a favorable unimodal behavior under practically relevant conditions, which enables an efficient one-dimensional search for the optimal C-PAA position. To further reduce the computational complexity, a closed-form approximate solution for the near-optimal array-center position is derived. Numerical results verify the accuracy of the developed analysis and demonstrate that the proposed C-PAA scheme closely approaches the ideal upper bound and significantly outperforms conventional fixed-spacing and existing PA array benchmarks.
DG-CoLearn: An Efficient Collaborative Learning Framework for Dynamic Graphs
May 29, 2026Dynamic graph learning (DGL) is essential for modelling evolving graph data, but existing methods suffer from significant computational overhead due to repeated full-snapshot retraining and are not well-suited for collaborative settings with partitioned data. In realistic graph systems, cross-partition edges are unavoidable, but direct sharing of graph structure between clients may violate privacy constraints. We propose DG-CoLearn, a client-oblivious collaborative dynamic graph learning framework built on incremental graph snapshot processing, which focuses computation on graph regions affected by temporal updates while preserving historical information through temporal modelling. This incremental design is consistently applied across the entire graph processing pipeline, including a server-mediated embedding exchange mechanism to enable accurate multi-hop message passing without exposing raw cross-client structural information. Extensive experiments demonstrate that DG-CoLearn achieves up to 33.8$\times$ speedup in training time and 27.4$\times$ reduction in communication overhead, while consistently improving predictive performance on both node classification (up to 13.36% F1 improvement) and link prediction (up to 8.27% MAP improvement) tasks. These results highlight the effectiveness of DG-CoLearn in bridging efficiency, scalability, and client-to-client structural privacy in collaborative dynamic graph learning.
Criticality-Based Dynamic Topology Optimization for Enhancing Aerial-Marine Swarm Resilience
Aug 01, 2025Heterogeneous marine-aerial swarm networks encounter substantial difficulties due to targeted communication disruptions and structural weaknesses in adversarial environments. This paper proposes a two-step framework to strengthen the network's resilience. Specifically, our framework combines the node prioritization based on criticality with multi-objective topology optimization. First, we design a three-layer architecture to represent structural, communication, and task dependencies of the swarm networks. Then, we introduce the SurBi-Ranking method, which utilizes graph convolutional networks, to dynamically evaluate and rank the criticality of nodes and edges in real time. Next, we apply the NSGA-III algorithm to optimize the network topology, aiming to balance communication efficiency, global connectivity, and mission success rate. Experiments demonstrate that compared to traditional methods like K-Shell, our SurBi-Ranking method identifies critical nodes and edges with greater accuracy, as deliberate attacks on these components cause more significant connectivity degradation. Furthermore, our optimization approach, when prioritizing SurBi-Ranked critical components under attack, reduces the natural connectivity degradation by around 30%, achieves higher mission success rates, and incurs lower communication reconfiguration costs, ensuring sustained connectivity and mission effectiveness across multi-phase operations.
Semantic Communication Meets Heterogeneous Network: Emerging Trends, Opportunities, and Challenges
Feb 13, 2025Recent developments in machine learning (ML) techniques enable users to extract, transmit, and reproduce information semantics via ML-based semantic communication (SemCom). This significantly increases network spectral efficiency and transmission robustness. In the network, the semantic encoders and decoders among various users, based on ML, however, require collaborative updating according to new transmission tasks. The various heterogeneous characteristics of most networks in turn introduce emerging but unique challenges for semantic codec updating that are different from other general ML model updating. In this article, we first overview the key components of the SemCom system. We then discuss the unique challenges associated with semantic codec updates in heterogeneous networks. Accordingly, we point out a potential framework and discuss the pros and cons thereof. Finally, several future research directions are also discussed.
STAR-RIS Enabled ISAC Systems: Joint Rate Splitting and Beamforming Optimization
Nov 14, 2024



This paper delves into an integrated sensing and communication (ISAC) system bolstered by a simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS). Within this system, a base station (BS) is equipped with communication and radar capabilities, enabling it to communicate with ground terminals (GTs) and concurrently probe for echo signals from a target of interest. Moreover, to manage interference and improve communication quality, the rate splitting multiple access (RSMA) scheme is incorporated into the system. The signal-to-interference-plus-noise ratio (SINR) of the received sensing echo signals is a measure of sensing performance. We formulate a joint optimization problem of common rates, transmit beamforming at the BS, and passive beamforming vectors of the STAR-RIS. The objective is to maximize sensing SINR while guaranteeing the communication rate requirements for each GT. We present an iterative algorithm to address the non-convex problem by invoking Dinkelbach's transform, semidefinite relaxation (SDR), majorization-minimization, and sequential rank-one constraint relaxation (SROCR) theories. Simulation results manifest that the performance of the studied ISAC network enhanced by the STAR-RIS and RSMA surpasses other benchmarks considerably. The results evidently indicate the superior performance improvement of the ISAC system with the proposed RSMA-based transmission strategy design and the dynamic optimization of both transmission and reflection beamforming at STAR-RIS.
Communication and Control Co-Design in 6G: Sequential Decision-Making with LLMs
Jul 06, 2024



This article investigates a control system within the context of six-generation wireless networks. The control performance optimization confronts the technical challenges that arise from the intricate interactions between communication and control sub-systems, asking for a co-design. Accounting for the system dynamics, we formulate the sequential co-design decision-makings of communication and control over the discrete time horizon as a Markov decision process, for which a practical offline learning framework is proposed. Our proposed framework integrates large language models into the elements of reinforcement learning. We present a case study on the age of semantics-aware communication and control co-design to showcase the potentials from our proposed learning framework. Furthermore, we discuss the open issues remaining to make our proposed offline learning framework feasible for real-world implementations, and highlight the research directions for future explorations.
Certified Policy Smoothing for Cooperative Multi-Agent Reinforcement Learning
Dec 22, 2022Cooperative multi-agent reinforcement learning (c-MARL) is widely applied in safety-critical scenarios, thus the analysis of robustness for c-MARL models is profoundly important. However, robustness certification for c-MARLs has not yet been explored in the community. In this paper, we propose a novel certification method, which is the first work to leverage a scalable approach for c-MARLs to determine actions with guaranteed certified bounds. c-MARL certification poses two key challenges compared with single-agent systems: (i) the accumulated uncertainty as the number of agents increases; (ii) the potential lack of impact when changing the action of a single agent into a global team reward. These challenges prevent us from directly using existing algorithms. Hence, we employ the false discovery rate (FDR) controlling procedure considering the importance of each agent to certify per-state robustness and propose a tree-search-based algorithm to find a lower bound of the global reward under the minimal certified perturbation. As our method is general, it can also be applied in single-agent environments. We empirically show that our certification bounds are much tighter than state-of-the-art RL certification solutions. We also run experiments on two popular c-MARL algorithms: QMIX and VDN, in two different environments, with two and four agents. The experimental results show that our method produces meaningful guaranteed robustness for all models and environments. Our tool CertifyCMARL is available at https://github.com/TrustAI/CertifyCMA
3DVerifier: Efficient Robustness Verification for 3D Point Cloud Models
Jul 15, 2022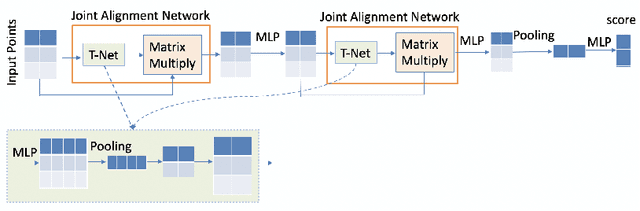
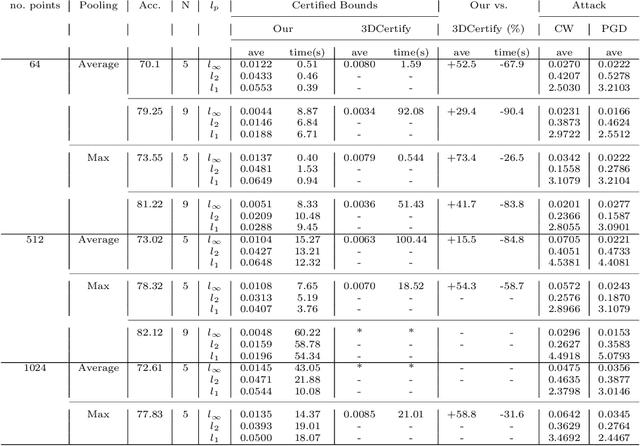

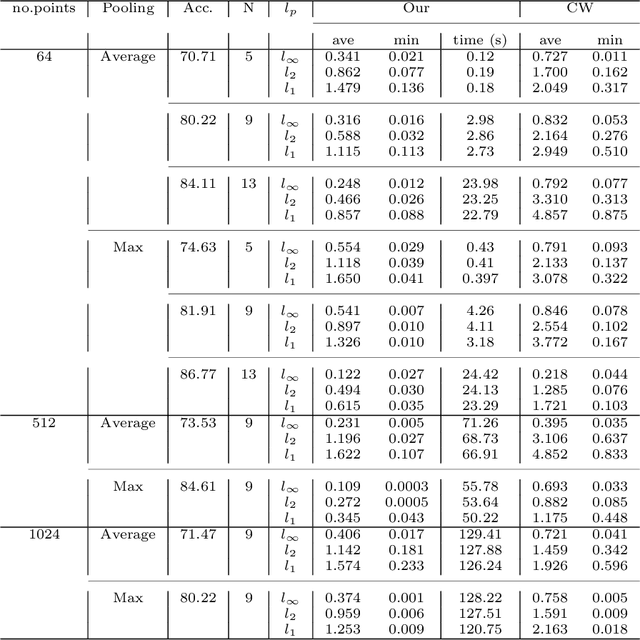
3D point cloud models are widely applied in safety-critical scenes, which delivers an urgent need to obtain more solid proofs to verify the robustness of models. Existing verification method for point cloud model is time-expensive and computationally unattainable on large networks. Additionally, they cannot handle the complete PointNet model with joint alignment network (JANet) that contains multiplication layers, which effectively boosts the performance of 3D models. This motivates us to design a more efficient and general framework to verify various architectures of point cloud models. The key challenges in verifying the large-scale complete PointNet models are addressed as dealing with the cross-non-linearity operations in the multiplication layers and the high computational complexity of high-dimensional point cloud inputs and added layers. Thus, we propose an efficient verification framework, 3DVerifier, to tackle both challenges by adopting a linear relaxation function to bound the multiplication layer and combining forward and backward propagation to compute the certified bounds of the outputs of the point cloud models. Our comprehensive experiments demonstrate that 3DVerifier outperforms existing verification algorithms for 3D models in terms of both efficiency and accuracy. Notably, our approach achieves an orders-of-magnitude improvement in verification efficiency for the large network, and the obtained certified bounds are also significantly tighter than the state-of-the-art verifiers. We release our tool 3DVerifier via https://github.com/TrustAI/3DVerifier for use by the community.
Sparse Adversarial Video Attacks with Spatial Transformations
Nov 10, 2021

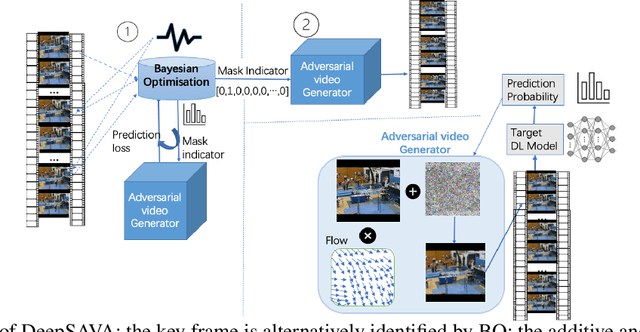

In recent years, a significant amount of research efforts concentrated on adversarial attacks on images, while adversarial video attacks have seldom been explored. We propose an adversarial attack strategy on videos, called DeepSAVA. Our model includes both additive perturbation and spatial transformation by a unified optimisation framework, where the structural similarity index (SSIM) measure is adopted to measure the adversarial distance. We design an effective and novel optimisation scheme which alternatively utilizes Bayesian optimisation to identify the most influential frame in a video and Stochastic gradient descent (SGD) based optimisation to produce both additive and spatial-transformed perturbations. Doing so enables DeepSAVA to perform a very sparse attack on videos for maintaining human imperceptibility while still achieving state-of-the-art performance in terms of both attack success rate and adversarial transferability. Our intensive experiments on various types of deep neural networks and video datasets confirm the superiority of DeepSAVA.
Auxiliary-task Based Deep Reinforcement Learning for Participant Selection Problem in Mobile Crowdsourcing
Aug 26, 2020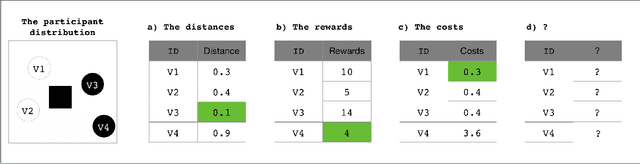
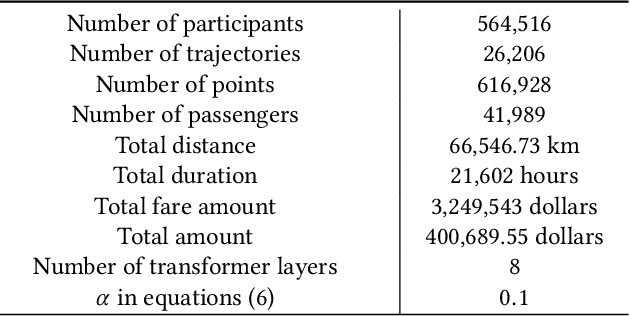
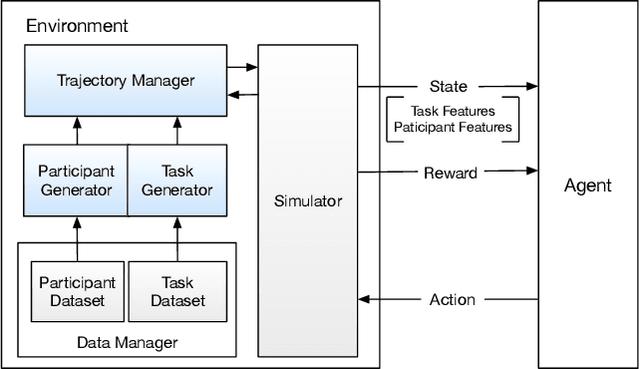
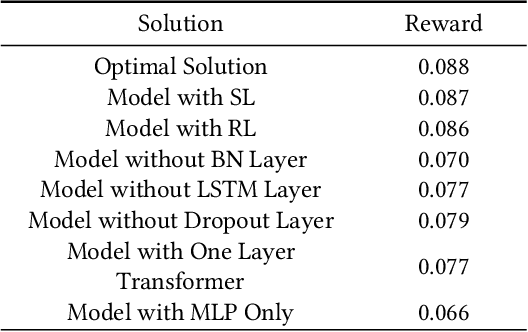
In mobile crowdsourcing (MCS), the platform selects participants to complete location-aware tasks from the recruiters aiming to achieve multiple goals (e.g., profit maximization, energy efficiency, and fairness). However, different MCS systems have different goals and there are possibly conflicting goals even in one MCS system. Therefore, it is crucial to design a participant selection algorithm that applies to different MCS systems to achieve multiple goals. To deal with this issue, we formulate the participant selection problem as a reinforcement learning problem and propose to solve it with a novel method, which we call auxiliary-task based deep reinforcement learning (ADRL). We use transformers to extract representations from the context of the MCS system and a pointer network to deal with the combinatorial optimization problem. To improve the sample efficiency, we adopt an auxiliary-task training process that trains the network to predict the imminent tasks from the recruiters, which facilitates the embedding learning of the deep learning model. Additionally, we release a simulated environment on a specific MCS task, the ride-sharing task, and conduct extensive performance evaluations in this environment. The experimental results demonstrate that ADRL outperforms and improves sample efficiency over other well-recognized baselines in various settings.