 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy is AI not a Panacea for Data Workers? An Interview Study on Human-AI Collaboration in Data Storytelling
Apr 17, 2023


Data storytelling plays an important role in data workers' daily jobs since it boosts team collaboration and public communication. However, to make an appealing data story, data workers spend tremendous efforts on various tasks, including outlining and styling the story. Recently, a growing research trend has been exploring how to assist data storytelling with advanced artificial intelligence (AI). However, existing studies may focus on individual tasks in the workflow of data storytelling and do not reveal a complete picture of humans' preference for collaborating with AI. To better understand real-world needs, we interviewed eighteen data workers from both industry and academia to learn where and how they would like to collaborate with AI. Surprisingly, though the participants showed excitement about collaborating with AI, many of them also expressed reluctance and pointed out nuanced reasons. Based on their responses, we first characterize stages and tasks in the practical data storytelling workflows and the desired roles of AI. Then the preferred collaboration patterns in different tasks are identified. Next, we summarize the interviewees' reasons why and why not they would like to collaborate with AI. Finally, we provide suggestions for human-AI collaborative data storytelling to hopefully shed light on future related research.
fAIlureNotes: Supporting Designers in Understanding the Limits of AI Models for Computer Vision Tasks
Feb 22, 2023



To design with AI models, user experience (UX) designers must assess the fit between the model and user needs. Based on user research, they need to contextualize the model's behavior and potential failures within their product-specific data instances and user scenarios. However, our formative interviews with ten UX professionals revealed that such a proactive discovery of model limitations is challenging and time-intensive. Furthermore, designers often lack technical knowledge of AI and accessible exploration tools, which challenges their understanding of model capabilities and limitations. In this work, we introduced a failure-driven design approach to AI, a workflow that encourages designers to explore model behavior and failure patterns early in the design process. The implementation of fAIlureNotes, a designer-centered failure exploration and analysis tool, supports designers in evaluating models and identifying failures across diverse user groups and scenarios. Our evaluation with UX practitioners shows that fAIlureNotes outperforms today's interactive model cards in assessing context-specific model performance.
Designerly Understanding: Information Needs for Model Transparency to Support Design Ideation for AI-Powered User Experience
Feb 21, 2023



Despite the widespread use of artificial intelligence (AI), designing user experiences (UX) for AI-powered systems remains challenging. UX designers face hurdles understanding AI technologies, such as pre-trained language models, as design materials. This limits their ability to ideate and make decisions about whether, where, and how to use AI. To address this problem, we bridge the literature on AI design and AI transparency to explore whether and how frameworks for transparent model reporting can support design ideation with pre-trained models. By interviewing 23 UX practitioners, we find that practitioners frequently work with pre-trained models, but lack support for UX-led ideation. Through a scenario-based design task, we identify common goals that designers seek model understanding for and pinpoint their model transparency information needs. Our study highlights the pivotal role that UX designers can play in Responsible AI and calls for supporting their understanding of AI limitations through model transparency and interrogation.
Human-Centered Responsible Artificial Intelligence: Current & Future Trends
Feb 16, 2023
In recent years, the CHI community has seen significant growth in research on Human-Centered Responsible Artificial Intelligence. While different research communities may use different terminology to discuss similar topics, all of this work is ultimately aimed at developing AI that benefits humanity while being grounded in human rights and ethics, and reducing the potential harms of AI. In this special interest group, we aim to bring together researchers from academia and industry interested in these topics to map current and future research trends to advance this important area of research by fostering collaboration and sharing ideas.
Generation Probabilities Are Not Enough: Exploring the Effectiveness of Uncertainty Highlighting in AI-Powered Code Completions
Feb 14, 2023



Large-scale generative models enabled the development of AI-powered code completion tools to assist programmers in writing code. However, much like other AI-powered tools, AI-powered code completions are not always accurate, potentially introducing bugs or even security vulnerabilities into code if not properly detected and corrected by a human programmer. One technique that has been proposed and implemented to help programmers identify potential errors is to highlight uncertain tokens. However, there have been no empirical studies exploring the effectiveness of this technique-- nor investigating the different and not-yet-agreed-upon notions of uncertainty in the context of generative models. We explore the question of whether conveying information about uncertainty enables programmers to more quickly and accurately produce code when collaborating with an AI-powered code completion tool, and if so, what measure of uncertainty best fits programmers' needs. Through a mixed-methods study with 30 programmers, we compare three conditions: providing the AI system's code completion alone, highlighting tokens with the lowest likelihood of being generated by the underlying generative model, and highlighting tokens with the highest predicted likelihood of being edited by a programmer. We find that highlighting tokens with the highest predicted likelihood of being edited leads to faster task completion and more targeted edits, and is subjectively preferred by study participants. In contrast, highlighting tokens according to their probability of being generated does not provide any benefit over the baseline with no highlighting. We further explore the design space of how to convey uncertainty in AI-powered code completion tools, and find that programmers prefer highlights that are granular, informative, interpretable, and not overwhelming.
Selective Explanations: Leveraging Human Input to Align Explainable AI
Jan 23, 2023



While a vast collection of explainable AI (XAI) algorithms have been developed in recent years, they are often criticized for significant gaps with how humans produce and consume explanations. As a result, current XAI techniques are often found to be hard to use and lack effectiveness. In this work, we attempt to close these gaps by making AI explanations selective -- a fundamental property of human explanations -- by selectively presenting a subset from a large set of model reasons based on what aligns with the recipient's preferences. We propose a general framework for generating selective explanations by leveraging human input on a small sample. This framework opens up a rich design space that accounts for different selectivity goals, types of input, and more. As a showcase, we use a decision-support task to explore selective explanations based on what the decision-maker would consider relevant to the decision task. We conducted two experimental studies to examine three out of a broader possible set of paradigms based on our proposed framework: in Study 1, we ask the participants to provide their own input to generate selective explanations, with either open-ended or critique-based input. In Study 2, we show participants selective explanations based on input from a panel of similar users (annotators). Our experiments demonstrate the promise of selective explanations in reducing over-reliance on AI and improving decision outcomes and subjective perceptions of the AI, but also paint a nuanced picture that attributes some of these positive effects to the opportunity to provide one's own input to augment AI explanations. Overall, our work proposes a novel XAI framework inspired by human communication behaviors and demonstrates its potentials to encourage future work to better align AI explanations with human production and consumption of explanations.
Understanding the Role of Human Intuition on Reliance in Human-AI Decision-Making with Explanations
Jan 18, 2023



AI explanations are often mentioned as a way to improve human-AI decision-making. Yet, empirical studies have not found consistent evidence of explanations' effectiveness and, on the contrary, suggest that they can increase overreliance when the AI system is wrong. While many factors may affect reliance on AI support, one important factor is how decision-makers reconcile their own intuition -- which may be based on domain knowledge, prior task experience, or pattern recognition -- with the information provided by the AI system to determine when to override AI predictions. We conduct a think-aloud, mixed-methods study with two explanation types (feature- and example-based) for two prediction tasks to explore how decision-makers' intuition affects their use of AI predictions and explanations, and ultimately their choice of when to rely on AI. Our results identify three types of intuition involved in reasoning about AI predictions and explanations: intuition about the task outcome, features, and AI limitations. Building on these, we summarize three observed pathways for decision-makers to apply their own intuition and override AI predictions. We use these pathways to explain why (1) the feature-based explanations we used did not improve participants' decision outcomes and increased their overreliance on AI, and (2) the example-based explanations we used improved decision-makers' performance over feature-based explanations and helped achieve complementary human-AI performance. Overall, our work identifies directions for further development of AI decision-support systems and explanation methods that help decision-makers effectively apply their intuition to achieve appropriate reliance on AI.
Seamful XAI: Operationalizing Seamful Design in Explainable AI
Nov 12, 2022



Mistakes in AI systems are inevitable, arising from both technical limitations and sociotechnical gaps. While black-boxing AI systems can make the user experience seamless, hiding the seams risks disempowering users to mitigate fallouts from AI mistakes. While Explainable AI (XAI) has predominantly tackled algorithmic opaqueness, we propose that seamful design can foster Humancentered XAI by strategically revealing sociotechnical and infrastructural mismatches. We introduce the notion of Seamful XAI by (1) conceptually transferring "seams" to the AI context and (2) developing a design process that helps stakeholders design with seams, thereby augmenting explainability and user agency. We explore this process with 43 AI practitioners and users, using a scenario-based co-design activity informed by real-world use cases. We share empirical insights, implications, and critical reflections on how this process can help practitioners anticipate and craft seams in AI, how seamfulness can improve explainability, empower end-users, and facilitate Responsible AI.
Connecting Algorithmic Research and Usage Contexts: A Perspective of Contextualized Evaluation for Explainable AI
Jun 22, 2022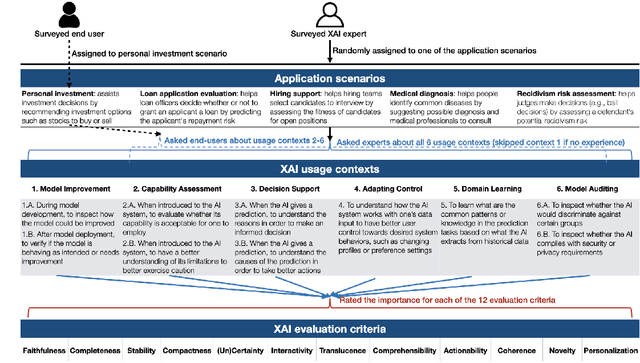
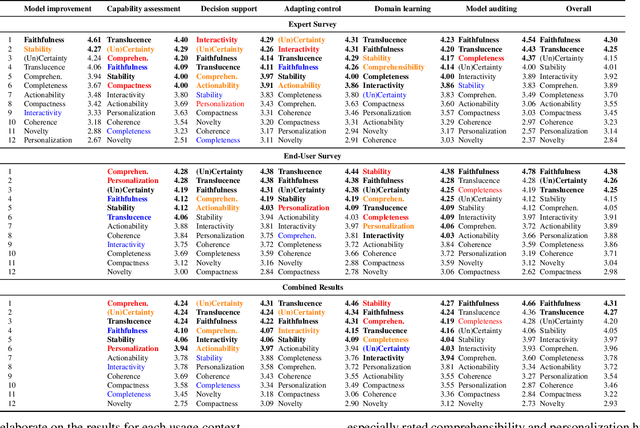

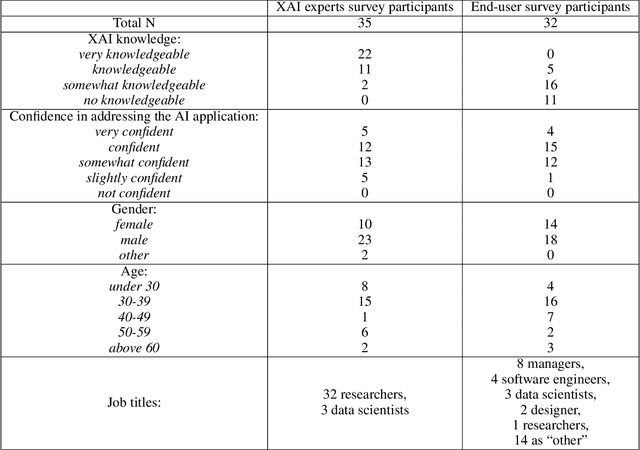
Recent years have seen a surge of interest in the field of explainable AI (XAI), with a plethora of algorithms proposed in the literature. However, a lack of consensus on how to evaluate XAI hinders the advancement of the field. We highlight that XAI is not a monolithic set of technologies -- researchers and practitioners have begun to leverage XAI algorithms to build XAI systems that serve different usage contexts, such as model debugging and decision-support. Algorithmic research of XAI, however, often does not account for these diverse downstream usage contexts, resulting in limited effectiveness or even unintended consequences for actual users, as well as difficulties for practitioners to make technical choices. We argue that one way to close the gap is to develop evaluation methods that account for different user requirements in these usage contexts. Towards this goal, we introduce a perspective of contextualized XAI evaluation by considering the relative importance of XAI evaluation criteria for prototypical usage contexts of XAI. To explore the context-dependency of XAI evaluation criteria, we conduct two survey studies, one with XAI topical experts and another with crowd workers. Our results urge for responsible AI research with usage-informed evaluation practices, and provide a nuanced understanding of user requirements for XAI in different usage contexts.
Designing for Responsible Trust in AI Systems: A Communication Perspective
Apr 29, 2022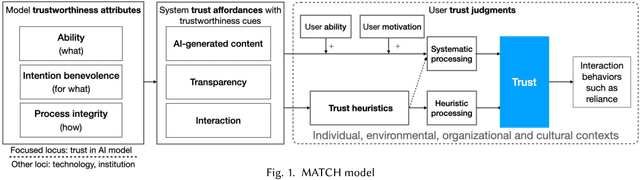
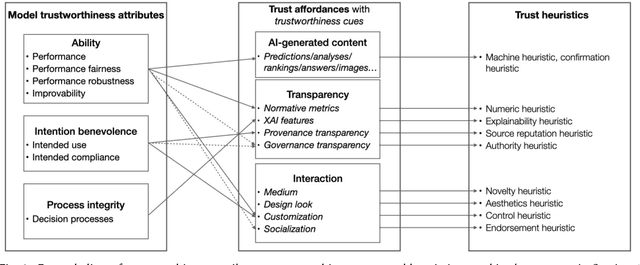
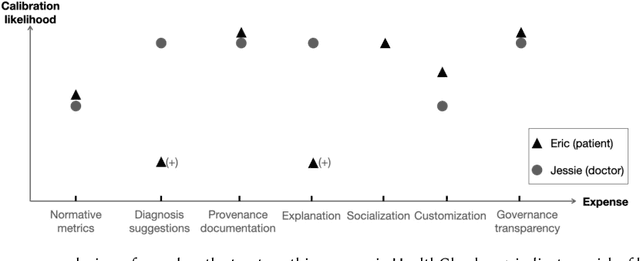
Current literature and public discourse on "trust in AI" are often focused on the principles underlying trustworthy AI, with insufficient attention paid to how people develop trust. Given that AI systems differ in their level of trustworthiness, two open questions come to the fore: how should AI trustworthiness be responsibly communicated to ensure appropriate and equitable trust judgments by different users, and how can we protect users from deceptive attempts to earn their trust? We draw from communication theories and literature on trust in technologies to develop a conceptual model called MATCH, which describes how trustworthiness is communicated in AI systems through trustworthiness cues and how those cues are processed by people to make trust judgments. Besides AI-generated content, we highlight transparency and interaction as AI systems' affordances that present a wide range of trustworthiness cues to users. By bringing to light the variety of users' cognitive processes to make trust judgments and their potential limitations, we urge technology creators to make conscious decisions in choosing reliable trustworthiness cues for target users and, as an industry, to regulate this space and prevent malicious use. Towards these goals, we define the concepts of warranted trustworthiness cues and expensive trustworthiness cues, and propose a checklist of requirements to help technology creators identify appropriate cues to use. We present a hypothetical use case to illustrate how practitioners can use MATCH to design AI systems responsibly, and discuss future directions for research and industry efforts aimed at promoting responsible trust in AI.