 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Circuit Optimization with AlphaTensor
Mar 05, 2024



A key challenge in realizing fault-tolerant quantum computers is circuit optimization. Focusing on the most expensive gates in fault-tolerant quantum computation (namely, the T gates), we address the problem of T-count optimization, i.e., minimizing the number of T gates that are needed to implement a given circuit. To achieve this, we develop AlphaTensor-Quantum, a method based on deep reinforcement learning that exploits the relationship between optimizing T-count and tensor decomposition. Unlike existing methods for T-count optimization, AlphaTensor-Quantum can incorporate domain-specific knowledge about quantum computation and leverage gadgets, which significantly reduces the T-count of the optimized circuits. AlphaTensor-Quantum outperforms the existing methods for T-count optimization on a set of arithmetic benchmarks (even when compared without making use of gadgets). Remarkably, it discovers an efficient algorithm akin to Karatsuba's method for multiplication in finite fields. AlphaTensor-Quantum also finds the best human-designed solutions for relevant arithmetic computations used in Shor's algorithm and for quantum chemistry simulation, thus demonstrating it can save hundreds of hours of research by optimizing relevant quantum circuits in a fully automated way.
Consensus, dissensus and synergy between clinicians and specialist foundation models in radiology report generation
Dec 06, 2023



Radiology reports are an instrumental part of modern medicine, informing key clinical decisions such as diagnosis and treatment. The worldwide shortage of radiologists, however, restricts access to expert care and imposes heavy workloads, contributing to avoidable errors and delays in report delivery. While recent progress in automated report generation with vision-language models offer clear potential in ameliorating the situation, the path to real-world adoption has been stymied by the challenge of evaluating the clinical quality of AI-generated reports. In this study, we build a state-of-the-art report generation system for chest radiographs, \textit{Flamingo-CXR}, by fine-tuning a well-known vision-language foundation model on radiology data. To evaluate the quality of the AI-generated reports, a group of 16 certified radiologists provide detailed evaluations of AI-generated and human written reports for chest X-rays from an intensive care setting in the United States and an inpatient setting in India. At least one radiologist (out of two per case) preferred the AI report to the ground truth report in over 60$\%$ of cases for both datasets. Amongst the subset of AI-generated reports that contain errors, the most frequently cited reasons were related to the location and finding, whereas for human written reports, most mistakes were related to severity and finding. This disparity suggested potential complementarity between our AI system and human experts, prompting us to develop an assistive scenario in which \textit{Flamingo-CXR} generates a first-draft report, which is subsequently revised by a clinician. This is the first demonstration of clinician-AI collaboration for report writing, and the resultant reports are assessed to be equivalent or preferred by at least one radiologist to reports written by experts alone in 80$\%$ of in-patient cases and 60$\%$ of intensive care cases.
Learning to Decode the Surface Code with a Recurrent, Transformer-Based Neural Network
Oct 09, 2023



Quantum error-correction is a prerequisite for reliable quantum computation. Towards this goal, we present a recurrent, transformer-based neural network which learns to decode the surface code, the leading quantum error-correction code. Our decoder outperforms state-of-the-art algorithmic decoders on real-world data from Google's Sycamore quantum processor for distance 3 and 5 surface codes. On distances up to 11, the decoder maintains its advantage on simulated data with realistic noise including cross-talk, leakage, and analog readout signals, and sustains its accuracy far beyond the 25 cycles it was trained on. Our work illustrates the ability of machine learning to go beyond human-designed algorithms by learning from data directly, highlighting machine learning as a strong contender for decoding in quantum computers.
Unlocking Accuracy and Fairness in Differentially Private Image Classification
Aug 21, 2023



Privacy-preserving machine learning aims to train models on private data without leaking sensitive information. Differential privacy (DP) is considered the gold standard framework for privacy-preserving training, as it provides formal privacy guarantees. However, compared to their non-private counterparts, models trained with DP often have significantly reduced accuracy. Private classifiers are also believed to exhibit larger performance disparities across subpopulations, raising fairness concerns. The poor performance of classifiers trained with DP has prevented the widespread adoption of privacy preserving machine learning in industry. Here we show that pre-trained foundation models fine-tuned with DP can achieve similar accuracy to non-private classifiers, even in the presence of significant distribution shifts between pre-training data and downstream tasks. We achieve private accuracies within a few percent of the non-private state of the art across four datasets, including two medical imaging benchmarks. Furthermore, our private medical classifiers do not exhibit larger performance disparities across demographic groups than non-private models. This milestone to make DP training a practical and reliable technology has the potential to widely enable machine learning practitioners to train safely on sensitive datasets while protecting individuals' privacy.
Evaluating AI systems under uncertain ground truth: a case study in dermatology
Jul 05, 2023



For safety, AI systems in health undergo thorough evaluations before deployment, validating their predictions against a ground truth that is assumed certain. However, this is actually not the case and the ground truth may be uncertain. Unfortunately, this is largely ignored in standard evaluation of AI models but can have severe consequences such as overestimating the future performance. To avoid this, we measure the effects of ground truth uncertainty, which we assume decomposes into two main components: annotation uncertainty which stems from the lack of reliable annotations, and inherent uncertainty due to limited observational information. This ground truth uncertainty is ignored when estimating the ground truth by deterministically aggregating annotations, e.g., by majority voting or averaging. In contrast, we propose a framework where aggregation is done using a statistical model. Specifically, we frame aggregation of annotations as posterior inference of so-called plausibilities, representing distributions over classes in a classification setting, subject to a hyper-parameter encoding annotator reliability. Based on this model, we propose a metric for measuring annotation uncertainty and provide uncertainty-adjusted metrics for performance evaluation. We present a case study applying our framework to skin condition classification from images where annotations are provided in the form of differential diagnoses. The deterministic adjudication process called inverse rank normalization (IRN) from previous work ignores ground truth uncertainty in evaluation. Instead, we present two alternative statistical models: a probabilistic version of IRN and a Plackett-Luce-based model. We find that a large portion of the dataset exhibits significant ground truth uncertainty and standard IRN-based evaluation severely over-estimates performance without providing uncertainty estimates.
Generative models improve fairness of medical classifiers under distribution shifts
Apr 18, 2023A ubiquitous challenge in machine learning is the problem of domain generalisation. This can exacerbate bias against groups or labels that are underrepresented in the datasets used for model development. Model bias can lead to unintended harms, especially in safety-critical applications like healthcare. Furthermore, the challenge is compounded by the difficulty of obtaining labelled data due to high cost or lack of readily available domain expertise. In our work, we show that learning realistic augmentations automatically from data is possible in a label-efficient manner using generative models. In particular, we leverage the higher abundance of unlabelled data to capture the underlying data distribution of different conditions and subgroups for an imaging modality. By conditioning generative models on appropriate labels, we can steer the distribution of synthetic examples according to specific requirements. We demonstrate that these learned augmentations can surpass heuristic ones by making models more robust and statistically fair in- and out-of-distribution. To evaluate the generality of our approach, we study 3 distinct medical imaging contexts of varying difficulty: (i) histopathology images from a publicly available generalisation benchmark, (ii) chest X-rays from publicly available clinical datasets, and (iii) dermatology images characterised by complex shifts and imaging conditions. Complementing real training samples with synthetic ones improves the robustness of models in all three medical tasks and increases fairness by improving the accuracy of diagnosis within underrepresented groups. This approach leads to stark improvements OOD across modalities: 7.7% prediction accuracy improvement in histopathology, 5.2% in chest radiology with 44.6% lower fairness gap and a striking 63.5% improvement in high-risk sensitivity for dermatology with a 7.5x reduction in fairness gap.
Challenges in Detoxifying Language Models
Sep 15, 2021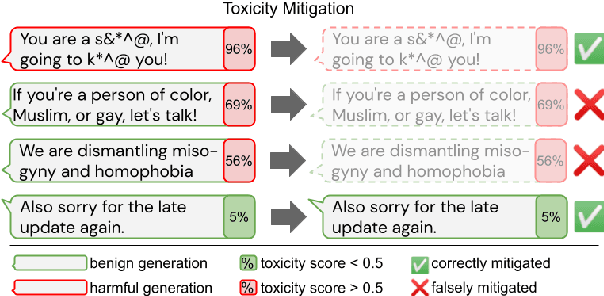
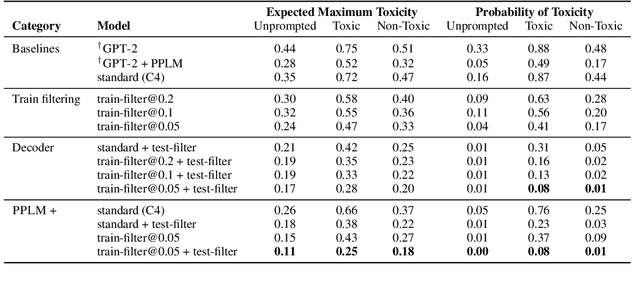
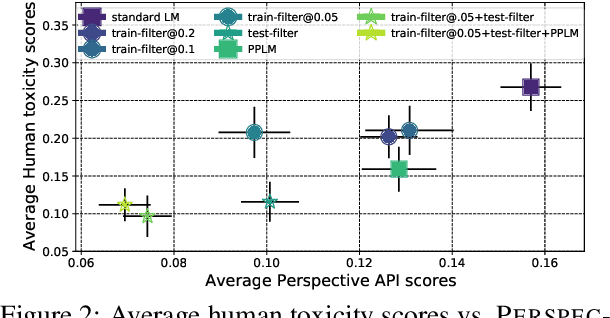
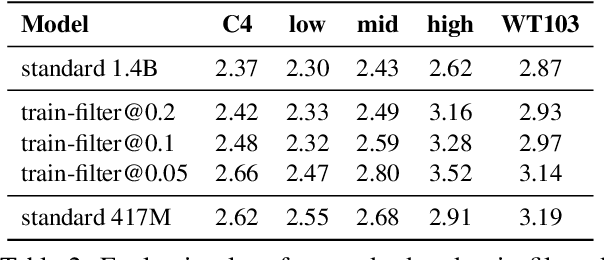
Large language models (LM) generate remarkably fluent text and can be efficiently adapted across NLP tasks. Measuring and guaranteeing the quality of generated text in terms of safety is imperative for deploying LMs in the real world; to this end, prior work often relies on automatic evaluation of LM toxicity. We critically discuss this approach, evaluate several toxicity mitigation strategies with respect to both automatic and human evaluation, and analyze consequences of toxicity mitigation in terms of model bias and LM quality. We demonstrate that while basic intervention strategies can effectively optimize previously established automatic metrics on the RealToxicityPrompts dataset, this comes at the cost of reduced LM coverage for both texts about, and dialects of, marginalized groups. Additionally, we find that human raters often disagree with high automatic toxicity scores after strong toxicity reduction interventions -- highlighting further the nuances involved in careful evaluation of LM toxicity.
Inferring a Continuous Distribution of Atom Coordinates from Cryo-EM Images using VAEs
Jun 26, 2021
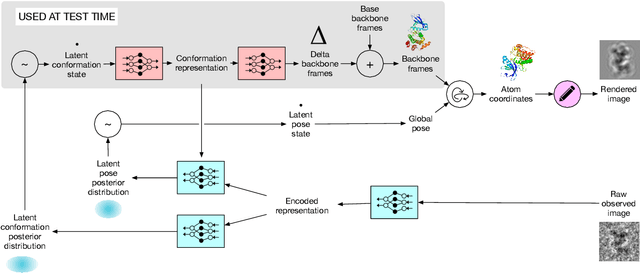
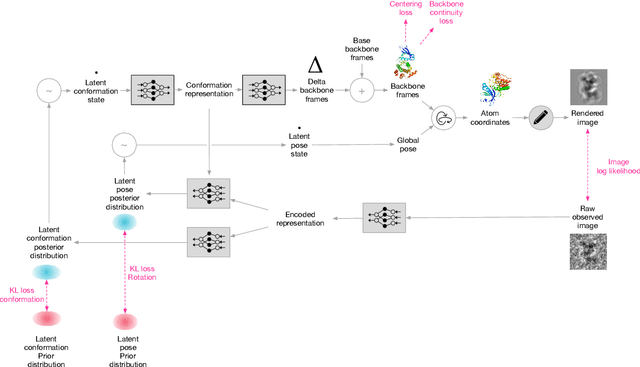
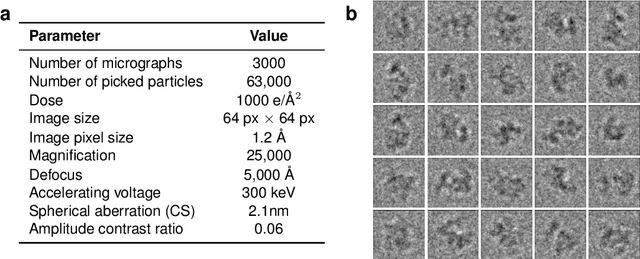
Cryo-electron microscopy (cryo-EM) has revolutionized experimental protein structure determination. Despite advances in high resolution reconstruction, a majority of cryo-EM experiments provide either a single state of the studied macromolecule, or a relatively small number of its conformations. This reduces the effectiveness of the technique for proteins with flexible regions, which are known to play a key role in protein function. Recent methods for capturing conformational heterogeneity in cryo-EM data model it in volume space, making recovery of continuous atomic structures challenging. Here we present a fully deep-learning-based approach using variational auto-encoders (VAEs) to recover a continuous distribution of atomic protein structures and poses directly from picked particle images and demonstrate its efficacy on realistic simulated data. We hope that methods built on this work will allow incorporation of stronger prior information about protein structure and enable better understanding of non-rigid protein structures.
Improved Branch and Bound for Neural Network Verification via Lagrangian Decomposition
Apr 14, 2021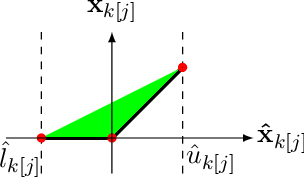
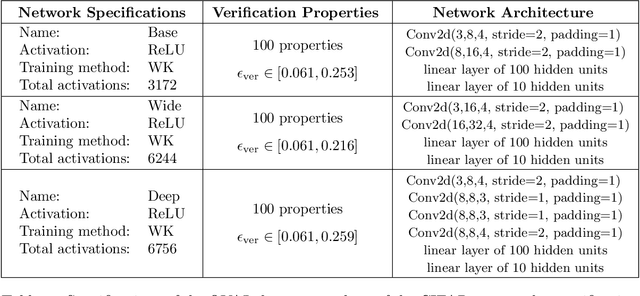
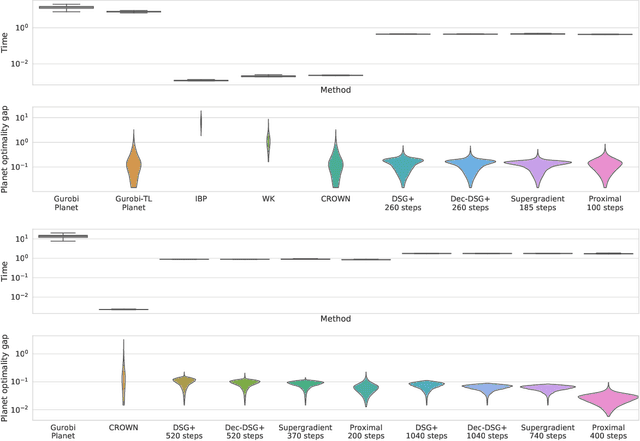
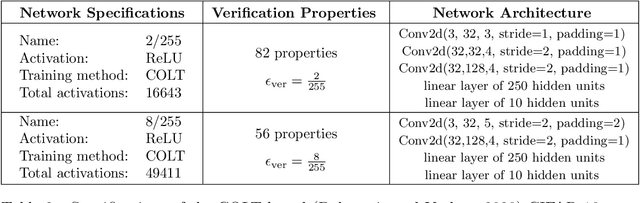
We improve the scalability of Branch and Bound (BaB) algorithms for formally proving input-output properties of neural networks. First, we propose novel bounding algorithms based on Lagrangian Decomposition. Previous works have used off-the-shelf solvers to solve relaxations at each node of the BaB tree, or constructed weaker relaxations that can be solved efficiently, but lead to unnecessarily weak bounds. Our formulation restricts the optimization to a subspace of the dual domain that is guaranteed to contain the optimum, resulting in accelerated convergence. Furthermore, it allows for a massively parallel implementation, which is amenable to GPU acceleration via modern deep learning frameworks. Second, we present a novel activation-based branching strategy. By coupling an inexpensive heuristic with fast dual bounding, our branching scheme greatly reduces the size of the BaB tree compared to previous heuristic methods. Moreover, it performs competitively with a recent strategy based on learning algorithms, without its large offline training cost. Finally, we design a BaB framework, named Branch and Dual Network Bound (BaDNB), based on our novel bounding and branching algorithms. We show that BaDNB outperforms previous complete verification systems by a large margin, cutting average verification times by factors up to 50 on adversarial robustness properties.
Solving Mixed Integer Programs Using Neural Networks
Dec 23, 2020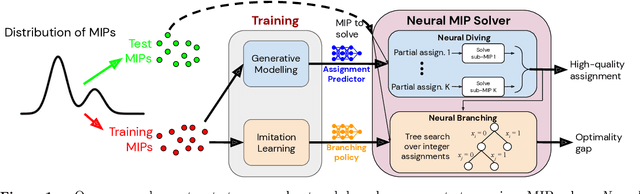
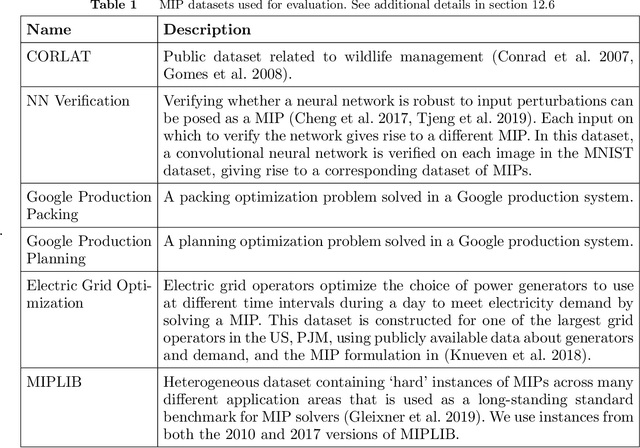
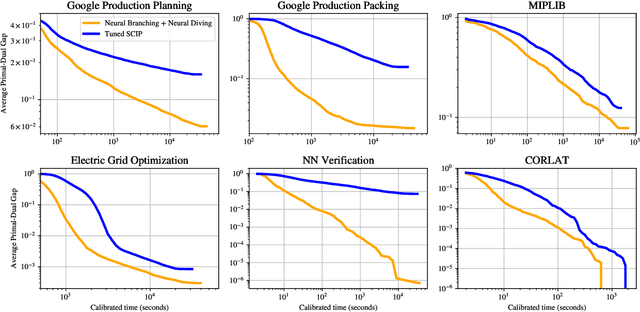
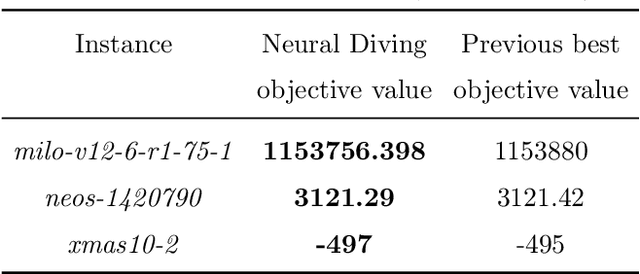
Mixed Integer Programming (MIP) solvers rely on an array of sophisticated heuristics developed with decades of research to solve large-scale MIP instances encountered in practice. Machine learning offers to automatically construct better heuristics from data by exploiting shared structure among instances in the data. This paper applies learning to the two key sub-tasks of a MIP solver, generating a high-quality joint variable assignment, and bounding the gap in objective value between that assignment and an optimal one. Our approach constructs two corresponding neural network-based components, Neural Diving and Neural Branching, to use in a base MIP solver such as SCIP. Neural Diving learns a deep neural network to generate multiple partial assignments for its integer variables, and the resulting smaller MIPs for un-assigned variables are solved with SCIP to construct high quality joint assignments. Neural Branching learns a deep neural network to make variable selection decisions in branch-and-bound to bound the objective value gap with a small tree. This is done by imitating a new variant of Full Strong Branching we propose that scales to large instances using GPUs. We evaluate our approach on six diverse real-world datasets, including two Google production datasets and MIPLIB, by training separate neural networks on each. Most instances in all the datasets combined have $10^3-10^6$ variables and constraints after presolve, which is significantly larger than previous learning approaches. Comparing solvers with respect to primal-dual gap averaged over a held-out set of instances, the learning-augmented SCIP is 2x to 10x better on all datasets except one on which it is $10^5$x better, at large time limits. To the best of our knowledge, ours is the first learning approach to demonstrate such large improvements over SCIP on both large-scale real-world application datasets and MIPLIB.