 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Pixels and Words: Mask-Aware Local Semantic Fusion for Multimodal Media Verification
Mar 27, 2026As multimodal misinformation becomes more sophisticated, its detection and grounding are crucial. However, current multimodal verification methods, relying on passive holistic fusion, struggle with sophisticated misinformation. Due to 'feature dilution,' global alignments tend to average out subtle local semantic inconsistencies, effectively masking the very conflicts they are designed to find. We introduce MaLSF (Mask-aware Local Semantic Fusion), a novel framework that shifts the paradigm to active, bidirectional verification, mimicking human cognitive cross-referencing. MaLSF utilizes mask-label pairs as semantic anchors to bridge pixels and words. Its core mechanism features two innovations: 1) a Bidirectional Cross-modal Verification (BCV) module that acts as an interrogator, using parallel query streams (Text-as-Query and Image-as-Query) to explicitly pinpoint conflicts; and 2) a Hierarchical Semantic Aggregation (HSA) module that intelligently aggregates these multi-granularity conflict signals for task-specific reasoning. In addition, to extract fine-grained mask-label pairs, we introduce a set of diverse mask-label pair extraction parsers. MaLSF achieves state-of-the-art performance on both the DGM4 and multimodal fake news detection tasks. Extensive ablation studies and visualization results further verify its effectiveness and interpretability.
LifeBench: A Benchmark for Long-Horizon Multi-Source Memory
Mar 04, 2026Long-term memory is fundamental for personalized agents capable of accumulating knowledge, reasoning over user experiences, and adapting across time. However, existing memory benchmarks primarily target declarative memory, specifically semantic and episodic types, where all information is explicitly presented in dialogues. In contrast, real-world actions are also governed by non-declarative memory, including habitual and procedural types, and need to be inferred from diverse digital traces. To bridge this gap, we introduce Lifebench, which features densely connected, long-horizon event simulation. It pushes AI agents beyond simple recall, requiring the integration of declarative and non-declarative memory reasoning across diverse and temporally extended contexts. Building such a benchmark presents two key challenges: ensuring data quality and scalability. We maintain data quality by employing real-world priors, including anonymized social surveys, map APIs, and holiday-integrated calendars, thus enforcing fidelity, diversity and behavioral rationality within the dataset. Towards scalability, we draw inspiration from cognitive science and structure events according to their partonomic hierarchy; enabling efficient parallel generation while maintaining global coherence. Performance results show that top-tier, state-of-the-art memory systems reach just 55.2\% accuracy, highlighting the inherent difficulty of long-horizon retrieval and multi-source integration within our proposed benchmark. The dataset and data synthesis code are available at https://github.com/1754955896/LifeBench.
STCOcc: Sparse Spatial-Temporal Cascade Renovation for 3D Occupancy and Scene Flow Prediction
Apr 28, 2025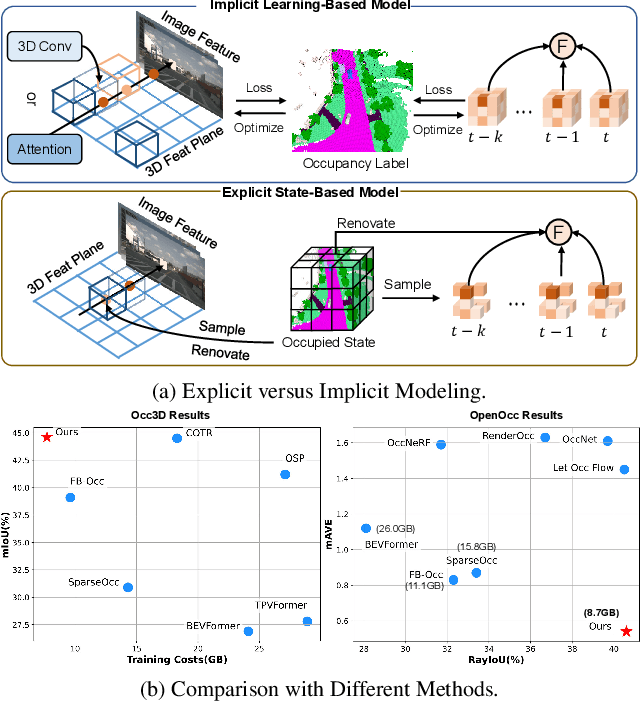
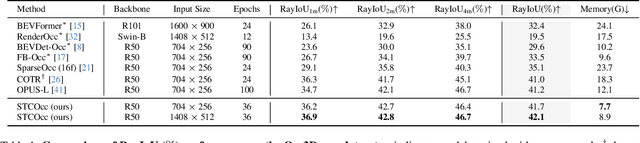
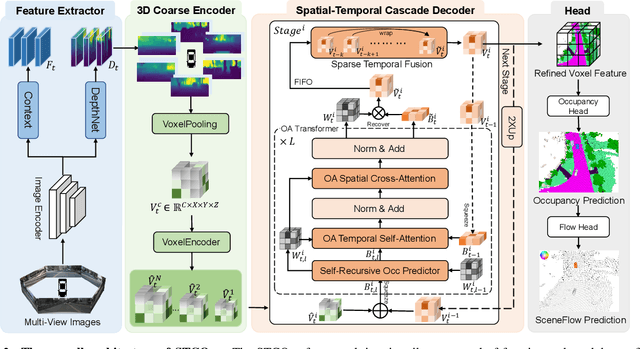
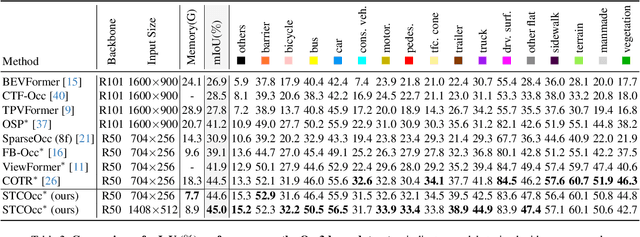
3D occupancy and scene flow offer a detailed and dynamic representation of 3D scene. Recognizing the sparsity and complexity of 3D space, previous vision-centric methods have employed implicit learning-based approaches to model spatial and temporal information. However, these approaches struggle to capture local details and diminish the model's spatial discriminative ability. To address these challenges, we propose a novel explicit state-based modeling method designed to leverage the occupied state to renovate the 3D features. Specifically, we propose a sparse occlusion-aware attention mechanism, integrated with a cascade refinement strategy, which accurately renovates 3D features with the guidance of occupied state information. Additionally, we introduce a novel method for modeling long-term dynamic interactions, which reduces computational costs and preserves spatial information. Compared to the previous state-of-the-art methods, our efficient explicit renovation strategy not only delivers superior performance in terms of RayIoU and mAVE for occupancy and scene flow prediction but also markedly reduces GPU memory usage during training, bringing it down to 8.7GB. Our code is available on https://github.com/lzzzzzm/STCOcc
Task-Driven Exploration: Decoupling and Inter-Task Feedback for Joint Moment Retrieval and Highlight Detection
Apr 14, 2024



Video moment retrieval and highlight detection are two highly valuable tasks in video understanding, but until recently they have been jointly studied. Although existing studies have made impressive advancement recently, they predominantly follow the data-driven bottom-up paradigm. Such paradigm overlooks task-specific and inter-task effects, resulting in poor model performance. In this paper, we propose a novel task-driven top-down framework TaskWeave for joint moment retrieval and highlight detection. The framework introduces a task-decoupled unit to capture task-specific and common representations. To investigate the interplay between the two tasks, we propose an inter-task feedback mechanism, which transforms the results of one task as guiding masks to assist the other task. Different from existing methods, we present a task-dependent joint loss function to optimize the model. Comprehensive experiments and in-depth ablation studies on QVHighlights, TVSum, and Charades-STA datasets corroborate the effectiveness and flexibility of the proposed framework. Codes are available at https://github.com/EdenGabriel/TaskWeave.