 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Who Said What to Who They Are: Modular Training-free Identity-Aware LLM Refinement of Speaker Diarization
Sep 18, 2025Speaker diarization (SD) struggles in real-world scenarios due to dynamic environments and unknown speaker counts. SD is rarely used alone and is often paired with automatic speech recognition (ASR), but non-modular methods that jointly train on domain-specific data have limited flexibility. Moreover, many applications require true speaker identities rather than SD's pseudo labels. We propose a training-free modular pipeline combining off-the-shelf SD, ASR, and a large language model (LLM) to determine who spoke, what was said, and who they are. Using structured LLM prompting on reconciled SD and ASR outputs, our method leverages semantic continuity in conversational context to refine low-confidence speaker labels and assigns role identities while correcting split speakers. On a real-world patient-clinician dataset, our approach achieves a 29.7% relative error reduction over baseline reconciled SD and ASR. It enhances diarization performance without additional training and delivers a complete pipeline for SD, ASR, and speaker identity detection in practical applications.
Read to Hear: A Zero-Shot Pronunciation Assessment Using Textual Descriptions and LLMs
Sep 17, 2025Automatic pronunciation assessment is typically performed by acoustic models trained on audio-score pairs. Although effective, these systems provide only numerical scores, without the information needed to help learners understand their errors. Meanwhile, large language models (LLMs) have proven effective in supporting language learning, but their potential for assessing pronunciation remains unexplored. In this work, we introduce TextPA, a zero-shot, Textual description-based Pronunciation Assessment approach. TextPA utilizes human-readable representations of speech signals, which are fed into an LLM to assess pronunciation accuracy and fluency, while also providing reasoning behind the assigned scores. Finally, a phoneme sequence match scoring method is used to refine the accuracy scores. Our work highlights a previously overlooked direction for pronunciation assessment. Instead of relying on supervised training with audio-score examples, we exploit the rich pronunciation knowledge embedded in written text. Experimental results show that our approach is both cost-efficient and competitive in performance. Furthermore, TextPA significantly improves the performance of conventional audio-score-trained models on out-of-domain data by offering a complementary perspective.
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Jun 18, 2024Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
Exploring Robustness in Doctor-Patient Conversation Summarization: An Analysis of Out-of-Domain SOAP Notes
Jun 05, 2024Summarizing medical conversations poses unique challenges due to the specialized domain and the difficulty of collecting in-domain training data. In this study, we investigate the performance of state-of-the-art doctor-patient conversation generative summarization models on the out-of-domain data. We divide the summarization model of doctor-patient conversation into two configurations: (1) a general model, without specifying subjective (S), objective (O), and assessment (A) and plan (P) notes; (2) a SOAP-oriented model that generates a summary with SOAP sections. We analyzed the limitations and strengths of the fine-tuning language model-based methods and GPTs on both configurations. We also conducted a Linguistic Inquiry and Word Count analysis to compare the SOAP notes from different datasets. The results exhibit a strong correlation for reference notes across different datasets, indicating that format mismatch (i.e., discrepancies in word distribution) is not the main cause of performance decline on out-of-domain data. Lastly, a detailed analysis of SOAP notes is included to provide insights into missing information and hallucinations introduced by the models.
A Study on Incorporating Whisper for Robust Speech Assessment
Sep 22, 2023



This research introduces an enhanced version of the multi-objective speech assessment model, called MOSA-Net+, by leveraging the acoustic features from large pre-trained weakly supervised models, namely Whisper, to create embedding features. The first part of this study investigates the correlation between the embedding features of Whisper and two self-supervised learning (SSL) models with subjective quality and intelligibility scores. The second part evaluates the effectiveness of Whisper in deploying a more robust speech assessment model. Third, the possibility of combining representations from Whisper and SSL models while deploying MOSA-Net+ is analyzed. The experimental results reveal that Whisper's embedding features correlate more strongly with subjective quality and intelligibility than other SSL's embedding features, contributing to more accurate prediction performance achieved by MOSA-Net+. Moreover, combining the embedding features from Whisper and SSL models only leads to marginal improvement. As compared to MOSA-Net and other SSL-based speech assessment models, MOSA-Net+ yields notable improvements in estimating subjective quality and intelligibility scores across all evaluation metrics. We further tested MOSA-Net+ on Track 3 of the VoiceMOS Challenge 2023 and obtained the top-ranked performance.
Noise robust speech emotion recognition with signal-to-noise ratio adapting speech enhancement
Sep 03, 2023



Speech emotion recognition (SER) often experiences reduced performance due to background noise. In addition, making a prediction on signals with only background noise could undermine user trust in the system. In this study, we propose a Noise Robust Speech Emotion Recognition system, NRSER. NRSER employs speech enhancement (SE) to effectively reduce the noise in input signals. Then, the signal-to-noise-ratio (SNR)-level detection structure and waveform reconstitution strategy are introduced to reduce the negative impact of SE on speech signals with no or little background noise. Our experimental results show that NRSER can effectively improve the noise robustness of the SER system, including preventing the system from making emotion recognition on signals consisting solely of background noise. Moreover, the proposed SNR-level detection structure can be used individually for tasks such as data selection.
MultiPA: a multi-task speech pronunciation assessment system for a closed and open response scenario
Aug 24, 2023



The design of automatic speech pronunciation assessment can be categorized into closed and open response scenarios, each with strengths and limitations. A system with the ability to function in both scenarios can cater to diverse learning needs and provide a more precise and holistic assessment of pronunciation skills. In this study, we propose a Multi-task Pronunciation Assessment model called MultiPA. MultiPA provides an alternative to Kaldi-based systems in that it has simpler format requirements and better compatibility with other neural network models. Compared with previous open response systems, MultiPA provides a wider range of evaluations, encompassing assessments at both the sentence and word-level. Our experimental results show that MultiPA achieves comparable performance when working in closed response scenarios and maintains more robust performance when directly used for open responses.
Investigation of Factorized Optical Flows as Mid-Level Representations
Mar 10, 2022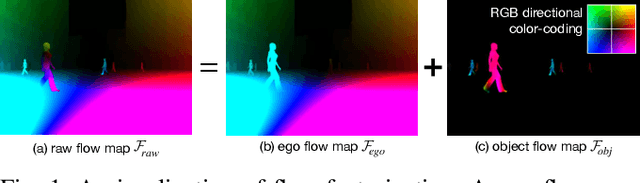
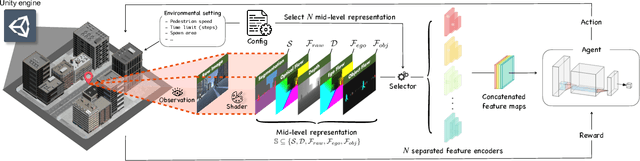
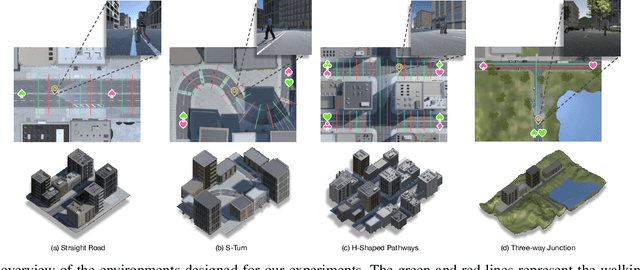
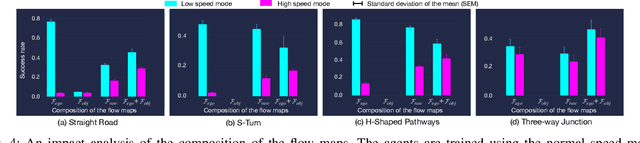
In this paper, we introduce a new concept of incorporating factorized flow maps as mid-level representations, for bridging the perception and the control modules in modular learning based robotic frameworks. To investigate the advantages of factorized flow maps and examine their interplay with the other types of mid-level representations, we further develop a configurable framework, along with four different environments that contain both static and dynamic objects, for analyzing the impacts of factorized optical flow maps on the performance of deep reinforcement learning agents. Based on this framework, we report our experimental results on various scenarios, and offer a set of analyses to justify our hypothesis. Finally, we validate flow factorization in real world scenarios.
InQSS: a speech intelligibility assessment model using a multi-task learning network
Nov 04, 2021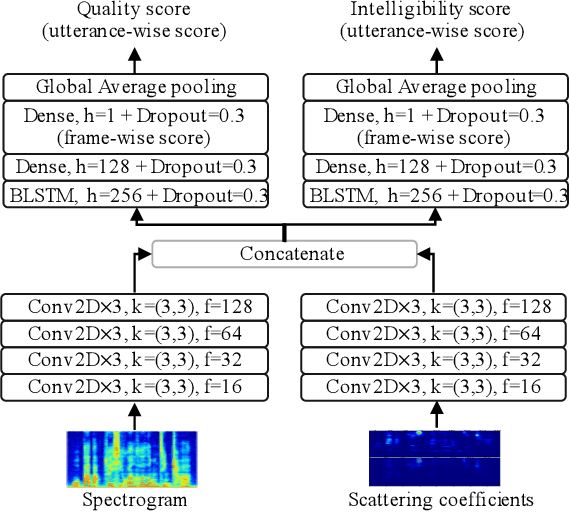
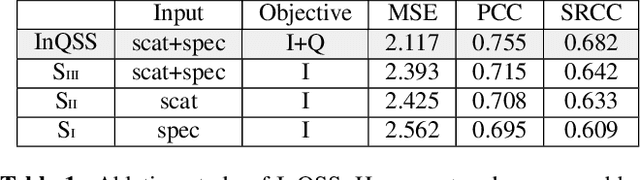
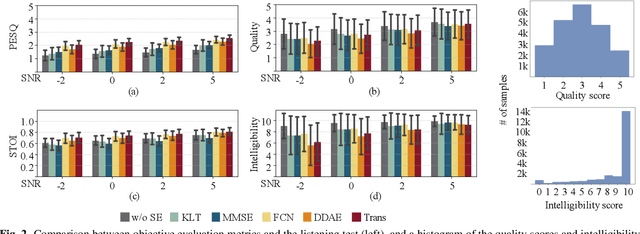
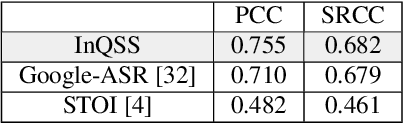
Speech intelligibility assessment models are essential tools for researchers to evaluate and improve speech processing models. In this study, we propose InQSS, a speech intelligibility assessment model that uses both spectrogram and scattering coefficients as input features. In addition, InQSS uses a multi-task learning network in which quality scores can guide the training of the speech intelligibility assessment. The resulting model can predict not only the intelligibility scores but also the quality scores of a speech. The experimental results confirm that the scattering coefficients and quality scores are informative for intelligibility. Moreover, we released TMHINT-QI, which is a Chinese speech dataset that records the quality and intelligibility scores of clean, noisy, and enhanced speech.
The AS-NU System for the M2VoC Challenge
Apr 07, 2021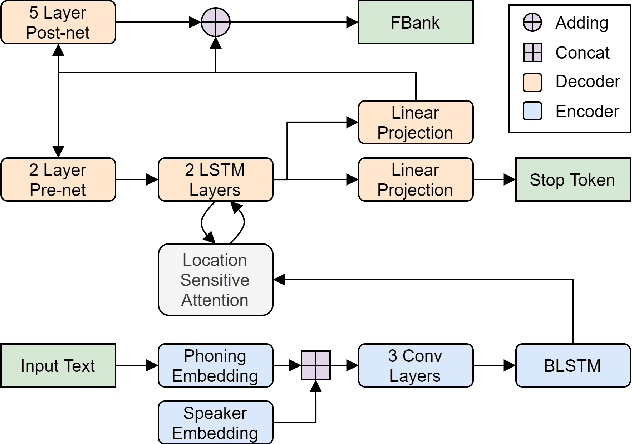
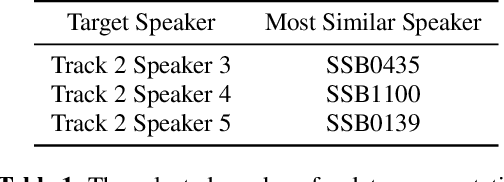
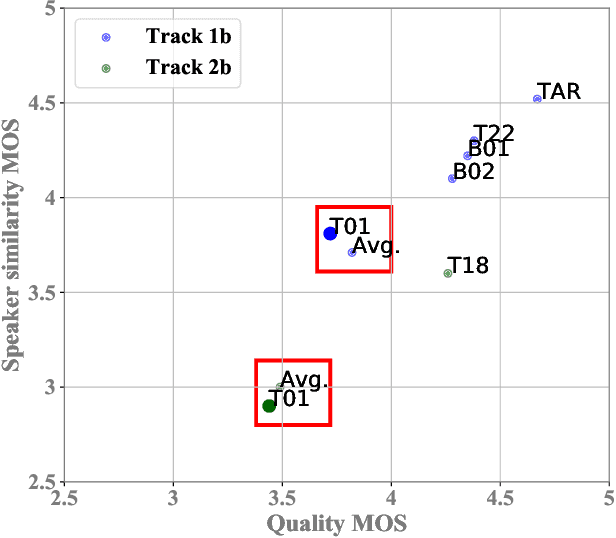
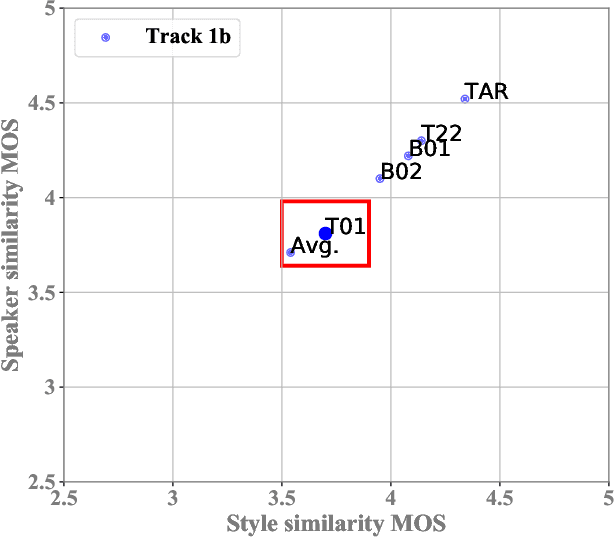
This paper describes the AS-NU systems for two tracks in MultiSpeaker Multi-Style Voice Cloning Challenge (M2VoC). The first track focuses on using a small number of 100 target utterances for voice cloning, while the second track focuses on using only 5 target utterances for voice cloning. Due to the serious lack of data in the second track, we selected the speaker most similar to the target speaker from the training data of the TTS system, and used the speaker's utterances and the given 5 target utterances to fine-tune our model. The evaluation results show that our systems on the two tracks perform similarly in terms of quality, but there is still a clear gap between the similarity score of the second track and the similarity score of the first track.