 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Sketch & Fill: Multiclass Sketch-to-Image Translation
Sep 25, 2019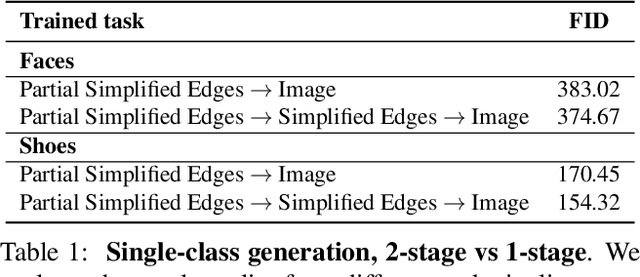


We propose an interactive GAN-based sketch-to-image translation method that helps novice users create images of simple objects. As the user starts to draw a sketch of a desired object type, the network interactively recommends plausible completions, and shows a corresponding synthesized image to the user. This enables a feedback loop, where the user can edit their sketch based on the network's recommendations, visualizing both the completed shape and final rendered image while they draw. In order to use a single trained model across a wide array of object classes, we introduce a gating-based approach for class conditioning, which allows us to generate distinct classes without feature mixing, from a single generator network. Video available at our website: https://arnabgho.github.io/iSketchNFill/.
Controllable Text-to-Image Generation
Sep 16, 2019

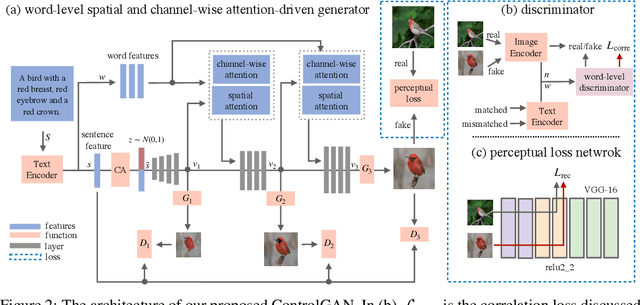
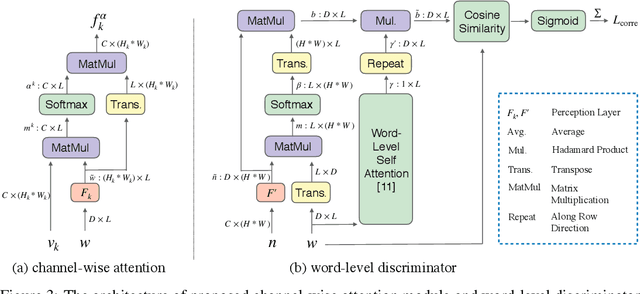
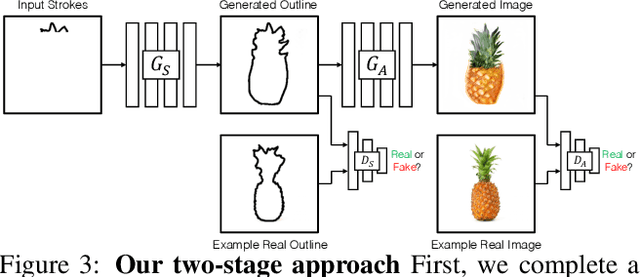
In this paper, we propose a novel controllable text-to-image generative adversarial network (ControlGAN), which can effectively synthesise high-quality images and also control parts of the image generation according to natural language descriptions. To achieve this, we introduce a word-level spatial and channel-wise attention-driven generator that can disentangle different visual attributes, and allow the model to focus on generating and manipulating subregions corresponding to the most relevant words. Also, a word-level discriminator is proposed to provide fine-grained supervisory feedback by correlating words with image regions, facilitating training an effective generator which is able to manipulate specific visual attributes without affecting the generation of other contents. Furthermore, perceptual loss is adopted to reduce the randomness involved in the image generation, and to encourage the generator to manipulate specific attributes required in the modified text. Extensive experiments on benchmark datasets demonstrate that our method outperforms existing state of the art, and is able to effectively manipulate synthetic images using natural language descriptions.
Branch and Bound for Piecewise Linear Neural Network Verification
Sep 14, 2019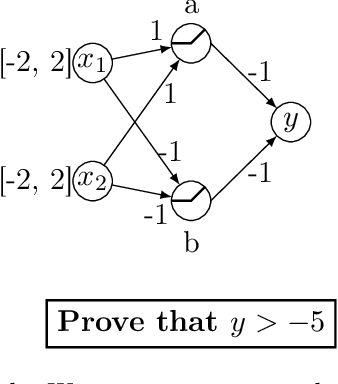
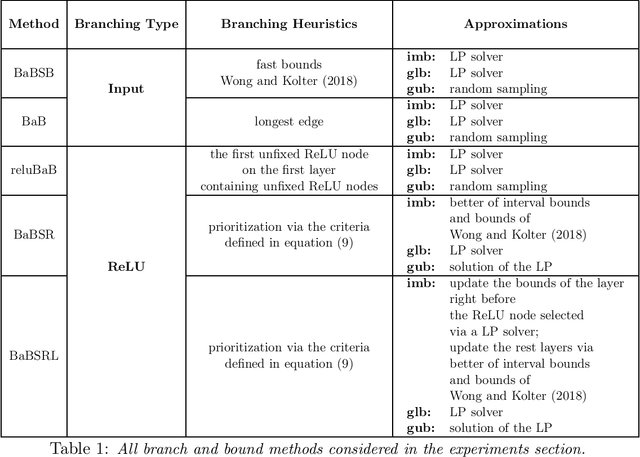
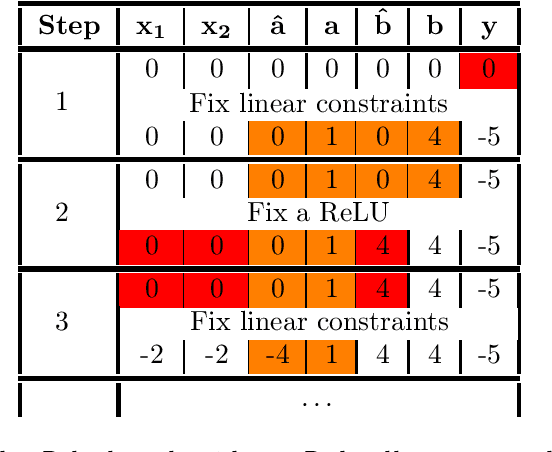
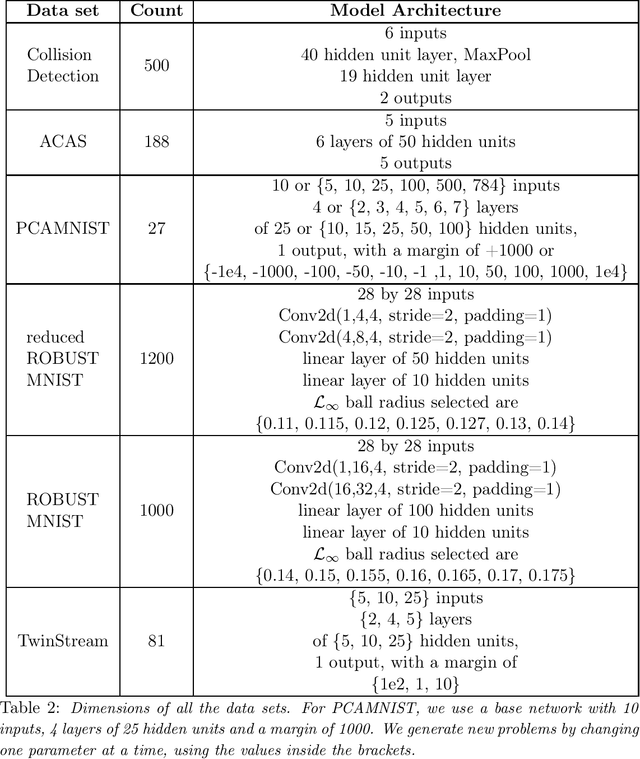
The success of Deep Learning and its potential use in many safety-critical applications has motivated research on formal verification of Neural Network (NN) models. In this context, verification means verifying whether a NN model satisfies certain input-output properties. Despite the reputation of learned NN models as black boxes, and the theoretical hardness of proving useful properties about them, researchers have been successful in verifying some classes of models by exploiting their piecewise linear structure and taking insights from formal methods such as Satisifiability Modulo Theory. However, these methods are still far from scaling to realistic neural networks. To facilitate progress on this crucial area, we make two key contributions. First, we present a unified framework based on branch and bound that encompasses previous methods. This analysis results in the identification of new methods that combine the strengths of multiple existing approaches, accomplishing a speedup of two orders of magnitude compared to the previous state of the art. Second, we propose a new data set of benchmarks which includes a collection of previously released test cases. We use the benchmark to provide a thorough experimental comparison of existing algorithms and identify the factors impacting the hardness of verification problems.
Dual Graph Convolutional Network for Semantic Segmentation
Sep 13, 2019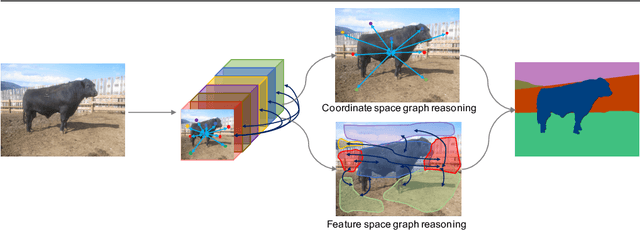

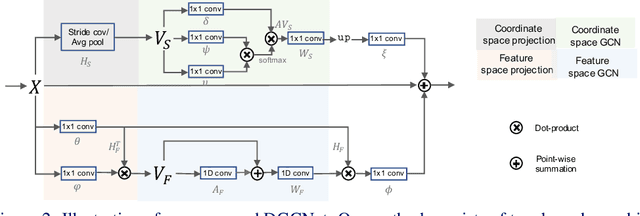

Exploiting long-range contextual information is key for pixel-wise prediction tasks such as semantic segmentation. In contrast to previous work that uses multi-scale feature fusion or dilated convolutions, we propose a novel graph-convolutional network (GCN) to address this problem. Our Dual Graph Convolutional Network (DGCNet) models the global context of the input feature by modelling two orthogonal graphs in a single framework. The first component models spatial relationships between pixels in the image, whilst the second models interdependencies along the channel dimensions of the network's feature map. This is done efficiently by projecting the feature into a new, lower-dimensional space where all pairwise interactions can be modelled, before reprojecting into the original space. Our simple method provides substantial benefits over a strong baseline and achieves state-of-the-art results on both Cityscapes (82.0\% mean IoU) and Pascal Context (53.7\% mean IoU) datasets.
Dynamic Graph Message Passing Networks
Aug 19, 2019
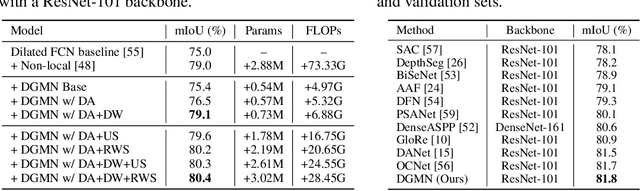
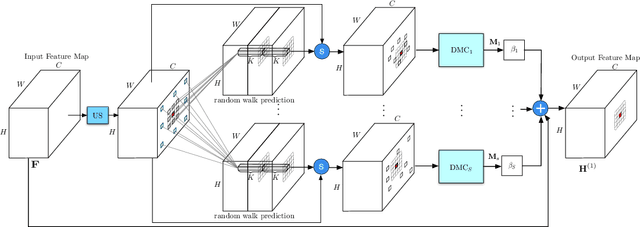
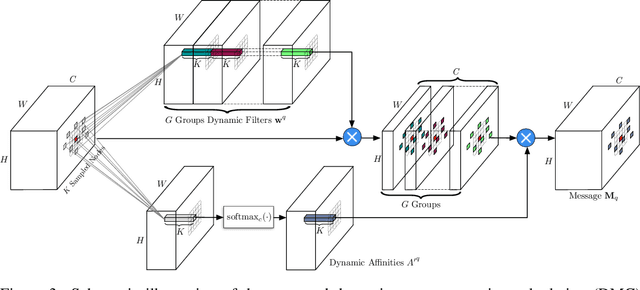
Modelling long-range dependencies is critical for complex scene understanding tasks such as semantic segmentation and object detection. Although CNNs have excelled in many computer vision tasks, they are still limited in capturing long-range structured relationships as they typically consist of layers of local kernels. A fully-connected graph is beneficial for such modelling, however, its computational overhead is prohibitive. We propose a dynamic graph message passing network, based on the message passing neural network framework, that significantly reduces the computational complexity compared to related works modelling a fully-connected graph. This is achieved by adaptively sampling nodes in the graph, conditioned on the input, for message passing. Based on the sampled nodes, we then dynamically predict node-dependent filter weights and the affinity matrix for propagating information between them. Using this model, we show significant improvements with respect to strong, state-of-the-art baselines on three different tasks and backbone architectures. Our approach also outperforms fully-connected graphs while using substantially fewer floating point operations and parameters.
Real-Time Highly Accurate Dense Depth on a Power Budget using an FPGA-CPU Hybrid SoC
Jul 17, 2019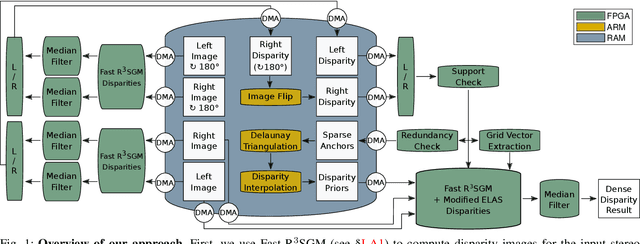
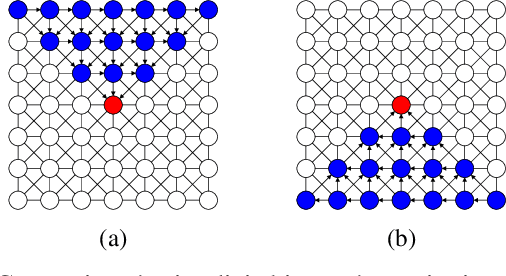
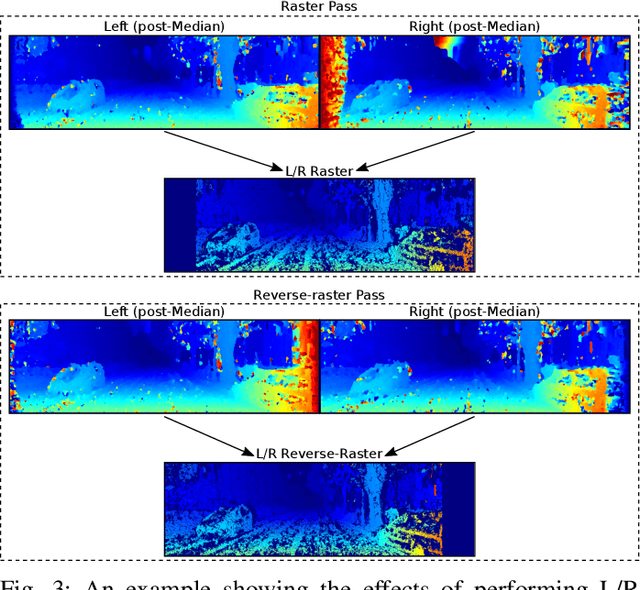
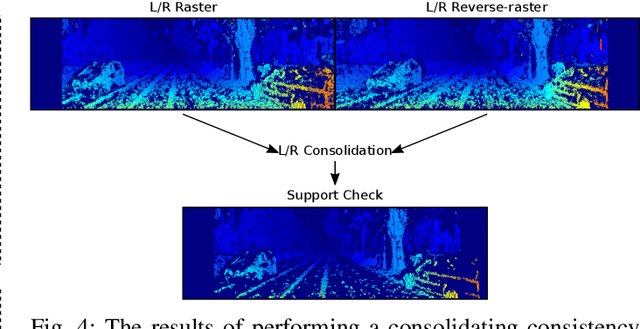
Obtaining highly accurate depth from stereo images in real time has many applications across computer vision and robotics, but in some contexts, upper bounds on power consumption constrain the feasible hardware to embedded platforms such as FPGAs. Whilst various stereo algorithms have been deployed on these platforms, usually cut down to better match the embedded architecture, certain key parts of the more advanced algorithms, e.g. those that rely on unpredictable access to memory or are highly iterative in nature, are difficult to deploy efficiently on FPGAs, and thus the depth quality that can be achieved is limited. In this paper, we leverage a FPGA-CPU chip to propose a novel, sophisticated, stereo approach that combines the best features of SGM and ELAS-based methods to compute highly accurate dense depth in real time. Our approach achieves an 8.7% error rate on the challenging KITTI 2015 dataset at over 50 FPS, with a power consumption of only 5W.
* 6 pages, 7 figures, 2 tables, journal
A Signal Propagation Perspective for Pruning Neural Networks at Initialization
Jun 14, 2019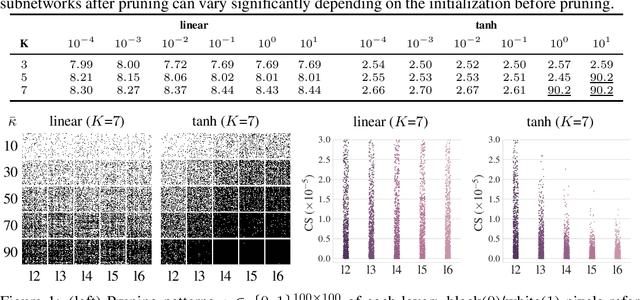
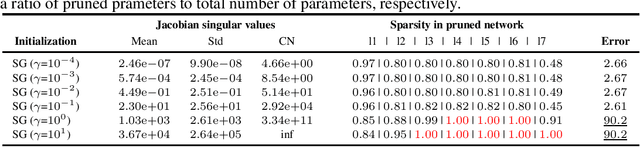
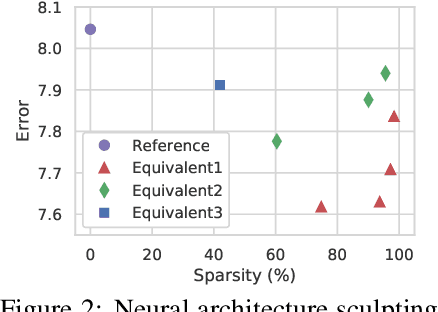
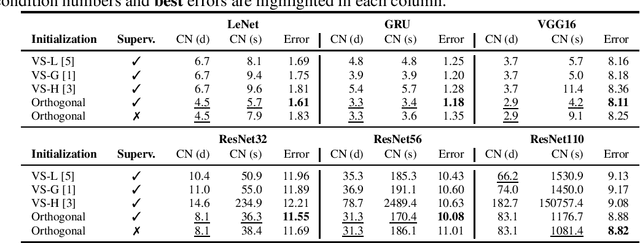
Network pruning is a promising avenue for compressing deep neural networks. A typical approach to pruning starts by training a model and removing unnecessary parameters while minimizing the impact on what is learned. Alternatively, a recent approach shows that pruning can be done at initialization prior to training. However, it remains unclear exactly why pruning an untrained, randomly initialized neural network is effective. In this work, we consider the pruning problem from a signal propagation perspective, formally characterizing initialization conditions that ensure faithful signal propagation throughout a network. Based on singular values of a network's input-output Jacobian, we find that orthogonal initialization enables more faithful signal propagation compared to other initialization schemes, thereby enhancing pruning results on a range of modern architectures and datasets. Also, we empirically study the effect of supervision for pruning at initialization, and show that often unsupervised pruning can be as effective as the supervised pruning. Furthermore, we demonstrate that our signal propagation perspective, combined with unsupervised pruning, can indeed be useful in various scenarios where pruning is applied to non-standard arbitrarily-designed architectures.
Stable Rank Normalization for Improved Generalization in Neural Networks and GANs
Jun 12, 2019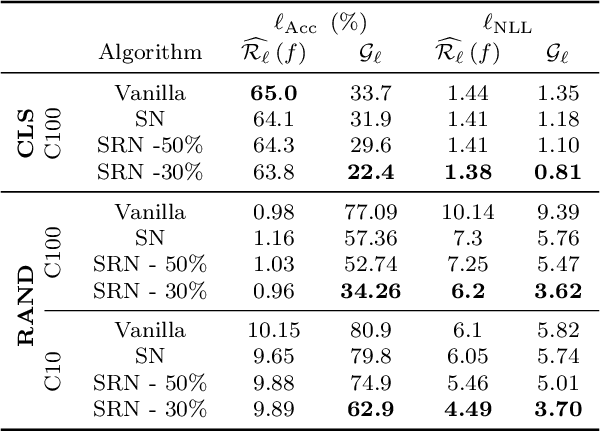
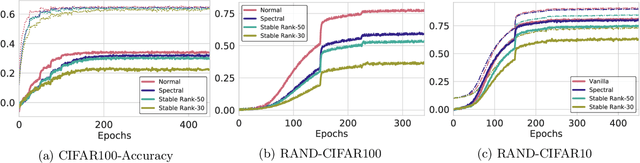
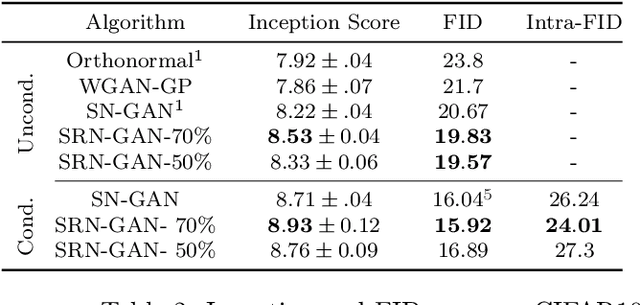
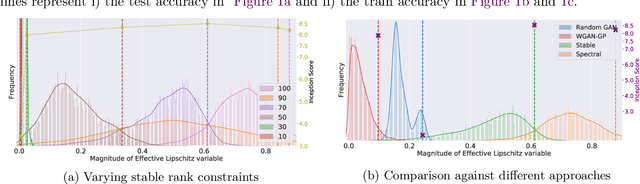
Exciting new work on the generalization bounds for neural networks (NN) given by Neyshabur et al. , Bartlett et al. closely depend on two parameter-depenedent quantities: the Lipschitz constant upper-bound and the stable rank (a softer version of the rank operator). This leads to an interesting question of whether controlling these quantities might improve the generalization behaviour of NNs. To this end, we propose stable rank normalization (SRN), a novel, optimal, and computationally efficient weight-normalization scheme which minimizes the stable rank of a linear operator. Surprisingly we find that SRN, inspite of being non-convex problem, can be shown to have a unique optimal solution. Moreover, we show that SRN allows control of the data-dependent empirical Lipschitz constant, which in contrast to the Lipschitz upper-bound, reflects the true behaviour of a model on a given dataset. We provide thorough analyses to show that SRN, when applied to the linear layers of a NN for classification, provides striking improvements-11.3% on the generalization gap compared to the standard NN along with significant reduction in memorization. When applied to the discriminator of GANs (called SRN-GAN) it improves Inception, FID, and Neural divergence scores on the CIFAR 10/100 and CelebA datasets, while learning mappings with low empirical Lipschitz constants.
Hijacking Malaria Simulators with Probabilistic Programming
May 29, 2019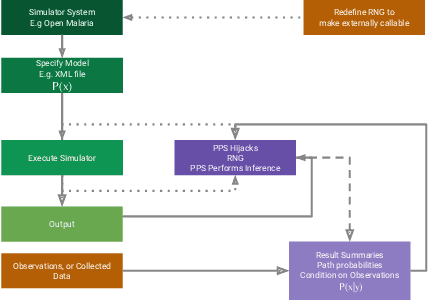
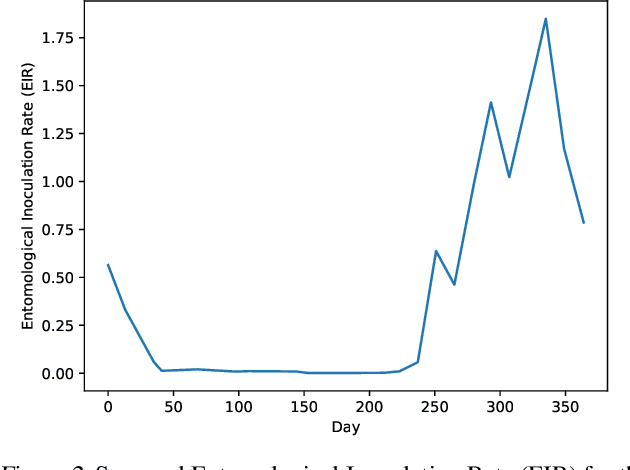

Epidemiology simulations have become a fundamental tool in the fight against the epidemics of various infectious diseases like AIDS and malaria. However, the complicated and stochastic nature of these simulators can mean their output is difficult to interpret, which reduces their usefulness to policymakers. In this paper, we introduce an approach that allows one to treat a large class of population-based epidemiology simulators as probabilistic generative models. This is achieved by hijacking the internal random number generator calls, through the use of a universal probabilistic programming system (PPS). In contrast to other methods, our approach can be easily retrofitted to simulators written in popular industrial programming frameworks. We demonstrate that our method can be used for interpretable introspection and inference, thus shedding light on black-box simulators. This reinstates much-needed trust between policymakers and evidence-based methods.
* 6 pages, 3 figures, Accepted at the International Conference on Machine Learning AI for Social Good Workshop, Long Beach, United States, 2019
Straight to Shapes++: Real-time Instance Segmentation Made More Accurate
May 27, 2019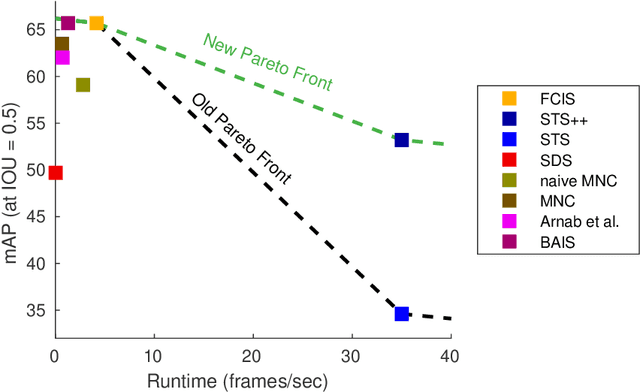
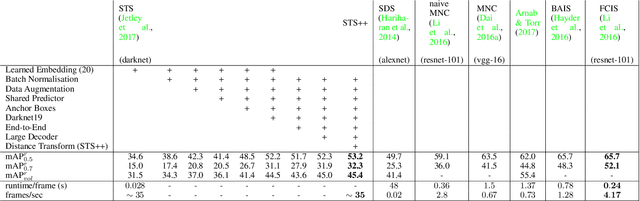
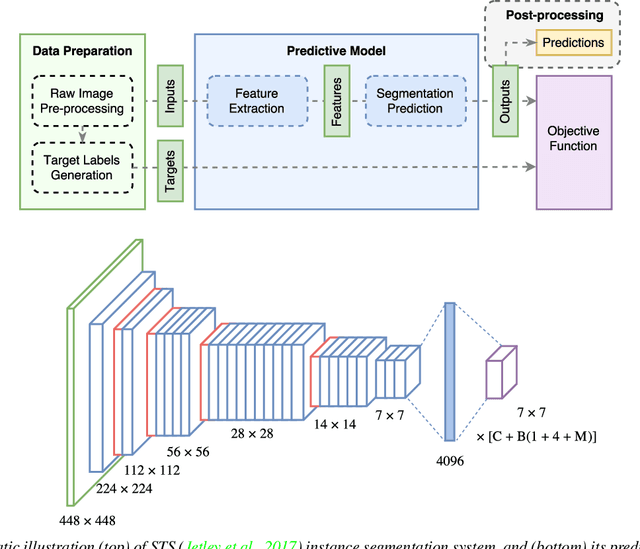
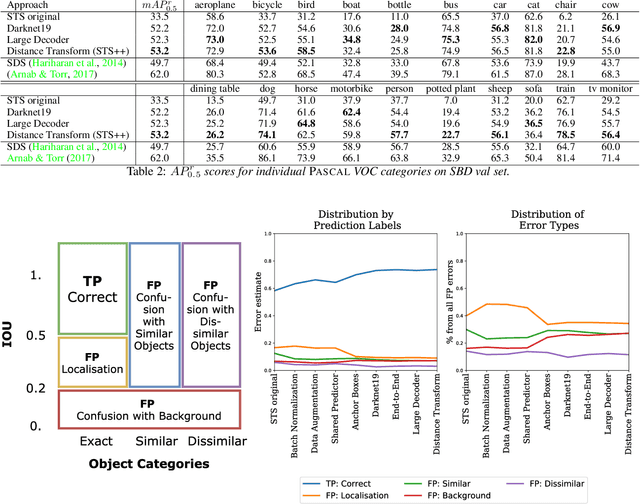
Instance segmentation is an important problem in computer vision, with applications in autonomous driving, drone navigation and robotic manipulation. However, most existing methods are not real-time, complicating their deployment in time-sensitive contexts. In this work, we extend an existing approach to real-time instance segmentation, called `Straight to Shapes' (STS), which makes use of low-dimensional shape embedding spaces to directly regress to object shape masks. The STS model can run at 35 FPS on a high-end desktop, but its accuracy is significantly worse than that of offline state-of-the-art methods. We leverage recent advances in the design and training of deep instance segmentation models to improve the performance accuracy of the STS model whilst keeping its real-time capabilities intact. In particular, we find that parameter sharing, more aggressive data augmentation and the use of structured loss for shape mask prediction all provide a useful boost to the network performance. Our proposed approach, `Straight to Shapes++', achieves a remarkable 19.7 point improvement in mAP (at IOU of 0.5) over the original method as evaluated on the PASCAL VOC dataset, thus redefining the accuracy frontier at real-time speeds. Since the accuracy of instance segmentation is closely tied to that of object bounding box prediction, we also study the error profile of the latter and examine the failure modes of our method for future improvements.