 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Minimization of Higher Order Submodular Functions using Monotonic Boolean Functions
Jan 23, 2017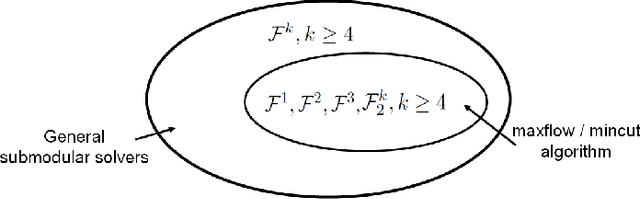
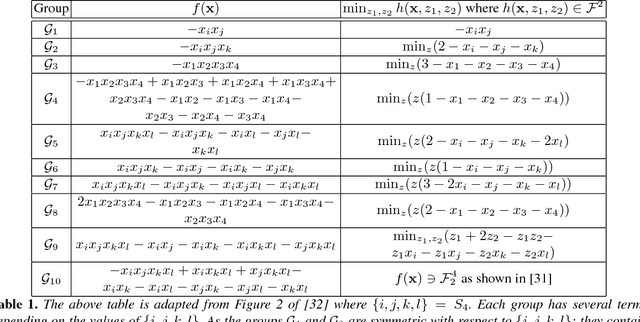

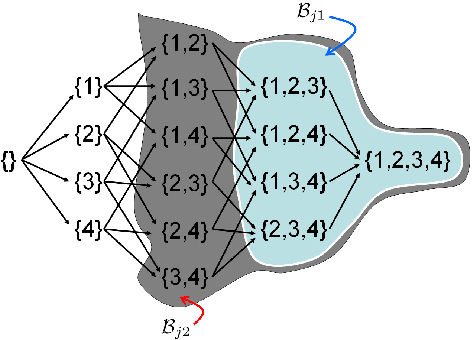
Submodular function minimization is a key problem in a wide variety of applications in machine learning, economics, game theory, computer vision, and many others. The general solver has a complexity of $O(n^3 \log^2 n . E +n^4 {\log}^{O(1)} n)$ where $E$ is the time required to evaluate the function and $n$ is the number of variables \cite{Lee2015}. On the other hand, many computer vision and machine learning problems are defined over special subclasses of submodular functions that can be written as the sum of many submodular cost functions defined over cliques containing few variables. In such functions, the pseudo-Boolean (or polynomial) representation \cite{BorosH02} of these subclasses are of degree (or order, or clique size) $k$ where $k \ll n$. In this work, we develop efficient algorithms for the minimization of this useful subclass of submodular functions. To do this, we define novel mapping that transform submodular functions of order $k$ into quadratic ones. The underlying idea is to use auxiliary variables to model the higher order terms and the transformation is found using a carefully constructed linear program. In particular, we model the auxiliary variables as monotonic Boolean functions, allowing us to obtain a compact transformation using as few auxiliary variables as possible.
ROAM: a Rich Object Appearance Model with Application to Rotoscoping
Dec 05, 2016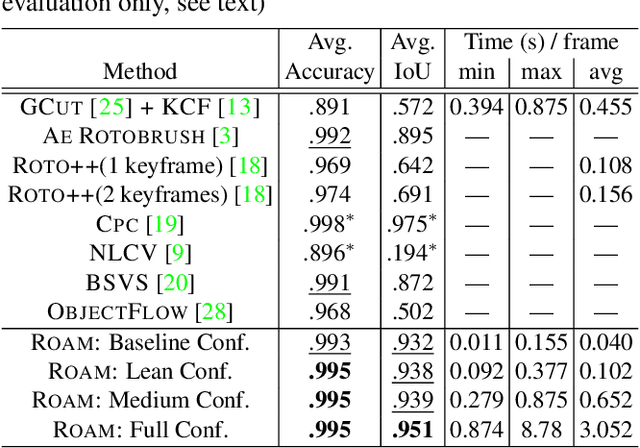
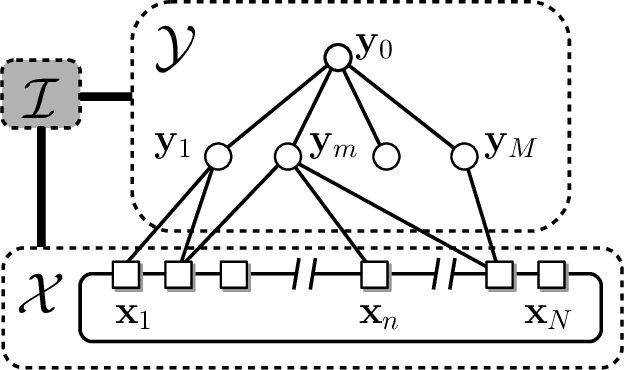
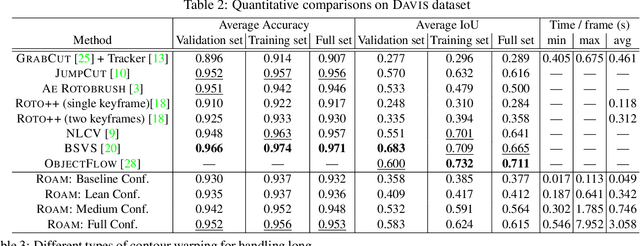
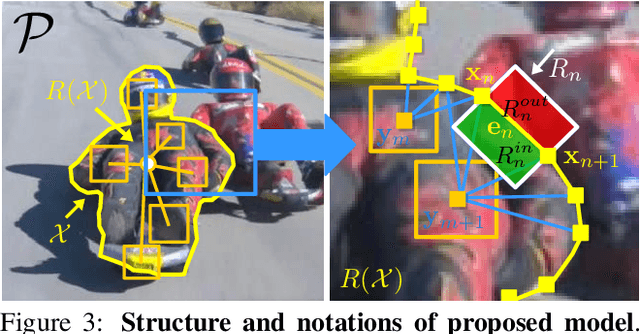
Rotoscoping, the detailed delineation of scene elements through a video shot, is a painstaking task of tremendous importance in professional post-production pipelines. While pixel-wise segmentation techniques can help for this task, professional rotoscoping tools rely on parametric curves that offer the artists a much better interactive control on the definition, editing and manipulation of the segments of interest. Sticking to this prevalent rotoscoping paradigm, we propose a novel framework to capture and track the visual aspect of an arbitrary object in a scene, given a first closed outline of this object. This model combines a collection of local foreground/background appearance models spread along the outline, a global appearance model of the enclosed object and a set of distinctive foreground landmarks. The structure of this rich appearance model allows simple initialization, efficient iterative optimization with exact minimization at each step, and on-line adaptation in videos. We demonstrate qualitatively and quantitatively the merit of this framework through comparisons with tools based on either dynamic segmentation with a closed curve or pixel-wise binary labelling.
Learning to superoptimize programs - Workshop Version
Dec 04, 2016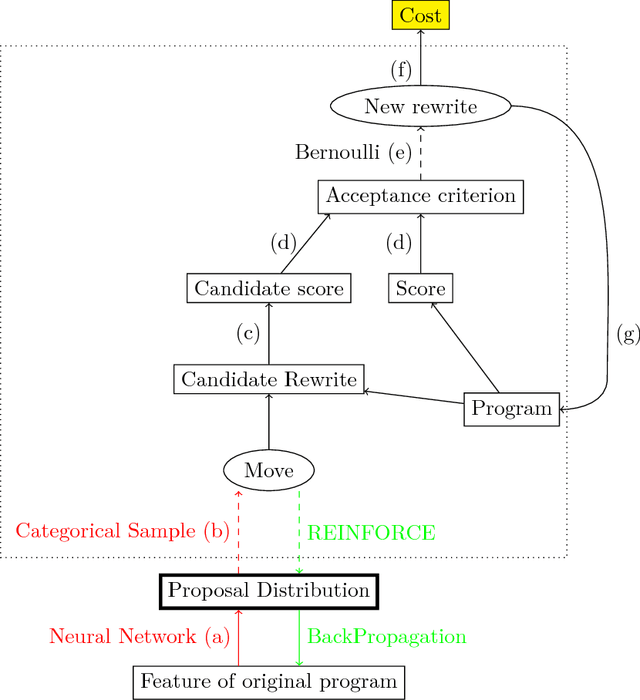
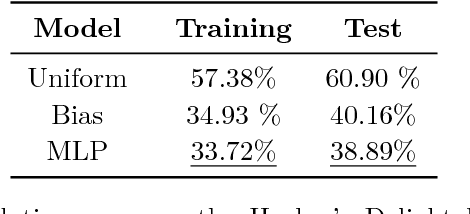
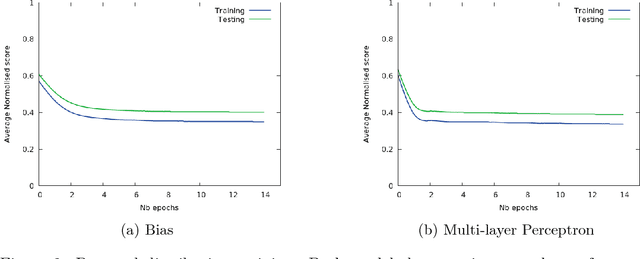
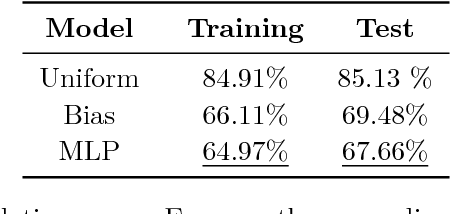
Superoptimization requires the estimation of the best program for a given computational task. In order to deal with large programs, superoptimization techniques perform a stochastic search. This involves proposing a modification of the current program, which is accepted or rejected based on the improvement achieved. The state of the art method uses uniform proposal distributions, which fails to exploit the problem structure to the fullest. To alleviate this deficiency, we learn a proposal distribution over possible modifications using Reinforcement Learning. We provide convincing results on the superoptimization of "Hacker's Delight" programs.
Playing Doom with SLAM-Augmented Deep Reinforcement Learning
Dec 01, 2016

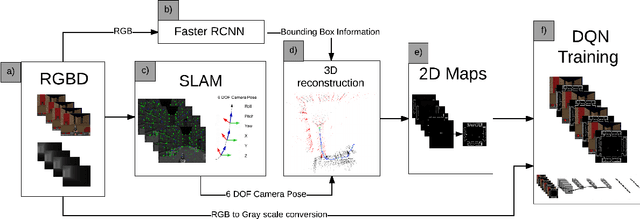
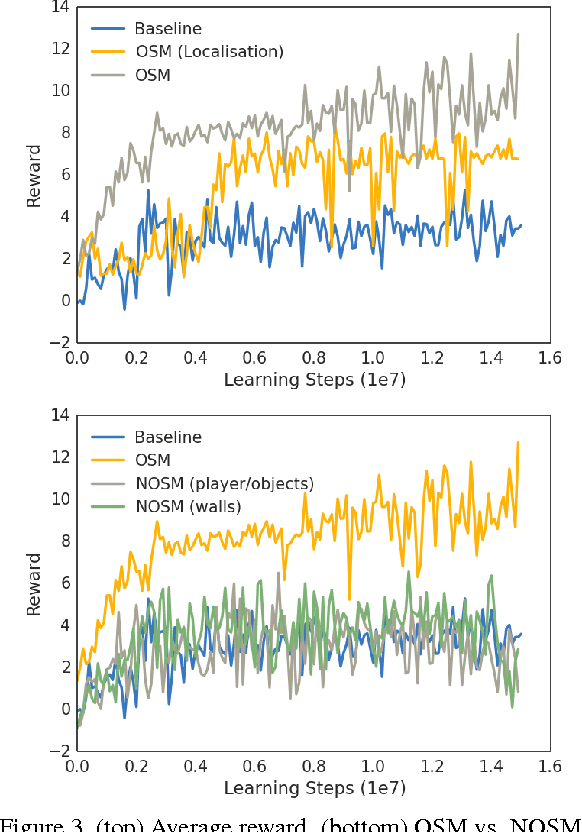
A number of recent approaches to policy learning in 2D game domains have been successful going directly from raw input images to actions. However when employed in complex 3D environments, they typically suffer from challenges related to partial observability, combinatorial exploration spaces, path planning, and a scarcity of rewarding scenarios. Inspired from prior work in human cognition that indicates how humans employ a variety of semantic concepts and abstractions (object categories, localisation, etc.) to reason about the world, we build an agent-model that incorporates such abstractions into its policy-learning framework. We augment the raw image input to a Deep Q-Learning Network (DQN), by adding details of objects and structural elements encountered, along with the agent's localisation. The different components are automatically extracted and composed into a topological representation using on-the-fly object detection and 3D-scene reconstruction.We evaluate the efficacy of our approach in Doom, a 3D first-person combat game that exhibits a number of challenges discussed, and show that our augmented framework consistently learns better, more effective policies.
Inducing Interpretable Representations with Variational Autoencoders
Nov 22, 2016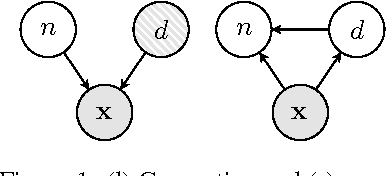
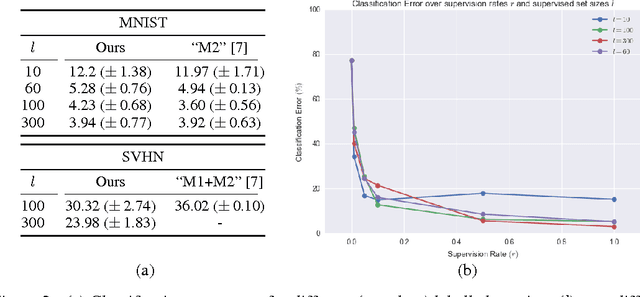

We develop a framework for incorporating structured graphical models in the \emph{encoders} of variational autoencoders (VAEs) that allows us to induce interpretable representations through approximate variational inference. This allows us to both perform reasoning (e.g. classification) under the structural constraints of a given graphical model, and use deep generative models to deal with messy, high-dimensional domains where it is often difficult to model all the variation. Learning in this framework is carried out end-to-end with a variational objective, applying to both unsupervised and semi-supervised schemes.
Recurrent Instance Segmentation
Oct 24, 2016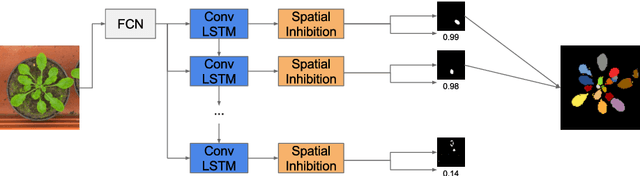
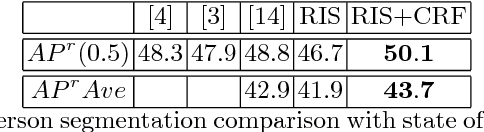
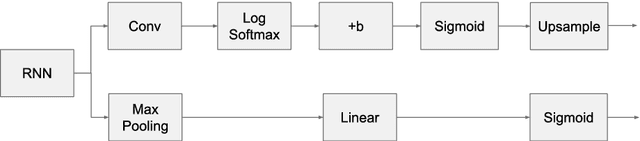
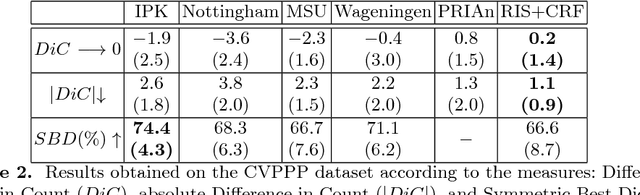
Instance segmentation is the problem of detecting and delineating each distinct object of interest appearing in an image. Current instance segmentation approaches consist of ensembles of modules that are trained independently of each other, thus missing opportunities for joint learning. Here we propose a new instance segmentation paradigm consisting in an end-to-end method that learns how to segment instances sequentially. The model is based on a recurrent neural network that sequentially finds objects and their segmentations one at a time. This net is provided with a spatial memory that keeps track of what pixels have been explained and allows occlusion handling. In order to train the model we designed a principled loss function that accurately represents the properties of the instance segmentation problem. In the experiments carried out, we found that our method outperforms recent approaches on multiple person segmentation, and all state of the art approaches on the Plant Phenotyping dataset for leaf counting.
* 14 pages (main paper). 24 pages including references and appendix
Joint Training of Generic CNN-CRF Models with Stochastic Optimization
Sep 14, 2016
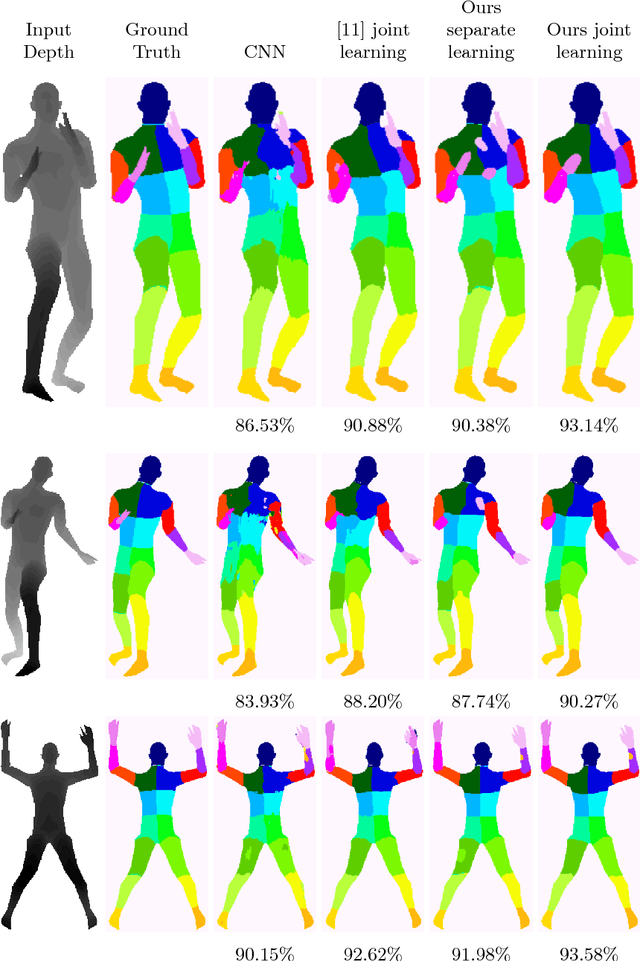
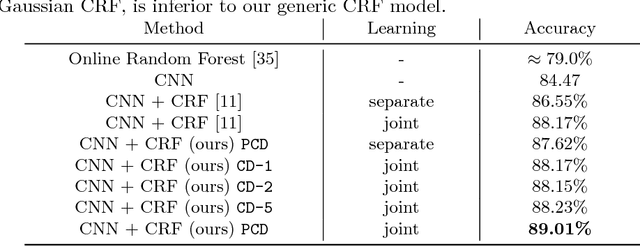
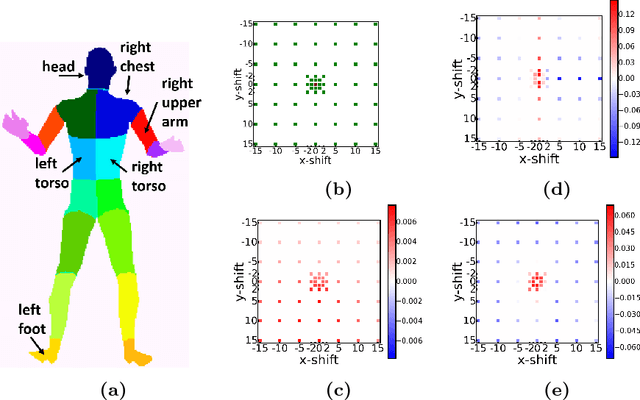
We propose a new CNN-CRF end-to-end learning framework, which is based on joint stochastic optimization with respect to both Convolutional Neural Network (CNN) and Conditional Random Field (CRF) parameters. While stochastic gradient descent is a standard technique for CNN training, it was not used for joint models so far. We show that our learning method is (i) general, i.e. it applies to arbitrary CNN and CRF architectures and potential functions; (ii) scalable, i.e. it has a low memory footprint and straightforwardly parallelizes on GPUs; (iii) easy in implementation. Additionally, the unified CNN-CRF optimization approach simplifies a potential hardware implementation. We empirically evaluate our method on the task of semantic labeling of body parts in depth images and show that it compares favorably to competing techniques.
Fully-Convolutional Siamese Networks for Object Tracking
Sep 14, 2016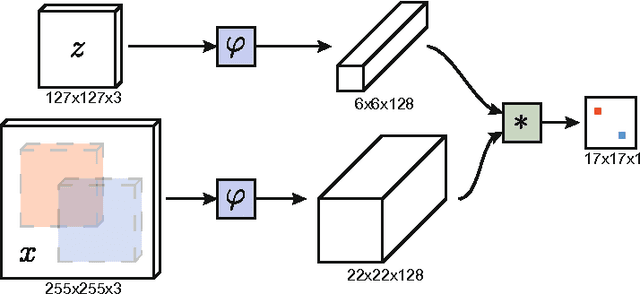
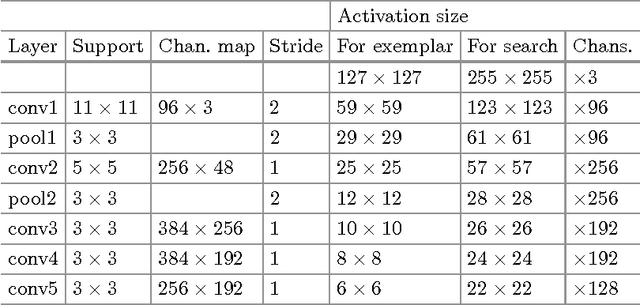

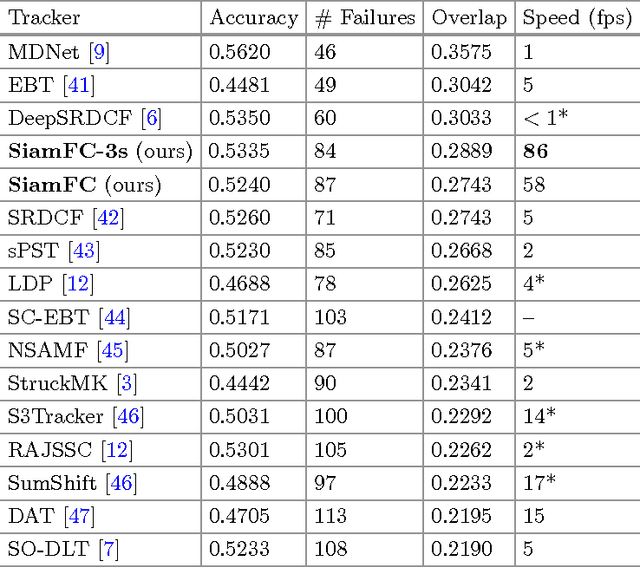
The problem of arbitrary object tracking has traditionally been tackled by learning a model of the object's appearance exclusively online, using as sole training data the video itself. Despite the success of these methods, their online-only approach inherently limits the richness of the model they can learn. Recently, several attempts have been made to exploit the expressive power of deep convolutional networks. However, when the object to track is not known beforehand, it is necessary to perform Stochastic Gradient Descent online to adapt the weights of the network, severely compromising the speed of the system. In this paper we equip a basic tracking algorithm with a novel fully-convolutional Siamese network trained end-to-end on the ILSVRC15 dataset for object detection in video. Our tracker operates at frame-rates beyond real-time and, despite its extreme simplicity, achieves state-of-the-art performance in multiple benchmarks.
Fully-Trainable Deep Matching
Sep 12, 2016
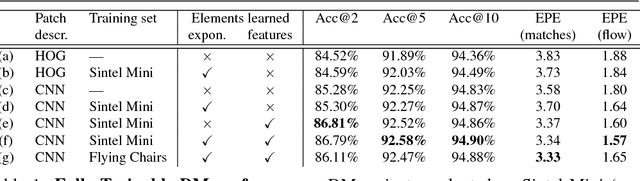
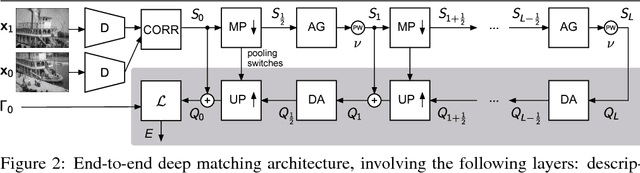
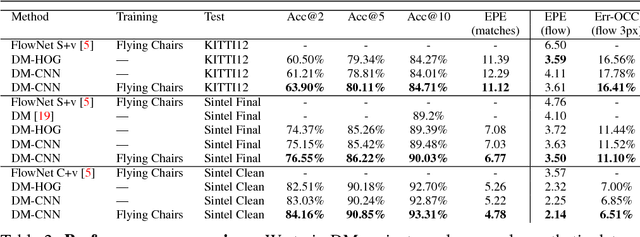
Deep Matching (DM) is a popular high-quality method for quasi-dense image matching. Despite its name, however, the original DM formulation does not yield a deep neural network that can be trained end-to-end via backpropagation. In this paper, we remove this limitation by rewriting the complete DM algorithm as a convolutional neural network. This results in a novel deep architecture for image matching that involves a number of new layer types and that, similar to recent networks for image segmentation, has a U-topology. We demonstrate the utility of the approach by improving the performance of DM by learning it end-to-end on an image matching task.
Bottom-up Instance Segmentation using Deep Higher-Order CRFs
Sep 08, 2016
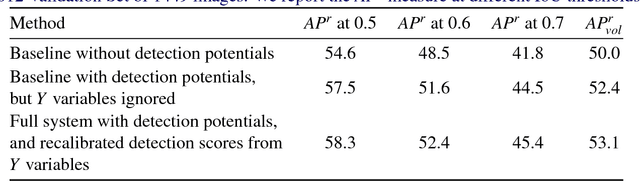
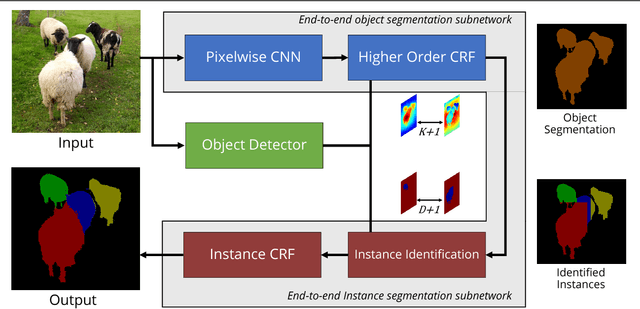
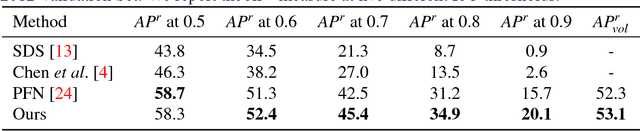
Traditional Scene Understanding problems such as Object Detection and Semantic Segmentation have made breakthroughs in recent years due to the adoption of deep learning. However, the former task is not able to localise objects at a pixel level, and the latter task has no notion of different instances of objects of the same class. We focus on the task of Instance Segmentation which recognises and localises objects down to a pixel level. Our model is based on a deep neural network trained for semantic segmentation. This network incorporates a Conditional Random Field with end-to-end trainable higher order potentials based on object detector outputs. This allows us to reason about instances from an initial, category-level semantic segmentation. Our simple method effectively leverages the great progress recently made in semantic segmentation and object detection. The accurate instance-level segmentations that our network produces is reflected by the considerable improvements obtained over previous work.