Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Interpretable Representations with Variational Autoencoders
Nov 22, 2016
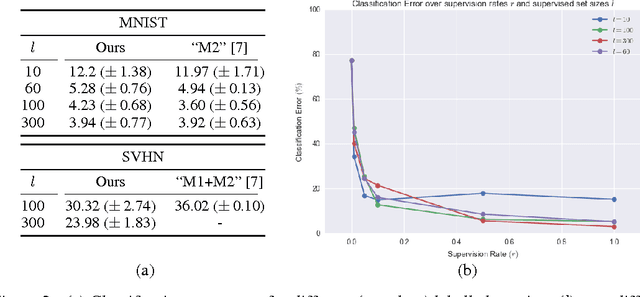

We develop a framework for incorporating structured graphical models in the \emph{encoders} of variational autoencoders (VAEs) that allows us to induce interpretable representations through approximate variational inference. This allows us to both perform reasoning (e.g. classification) under the structural constraints of a given graphical model, and use deep generative models to deal with messy, high-dimensional domains where it is often difficult to model all the variation. Learning in this framework is carried out end-to-end with a variational objective, applying to both unsupervised and semi-supervised schemes.
* Presented at NIPS 2016 Workshop on Interpretable Machine Learning in
Complex Systems
Via