 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-Up Skill Discovery from Unsegmented Demonstrations for Long-Horizon Robot Manipulation
Sep 28, 2021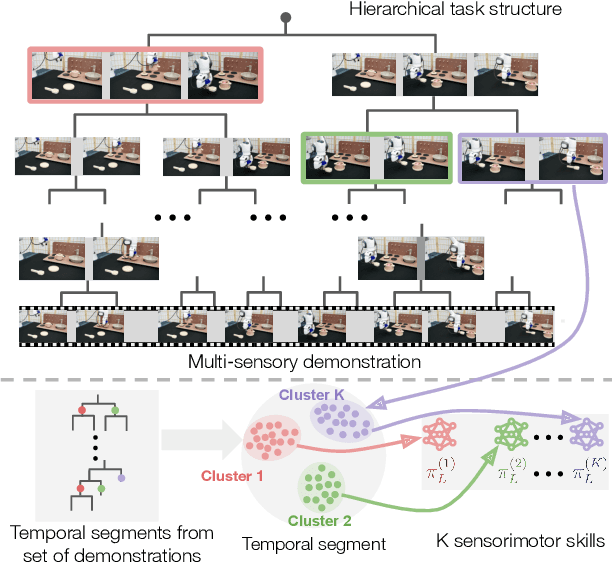
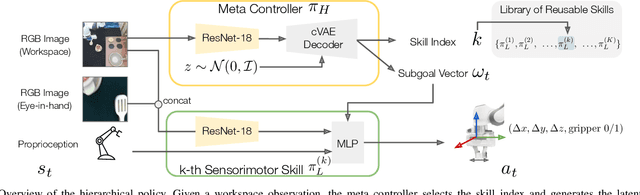

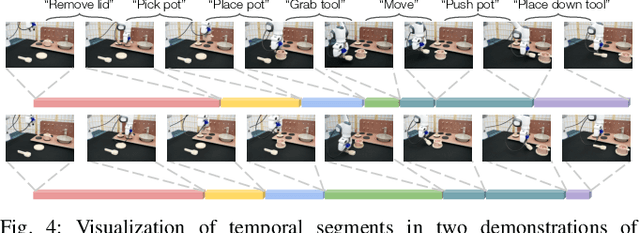
We tackle real-world long-horizon robot manipulation tasks through skill discovery. We present a bottom-up approach to learning a library of reusable skills from unsegmented demonstrations and use these skills to synthesize prolonged robot behaviors. Our method starts with constructing a hierarchical task structure from each demonstration through agglomerative clustering. From the task structures of multi-task demonstrations, we identify skills based on the recurring patterns and train goal-conditioned sensorimotor policies with hierarchical imitation learning. Finally, we train a meta controller to compose these skills to solve long-horizon manipulation tasks. The entire model can be trained on a small set of human demonstrations collected within 30 minutes without further annotations, making it amendable to real-world deployment. We systematically evaluated our method in simulation environments and on a real robot. Our method has shown superior performance over state-of-the-art imitation learning methods in multi-stage manipulation tasks. Furthermore, skills discovered from multi-task demonstrations boost the average task success by $8\%$ compared to those discovered from individual tasks.
APPLE: Adaptive Planner Parameter Learning from Evaluative Feedback
Aug 22, 2021


Classical autonomous navigation systems can control robots in a collision-free manner, oftentimes with verifiable safety and explainability. When facing new environments, however, fine-tuning of the system parameters by an expert is typically required before the system can navigate as expected. To alleviate this requirement, the recently-proposed Adaptive Planner Parameter Learning paradigm allows robots to \emph{learn} how to dynamically adjust planner parameters using a teleoperated demonstration or corrective interventions from non-expert users. However, these interaction modalities require users to take full control of the moving robot, which requires the users to be familiar with robot teleoperation. As an alternative, we introduce \textsc{apple}, Adaptive Planner Parameter Learning from \emph{Evaluative Feedback} (real-time, scalar-valued assessments of behavior), which represents a less-demanding modality of interaction. Simulated and physical experiments show \textsc{apple} can achieve better performance compared to the planner with static default parameters and even yield improvement over learned parameters from richer interaction modalities.
From Agile Ground to Aerial Navigation: Learning from Learned Hallucination
Aug 22, 2021

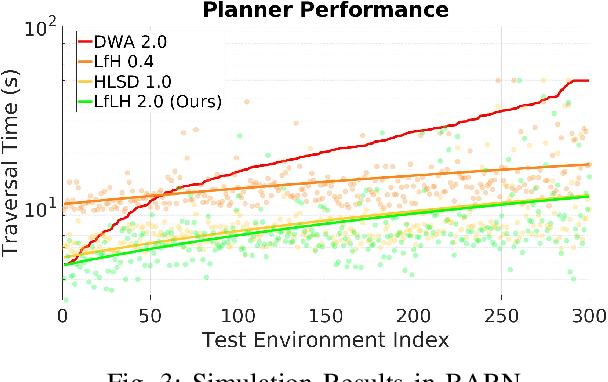

This paper presents a self-supervised Learning from Learned Hallucination (LfLH) method to learn fast and reactive motion planners for ground and aerial robots to navigate through highly constrained environments. The recent Learning from Hallucination (LfH) paradigm for autonomous navigation executes motion plans by random exploration in completely safe obstacle-free spaces, uses hand-crafted hallucination techniques to add imaginary obstacles to the robot's perception, and then learns motion planners to navigate in realistic, highly-constrained, dangerous spaces. However, current hand-crafted hallucination techniques need to be tailored for specific robot types (e.g., a differential drive ground vehicle), and use approximations heavily dependent on certain assumptions (e.g., a short planning horizon). In this work, instead of manually designing hallucination functions, LfLH learns to hallucinate obstacle configurations, where the motion plans from random exploration in open space are optimal, in a self-supervised manner. LfLH is robust to different robot types and does not make assumptions about the planning horizon. Evaluated in both simulated and physical environments with a ground and an aerial robot, LfLH outperforms or performs comparably to previous hallucination approaches, along with sampling- and optimization-based classical methods.
Recent Advances in Leveraging Human Guidance for Sequential Decision-Making Tasks
Jul 13, 2021
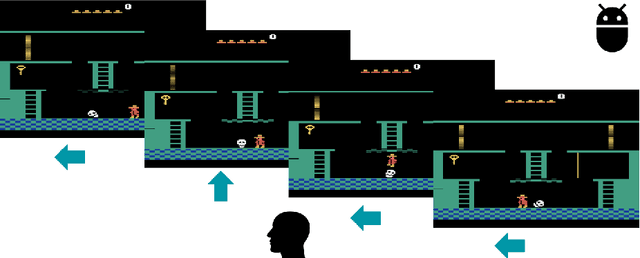
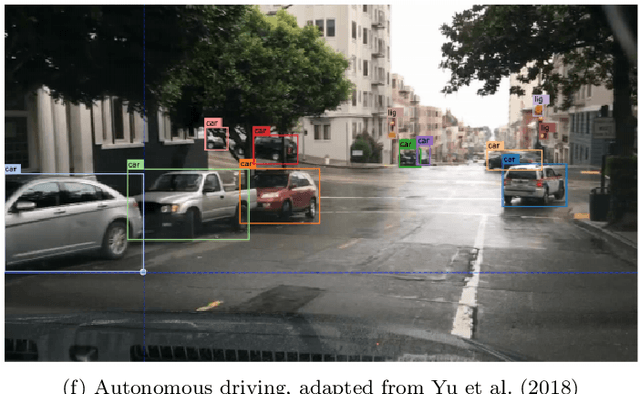
A longstanding goal of artificial intelligence is to create artificial agents capable of learning to perform tasks that require sequential decision making. Importantly, while it is the artificial agent that learns and acts, it is still up to humans to specify the particular task to be performed. Classical task-specification approaches typically involve humans providing stationary reward functions or explicit demonstrations of the desired tasks. However, there has recently been a great deal of research energy invested in exploring alternative ways in which humans may guide learning agents that may, e.g., be more suitable for certain tasks or require less human effort. This survey provides a high-level overview of five recent machine learning frameworks that primarily rely on human guidance apart from pre-specified reward functions or conventional, step-by-step action demonstrations. We review the motivation, assumptions, and implementation of each framework, and we discuss possible future research directions.
* Springer journal, Autonomous Agents and Multi-Agent Systems (JAAMAS)
Incorporating Gaze into Social Navigation
Jul 10, 2021

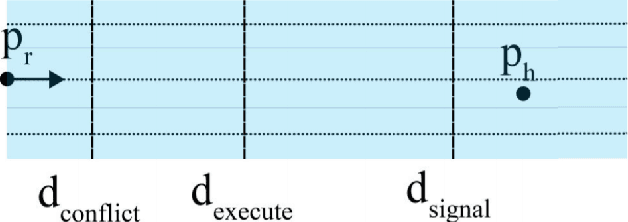
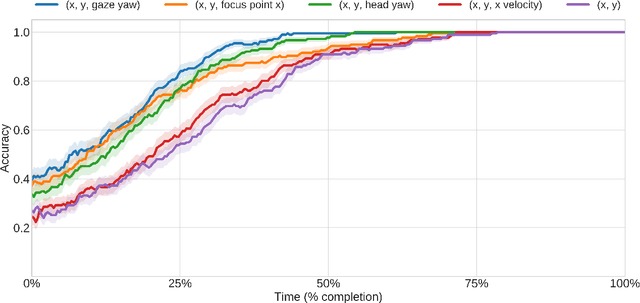
Most current approaches to social navigation focus on the trajectory and position of participants in the interaction. Our current work on the topic focuses on integrating gaze into social navigation, both to cue nearby pedestrians as to the intended trajectory of the robot and to enable the robot to read the intentions of nearby pedestrians. This paper documents a series of experiments in our laboratory investigating the role of gaze in social navigation.
Prevention and Resolution of Conflicts in Social Navigation -- a Survey
Jun 23, 2021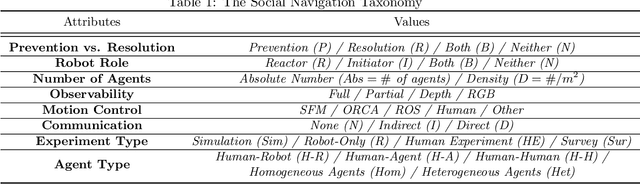

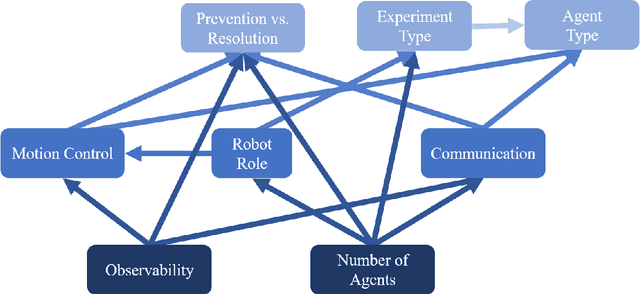
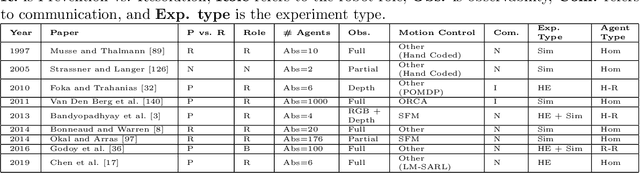
With the approaching goal of having robots collaborate in shared human-robot environments, navigation in this context becomes both crucial and desirable. Recent developments in robotics have encountered and tackled some of the challenges of navigating in mixed human-robot environments, and in recent years we observe a surge of related work that specifically targets the question of how to handle conflicts between agents in social navigation. These contributions offer models, algorithms, and evaluation metrics, however as this research area is inherently interdisciplinary, many of the relevant papers are not comparable and there is no standard vocabulary between the researchers. The main goal of this survey is to bridge this gap by proposing such a common language, using it to survey existing work, and highlighting open problems. It starts by defining a conflict in social navigation, and offers a detailed taxonomy of its components. This survey then maps existing work while discussing papers using the framing of the proposed taxonomy. Finally, this paper propose some future directions and problems that are currently in the frontier of social navigation to help focus research efforts.
Dynamic Sparse Training for Deep Reinforcement Learning
Jun 08, 2021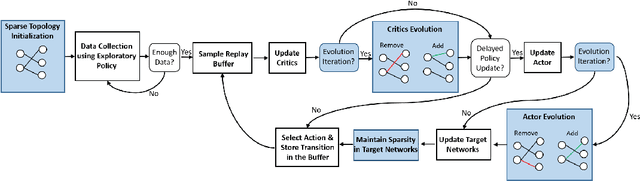
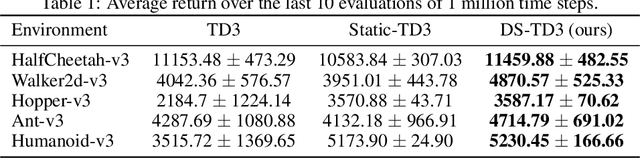
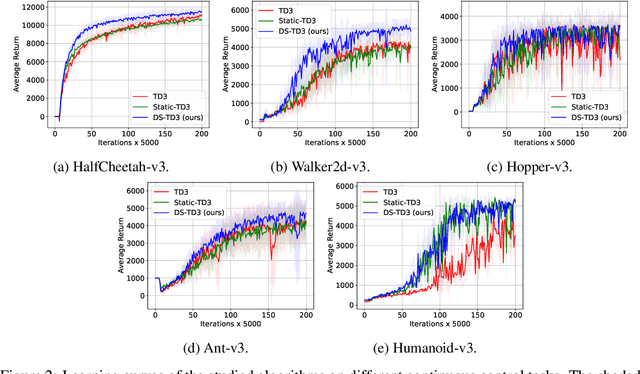

Deep reinforcement learning has achieved significant success in many decision-making tasks in various fields. However, it requires a large training time of dense neural networks to obtain a good performance. This hinders its applicability on low-resource devices where memory and computation are strictly constrained. In a step towards enabling deep reinforcement learning agents to be applied to low-resource devices, in this work, we propose for the first time to dynamically train deep reinforcement learning agents with sparse neural networks from scratch. We adopt the evolution principles of dynamic sparse training in the reinforcement learning paradigm and introduce a training algorithm that optimizes the sparse topology and the weight values jointly to dynamically fit the incoming data. Our approach is easy to be integrated into existing deep reinforcement learning algorithms and has many favorable advantages. First, it allows for significant compression of the network size which reduces the memory and computation costs substantially. This would accelerate not only the agent inference but also its training process. Second, it speeds up the agent learning process and allows for reducing the number of required training steps. Third, it can achieve higher performance than training the dense counterpart network. We evaluate our approach on OpenAI gym continuous control tasks. The experimental results show the effectiveness of our approach in achieving higher performance than one of the state-of-art baselines with a 50\% reduction in the network size and floating-point operations (FLOPs). Moreover, our proposed approach can reach the same performance achieved by the dense network with a 40-50\% reduction in the number of training steps.
Adversarial Intrinsic Motivation for Reinforcement Learning
May 30, 2021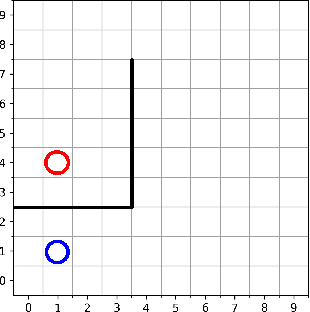
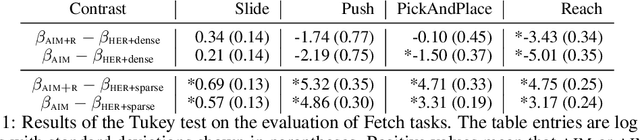
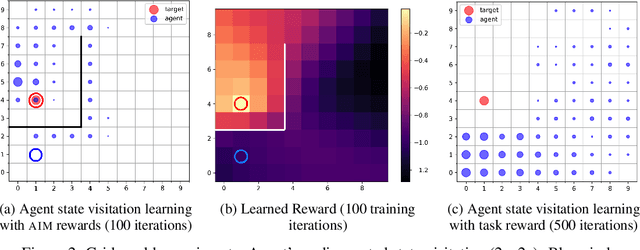
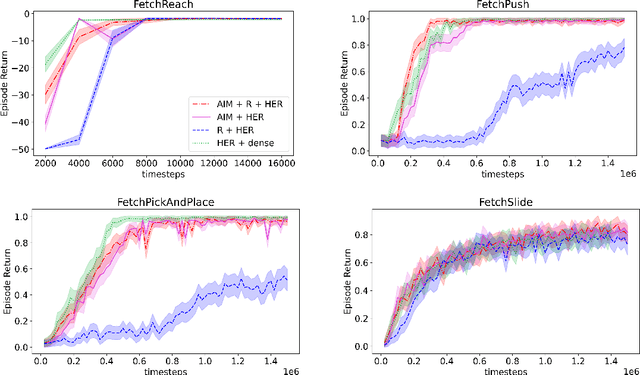
Learning with an objective to minimize the mismatch with a reference distribution has been shown to be useful for generative modeling and imitation learning. In this paper, we investigate whether one such objective, the Wasserstein-1 distance between a policy's state visitation distribution and a target distribution, can be utilized effectively for reinforcement learning (RL) tasks. Specifically, this paper focuses on goal-conditioned reinforcement learning where the idealized (unachievable) target distribution has full measure at the goal. We introduce a quasimetric specific to Markov Decision Processes (MDPs), and show that the policy that minimizes the Wasserstein-1 distance of its state visitation distribution to this target distribution under this quasimetric is the policy that reaches the goal in as few steps as possible. Our approach, termed Adversarial Intrinsic Motivation (AIM), estimates this Wasserstein-1 distance through its dual objective and uses it to compute a supplemental reward function. Our experiments show that this reward function changes smoothly with respect to transitions in the MDP and assists the agent in learning. Additionally, we combine AIM with Hindsight Experience Replay (HER) and show that the resulting algorithm accelerates learning significantly on several simulated robotics tasks when compared to HER with a sparse positive reward at the goal state.
VOILA: Visual-Observation-Only Imitation Learning for Autonomous Navigation
May 19, 2021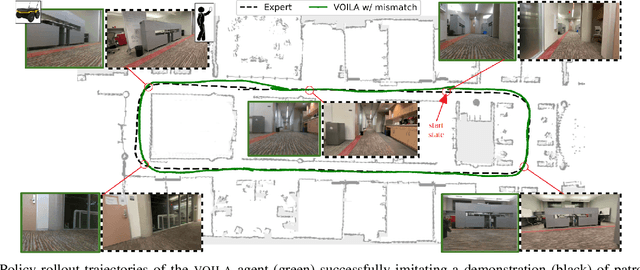
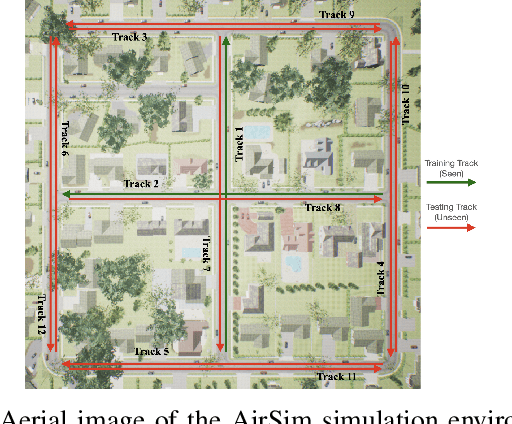
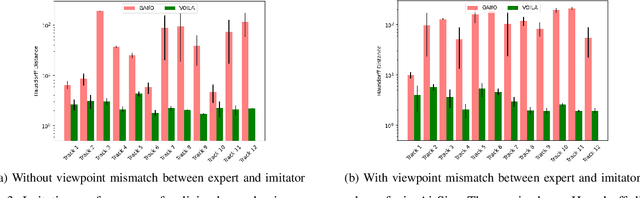

While imitation learning for vision based autonomous mobile robot navigation has recently received a great deal of attention in the research community, existing approaches typically require state action demonstrations that were gathered using the deployment platform. However, what if one cannot easily outfit their platform to record these demonstration signals or worse yet the demonstrator does not have access to the platform at all? Is imitation learning for vision based autonomous navigation even possible in such scenarios? In this work, we hypothesize that the answer is yes and that recent ideas from the Imitation from Observation (IfO) literature can be brought to bear such that a robot can learn to navigate using only ego centric video collected by a demonstrator, even in the presence of viewpoint mismatch. To this end, we introduce a new algorithm, Visual Observation only Imitation Learning for Autonomous navigation (VOILA), that can successfully learn navigation policies from a single video demonstration collected from a physically different agent. We evaluate VOILA in the photorealistic AirSim simulator and show that VOILA not only successfully imitates the expert, but that it also learns navigation policies that can generalize to novel environments. Further, we demonstrate the effectiveness of VOILA in a real world setting by showing that it allows a wheeled Jackal robot to successfully imitate a human walking in an environment using a video recorded using a mobile phone camera.
Coach-Player Multi-Agent Reinforcement Learning for Dynamic Team Composition
May 18, 2021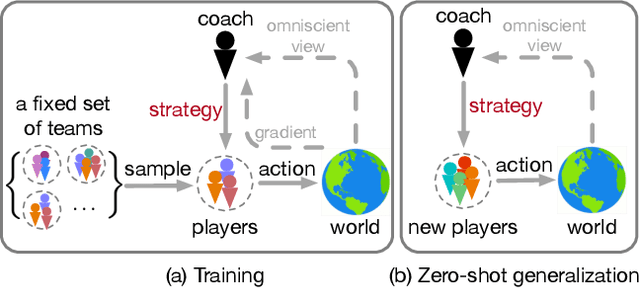
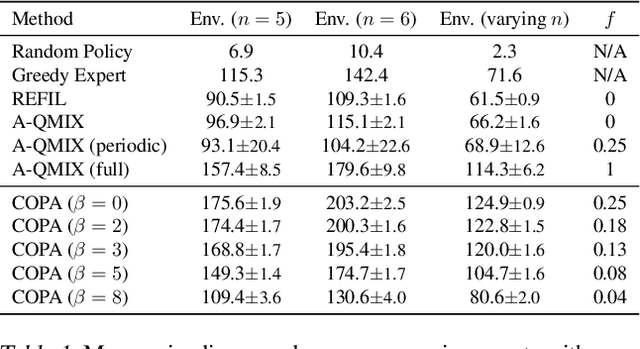
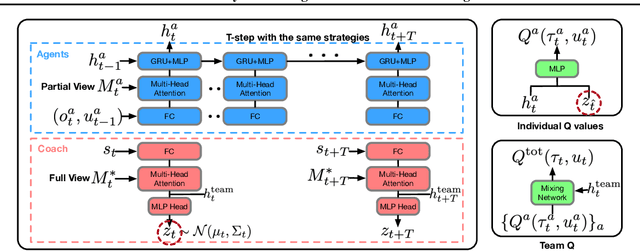
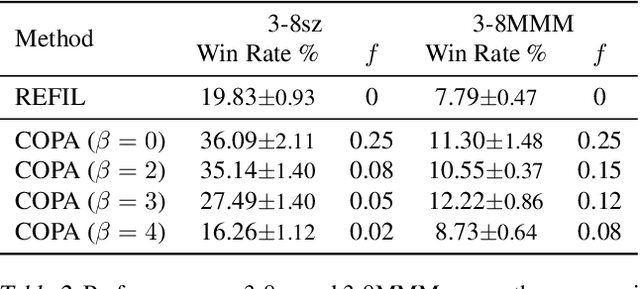
In real-world multiagent systems, agents with different capabilities may join or leave without altering the team's overarching goals. Coordinating teams with such dynamic composition is challenging: the optimal team strategy varies with the composition. We propose COPA, a coach-player framework to tackle this problem. We assume the coach has a global view of the environment and coordinates the players, who only have partial views, by distributing individual strategies. Specifically, we 1) adopt the attention mechanism for both the coach and the players; 2) propose a variational objective to regularize learning; and 3) design an adaptive communication method to let the coach decide when to communicate with the players. We validate our methods on a resource collection task, a rescue game, and the StarCraft micromanagement tasks. We demonstrate zero-shot generalization to new team compositions. Our method achieves comparable or better performance than the setting where all players have a full view of the environment. Moreover, we see that the performance remains high even when the coach communicates as little as 13% of the time using the adaptive communication strategy.