 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph networks as learnable physics engines for inference and control
Jun 04, 2018
Understanding and interacting with everyday physical scenes requires rich knowledge about the structure of the world, represented either implicitly in a value or policy function, or explicitly in a transition model. Here we introduce a new class of learnable models--based on graph networks--which implement an inductive bias for object- and relation-centric representations of complex, dynamical systems. Our results show that as a forward model, our approach supports accurate predictions from real and simulated data, and surprisingly strong and efficient generalization, across eight distinct physical systems which we varied parametrically and structurally. We also found that our inference model can perform system identification. Our models are also differentiable, and support online planning via gradient-based trajectory optimization, as well as offline policy optimization. Our framework offers new opportunities for harnessing and exploiting rich knowledge about the world, and takes a key step toward building machines with more human-like representations of the world.
Hyperbolic Attention Networks
May 24, 2018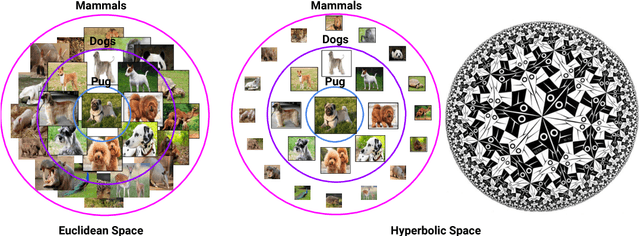
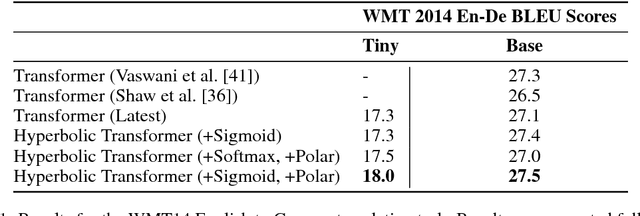
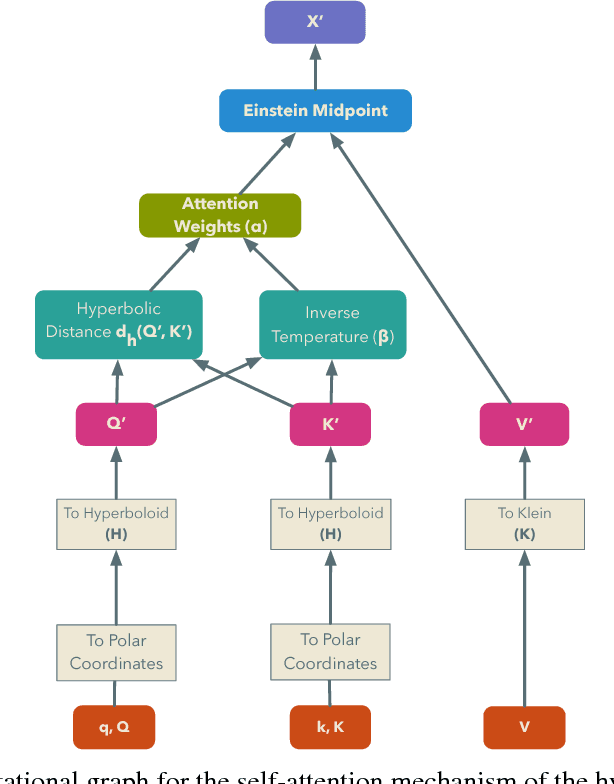
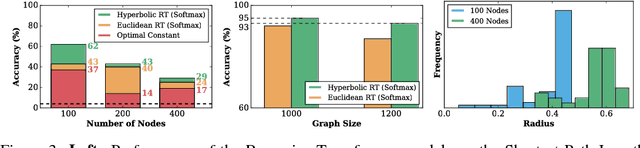
We introduce hyperbolic attention networks to endow neural networks with enough capacity to match the complexity of data with hierarchical and power-law structure. A few recent approaches have successfully demonstrated the benefits of imposing hyperbolic geometry on the parameters of shallow networks. We extend this line of work by imposing hyperbolic geometry on the activations of neural networks. This allows us to exploit hyperbolic geometry to reason about embeddings produced by deep networks. We achieve this by re-expressing the ubiquitous mechanism of soft attention in terms of operations defined for hyperboloid and Klein models. Our method shows improvements in terms of generalization on neural machine translation, learning on graphs and visual question answering tasks while keeping the neural representations compact.
Learning Deep Generative Models of Graphs
Mar 08, 2018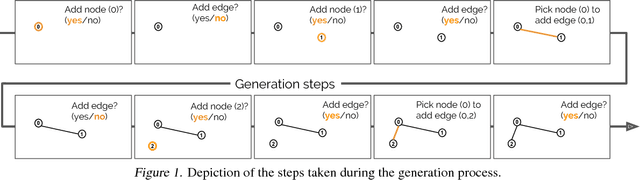
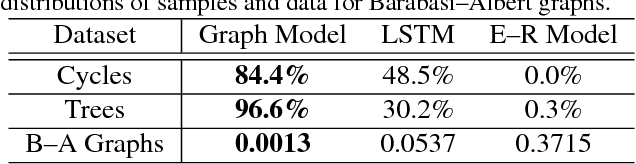
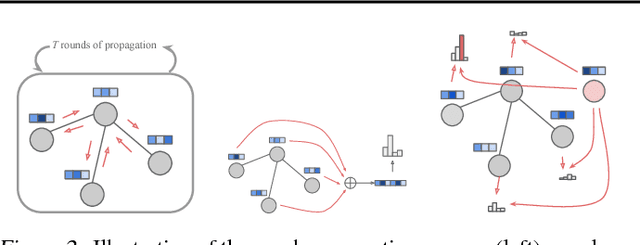
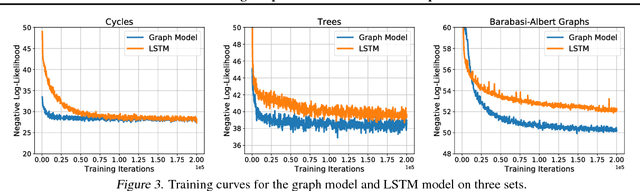
Graphs are fundamental data structures which concisely capture the relational structure in many important real-world domains, such as knowledge graphs, physical and social interactions, language, and chemistry. Here we introduce a powerful new approach for learning generative models over graphs, which can capture both their structure and attributes. Our approach uses graph neural networks to express probabilistic dependencies among a graph's nodes and edges, and can, in principle, learn distributions over any arbitrary graph. In a series of experiments our results show that once trained, our models can generate good quality samples of both synthetic graphs as well as real molecular graphs, both unconditionally and conditioned on data. Compared to baselines that do not use graph-structured representations, our models often perform far better. We also explore key challenges of learning generative models of graphs, such as how to handle symmetries and ordering of elements during the graph generation process, and offer possible solutions. Our work is the first and most general approach for learning generative models over arbitrary graphs, and opens new directions for moving away from restrictions of vector- and sequence-like knowledge representations, toward more expressive and flexible relational data structures.
Imagination-Augmented Agents for Deep Reinforcement Learning
Feb 14, 2018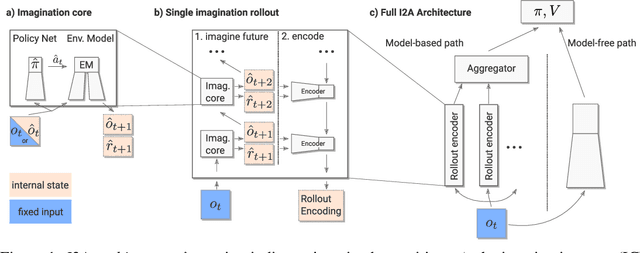
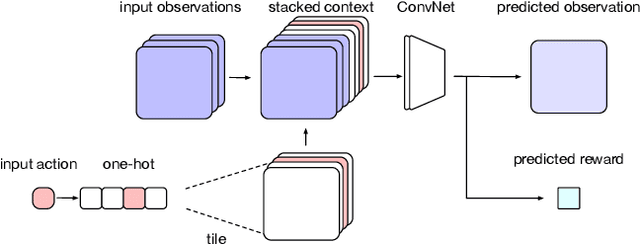


We introduce Imagination-Augmented Agents (I2As), a novel architecture for deep reinforcement learning combining model-free and model-based aspects. In contrast to most existing model-based reinforcement learning and planning methods, which prescribe how a model should be used to arrive at a policy, I2As learn to interpret predictions from a learned environment model to construct implicit plans in arbitrary ways, by using the predictions as additional context in deep policy networks. I2As show improved data efficiency, performance, and robustness to model misspecification compared to several baselines.
Learning to Perform Physics Experiments via Deep Reinforcement Learning
Aug 17, 2017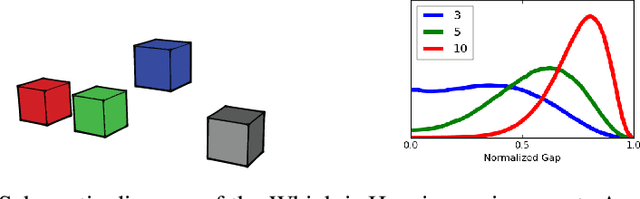
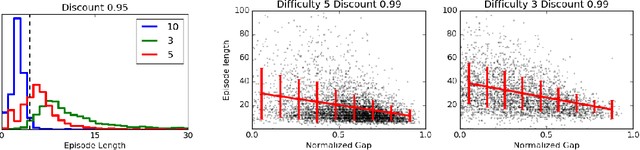
When encountering novel objects, humans are able to infer a wide range of physical properties such as mass, friction and deformability by interacting with them in a goal driven way. This process of active interaction is in the same spirit as a scientist performing experiments to discover hidden facts. Recent advances in artificial intelligence have yielded machines that can achieve superhuman performance in Go, Atari, natural language processing, and complex control problems; however, it is not clear that these systems can rival the scientific intuition of even a young child. In this work we introduce a basic set of tasks that require agents to estimate properties such as mass and cohesion of objects in an interactive simulated environment where they can manipulate the objects and observe the consequences. We found that state of art deep reinforcement learning methods can learn to perform the experiments necessary to discover such hidden properties. By systematically manipulating the problem difficulty and the cost incurred by the agent for performing experiments, we found that agents learn different strategies that balance the cost of gathering information against the cost of making mistakes in different situations.
Learning model-based planning from scratch
Jul 19, 2017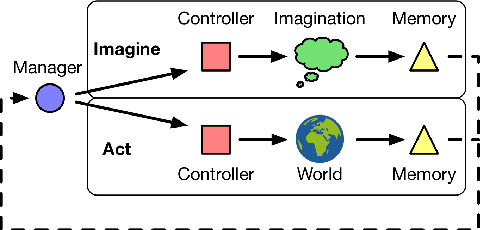
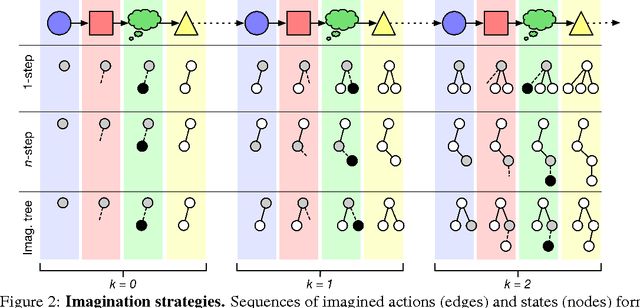
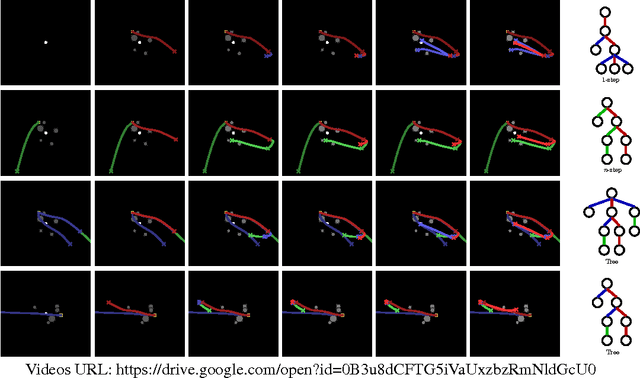
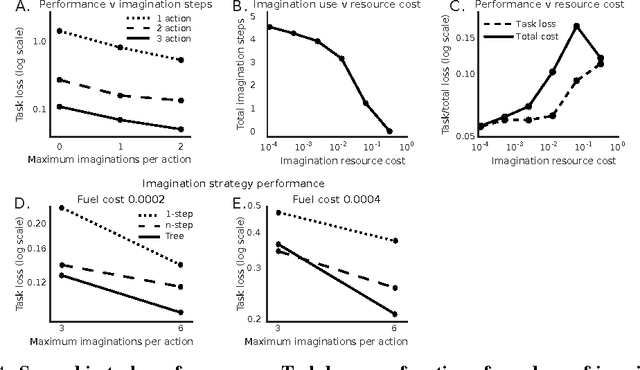
Conventional wisdom holds that model-based planning is a powerful approach to sequential decision-making. It is often very challenging in practice, however, because while a model can be used to evaluate a plan, it does not prescribe how to construct a plan. Here we introduce the "Imagination-based Planner", the first model-based, sequential decision-making agent that can learn to construct, evaluate, and execute plans. Before any action, it can perform a variable number of imagination steps, which involve proposing an imagined action and evaluating it with its model-based imagination. All imagined actions and outcomes are aggregated, iteratively, into a "plan context" which conditions future real and imagined actions. The agent can even decide how to imagine: testing out alternative imagined actions, chaining sequences of actions together, or building a more complex "imagination tree" by navigating flexibly among the previously imagined states using a learned policy. And our agent can learn to plan economically, jointly optimizing for external rewards and computational costs associated with using its imagination. We show that our architecture can learn to solve a challenging continuous control problem, and also learn elaborate planning strategies in a discrete maze-solving task. Our work opens a new direction toward learning the components of a model-based planning system and how to use them.
Visual Interaction Networks
Jun 05, 2017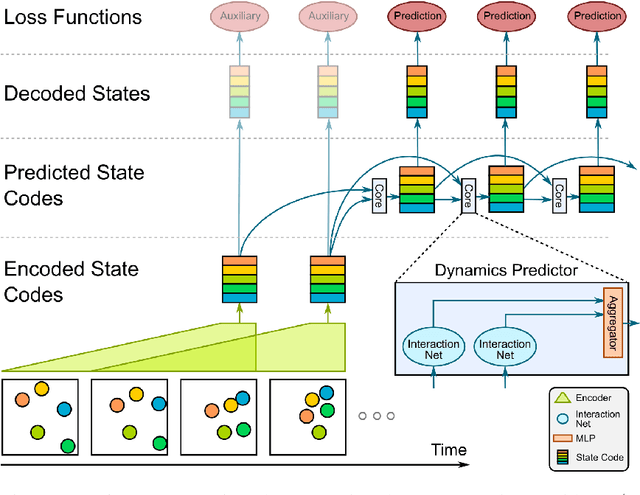

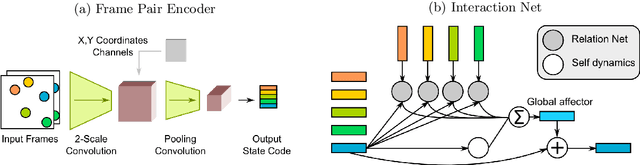
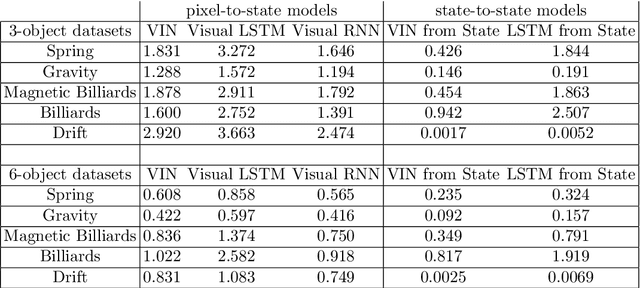
From just a glance, humans can make rich predictions about the future state of a wide range of physical systems. On the other hand, modern approaches from engineering, robotics, and graphics are often restricted to narrow domains and require direct measurements of the underlying states. We introduce the Visual Interaction Network, a general-purpose model for learning the dynamics of a physical system from raw visual observations. Our model consists of a perceptual front-end based on convolutional neural networks and a dynamics predictor based on interaction networks. Through joint training, the perceptual front-end learns to parse a dynamic visual scene into a set of factored latent object representations. The dynamics predictor learns to roll these states forward in time by computing their interactions and dynamics, producing a predicted physical trajectory of arbitrary length. We found that from just six input video frames the Visual Interaction Network can generate accurate future trajectories of hundreds of time steps on a wide range of physical systems. Our model can also be applied to scenes with invisible objects, inferring their future states from their effects on the visible objects, and can implicitly infer the unknown mass of objects. Our results demonstrate that the perceptual module and the object-based dynamics predictor module can induce factored latent representations that support accurate dynamical predictions. This work opens new opportunities for model-based decision-making and planning from raw sensory observations in complex physical environments.
A simple neural network module for relational reasoning
Jun 05, 2017
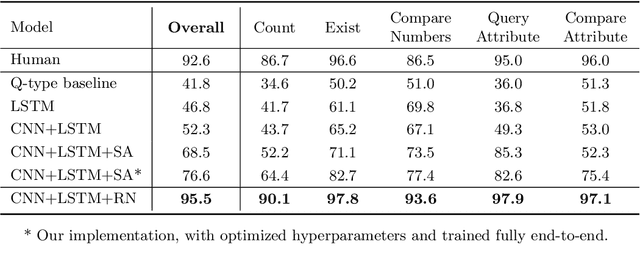
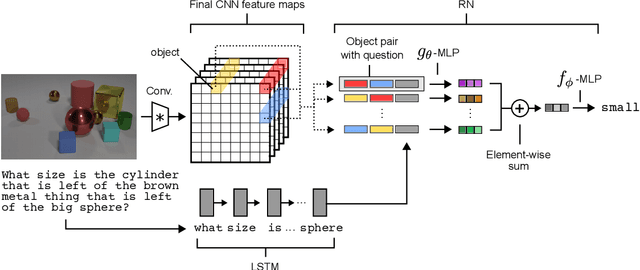

Relational reasoning is a central component of generally intelligent behavior, but has proven difficult for neural networks to learn. In this paper we describe how to use Relation Networks (RNs) as a simple plug-and-play module to solve problems that fundamentally hinge on relational reasoning. We tested RN-augmented networks on three tasks: visual question answering using a challenging dataset called CLEVR, on which we achieve state-of-the-art, super-human performance; text-based question answering using the bAbI suite of tasks; and complex reasoning about dynamic physical systems. Then, using a curated dataset called Sort-of-CLEVR we show that powerful convolutional networks do not have a general capacity to solve relational questions, but can gain this capacity when augmented with RNs. Our work shows how a deep learning architecture equipped with an RN module can implicitly discover and learn to reason about entities and their relations.
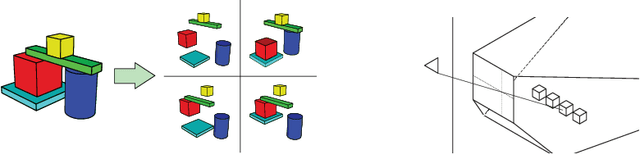
Discovering objects and their relations from entangled scene representations
Feb 16, 2017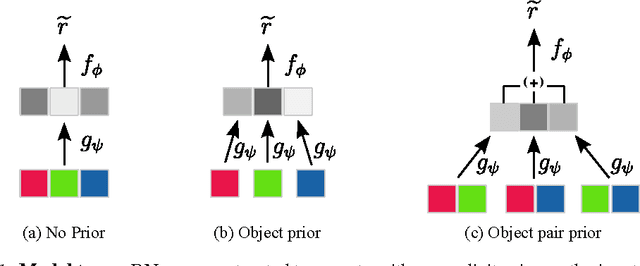
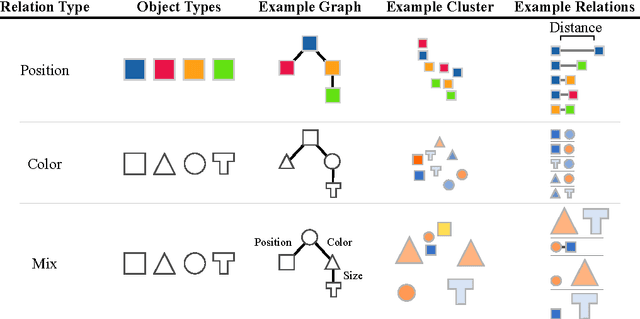
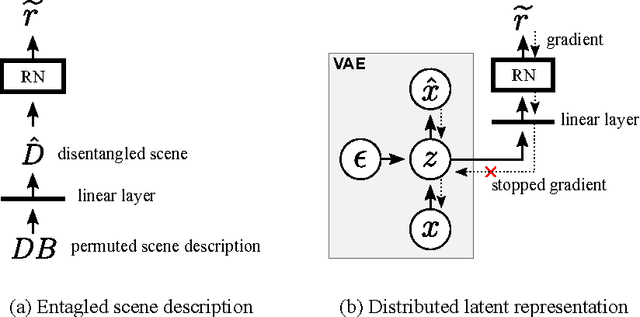
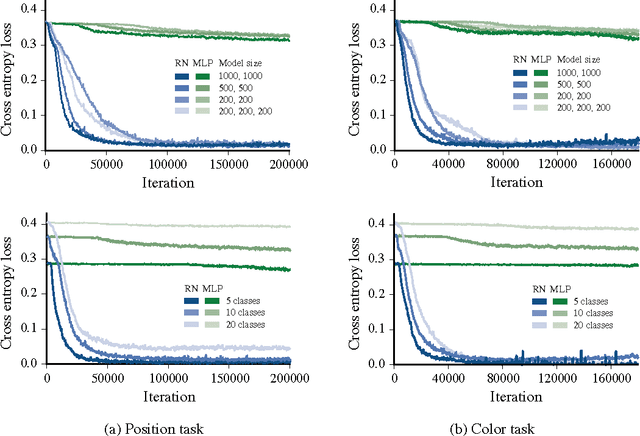
Our world can be succinctly and compactly described as structured scenes of objects and relations. A typical room, for example, contains salient objects such as tables, chairs and books, and these objects typically relate to each other by their underlying causes and semantics. This gives rise to correlated features, such as position, function and shape. Humans exploit knowledge of objects and their relations for learning a wide spectrum of tasks, and more generally when learning the structure underlying observed data. In this work, we introduce relation networks (RNs) - a general purpose neural network architecture for object-relation reasoning. We show that RNs are capable of learning object relations from scene description data. Furthermore, we show that RNs can act as a bottleneck that induces the factorization of objects from entangled scene description inputs, and from distributed deep representations of scene images provided by a variational autoencoder. The model can also be used in conjunction with differentiable memory mechanisms for implicit relation discovery in one-shot learning tasks. Our results suggest that relation networks are a potentially powerful architecture for solving a variety of problems that require object relation reasoning.