 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Contrastive Decoding: Open-ended Text Generation as Optimization
Oct 27, 2022Likelihood, although useful as a training loss, is a poor search objective for guiding open-ended generation from language models (LMs). Existing generation algorithms must avoid both unlikely strings, which are incoherent, and highly likely ones, which are short and repetitive. We propose contrastive decoding (CD), a more reliable search objective that returns the difference between likelihood under a large LM (called the expert, e.g. OPT-13b) and a small LM (called the amateur, e.g. OPT-125m). CD is inspired by the fact that the failures of larger LMs are even more prevalent in smaller LMs, and that this difference signals exactly which texts should be preferred. CD requires zero training, and produces higher quality text than decoding from the larger LM alone. It also generalizes across model types (OPT and GPT2) and significantly outperforms four strong decoding algorithms in automatic and human evaluations.
Truncation Sampling as Language Model Desmoothing
Oct 27, 2022Long samples of text from neural language models can be of poor quality. Truncation sampling algorithms--like top-$p$ or top-$k$ -- address this by setting some words' probabilities to zero at each step. This work provides framing for the aim of truncation, and an improved algorithm for that aim. We propose thinking of a neural language model as a mixture of a true distribution and a smoothing distribution that avoids infinite perplexity. In this light, truncation algorithms aim to perform desmoothing, estimating a subset of the support of the true distribution. Finding a good subset is crucial: we show that top-$p$ unnecessarily truncates high-probability words, for example causing it to truncate all words but Trump for a document that starts with Donald. We introduce $\eta$-sampling, which truncates words below an entropy-dependent probability threshold. Compared to previous algorithms, $\eta$-sampling generates more plausible long English documents according to humans, is better at breaking out of repetition, and behaves more reasonably on a battery of test distributions.
Surgical Fine-Tuning Improves Adaptation to Distribution Shifts
Oct 20, 2022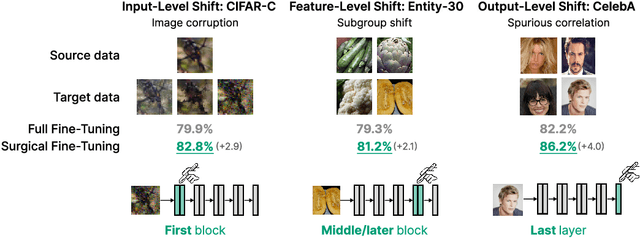
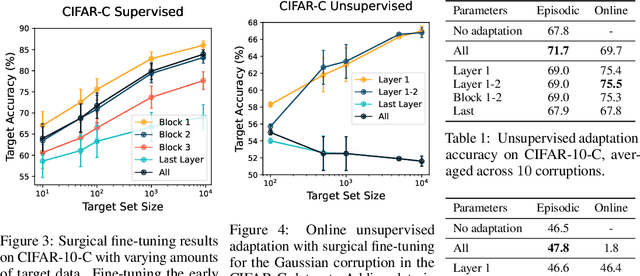
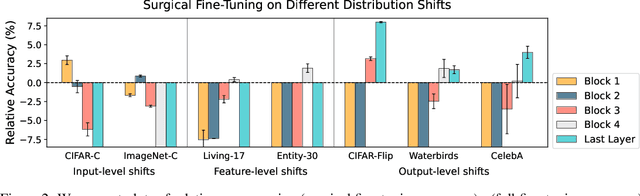
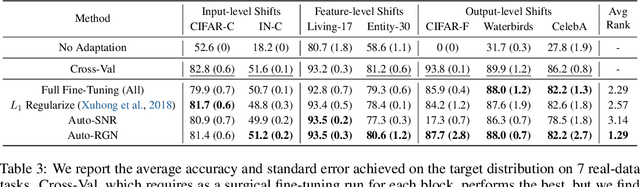
A common approach to transfer learning under distribution shift is to fine-tune the last few layers of a pre-trained model, preserving learned features while also adapting to the new task. This paper shows that in such settings, selectively fine-tuning a subset of layers (which we term surgical fine-tuning) matches or outperforms commonly used fine-tuning approaches. Moreover, the type of distribution shift influences which subset is more effective to tune: for example, for image corruptions, fine-tuning only the first few layers works best. We validate our findings systematically across seven real-world data tasks spanning three types of distribution shifts. Theoretically, we prove that for two-layer neural networks in an idealized setting, first-layer tuning can outperform fine-tuning all layers. Intuitively, fine-tuning more parameters on a small target dataset can cause information learned during pre-training to be forgotten, and the relevant information depends on the type of shift.
Deep Bidirectional Language-Knowledge Graph Pretraining
Oct 19, 2022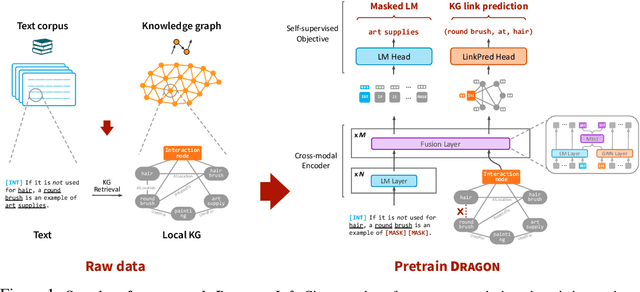

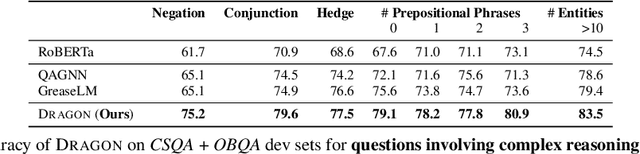

Pretraining a language model (LM) on text has been shown to help various downstream NLP tasks. Recent works show that a knowledge graph (KG) can complement text data, offering structured background knowledge that provides a useful scaffold for reasoning. However, these works are not pretrained to learn a deep fusion of the two modalities at scale, limiting the potential to acquire fully joint representations of text and KG. Here we propose DRAGON (Deep Bidirectional Language-Knowledge Graph Pretraining), a self-supervised approach to pretraining a deeply joint language-knowledge foundation model from text and KG at scale. Specifically, our model takes pairs of text segments and relevant KG subgraphs as input and bidirectionally fuses information from both modalities. We pretrain this model by unifying two self-supervised reasoning tasks, masked language modeling and KG link prediction. DRAGON outperforms existing LM and LM+KG models on diverse downstream tasks including question answering across general and biomedical domains, with +5% absolute gain on average. In particular, DRAGON achieves notable performance on complex reasoning about language and knowledge (+10% on questions involving long contexts or multi-step reasoning) and low-resource QA (+8% on OBQA and RiddleSense), and new state-of-the-art results on various BioNLP tasks. Our code and trained models are available at https://github.com/michiyasunaga/dragon.
Are Sample-Efficient NLP Models More Robust?
Oct 12, 2022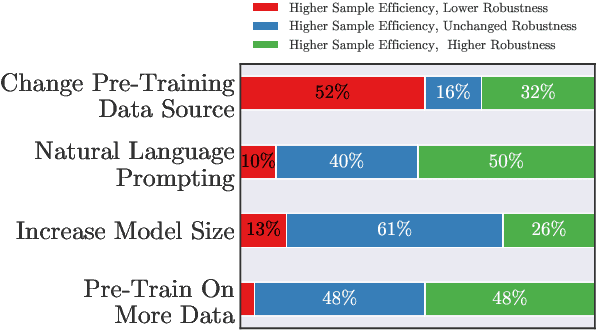
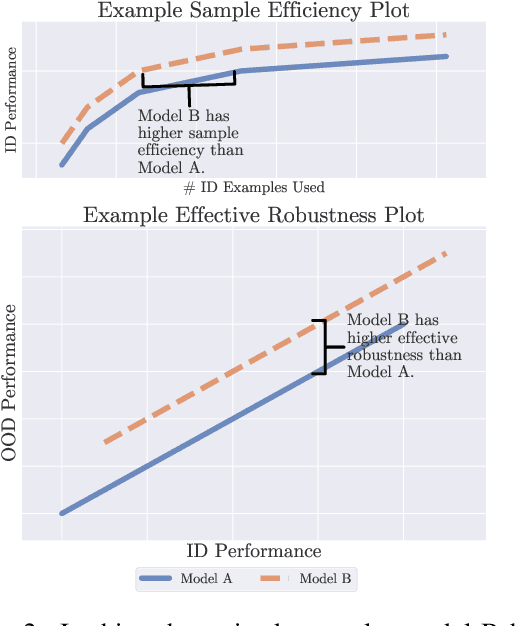
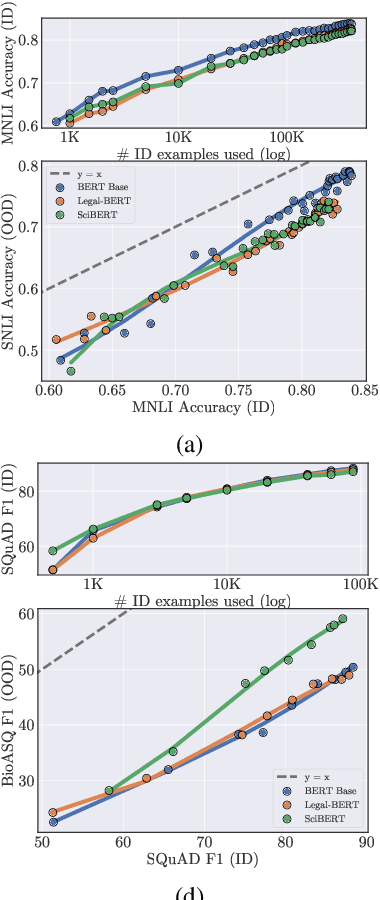
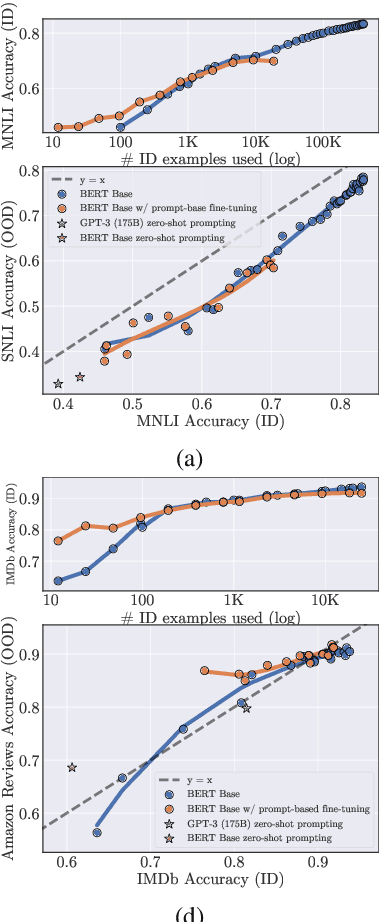
Recent work has observed that pre-trained models have higher out-of-distribution (OOD) robustness when they are exposed to less in-distribution (ID) training data (Radford et al., 2021). In particular, zero-shot models (e.g., GPT-3 and CLIP) have higher robustness than conventionally fine-tuned models, but these robustness gains fade as zero-shot models are fine-tuned on more ID data. We study this relationship between sample efficiency and robustness -- if two models have the same ID performance, does the model trained on fewer examples (higher sample efficiency) perform better OOD (higher robustness)? Surprisingly, experiments across three tasks, 23 total ID-OOD settings, and 14 models do not reveal a consistent relationship between sample efficiency and robustness -- while models with higher sample efficiency are sometimes more robust, most often there is no change in robustness, with some cases even showing decreased robustness. Since results vary on a case-by-case basis, we conduct detailed case studies of two particular ID-OOD pairs (SST-2 -> IMDb sentiment and SNLI -> HANS) to better understand why better sample efficiency may or may not yield higher robustness; attaining such an understanding requires case-by-case analysis of why models are not robust on a particular ID-OOD setting and how modeling techniques affect model capabilities.
Improving Self-Supervised Learning by Characterizing Idealized Representations
Sep 13, 2022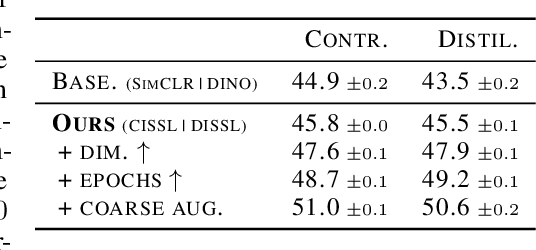
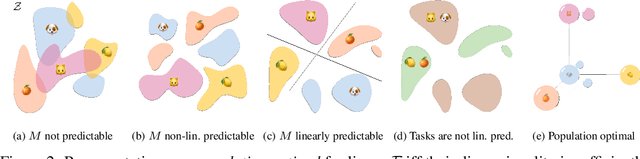
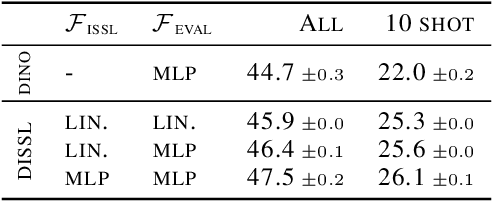
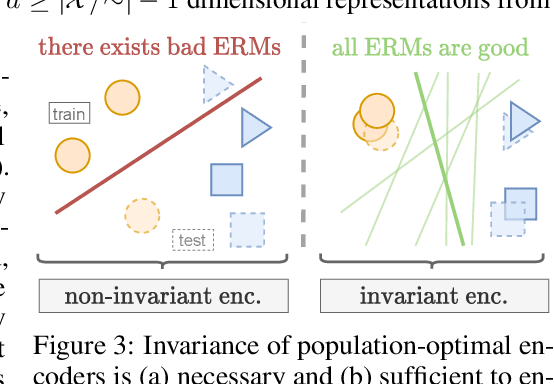
Despite the empirical successes of self-supervised learning (SSL) methods, it is unclear what characteristics of their representations lead to high downstream accuracies. In this work, we characterize properties that SSL representations should ideally satisfy. Specifically, we prove necessary and sufficient conditions such that for any task invariant to given data augmentations, desired probes (e.g., linear or MLP) trained on that representation attain perfect accuracy. These requirements lead to a unifying conceptual framework for improving existing SSL methods and deriving new ones. For contrastive learning, our framework prescribes simple but significant improvements to previous methods such as using asymmetric projection heads. For non-contrastive learning, we use our framework to derive a simple and novel objective. Our resulting SSL algorithms outperform baselines on standard benchmarks, including SwAV+multicrops on linear probing of ImageNet.
What Can Transformers Learn In-Context? A Case Study of Simple Function Classes
Aug 01, 2022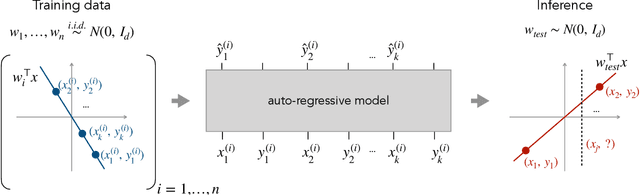
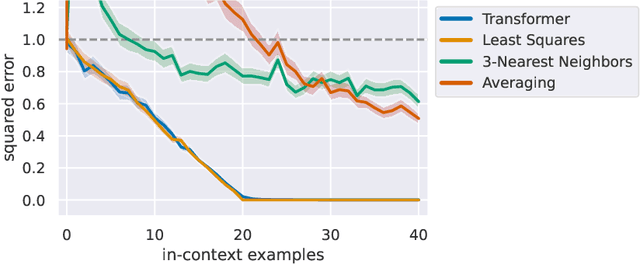
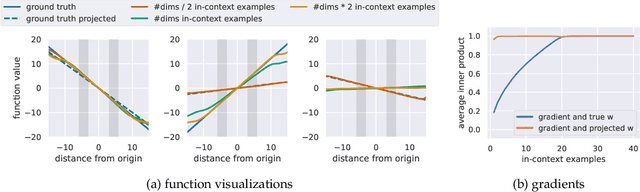
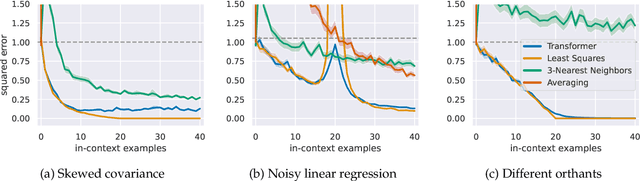
In-context learning refers to the ability of a model to condition on a prompt sequence consisting of in-context examples (input-output pairs corresponding to some task) along with a new query input, and generate the corresponding output. Crucially, in-context learning happens only at inference time without any parameter updates to the model. While large language models such as GPT-3 exhibit some ability to perform in-context learning, it is unclear what the relationship is between tasks on which this succeeds and what is present in the training data. To make progress towards understanding in-context learning, we consider the well-defined problem of training a model to in-context learn a function class (e.g., linear functions): that is, given data derived from some functions in the class, can we train a model to in-context learn "most" functions from this class? We show empirically that standard Transformers can be trained from scratch to perform in-context learning of linear functions -- that is, the trained model is able to learn unseen linear functions from in-context examples with performance comparable to the optimal least squares estimator. In fact, in-context learning is possible even under two forms of distribution shift: (i) between the training data of the model and inference-time prompts, and (ii) between the in-context examples and the query input during inference. We also show that we can train Transformers to in-context learn more complex function classes -- namely sparse linear functions, two-layer neural networks, and decision trees -- with performance that matches or exceeds task-specific learning algorithms. Our code and models are available at https://github.com/dtsip/in-context-learning .
Calibrated ensembles can mitigate accuracy tradeoffs under distribution shift
Jul 18, 2022
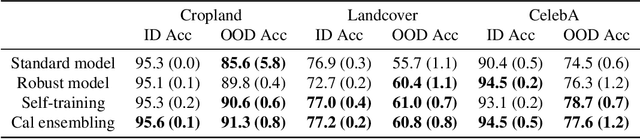
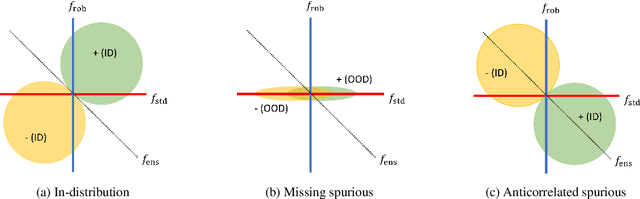
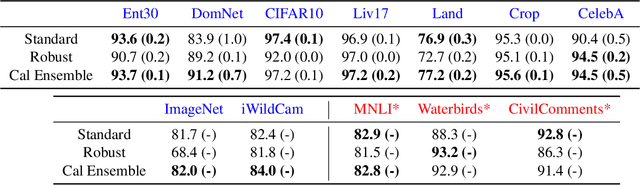
We often see undesirable tradeoffs in robust machine learning where out-of-distribution (OOD) accuracy is at odds with in-distribution (ID) accuracy: a robust classifier obtained via specialized techniques such as removing spurious features often has better OOD but worse ID accuracy compared to a standard classifier trained via ERM. In this paper, we find that ID-calibrated ensembles -- where we simply ensemble the standard and robust models after calibrating on only ID data -- outperforms prior state-of-the-art (based on self-training) on both ID and OOD accuracy. On eleven natural distribution shift datasets, ID-calibrated ensembles obtain the best of both worlds: strong ID accuracy and OOD accuracy. We analyze this method in stylized settings, and identify two important conditions for ensembles to perform well both ID and OOD: (1) we need to calibrate the standard and robust models (on ID data, because OOD data is unavailable), (2) OOD has no anticorrelated spurious features.
Is a Caption Worth a Thousand Images? A Controlled Study for Representation Learning
Jul 15, 2022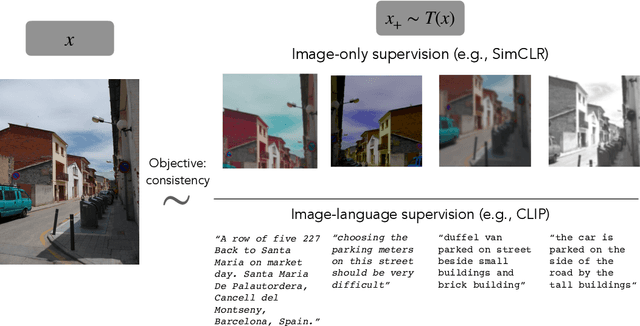
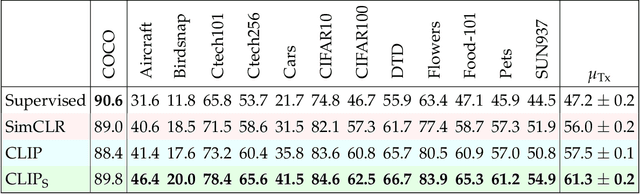

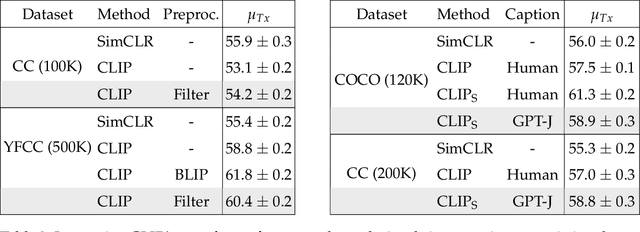
The development of CLIP [Radford et al., 2021] has sparked a debate on whether language supervision can result in vision models with more transferable representations than traditional image-only methods. Our work studies this question through a carefully controlled comparison of two approaches in terms of their ability to learn representations that generalize to downstream classification tasks. We find that when the pre-training dataset meets certain criteria -- it is sufficiently large and contains descriptive captions with low variability -- image-only methods do not match CLIP's transfer performance, even when they are trained with more image data. However, contrary to what one might expect, there are practical settings in which these criteria are not met, wherein added supervision through captions is actually detrimental. Motivated by our findings, we devise simple prescriptions to enable CLIP to better leverage the language information present in existing pre-training datasets.