 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing and Shifting: Exploiting Global and Local Dependencies in Vision MLPs
Feb 14, 2022Token-mixing multi-layer perceptron (MLP) models have shown competitive performance in computer vision tasks with a simple architecture and relatively small computational cost. Their success in maintaining computation efficiency is mainly attributed to avoiding the use of self-attention that is often computationally heavy, yet this is at the expense of not being able to mix tokens both globally and locally. In this paper, to exploit both global and local dependencies without self-attention, we present Mix-Shift-MLP (MS-MLP) which makes the size of the local receptive field used for mixing increase with respect to the amount of spatial shifting. In addition to conventional mixing and shifting techniques, MS-MLP mixes both neighboring and distant tokens from fine- to coarse-grained levels and then gathers them via a shifting operation. This directly contributes to the interactions between global and local tokens. Being simple to implement, MS-MLP achieves competitive performance in multiple vision benchmarks. For example, an MS-MLP with 85 million parameters achieves 83.8% top-1 classification accuracy on ImageNet-1K. Moreover, by combining MS-MLP with state-of-the-art Vision Transformers such as the Swin Transformer, we show MS-MLP achieves further improvements on three different model scales, e.g., by 0.5% on ImageNet-1K classification with Swin-B. The code is available at: https://github.com/JegZheng/MS-MLP.
Human Parity on CommonsenseQA: Augmenting Self-Attention with External Attention
Dec 14, 2021
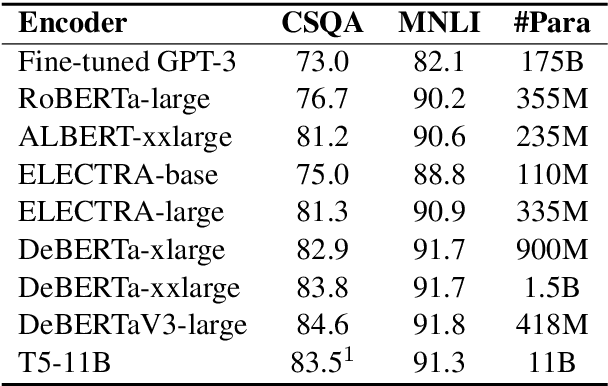
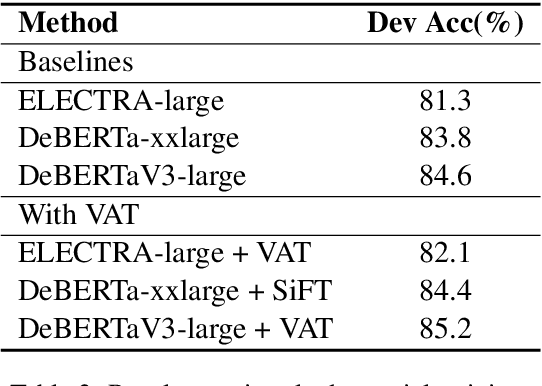

Most of today's AI systems focus on using self-attention mechanisms and transformer architectures on large amounts of diverse data to achieve impressive performance gains. In this paper, we propose to augment the transformer architecture with an external attention mechanism to bring external knowledge and context to bear. By integrating external information into the prediction process, we hope to reduce the need for ever-larger models and increase the democratization of AI systems. We find that the proposed external attention mechanism can significantly improve the performance of existing AI systems, allowing practitioners to easily customize foundation AI models to many diverse downstream applications. In particular, we focus on the task of Commonsense Reasoning, demonstrating that the proposed external attention mechanism can augment existing transformer models and significantly improve the model's reasoning capabilities. The proposed system, Knowledgeable External Attention for commonsense Reasoning (KEAR), reaches human parity on the open CommonsenseQA research benchmark with an accuracy of 89.4\% in comparison to the human accuracy of 88.9\%.
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
Nov 18, 2021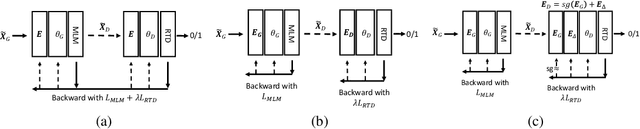
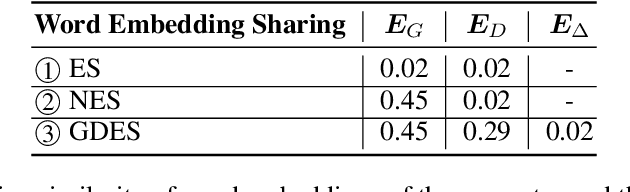
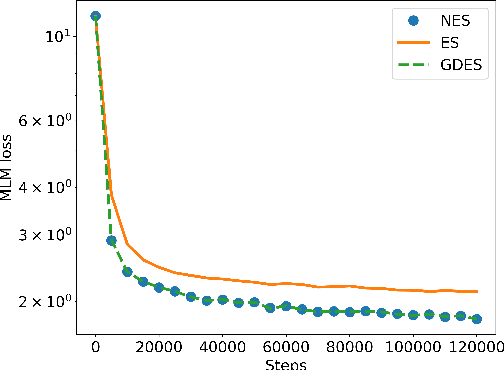
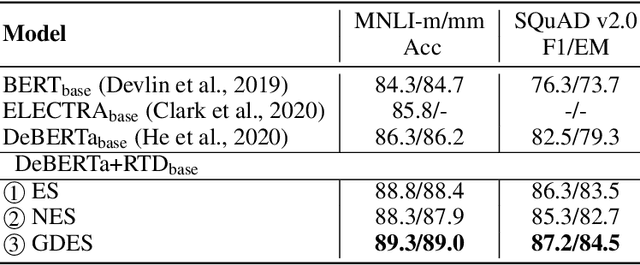
This paper presents a new pre-trained language model, DeBERTaV3, which improves the original DeBERTa model by replacing mask language modeling (MLM) with replaced token detection (RTD), a more sample-efficient pre-training task. Our analysis shows that vanilla embedding sharing in ELECTRA hurts training efficiency and model performance. This is because the training losses of the discriminator and the generator pull token embeddings in different directions, creating the "tug-of-war" dynamics. We thus propose a new gradient-disentangled embedding sharing method that avoids the tug-of-war dynamics, improving both training efficiency and the quality of the pre-trained model. We have pre-trained DeBERTaV3 using the same settings as DeBERTa to demonstrate its exceptional performance on a wide range of downstream natural language understanding (NLU) tasks. Taking the GLUE benchmark with eight tasks as an example, the DeBERTaV3 Large model achieves a 91.37% average score, which is 1.37% over DeBERTa and 1.91% over ELECTRA, setting a new state-of-the-art (SOTA) among the models with a similar structure. Furthermore, we have pre-trained a multi-lingual model mDeBERTa and observed a larger improvement over strong baselines compared to English models. For example, the mDeBERTa Base achieves a 79.8% zero-shot cross-lingual accuracy on XNLI and a 3.6% improvement over XLM-R Base, creating a new SOTA on this benchmark. We have made our pre-trained models and inference code publicly available at https://github.com/microsoft/DeBERTa.
ARCH: Efficient Adversarial Regularized Training with Caching
Sep 15, 2021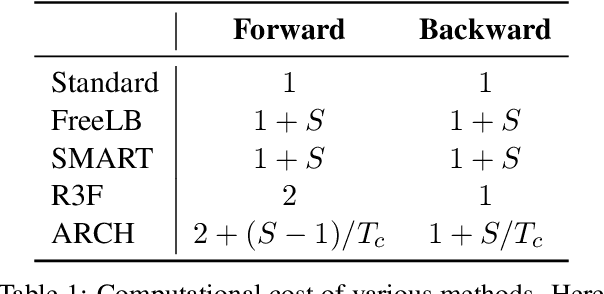
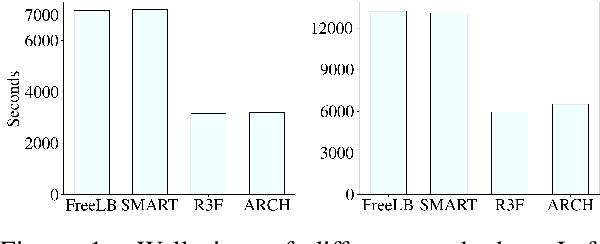
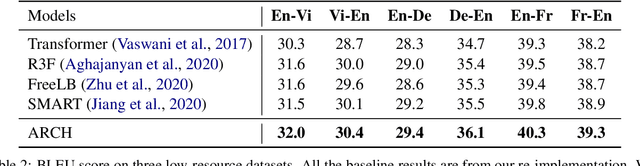
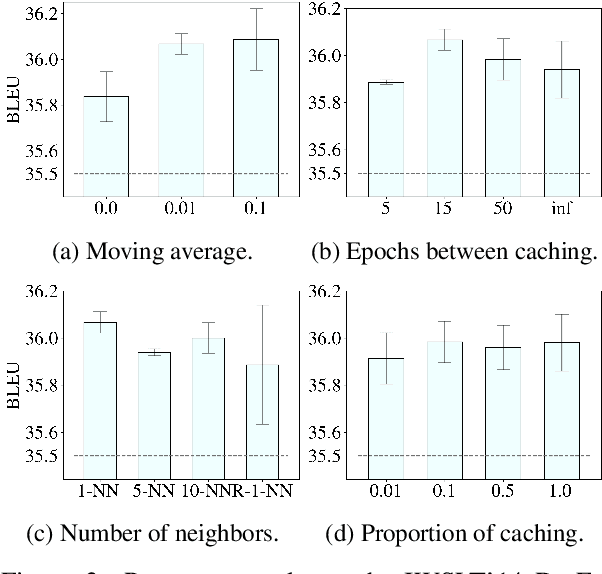
Adversarial regularization can improve model generalization in many natural language processing tasks. However, conventional approaches are computationally expensive since they need to generate a perturbation for each sample in each epoch. We propose a new adversarial regularization method ARCH (adversarial regularization with caching), where perturbations are generated and cached once every several epochs. As caching all the perturbations imposes memory usage concerns, we adopt a K-nearest neighbors-based strategy to tackle this issue. The strategy only requires caching a small amount of perturbations, without introducing additional training time. We evaluate our proposed method on a set of neural machine translation and natural language understanding tasks. We observe that ARCH significantly eases the computational burden (saves up to 70\% of computational time in comparison with conventional approaches). More surprisingly, by reducing the variance of stochastic gradients, ARCH produces a notably better (in most of the tasks) or comparable model generalization. Our code is publicly available.
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization
Jun 08, 2021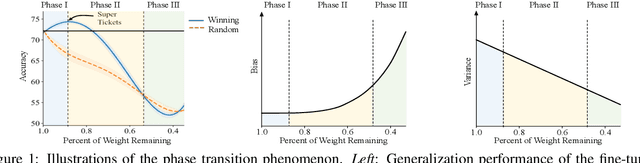

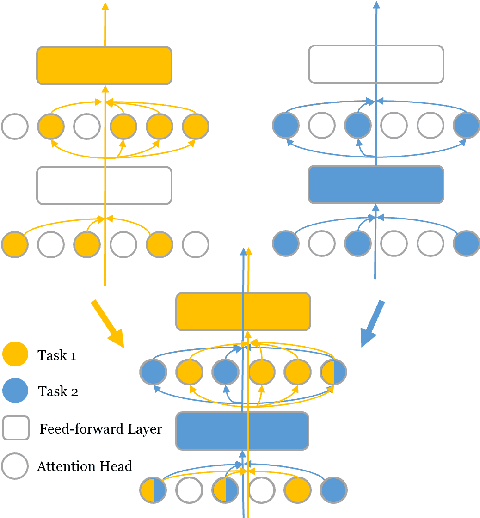

The Lottery Ticket Hypothesis suggests that an over-parametrized network consists of ``lottery tickets'', and training a certain collection of them (i.e., a subnetwork) can match the performance of the full model. In this paper, we study such a collection of tickets, which is referred to as ``winning tickets'', in extremely over-parametrized models, e.g., pre-trained language models. We observe that at certain compression ratios, the generalization performance of the winning tickets can not only match but also exceed that of the full model. In particular, we observe a phase transition phenomenon: As the compression ratio increases, generalization performance of the winning tickets first improves then deteriorates after a certain threshold. We refer to the tickets on the threshold as ``super tickets''. We further show that the phase transition is task and model dependent -- as the model size becomes larger and the training data set becomes smaller, the transition becomes more pronounced. Our experiments on the GLUE benchmark show that the super tickets improve single task fine-tuning by $0.9$ points on BERT-base and $1.0$ points on BERT-large, in terms of task-average score. We also demonstrate that adaptively sharing the super tickets across tasks benefits multi-task learning.
Adversarial Training as Stackelberg Game: An Unrolled Optimization Approach
Apr 11, 2021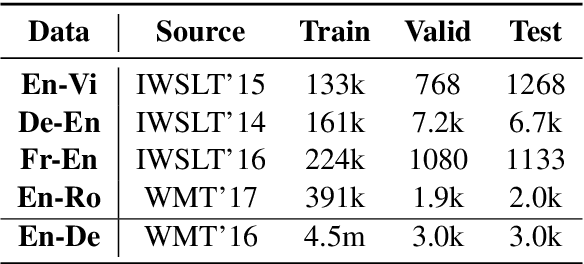
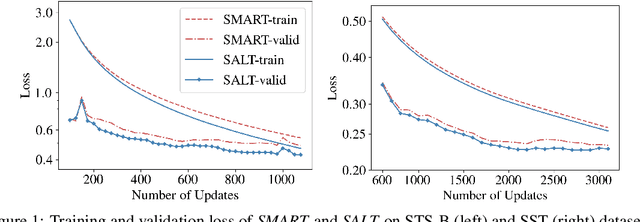
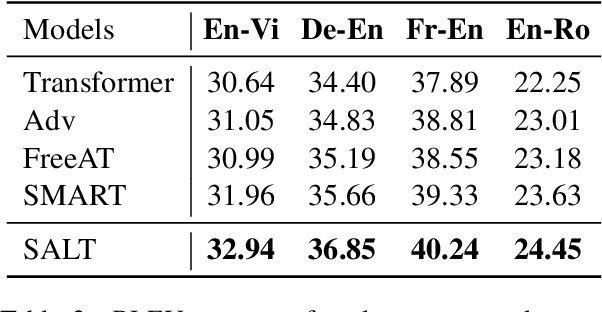
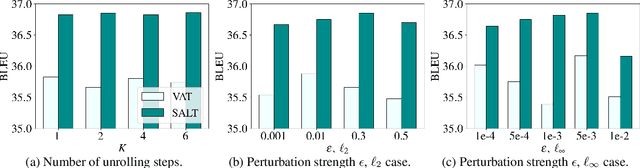
Adversarial training has been shown to improve the generalization performance of deep learning models in various natural language processing tasks. Existing works usually formulate adversarial training as a zero-sum game, which is solved by alternating gradient descent/ascent algorithms. Such a formulation treats the adversarial and the defending players equally, which is undesirable because only the defending player contributes to the generalization performance. To address this issue, we propose Stackelberg Adversarial Training (SALT), which formulates adversarial training as a Stackelberg game. This formulation induces a competition between a leader and a follower, where the follower generates perturbations, and the leader trains the model subject to the perturbations. Different from conventional adversarial training, in SALT, the leader is in an advantageous position. When the leader moves, it recognizes the strategy of the follower and takes the anticipated follower's outcomes into consideration. Such a leader's advantage enables us to improve the model fitting to the unperturbed data. The leader's strategic information is captured by the Stackelberg gradient, which is obtained using an unrolling algorithm. Our experimental results on a set of machine translation and natural language understanding tasks show that SALT outperforms existing adversarial training baselines across all tasks.
Token-wise Curriculum Learning for Neural Machine Translation
Mar 20, 2021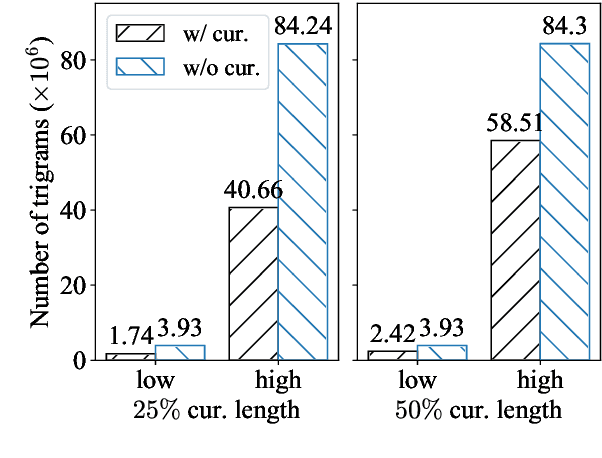
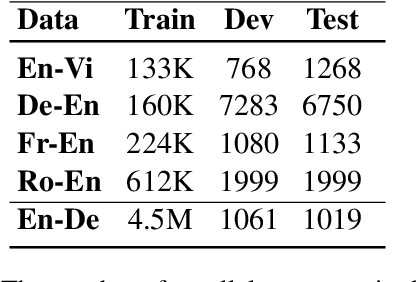
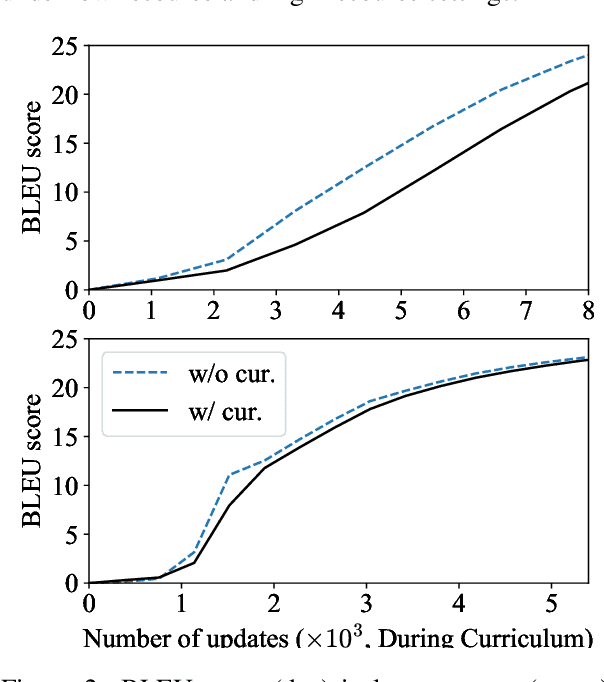
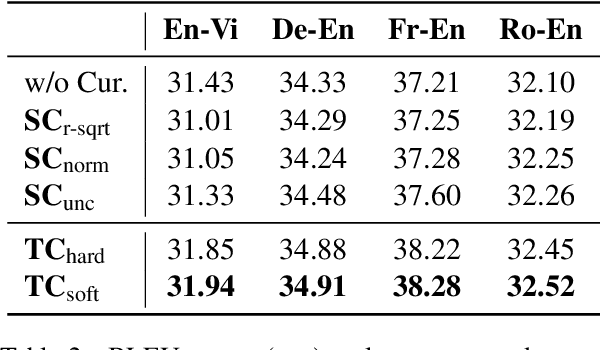
Existing curriculum learning approaches to Neural Machine Translation (NMT) require sampling sufficient amounts of "easy" samples from training data at the early training stage. This is not always achievable for low-resource languages where the amount of training data is limited. To address such limitation, we propose a novel token-wise curriculum learning approach that creates sufficient amounts of easy samples. Specifically, the model learns to predict a short sub-sequence from the beginning part of each target sentence at the early stage of training, and then the sub-sequence is gradually expanded as the training progresses. Such a new curriculum design is inspired by the cumulative effect of translation errors, which makes the latter tokens more difficult to predict than the beginning ones. Extensive experiments show that our approach can consistently outperform baselines on 5 language pairs, especially for low-resource languages. Combining our approach with sentence-level methods further improves the performance on high-resource languages.
Greedy Multi-step Off-Policy Reinforcement Learning
Mar 07, 2021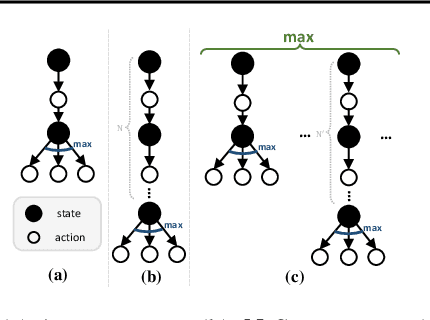
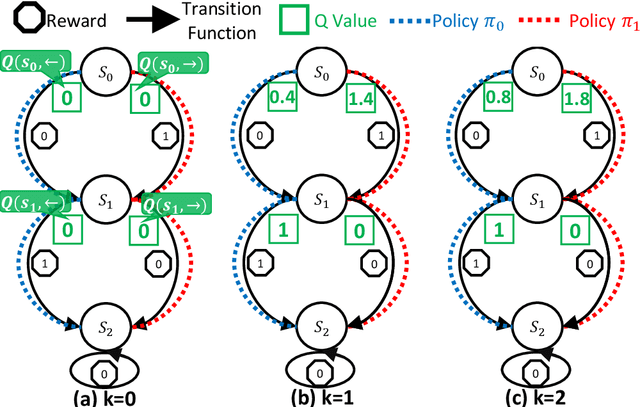
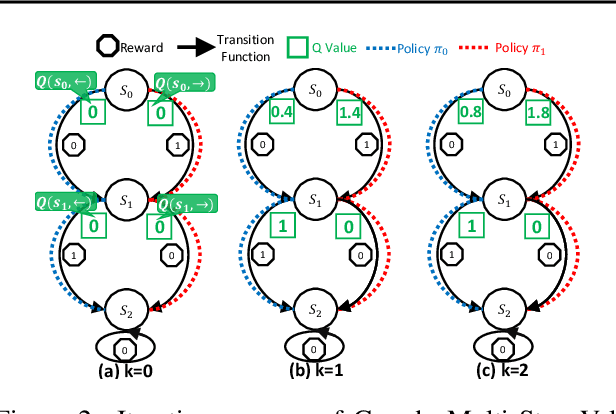
Multi-step off-policy reinforcement learning has achieved great success. However, existing multi-step methods usually impose a fixed prior on the bootstrap steps, while the off-policy methods often require additional correction, suffering from certain undesired effects. In this paper, we propose a novel bootstrapping method, which greedily takes the maximum value among the bootstrapping values with varying steps. The new method has two desired properties:1) it can flexibly adjust the bootstrap step based on the quality of the data and the learned value function; 2) it can safely and robustly utilize data from arbitrary behavior policy without additional correction, whatever its quality or "off-policyness". We analyze the theoretical properties of the related operator, showing that it is able to converge to the global optimal value function, with a ratio faster than the traditional Bellman Optimality Operator. Furthermore, based on this new operator, we derive new model-free RL algorithms named Greedy Multi-Step Q Learning (and Greedy Multi-step DQN). Experiments reveal that the proposed methods are reliable, easy to implement, and achieve state-of-the-art performance on a series of standard benchmark datasets.
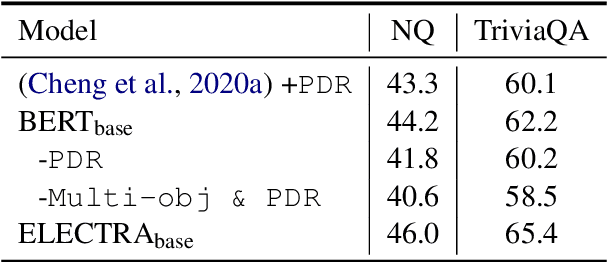
Reader-Guided Passage Reranking for Open-Domain Question Answering
Jan 01, 2021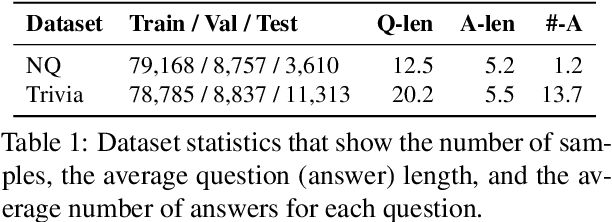
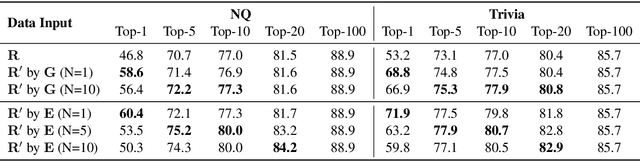
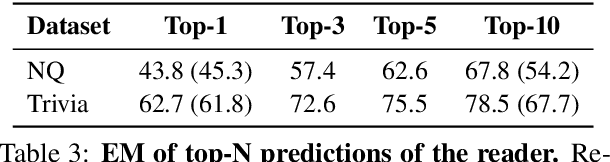
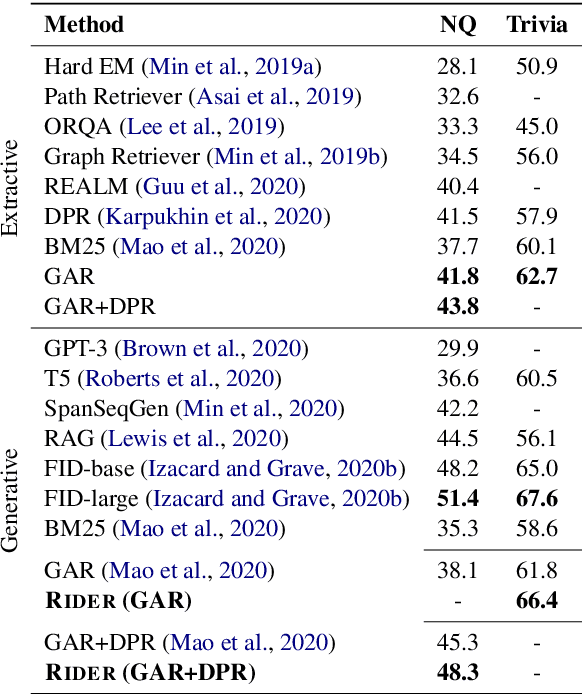
Current open-domain question answering (QA) systems often follow a Retriever-Reader (R2) architecture, where the retriever first retrieves relevant passages and the reader then reads the retrieved passages to form an answer. In this paper, we propose a simple and effective passage reranking method, Reader-guIDEd Reranker (Rider), which does not involve any training and reranks the retrieved passages solely based on the top predictions of the reader before reranking. We show that Rider, despite its simplicity, achieves 10 to 20 absolute gains in top-1 retrieval accuracy and 1 to 4 Exact Match (EM) score gains without refining the retriever or reader. In particular, Rider achieves 48.3 EM on the Natural Questions dataset and 66.4 on the TriviaQA dataset when only 1,024 tokens (7.8 passages on average) are used as the reader input.
UnitedQA: A Hybrid Approach for Open Domain Question Answering
Jan 01, 2021
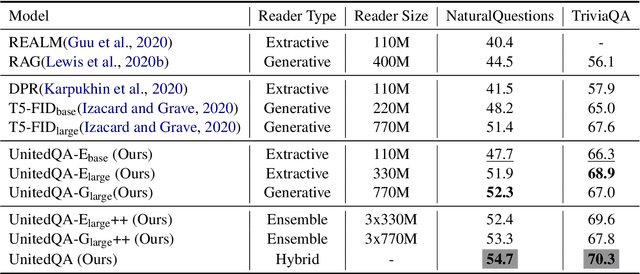
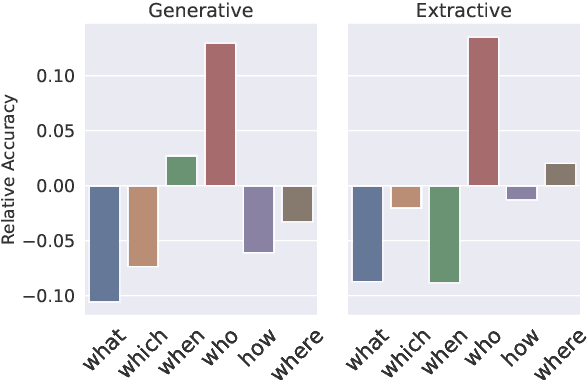
To date, most of recent work under the retrieval-reader framework for open-domain QA focuses on either extractive or generative reader exclusively. In this paper, we study a hybrid approach for leveraging the strengths of both models. We apply novel techniques to enhance both extractive and generative readers built upon recent pretrained neural language models, and find that proper training methods can provide large improvement over previous state-of-the-art models. We demonstrate that a simple hybrid approach by combining answers from both readers can efficiently take advantages of extractive and generative answer inference strategies and outperforms single models as well as homogeneous ensembles. Our approach outperforms previous state-of-the-art models by 3.3 and 2.7 points in exact match on NaturalQuestions and TriviaQA respectively.