 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCLIFD:Supervised Contrastive Knowledge Distillation for Incremental Fault Diagnosis under Limited Fault Data
Feb 12, 2023



Intelligent fault diagnosis has made extraordinary advancements currently. Nonetheless, few works tackle class-incremental learning for fault diagnosis under limited fault data, i.e., imbalanced and long-tailed fault diagnosis, which brings about various notable challenges. Initially, it is difficult to extract discriminative features from limited fault data. Moreover, a well-trained model must be retrained from scratch to classify the samples from new classes, thus causing a high computational burden and time consumption. Furthermore, the model may suffer from catastrophic forgetting when trained incrementally. Finally, the model decision is biased toward the new classes due to the class imbalance. The problems can consequently lead to performance degradation of fault diagnosis models. Accordingly, we introduce a supervised contrastive knowledge distillation for incremental fault diagnosis under limited fault data (SCLIFD) framework to address these issues, which extends the classical incremental classifier and representation learning (iCaRL) framework from three perspectives. Primarily, we adopt supervised contrastive knowledge distillation (KD) to enhance its representation learning capability under limited fault data. Moreover, we propose a novel prioritized exemplar selection method adaptive herding (AdaHerding) to restrict the increase of the computational burden, which is also combined with KD to alleviate catastrophic forgetting. Additionally, we adopt the cosine classifier to mitigate the adverse impact of class imbalance. We conduct extensive experiments on simulated and real-world industrial processes under different imbalance ratios. Experimental results show that our SCLIFD outperforms the existing methods by a large margin.
UnICLAM:Contrastive Representation Learning with Adversarial Masking for Unified and Interpretable Medical Vision Question Answering
Dec 23, 2022



Medical Visual Question Answering (Medical-VQA) aims to to answer clinical questions regarding radiology images, assisting doctors with decision-making options. Nevertheless, current Medical-VQA models learn cross-modal representations through residing vision and texture encoders in dual separate spaces, which lead to indirect semantic alignment. In this paper, we propose UnICLAM, a Unified and Interpretable Medical-VQA model through Contrastive Representation Learning with Adversarial Masking. Specifically, to learn an aligned image-text representation, we first establish a unified dual-stream pre-training structure with the gradually soft-parameter sharing strategy. Technically, the proposed strategy learns a constraint for the vision and texture encoders to be close in a same space, which is gradually loosened as the higher number of layers. Moreover, for grasping the unified semantic representation, we extend the adversarial masking data augmentation to the contrastive representation learning of vision and text in a unified manner. Concretely, while the encoder training minimizes the distance between original and masking samples, the adversarial masking module keeps adversarial learning to conversely maximize the distance. Furthermore, we also intuitively take a further exploration to the unified adversarial masking augmentation model, which improves the potential ante-hoc interpretability with remarkable performance and efficiency. Experimental results on VQA-RAD and SLAKE public benchmarks demonstrate that UnICLAM outperforms existing 11 state-of-the-art Medical-VQA models. More importantly, we make an additional discussion about the performance of UnICLAM in diagnosing heart failure, verifying that UnICLAM exhibits superior few-shot adaption performance in practical disease diagnosis.
Supervised Contrastive Learning with TPE-based Bayesian Optimization of Tabular Data for Imbalanced Learning
Oct 19, 2022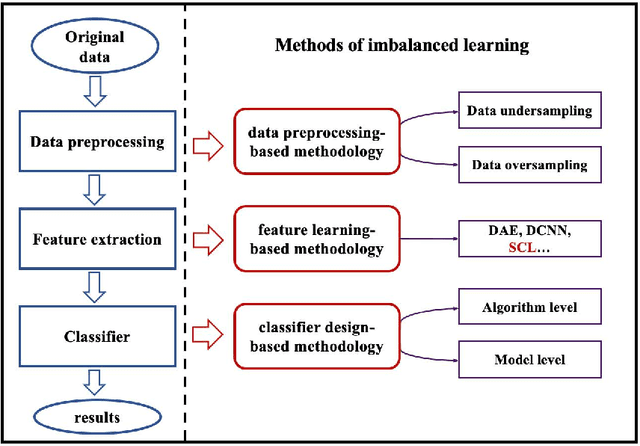
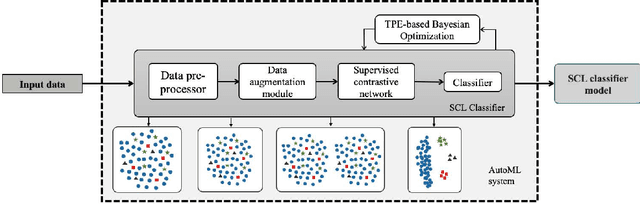
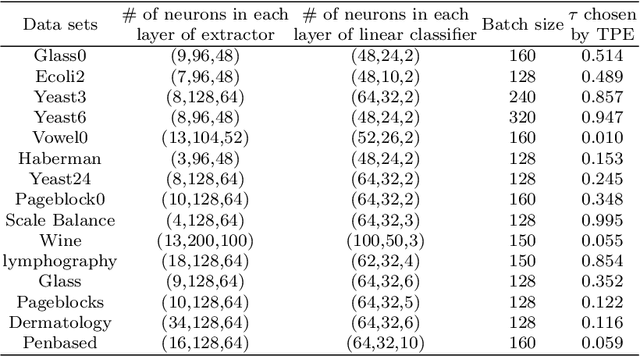
Class imbalance has a detrimental effect on the predictive performance of most supervised learning algorithms as the imbalanced distribution can lead to a bias preferring the majority class. To solve this problem, we propose a Supervised Contrastive Learning (SCL) method with Bayesian optimization technique based on Tree-structured Parzen Estimator (TPE) for imbalanced tabular datasets. Compared with supervised learning, contrastive learning can avoid "label bias" by extracting the information hidden in data. Based on contrastive loss, SCL can exploit the label information to address insufficient data augmentation of tabular data, and is thus used in the proposed SCL-TPE method to learn a discriminative representation of data. Additionally, as the hyper-parameter temperature has a decisive influence on the SCL performance and is difficult to tune, TPE-based Bayesian optimization is introduced to automatically select the best temperature. Experiments are conducted on both binary and multi-class imbalanced tabular datasets. As shown in the results obtained, TPE outperforms other hyper-parameter optimization (HPO) methods such as grid search, random search, and genetic algorithm. More importantly, the proposed SCL-TPE method achieves much-improved performance compared with the state-of-the-art methods.
Evolutionary Game-Theoretical Analysis for General Multiplayer Asymmetric Games
Jun 22, 2022

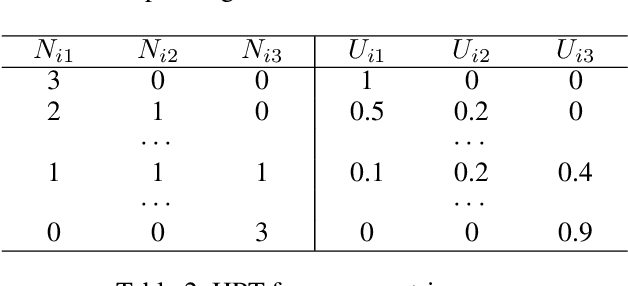
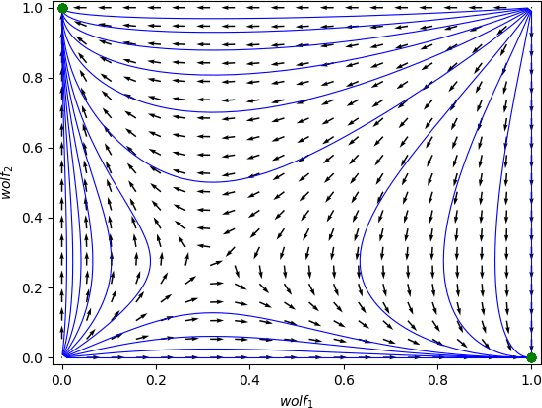
Evolutionary game theory has been a successful tool to combine classical game theory with learning-dynamical descriptions in multiagent systems. Provided some symmetric structures of interacting players, many studies have been focused on using a simplified heuristic payoff table as input to analyse the dynamics of interactions. Nevertheless, even for the state-of-the-art method, there are two limits. First, there is inaccuracy when analysing the simplified payoff table. Second, no existing work is able to deal with 2-population multiplayer asymmetric games. In this paper, we fill the gap between heuristic payoff table and dynamic analysis without any inaccuracy. In addition, we propose a general framework for $m$ versus $n$ 2-population multiplayer asymmetric games. Then, we compare our method with the state-of-the-art in some classic games. Finally, to illustrate our method, we perform empirical game-theoretical analysis on Wolfpack as well as StarCraft II, both of which involve complex multiagent interactions.
Obstacle Avoidance of Resilient UAV Swarm Formation with Active Sensing System in the Dense Environment
Feb 27, 2022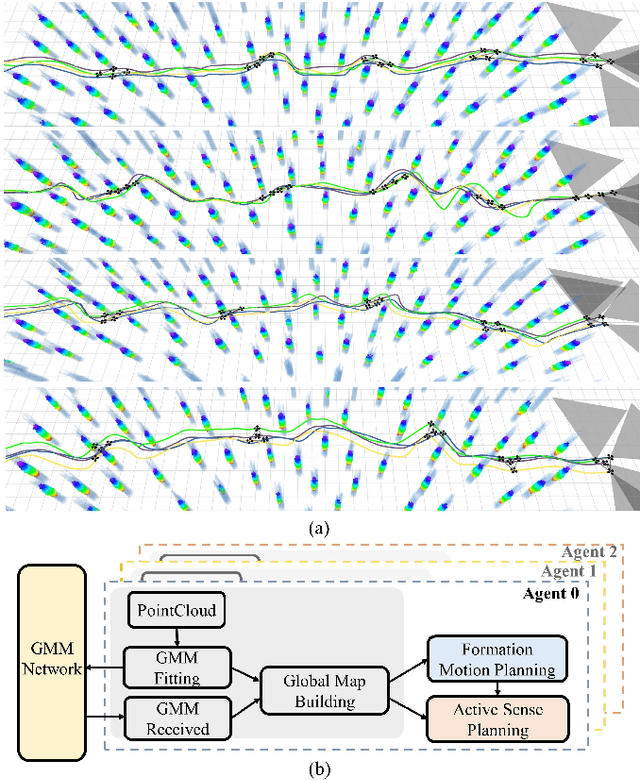
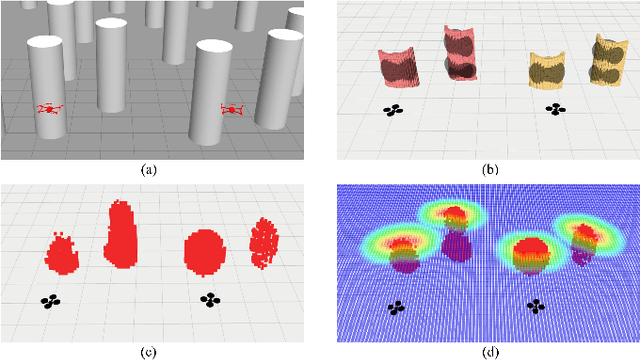
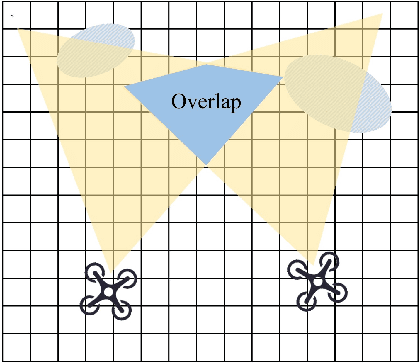
This paper proposes a perception-shared and swarm trajectory global optimal (STGO) algorithm fused UAVs formation motion planning framework aided by an active sensing system. First, the point cloud received by each UAV is fit by the gaussian mixture model (GMM) and transmitted in the swarm. Resampling from the received GMM contributes to a global map, which is used as the foundation for consensus. Second, to improve flight safety, an active sensing system is designed to plan the observation angle of each UAV considering the unknown field, overlap of the field of view (FOV), velocity direction and smoothness of yaw rotation, and this planning problem is solved by the distributed particle swarm optimization (DPSO) algorithm. Last, for the formation motion planning, to ensure obstacle avoidance, the formation structure is allowed for affine transformation and is treated as the soft constraint on the control points of the B-spline. Besides, the STGO is introduced to avoid local minima. The combination of GMM communication and STGO guarantees a safe and strict consensus between UAVs. Tests on different formations in the simulation show that our algorithm can contribute to a strict consensus and has a success rate of at least 80% for obstacle avoidance in a dense environment. Besides, the active sensing system can increase the success rate of obstacle avoidance from 50% to 100% in some scenarios.
Continuous Occupancy Mapping in Dynamic Environments Using Particles
Feb 13, 2022Dynamic occupancy maps were proposed in recent years to model the obstacles in dynamic environments. Among these maps, the particle-based map offers a solid theoretical basis and the ability to model complex-shaped obstacles. Current particle-based maps describe the occupancy status in discrete grid form and suffer from the grid size problem, namely: large grid size is unfavorable for path planning while small grid size lowers efficiency and causes gaps and inconsistencies. To tackle this problem, this paper generalizes the particle-based map into continuous space and builds an efficient 3D local map. A dual-structure subspace division paradigm, composed of a voxel subspace division and a novel pyramid-like subspace division, is proposed to propagate particles and update the map efficiently with the consideration of occlusions. The occupancy status of an arbitrary point can then be estimated with the cardinality expectation. To reduce the noise in modeling static and dynamic obstacles simultaneously, an initial velocity estimation approach and a mixture model are utilized. Experimental results show that our map can effectively and efficiently model both dynamic obstacles and static obstacles. Compared to the state-of-the-art grid-form particle-based map, our map enables continuous occupancy estimation and substantially improves the performance in different resolutions. We also deployed the map on a quadrotor to demonstrate the bright prospect of using this map in obstacle avoidance tasks of small-scale robotics systems.
Risk-aware Trajectory Sampling for Quadrotor Obstacle Avoidance in Dynamic Environments
Jan 17, 2022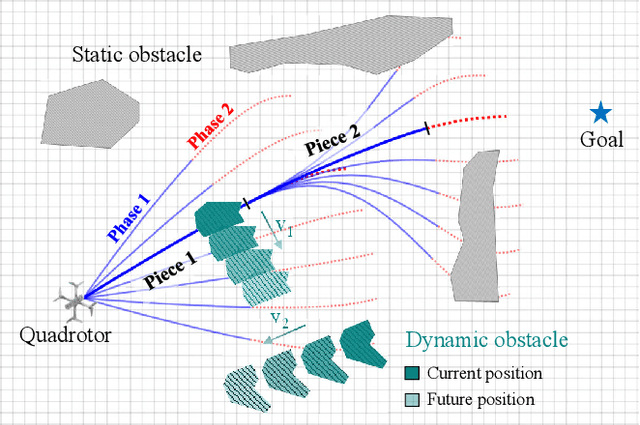
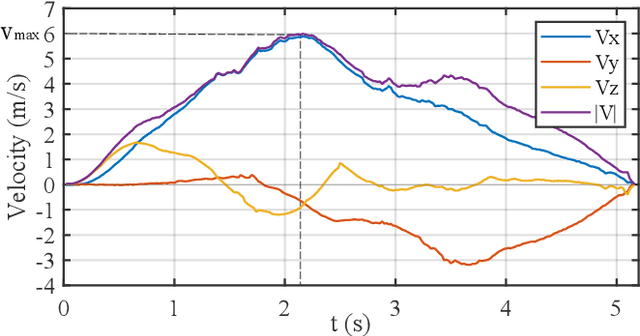
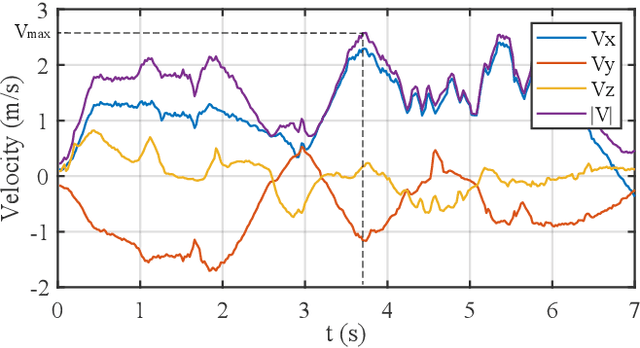
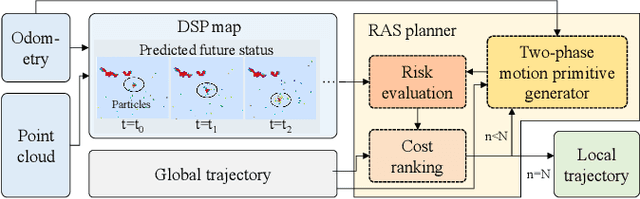
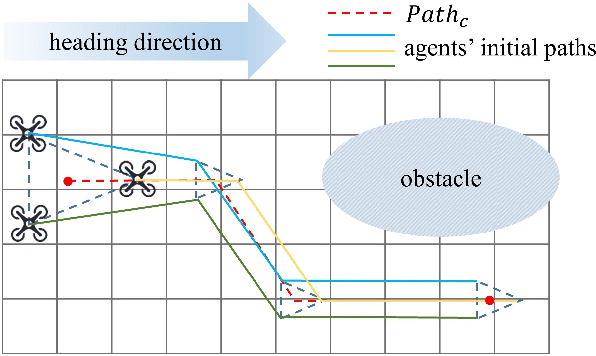
Obstacle avoidance of quadrotors in dynamic environments, with both static and dynamic obstacles, is still a very open problem. Current works commonly leverage traditional static maps to represent static obstacles and the detection and tracking of moving objects (DATMO) method to model dynamic obstacles separately. The dynamic obstacles are pre-trained in the detector and can only be modeled with certain shapes, such as cylinders or ellipsoids. This work utilizes our dual-structure particle-based (DSP) dynamic occupancy map to represent the arbitrary-shaped static obstacles and dynamic obstacles simultaneously and proposes an efficient risk-aware sampling-based local trajectory planner to realize safe flights in this map. The trajectory is planned by sampling motion primitives generated in the state space. Each motion primitive is divided into two phases: short-term planning with a strict risk limitation and relatively long-term planning designed to avoid high-risk regions. The risk is evaluated with the predicted future occupancy status, represented by particles, considering the time dimension. With an approach to split from and merge to global trajectories, the planner can also be used with an arbitrary preplanned global trajectory. Comparison experiments show that the obstacle avoidance system composed of the DSP map and our planner performs the best in dynamic environments. In real-world tests, our quadrotor reaches a speed of 6 m/s with the motion capture system and 2 m/s with everything computed on a low-price single board computer.
Robust Visual Odometry Using Position-Aware Flow and Geometric Bundle Adjustment
Nov 22, 2021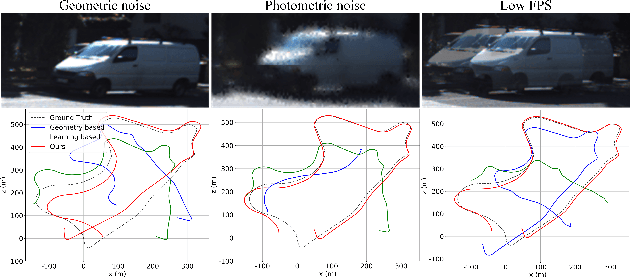
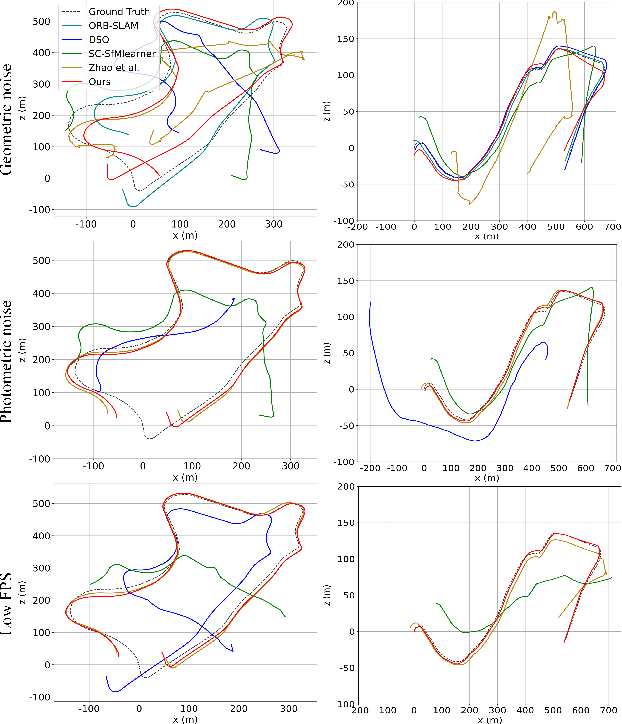
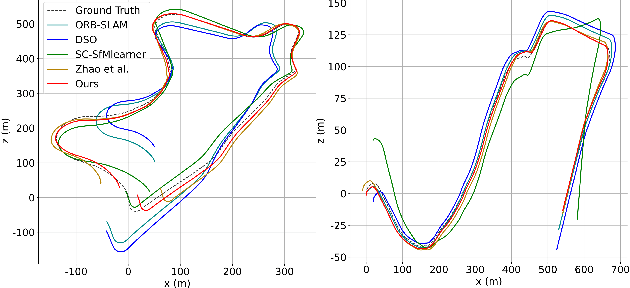

In this paper, an essential problem of robust visual odometry (VO) is approached by incorporating geometry-based methods into deep-learning architecture in a self-supervised manner. Generally, pure geometry-based algorithms are not as robust as deep learning in feature-point extraction and matching, but perform well in ego-motion estimation because of their well-established geometric theory. In this work, a novel optical flow network (PANet) built on a position-aware mechanism is proposed first. Then, a novel system that jointly estimates depth, optical flow, and ego-motion without a typical network to learning ego-motion is proposed. The key component of the proposed system is an improved bundle adjustment module containing multiple sampling, initialization of ego-motion, dynamic damping factor adjustment, and Jacobi matrix weighting. In addition, a novel relative photometric loss function is advanced to improve the depth estimation accuracy. The experiments show that the proposed system not only outperforms other state-of-the-art methods in terms of depth, flow, and VO estimation among self-supervised learning-based methods on KITTI dataset, but also significantly improves robustness compared with geometry-based, learning-based and hybrid VO systems. Further experiments show that our model achieves outstanding generalization ability and performance in challenging indoor (TMU-RGBD) and outdoor (KAIST) scenes.
Thermal Infrared Image Colorization for Nighttime Driving Scenes with Top-Down Guided Attention
Apr 29, 2021


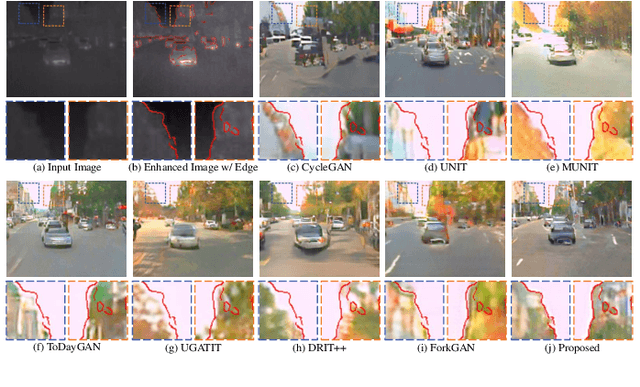
Benefitting from insensitivity to light and high penetration of foggy environments, infrared cameras are widely used for sensing in nighttime traffic scenes. However, the low contrast and lack of chromaticity of thermal infrared (TIR) images hinder the human interpretation and portability of high-level computer vision algorithms. Colorization to translate a nighttime TIR image into a daytime color (NTIR2DC) image may be a promising way to facilitate nighttime scene perception. Despite recent impressive advances in image translation, semantic encoding entanglement and geometric distortion in the NTIR2DC task remain under-addressed. Hence, we propose a toP-down attEntion And gRadient aLignment based GAN, referred to as PearlGAN. A top-down guided attention module and an elaborate attentional loss are first designed to reduce the semantic encoding ambiguity during translation. Then, a structured gradient alignment loss is introduced to encourage edge consistency between the translated and input images. In addition, pixel-level annotation is carried out on a subset of FLIR and KAIST datasets to evaluate the semantic preservation performance of multiple translation methods. Furthermore, a new metric is devised to evaluate the geometric consistency in the translation process. Extensive experiments demonstrate the superiority of the proposed PearlGAN over other image translation methods for the NTIR2DC task. The source code and labeled segmentation masks will be available at \url{https://github.com/FuyaLuo/PearlGAN/}.
SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft II
Dec 24, 2020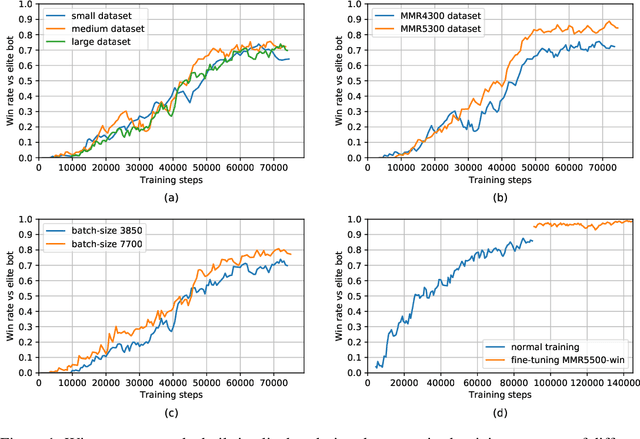
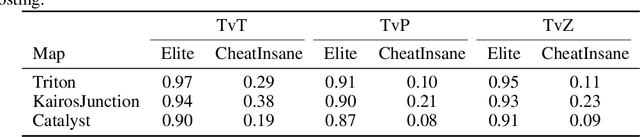
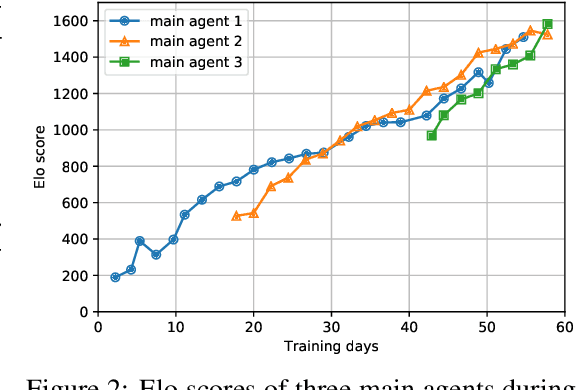
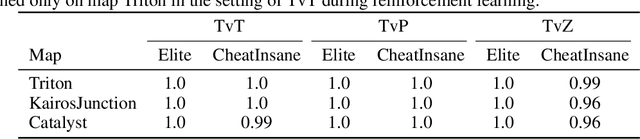
AlphaStar, the AI that reaches GrandMaster level in StarCraft II, is a remarkable milestone demonstrating what deep reinforcement learning can achieve in complex Real-Time Strategy (RTS) games. However, the complexities of the game, algorithms and systems, and especially the tremendous amount of computation needed are big obstacles for the community to conduct further research in this direction. We propose a deep reinforcement learning agent, StarCraft Commander (SCC). With order of magnitude less computation, it demonstrates top human performance defeating GrandMaster players in test matches and top professional players in a live event. Moreover, it shows strong robustness to various human strategies and discovers novel strategies unseen from human plays. In this paper, we will share the key insights and optimizations on efficient imitation learning and reinforcement learning for StarCraft II full game.