 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernelized Heterogeneous Risk Minimization
Oct 24, 2021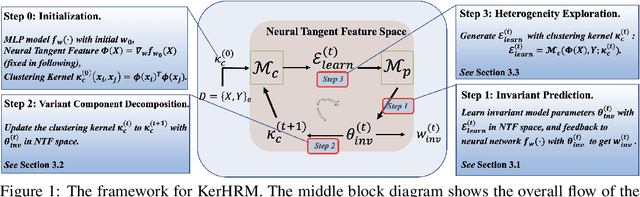
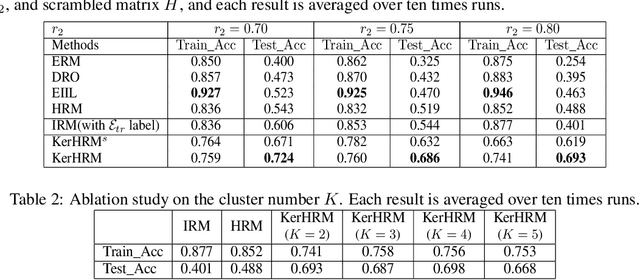
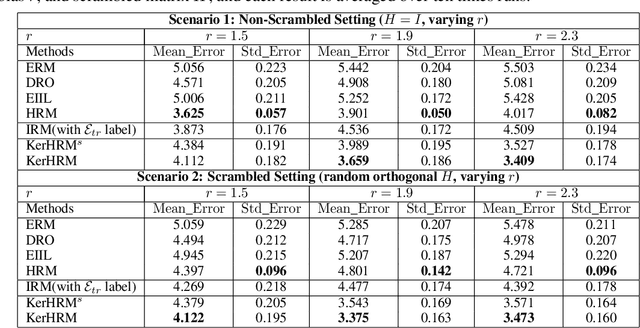
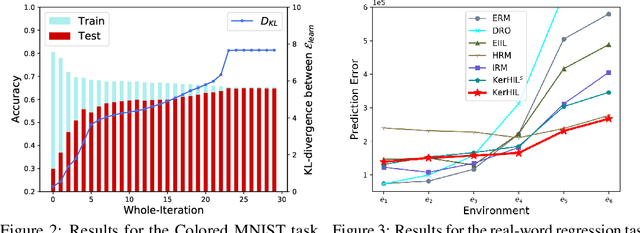
The ability to generalize under distributional shifts is essential to reliable machine learning, while models optimized with empirical risk minimization usually fail on non-$i.i.d$ testing data. Recently, invariant learning methods for out-of-distribution (OOD) generalization propose to find causally invariant relationships with multi-environments. However, modern datasets are frequently multi-sourced without explicit source labels, rendering many invariant learning methods inapplicable. In this paper, we propose Kernelized Heterogeneous Risk Minimization (KerHRM) algorithm, which achieves both the latent heterogeneity exploration and invariant learning in kernel space, and then gives feedback to the original neural network by appointing invariant gradient direction. We theoretically justify our algorithm and empirically validate the effectiveness of our algorithm with extensive experiments.
ListReader: Extracting List-form Answers for Opinion Questions
Oct 22, 2021

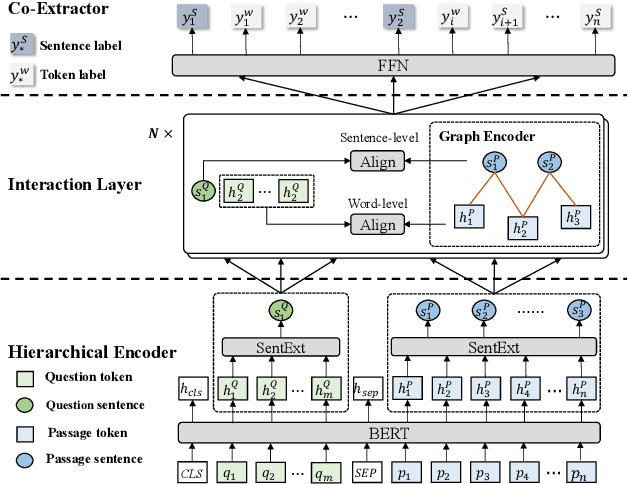
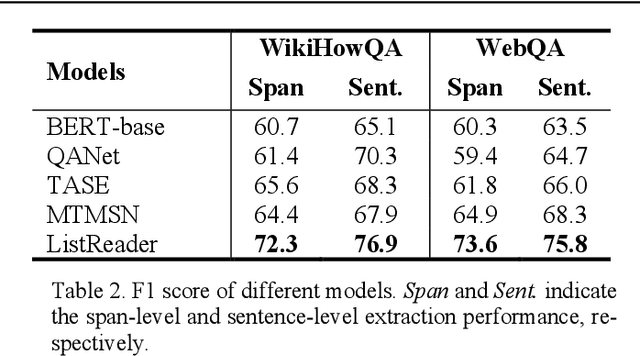
Question answering (QA) is a high-level ability of natural language processing. Most extractive ma-chine reading comprehension models focus on factoid questions (e.g., who, when, where) and restrict the output answer as a short and continuous span in the original passage. However, in real-world scenarios, many questions are non-factoid (e.g., how, why) and their answers are organized in the list format that contains multiple non-contiguous spans. Naturally, existing extractive models are by design unable to answer such questions. To address this issue, this paper proposes ListReader, a neural ex-tractive QA model for list-form answer. In addition to learning the alignment between the question and content, we introduce a heterogeneous graph neural network to explicitly capture the associations among candidate segments. Moreover, our model adopts a co-extraction setting that can extract either span- or sentence-level answers, allowing better applicability. Two large-scale datasets of different languages are constructed to support this study. Experimental results show that our model considerably outperforms various strong baselines. Further discussions provide an intuitive understanding of how our model works and where the performance gain comes from.
Topic-Guided Abstractive Multi-Document Summarization
Oct 21, 2021
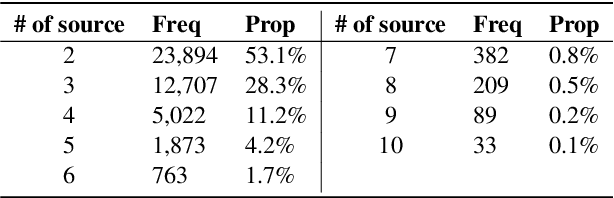
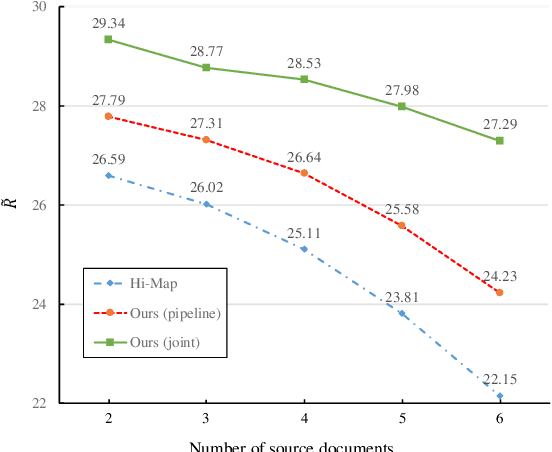
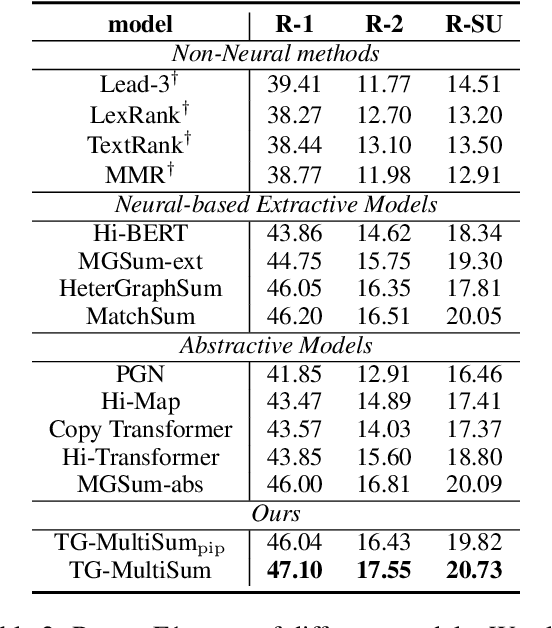
A critical point of multi-document summarization (MDS) is to learn the relations among various documents. In this paper, we propose a novel abstractive MDS model, in which we represent multiple documents as a heterogeneous graph, taking semantic nodes of different granularities into account, and then apply a graph-to-sequence framework to generate summaries. Moreover, we employ a neural topic model to jointly discover latent topics that can act as cross-document semantic units to bridge different documents and provide global information to guide the summary generation. Since topic extraction can be viewed as a special type of summarization that "summarizes" texts into a more abstract format, i.e., a topic distribution, we adopt a multi-task learning strategy to jointly train the topic and summarization module, allowing the promotion of each other. Experimental results on the Multi-News dataset demonstrate that our model outperforms previous state-of-the-art MDS models on both Rouge metrics and human evaluation, meanwhile learns high-quality topics.
Towards Out-Of-Distribution Generalization: A Survey
Aug 31, 2021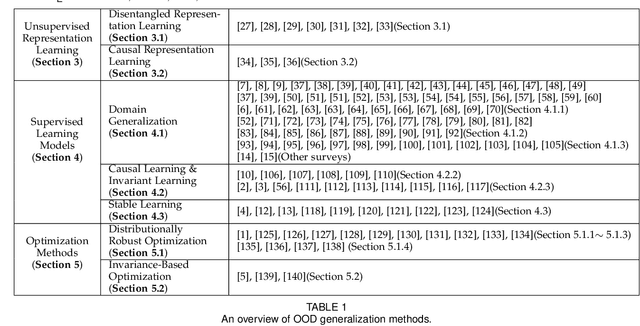
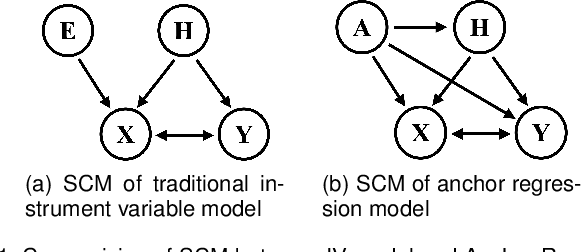
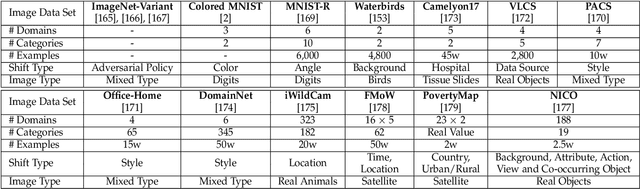
Classic machine learning methods are built on the $i.i.d.$ assumption that training and testing data are independent and identically distributed. However, in real scenarios, the $i.i.d.$ assumption can hardly be satisfied, rendering the sharp drop of classic machine learning algorithms' performances under distributional shifts, which indicates the significance of investigating the Out-of-Distribution generalization problem. Out-of-Distribution (OOD) generalization problem addresses the challenging setting where the testing distribution is unknown and different from the training. This paper serves as the first effort to systematically and comprehensively discuss the OOD generalization problem, from the definition, methodology, evaluation to the implications and future directions. Firstly, we provide the formal definition of the OOD generalization problem. Secondly, existing methods are categorized into three parts based on their positions in the whole learning pipeline, namely unsupervised representation learning, supervised model learning and optimization, and typical methods for each category are discussed in detail. We then demonstrate the theoretical connections of different categories, and introduce the commonly used datasets and evaluation metrics. Finally, we summarize the whole literature and raise some future directions for OOD generalization problem. The summary of OOD generalization methods reviewed in this survey can be found at http://out-of-distribution-generalization.com.
Domain-Irrelevant Representation Learning for Unsupervised Domain Generalization
Jul 13, 2021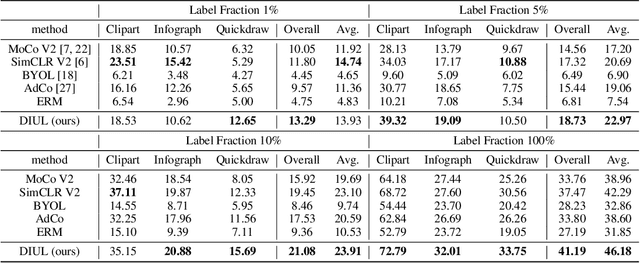
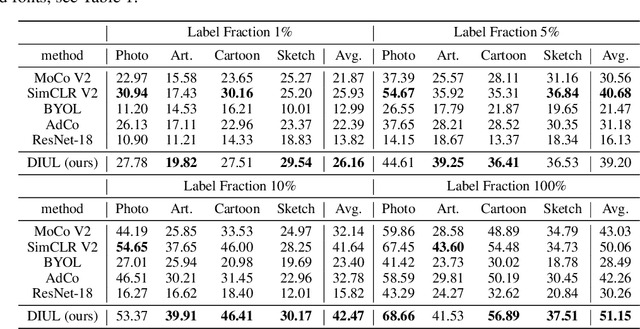
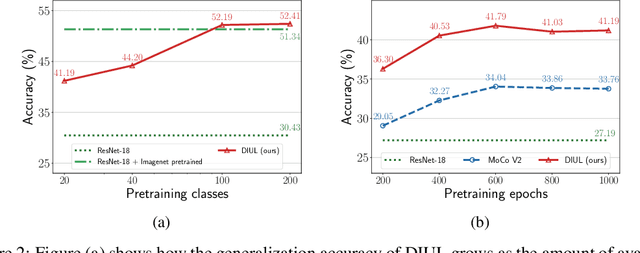
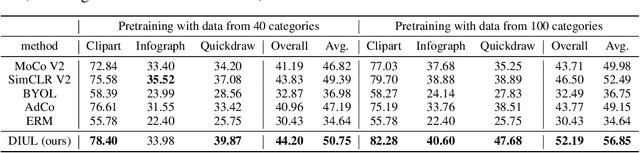
Domain generalization (DG) aims to help models trained on a set of source domains generalize better on unseen target domains. The performances of current DG methods largely rely on sufficient labeled data, which however are usually costly or unavailable. While unlabeled data are far more accessible, we seek to explore how unsupervised learning can help deep models generalizes across domains. Specifically, we study a novel generalization problem called unsupervised domain generalization, which aims to learn generalizable models with unlabeled data. Furthermore, we propose a Domain-Irrelevant Unsupervised Learning (DIUL) method to cope with the significant and misleading heterogeneity within unlabeled data and severe distribution shifts between source and target data. Surprisingly we observe that DIUL can not only counterbalance the scarcity of labeled data but also further strengthen the generalization ability of models when the labeled data are sufficient. As a pretraining approach, DIUL shows superior to ImageNet pretraining protocol even when the available data are unlabeled and of a greatly smaller amount compared to ImageNet. Extensive experiments clearly demonstrate the effectiveness of our method compared with state-of-the-art unsupervised learning counterparts.
Context-Aware Attention-Based Data Augmentation for POI Recommendation
Jun 30, 2021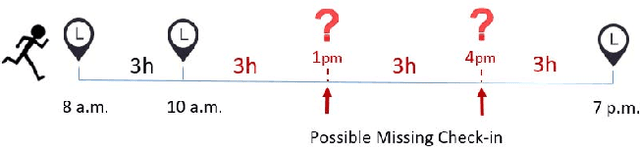
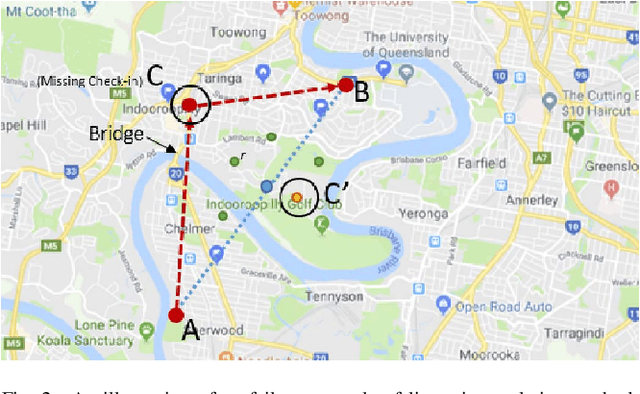
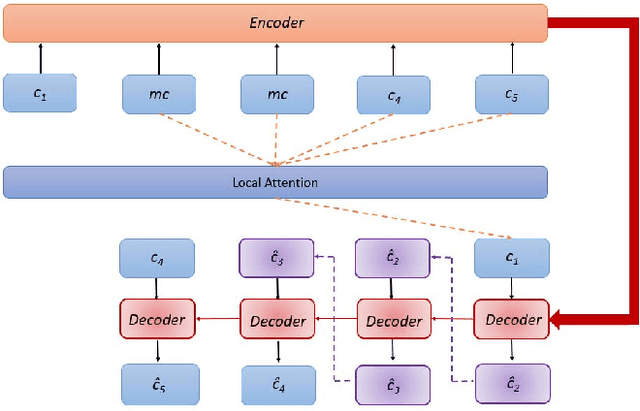
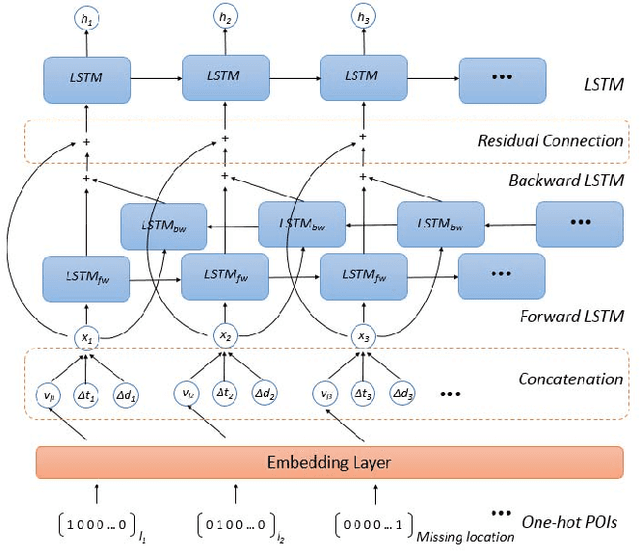
With the rapid growth of location-based social networks (LBSNs), Point-Of-Interest (POI) recommendation has been broadly studied in this decade. Recently, the next POI recommendation, a natural extension of POI recommendation, has attracted much attention. It aims at suggesting the next POI to a user in spatial and temporal context, which is a practical yet challenging task in various applications. Existing approaches mainly model the spatial and temporal information, and memorize historical patterns through user's trajectories for recommendation. However, they suffer from the negative impact of missing and irregular check-in data, which significantly influences the model performance. In this paper, we propose an attention-based sequence-to-sequence generative model, namely POI-Augmentation Seq2Seq (PA-Seq2Seq), to address the sparsity of training set by making check-in records to be evenly-spaced. Specifically, the encoder summarises each check-in sequence and the decoder predicts the possible missing check-ins based on the encoded information. In order to learn time-aware correlation among user history, we employ local attention mechanism to help the decoder focus on a specific range of context information when predicting a certain missing check-in point. Extensive experiments have been conducted on two real-world check-in datasets, Gowalla and Brightkite, for performance and effectiveness evaluation.
Distributionally Robust Learning with Stable Adversarial Training
Jun 30, 2021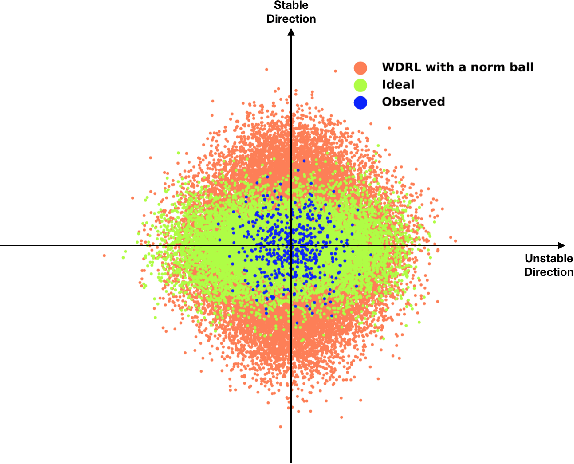
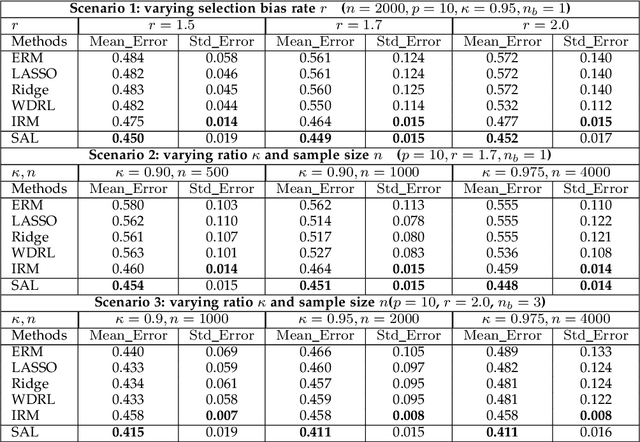
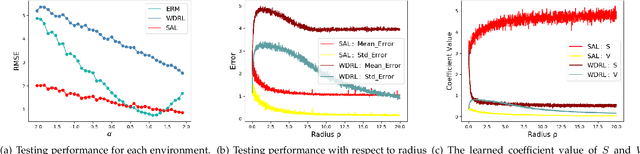
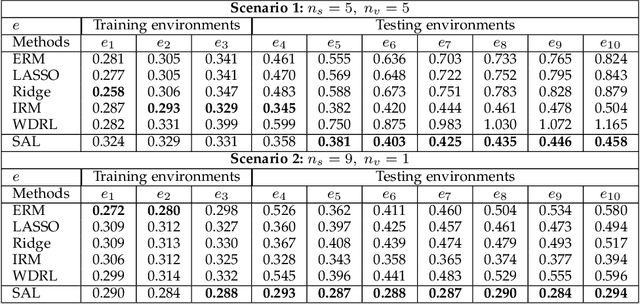
Machine learning algorithms with empirical risk minimization are vulnerable under distributional shifts due to the greedy adoption of all the correlations found in training data. There is an emerging literature on tackling this problem by minimizing the worst-case risk over an uncertainty set. However, existing methods mostly construct ambiguity sets by treating all variables equally regardless of the stability of their correlations with the target, resulting in the overwhelmingly-large uncertainty set and low confidence of the learner. In this paper, we propose a novel Stable Adversarial Learning (SAL) algorithm that leverages heterogeneous data sources to construct a more practical uncertainty set and conduct differentiated robustness optimization, where covariates are differentiated according to the stability of their correlations with the target. We theoretically show that our method is tractable for stochastic gradient-based optimization and provide the performance guarantees for our method. Empirical studies on both simulation and real datasets validate the effectiveness of our method in terms of uniformly good performance across unknown distributional shifts.
Adversarial Attack Framework on Graph Embedding Models with Limited Knowledge
May 26, 2021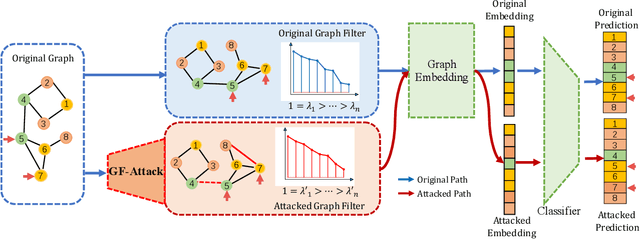



With the success of the graph embedding model in both academic and industry areas, the robustness of graph embedding against adversarial attack inevitably becomes a crucial problem in graph learning. Existing works usually perform the attack in a white-box fashion: they need to access the predictions/labels to construct their adversarial loss. However, the inaccessibility of predictions/labels makes the white-box attack impractical to a real graph learning system. This paper promotes current frameworks in a more general and flexible sense -- we demand to attack various kinds of graph embedding models with black-box driven. We investigate the theoretical connections between graph signal processing and graph embedding models and formulate the graph embedding model as a general graph signal process with a corresponding graph filter. Therefore, we design a generalized adversarial attacker: GF-Attack. Without accessing any labels and model predictions, GF-Attack can perform the attack directly on the graph filter in a black-box fashion. We further prove that GF-Attack can perform an effective attack without knowing the number of layers of graph embedding models. To validate the generalization of GF-Attack, we construct the attacker on four popular graph embedding models. Extensive experiments validate the effectiveness of GF-Attack on several benchmark datasets.
Heterogeneous Risk Minimization
May 09, 2021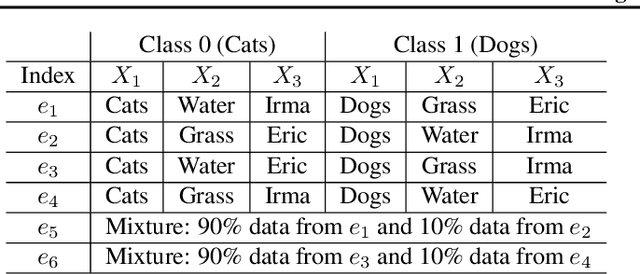

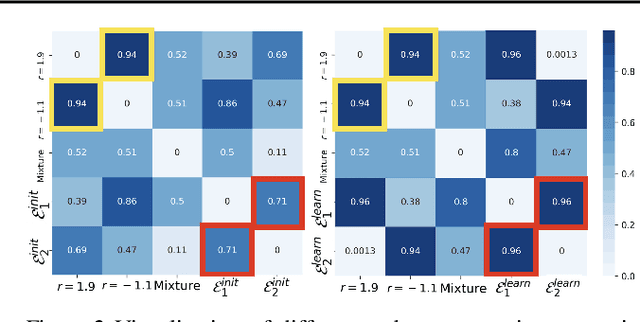
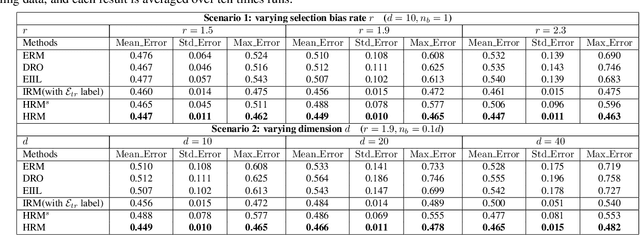
Machine learning algorithms with empirical risk minimization usually suffer from poor generalization performance due to the greedy exploitation of correlations among the training data, which are not stable under distributional shifts. Recently, some invariant learning methods for out-of-distribution (OOD) generalization have been proposed by leveraging multiple training environments to find invariant relationships. However, modern datasets are frequently assembled by merging data from multiple sources without explicit source labels. The resultant unobserved heterogeneity renders many invariant learning methods inapplicable. In this paper, we propose Heterogeneous Risk Minimization (HRM) framework to achieve joint learning of latent heterogeneity among the data and invariant relationship, which leads to stable prediction despite distributional shifts. We theoretically characterize the roles of the environment labels in invariant learning and justify our newly proposed HRM framework. Extensive experimental results validate the effectiveness of our HRM framework.
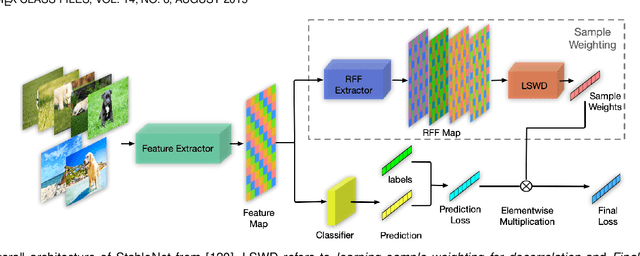
Deep Stable Learning for Out-Of-Distribution Generalization
Apr 16, 2021
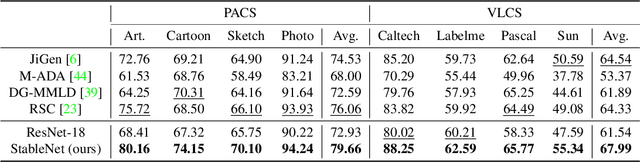
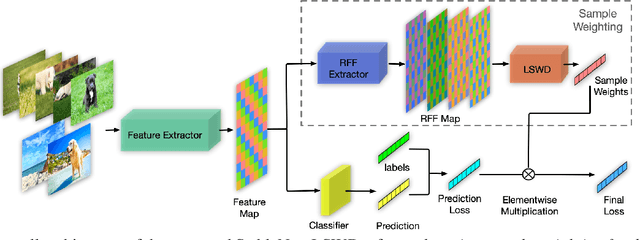
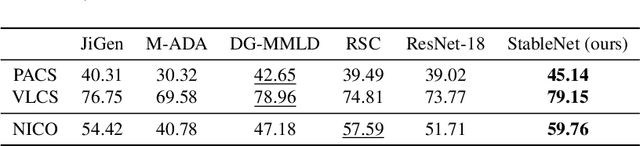
Approaches based on deep neural networks have achieved striking performance when testing data and training data share similar distribution, but can significantly fail otherwise. Therefore, eliminating the impact of distribution shifts between training and testing data is crucial for building performance-promising deep models. Conventional methods assume either the known heterogeneity of training data (e.g. domain labels) or the approximately equal capacities of different domains. In this paper, we consider a more challenging case where neither of the above assumptions holds. We propose to address this problem by removing the dependencies between features via learning weights for training samples, which helps deep models get rid of spurious correlations and, in turn, concentrate more on the true connection between discriminative features and labels. Extensive experiments clearly demonstrate the effectiveness of our method on multiple distribution generalization benchmarks compared with state-of-the-art counterparts. Through extensive experiments on distribution generalization benchmarks including PACS, VLCS, MNIST-M, and NICO, we show the effectiveness of our method compared with state-of-the-art counterparts.