 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast tree skeleton extraction using voxel thinning based on tree point cloud
Oct 18, 2021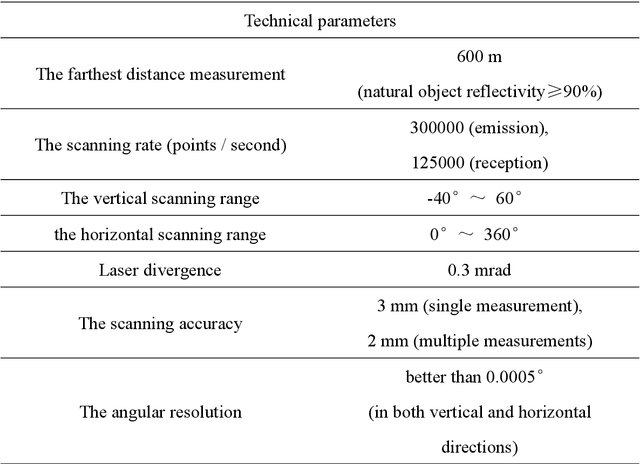
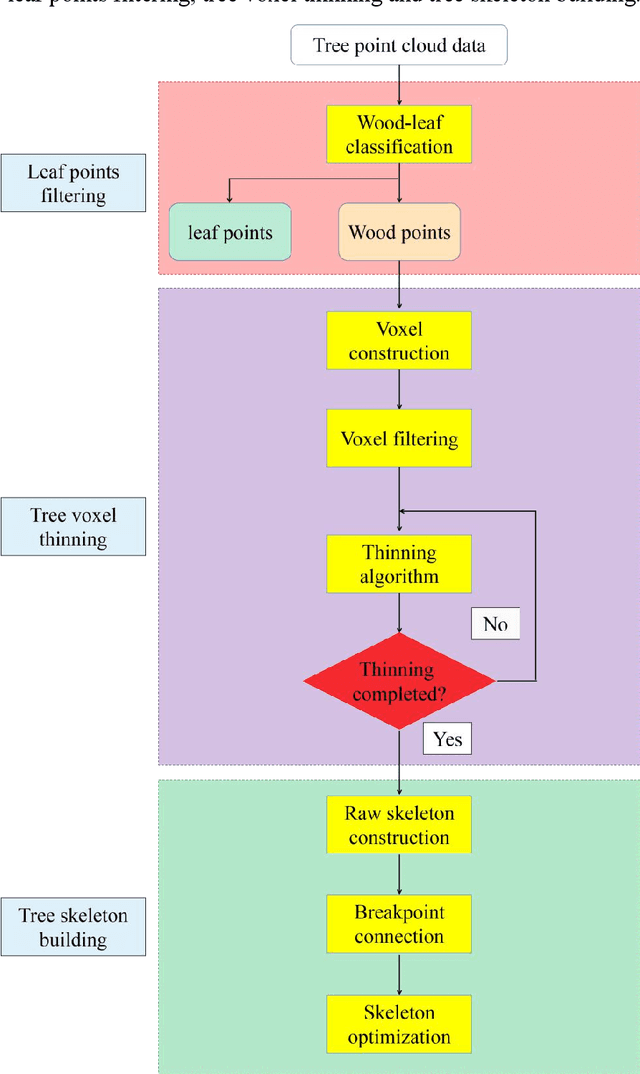
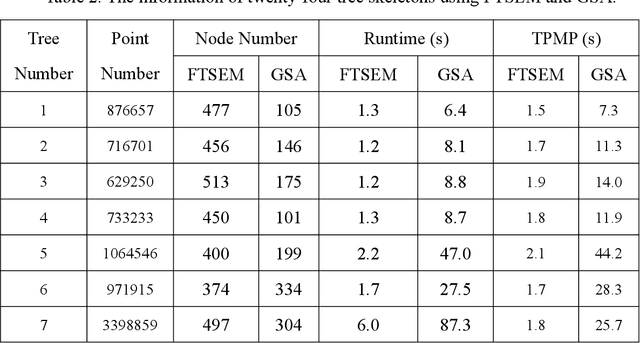
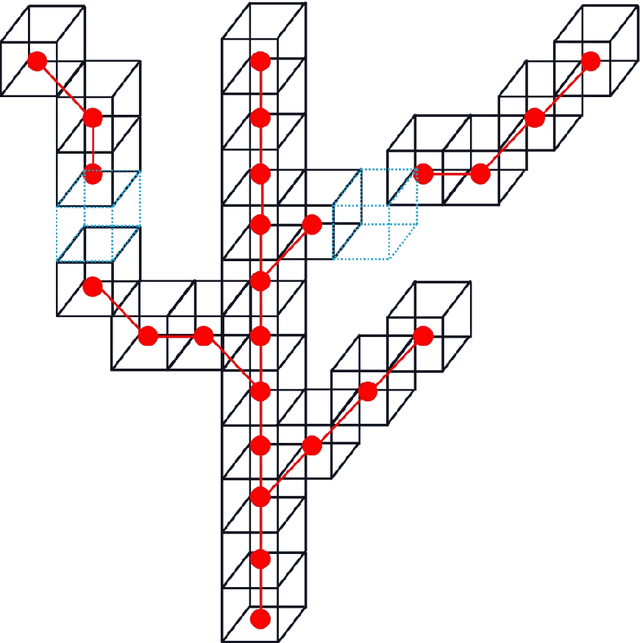
Tree skeleton plays an important role in tree structure analysis, forest inventory and ecosystem monitoring. However, it is a challenge to extract a skeleton from a tree point cloud with complex branches. In this paper, an automatic and fast tree skeleton extraction method (FTSEM) based on voxel thinning is proposed. In this method, a wood-leaf classification algorithm was introduced to filter leaf points for the reduction of the leaf interference on tree skeleton generation, tree voxel thinning was adopted to extract raw tree skeleton quickly, and a breakpoint connection algorithm was used to improve the skeleton connectivity and completeness. Experiments were carried out in Haidian Park, Beijing, in which 24 trees were scanned and processed to obtain tree skeletons. The graph search algorithm (GSA) is used to extract tree skeletons based on the same datasets. Compared with GSA method, the FTSEM method obtained more complete tree skeletons. And the time cost of the FTSEM method is evaluated using the runtime and time per million points (TPMP). The runtime of FTSEM is from 1.0 s to 13.0 s, and the runtime of GSA is from 6.4 s to 309.3 s. The average value of TPMP is 1.8 s for FTSEM, and 22.3 s for GSA respectively. The experimental results demonstrate that the proposed method is feasible, robust, and fast with a good potential on tree skeleton extraction.
SDTP: Semantic-aware Decoupled Transformer Pyramid for Dense Image Prediction
Sep 18, 2021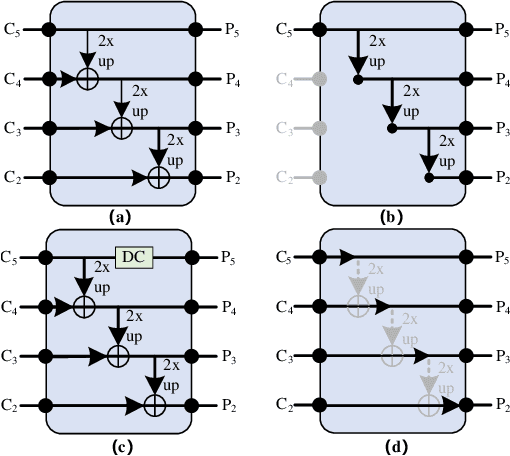
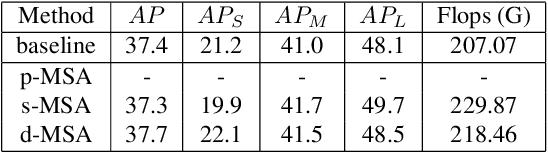
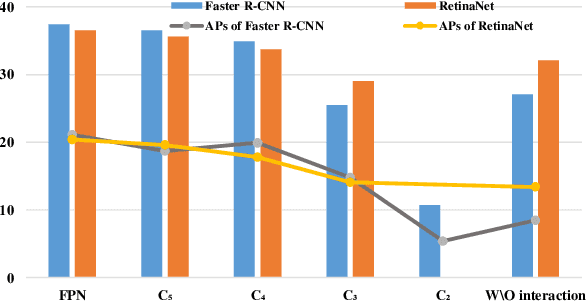
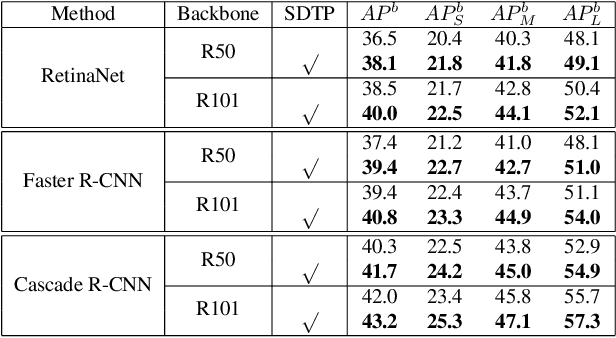
Although transformer has achieved great progress on computer vision tasks, the scale variation in dense image prediction is still the key challenge. Few effective multi-scale techniques are applied in transformer and there are two main limitations in the current methods. On one hand, self-attention module in vanilla transformer fails to sufficiently exploit the diversity of semantic information because of its rigid mechanism. On the other hand, it is hard to build attention and interaction among different levels due to the heavy computational burden. To alleviate this problem, we first revisit multi-scale problem in dense prediction, verifying the significance of diverse semantic representation and multi-scale interaction, and exploring the adaptation of transformer to pyramidal structure. Inspired by these findings, we propose a novel Semantic-aware Decoupled Transformer Pyramid (SDTP) for dense image prediction, consisting of Intra-level Semantic Promotion (ISP), Cross-level Decoupled Interaction (CDI) and Attention Refinement Function (ARF). ISP explores the semantic diversity in different receptive space. CDI builds the global attention and interaction among different levels in decoupled space which also solves the problem of heavy computation. Besides, ARF is further added to refine the attention in transformer. Experimental results demonstrate the validity and generality of the proposed method, which outperforms the state-of-the-art by a significant margin in dense image prediction tasks. Furthermore, the proposed components are all plug-and-play, which can be embedded in other methods.
Wood-leaf classification of tree point cloud based on intensity and geometrical information
Aug 02, 2021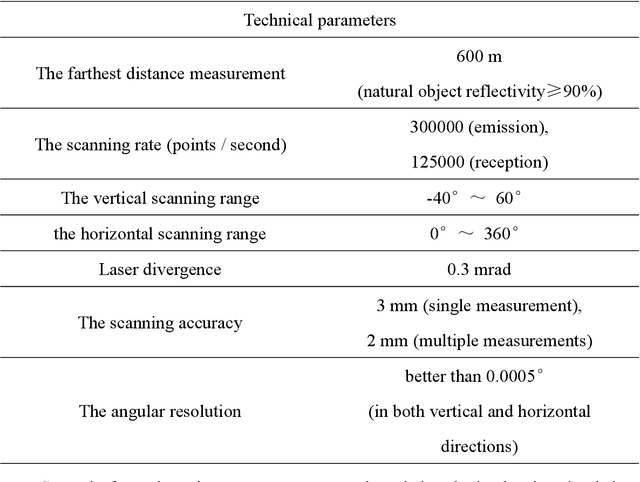

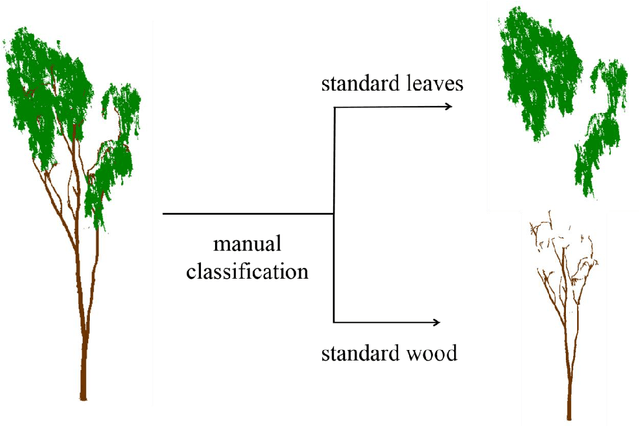
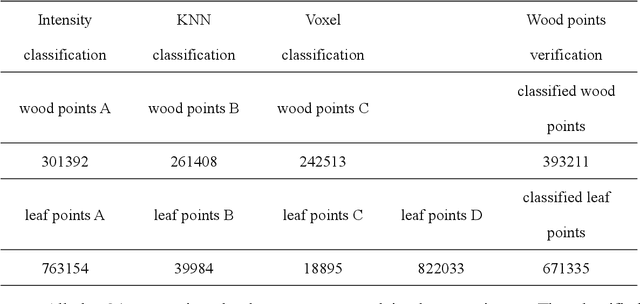
Terrestrial laser scanning (TLS) can obtain tree point cloud with high precision and high density. Efficient classification of wood points and leaf points is essential to study tree structural parameters and ecological characteristics. By using both the intensity and spatial information, a three-step classification and verification method was proposed to achieve automated wood-leaf classification. Tree point cloud was classified into wood points and leaf points by using intensity threshold, neighborhood density and voxelization successively. Experiment was carried in Haidian Park, Beijing, and 24 trees were scanned by using the RIEGL VZ-400 scanner. The tree point clouds were processed by using the proposed method, whose classification results were compared with the manual classification results which were used as standard results. To evaluate the classification accuracy, three indicators were used in the experiment, which are Overall Accuracy (OA), Kappa coefficient (Kappa) and Matthews correlation coefficient (MCC). The ranges of OA, Kappa and MCC of the proposed method are from 0.9167 to 0.9872, from 0.7276 to 0.9191, and from 0.7544 to 0.9211 respectively. The average values of OA, Kappa and MCC are 0.9550, 0.8547 and 0.8627 respectively. Time cost of wood-leaf classification was also recorded to evaluate the algorithm efficiency. The average processing time are 1.4 seconds per million points. The results showed that the proposed method performed well automatically and quickly on wood-leaf classification based on the experimental dataset.
IMAGINE: Image Synthesis by Image-Guided Model Inversion
Apr 13, 2021
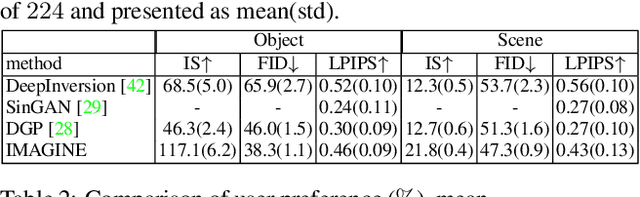

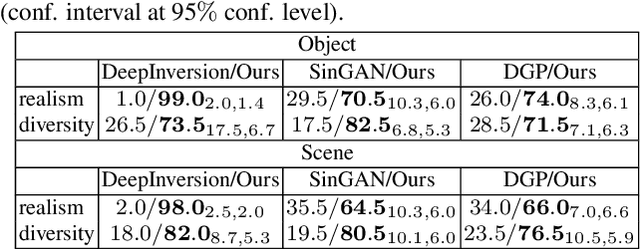
We introduce an inversion based method, denoted as IMAge-Guided model INvErsion (IMAGINE), to generate high-quality and diverse images from only a single training sample. We leverage the knowledge of image semantics from a pre-trained classifier to achieve plausible generations via matching multi-level feature representations in the classifier, associated with adversarial training with an external discriminator. IMAGINE enables the synthesis procedure to simultaneously 1) enforce semantic specificity constraints during the synthesis, 2) produce realistic images without generator training, and 3) give users intuitive control over the generation process. With extensive experimental results, we demonstrate qualitatively and quantitatively that IMAGINE performs favorably against state-of-the-art GAN-based and inversion-based methods, across three different image domains (i.e., objects, scenes, and textures).
Rethinking and Improving the Robustness of Image Style Transfer
Apr 08, 2021


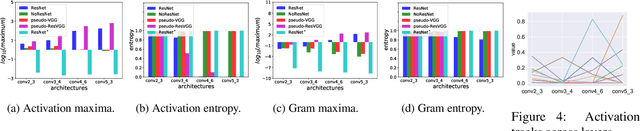
Extensive research in neural style transfer methods has shown that the correlation between features extracted by a pre-trained VGG network has a remarkable ability to capture the visual style of an image. Surprisingly, however, this stylization quality is not robust and often degrades significantly when applied to features from more advanced and lightweight networks, such as those in the ResNet family. By performing extensive experiments with different network architectures, we find that residual connections, which represent the main architectural difference between VGG and ResNet, produce feature maps of small entropy, which are not suitable for style transfer. To improve the robustness of the ResNet architecture, we then propose a simple yet effective solution based on a softmax transformation of the feature activations that enhances their entropy. Experimental results demonstrate that this small magic can greatly improve the quality of stylization results, even for networks with random weights. This suggests that the architecture used for feature extraction is more important than the use of learned weights for the task of style transfer.
Dynamic Transfer for Multi-Source Domain Adaptation
Mar 19, 2021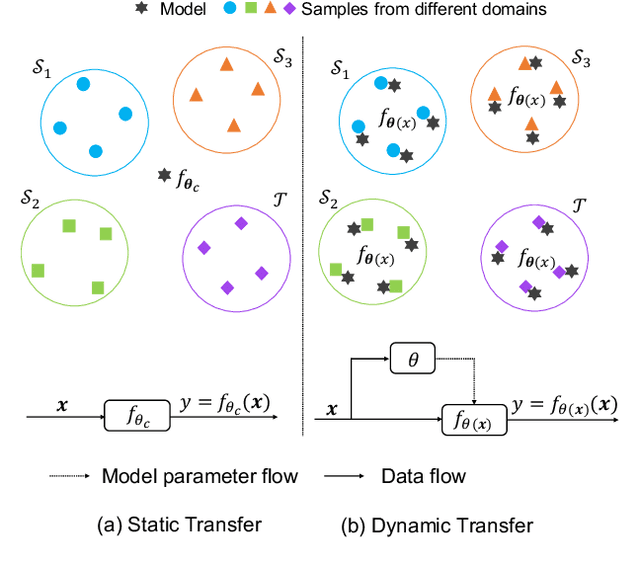

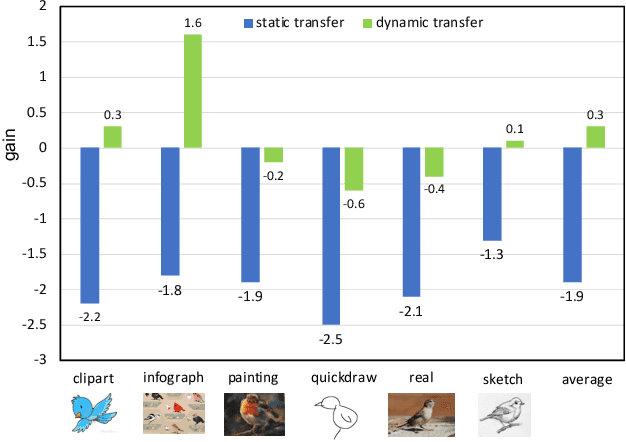
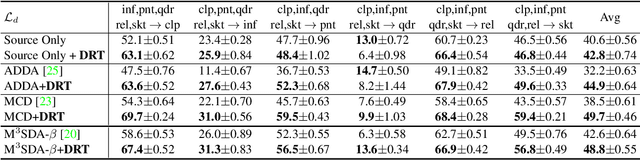
Recent works of multi-source domain adaptation focus on learning a domain-agnostic model, of which the parameters are static. However, such a static model is difficult to handle conflicts across multiple domains, and suffers from a performance degradation in both source domains and target domain. In this paper, we present dynamic transfer to address domain conflicts, where the model parameters are adapted to samples. The key insight is that adapting model across domains is achieved via adapting model across samples. Thus, it breaks down source domain barriers and turns multi-source domains into a single-source domain. This also simplifies the alignment between source and target domains, as it only requires the target domain to be aligned with any part of the union of source domains. Furthermore, we find dynamic transfer can be simply modeled by aggregating residual matrices and a static convolution matrix. Experimental results show that, without using domain labels, our dynamic transfer outperforms the state-of-the-art method by more than 3% on the large multi-source domain adaptation datasets -- DomainNet. Source code is at https://github.com/liyunsheng13/DRT.
Efficient Discretizations of Optimal Transport
Feb 16, 2021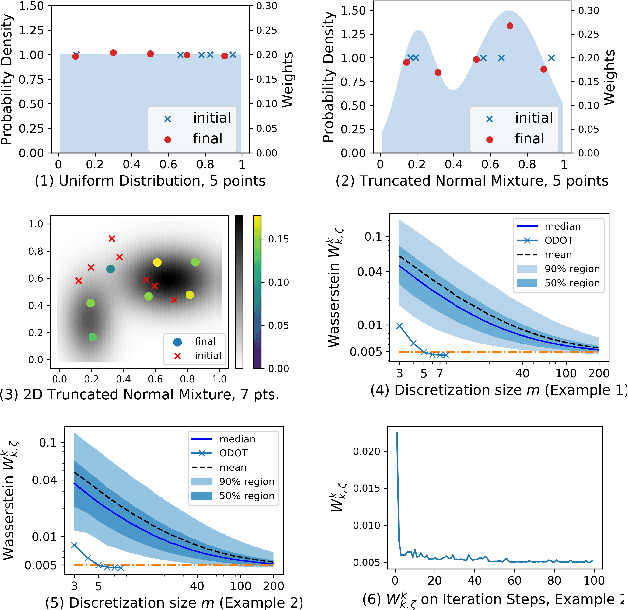

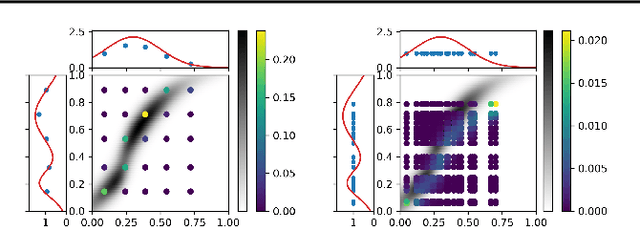
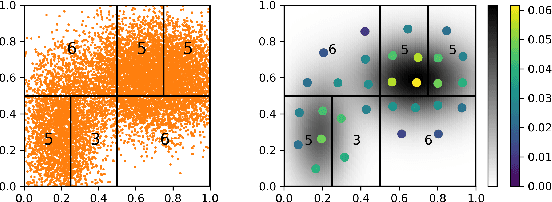
Obtaining solutions to Optimal Transportation (OT) problems is typically intractable when the marginal spaces are continuous. Recent research has focused on approximating continuous solutions with discretization methods based on i.i.d. sampling, and has proven convergence as the sample size increases. However, obtaining OT solutions with large sample sizes requires intensive computation effort, that can be prohibitive in practice. In this paper, we propose an algorithm for calculating discretizations with a given number of points for marginal distributions, by minimizing the (entropy-regularized) Wasserstein distance, and result in plans that are comparable to those obtained with much larger numbers of i.i.d. samples. Moreover, a local version of such discretizations which is parallelizable for large scale applications is proposed. We prove bounds for our approximation and demonstrate performance on a wide range of problems.
Distributionally-Constrained Policy Optimization via Unbalanced Optimal Transport
Feb 15, 2021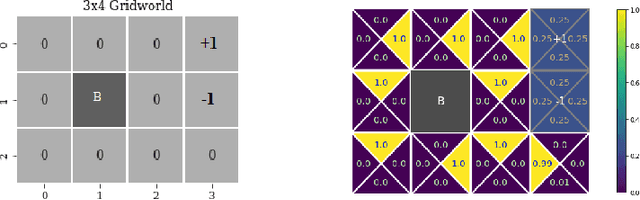
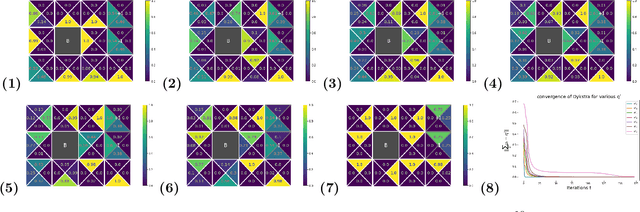

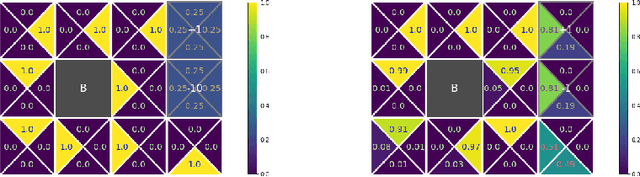
We consider constrained policy optimization in Reinforcement Learning, where the constraints are in form of marginals on state visitations and global action executions. Given these distributions, we formulate policy optimization as unbalanced optimal transport over the space of occupancy measures. We propose a general purpose RL objective based on Bregman divergence and optimize it using Dykstra's algorithm. The approach admits an actor-critic algorithm for when the state or action space is large, and only samples from the marginals are available. We discuss applications of our approach and provide demonstrations to show the effectiveness of our algorithm.
A Metamodel and Framework for Artificial General Intelligence From Theory to Practice
Feb 11, 2021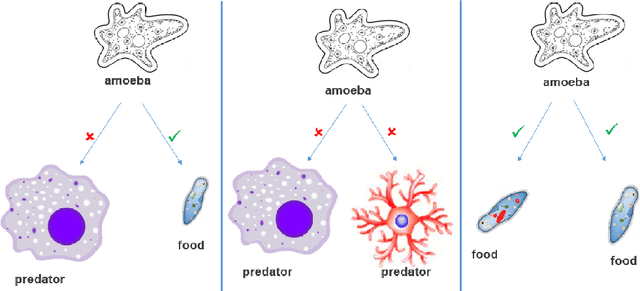
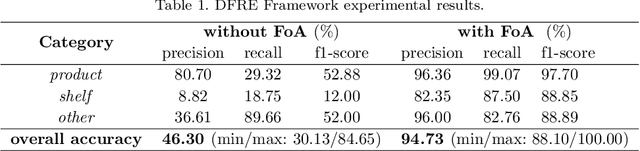
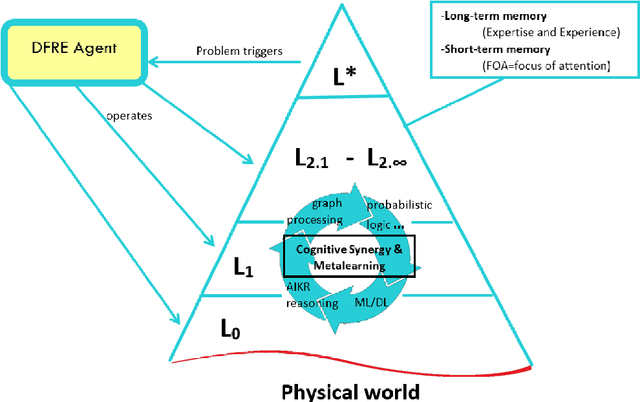
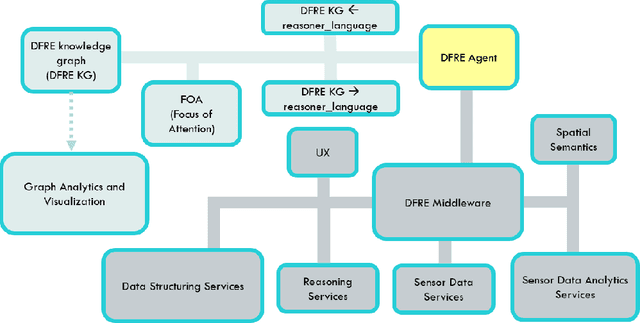
This paper introduces a new metamodel-based knowledge representation that significantly improves autonomous learning and adaptation. While interest in hybrid machine learning / symbolic AI systems leveraging, for example, reasoning and knowledge graphs, is gaining popularity, we find there remains a need for both a clear definition of knowledge and a metamodel to guide the creation and manipulation of knowledge. Some of the benefits of the metamodel we introduce in this paper include a solution to the symbol grounding problem, cumulative learning, and federated learning. We have applied the metamodel to problems ranging from time series analysis, computer vision, and natural language understanding and have found that the metamodel enables a wide variety of learning mechanisms ranging from machine learning, to graph network analysis and learning by reasoning engines to interoperate in a highly synergistic way. Our metamodel-based projects have consistently exhibited unprecedented accuracy, performance, and ability to generalize. This paper is inspired by the state-of-the-art approaches to AGI, recent AGI-aspiring work, the granular computing community, as well as Alfred Korzybski's general semantics. One surprising consequence of the metamodel is that it not only enables a new level of autonomous learning and optimal functioning for machine intelligences, but may also shed light on a path to better understanding how to improve human cognition.
Non-uniform Motion Deblurring with Blurry Component Divided Guidance
Jan 15, 2021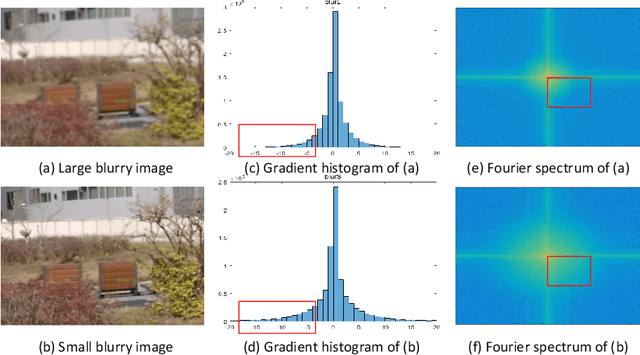
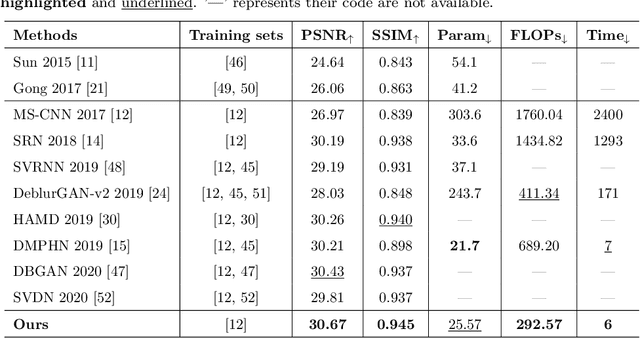


Blind image deblurring is a fundamental and challenging computer vision problem, which aims to recover both the blur kernel and the latent sharp image from only a blurry observation. Despite the superiority of deep learning methods in image deblurring have displayed, there still exists major challenge with various non-uniform motion blur. Previous methods simply take all the image features as the input to the decoder, which handles different degrees (e.g. large blur, small blur) simultaneously, leading to challenges for sharp image generation. To tackle the above problems, we present a deep two-branch network to deal with blurry images via a component divided module, which divides an image into two components based on the representation of blurry degree. Specifically, two component attentive blocks are employed to learn attention maps to exploit useful deblurring feature representations on both large and small blurry regions. Then, the blur-aware features are fed into two-branch reconstruction decoders respectively. In addition, a new feature fusion mechanism, orientation-based feature fusion, is proposed to merge sharp features of the two branches. Both qualitative and quantitative experimental results show that our method performs favorably against the state-of-the-art approaches.