 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pre-Computing Solution for Online Advertising Serving
Jul 04, 2022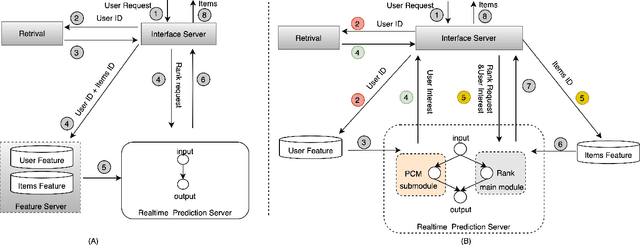

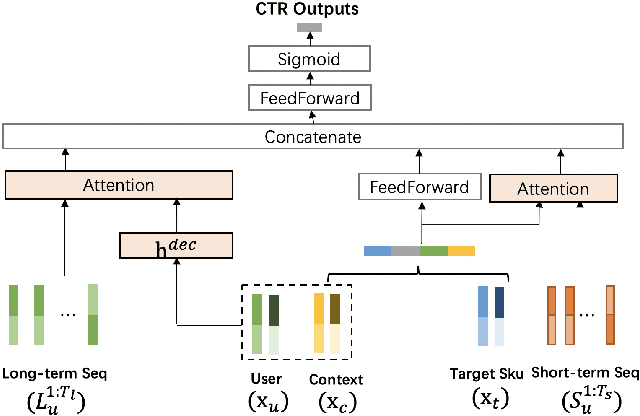
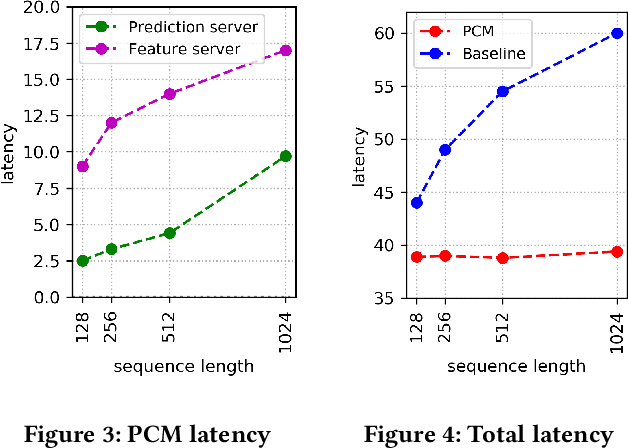
Click-Through Rate (CTR) prediction plays a key role in online advertising systems and online advertising. Constrained by strict requirements on online inference efficiency, it is often difficult to deploy useful but computationally intensive modules such as long-term behaviors modeling. Most recent works attempt to mitigate the online calculation issue of long historical behaviors by adopting two-stage methods to balance online efficiency and effectiveness. However, the information gaps caused by two-stage modeling may result in a diminished performance gain. In this work, we propose a novel framework called PCM to address this challenge in the view of system deployment. By deploying a pre-computing sub-module parallel to the retrieval stage, our PCM effectively reduces overall inference time which enables complex modeling in the ranking stage. Comprehensive offline and online experiments are conducted on the long-term user behaviors module to validate the effectiveness of our solution for the complex models. Moreover, our framework has been deployed into a large-scale real-world E-commerce system serving the main interface of hundreds of millions of active users, by deploying long sequential user behavior model in PCM. We achieved a 3\% CTR gain, with almost no increase in the ranking latency, compared to the base framework demonstrated from the online A/B test. To our knowledge, we are the first to propose an end-to-end solution for online training and deployment on complex CTR models from the system framework side.
Evolution of beliefs in social networks
May 26, 2022
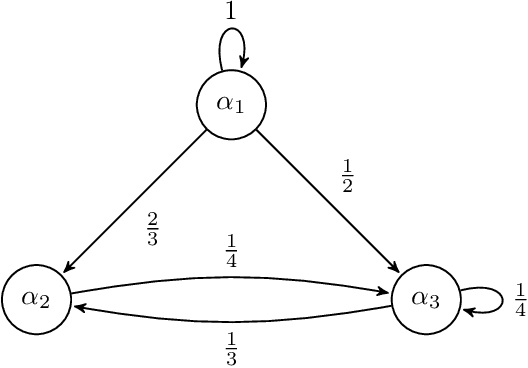
Evolution of beliefs of a society are a product of interactions between people (horizontal transmission) in the society over generations (vertical transmission). Researchers have studied both horizontal and vertical transmission separately. Extending prior work, we propose a new theoretical framework which allows application of tools from Markov chain theory to the analysis of belief evolution via horizontal and vertical transmission. We analyze three cases: static network, randomly changing network, and homophily-based dynamic network. Whereas the former two assume network structure is independent of beliefs, the latter assumes that people tend to communicate with those who have similar beliefs. We prove under general conditions that both static and randomly changing networks converge to a single set of beliefs among all individuals along with the rate of convergence. We prove that homophily-based network structures do not in general converge to a single set of beliefs shared by all and prove lower bounds on the number of different limiting beliefs as a function of initial beliefs. We conclude by discussing implications for prior theories and directions for future work.
IA-GCN: Interactive Graph Convolutional Network for Recommendation
Apr 08, 2022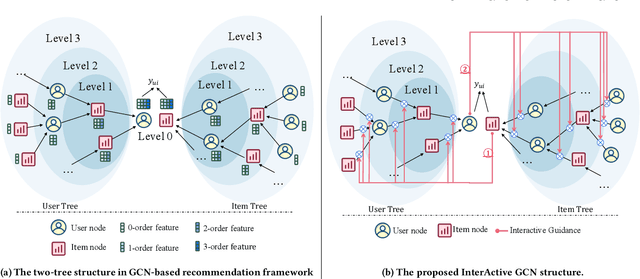

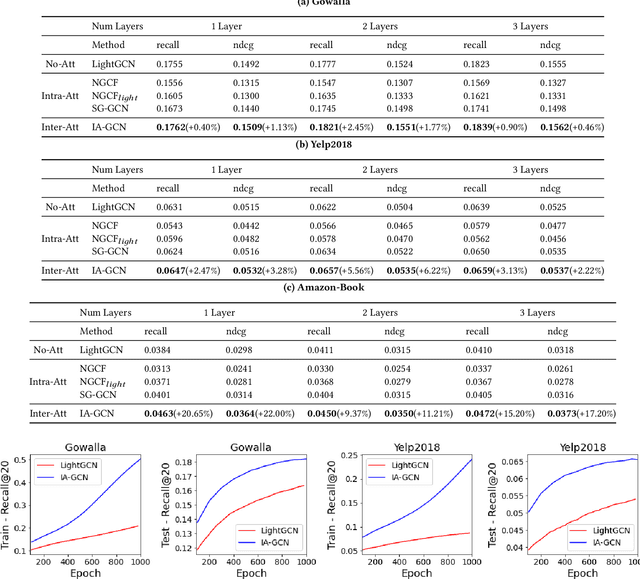
Recently, Graph Convolutional Network (GCN) has become a novel state-of-art for Collaborative Filtering (CF) based Recommender Systems (RS). It is a common practice to learn informative user and item representations by performing embedding propagation on a user-item bipartite graph, and then provide the users with personalized item suggestions based on the representations. Despite effectiveness, existing algorithms neglect precious interactive features between user-item pairs in the embedding process. When predicting a user's preference for different items, they still aggregate the user tree in the same way, without emphasizing target-related information in the user neighborhood. Such a uniform aggregation scheme easily leads to suboptimal user and item representations, limiting the model expressiveness to some extent. In this work, we address this problem by building bilateral interactive guidance between each user-item pair and proposing a new model named IA-GCN (short for InterActive GCN). Specifically, when learning the user representation from its neighborhood, we assign higher attention weights to those neighbors similar to the target item. Correspondingly, when learning the item representation, we pay more attention to those neighbors resembling the target user. This leads to interactive and interpretable features, effectively distilling target-specific information through each graph convolutional operation. Our model is built on top of LightGCN, a state-of-the-art GCN model for CF, and can be combined with various GCN-based CF architectures in an end-to-end fashion. Extensive experiments on three benchmark datasets demonstrate the effectiveness and robustness of IA-GCN.
Learning Distinctive Margin toward Active Domain Adaptation
Apr 03, 2022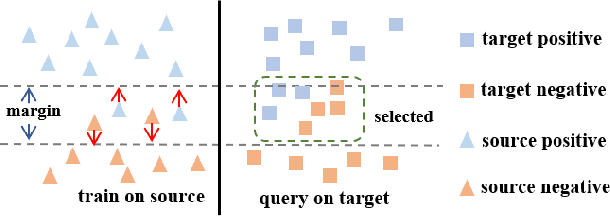
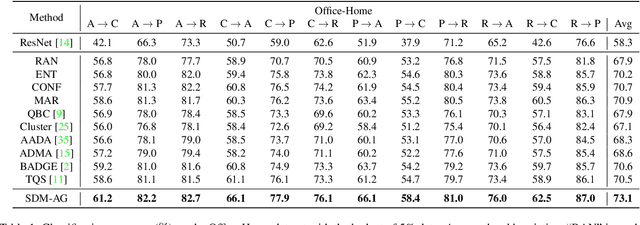
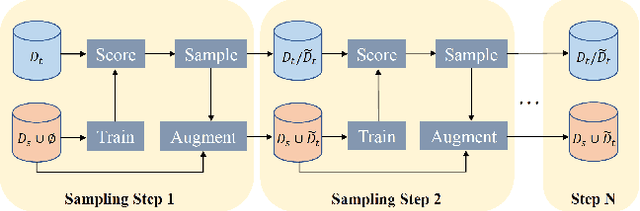
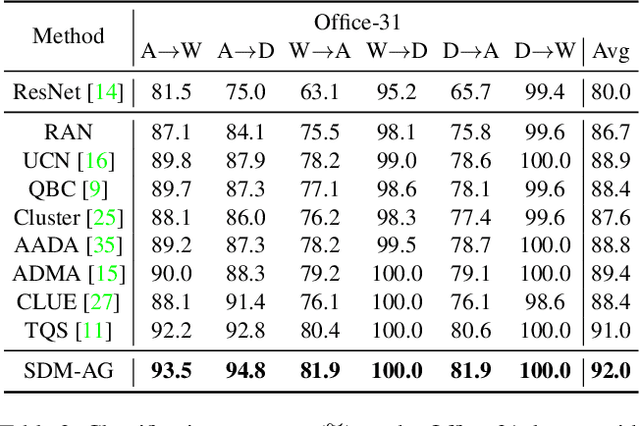
Despite plenty of efforts focusing on improving the domain adaptation ability (DA) under unsupervised or few-shot semi-supervised settings, recently the solution of active learning started to attract more attention due to its suitability in transferring model in a more practical way with limited annotation resource on target data. Nevertheless, most active learning methods are not inherently designed to handle domain gap between data distribution, on the other hand, some active domain adaptation methods (ADA) usually requires complicated query functions, which is vulnerable to overfitting. In this work, we propose a concise but effective ADA method called Select-by-Distinctive-Margin (SDM), which consists of a maximum margin loss and a margin sampling algorithm for data selection. We provide theoretical analysis to show that SDM works like a Support Vector Machine, storing hard examples around decision boundaries and exploiting them to find informative and transferable data. In addition, we propose two variants of our method, one is designed to adaptively adjust the gradient from margin loss, the other boosts the selectivity of margin sampling by taking the gradient direction into account. We benchmark SDM with standard active learning setting, demonstrating our algorithm achieves competitive results with good data scalability. Code is available at https://github.com/TencentYoutuResearch/ActiveLearning-SDM
Omni-DETR: Omni-Supervised Object Detection with Transformers
Mar 30, 2022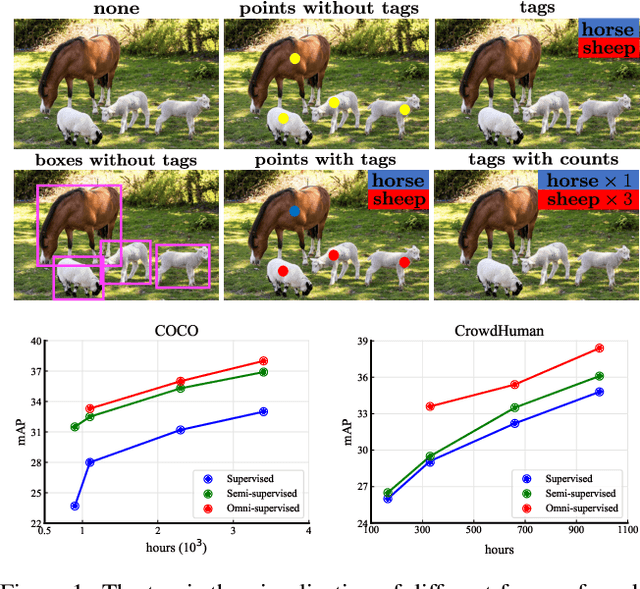


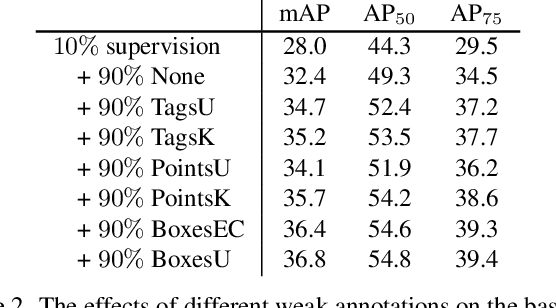
We consider the problem of omni-supervised object detection, which can use unlabeled, fully labeled and weakly labeled annotations, such as image tags, counts, points, etc., for object detection. This is enabled by a unified architecture, Omni-DETR, based on the recent progress on student-teacher framework and end-to-end transformer based object detection. Under this unified architecture, different types of weak labels can be leveraged to generate accurate pseudo labels, by a bipartite matching based filtering mechanism, for the model to learn. In the experiments, Omni-DETR has achieved state-of-the-art results on multiple datasets and settings. And we have found that weak annotations can help to improve detection performance and a mixture of them can achieve a better trade-off between annotation cost and accuracy than the standard complete annotation. These findings could encourage larger object detection datasets with mixture annotations. The code is available at https://github.com/amazon-research/omni-detr.
Neurosymbolic hybrid approach to driver collision warning
Mar 28, 2022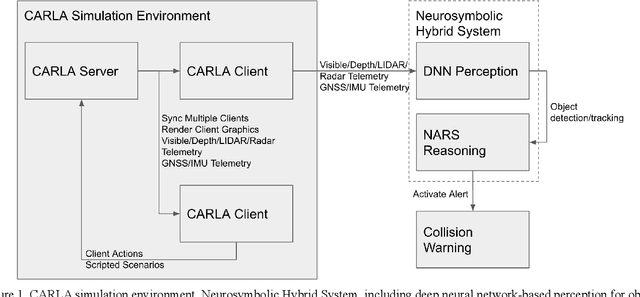

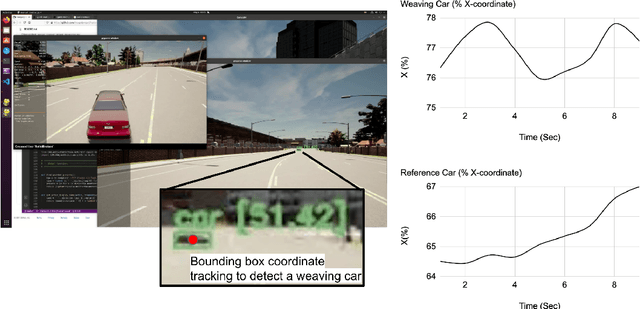

There are two main algorithmic approaches to autonomous driving systems: (1) An end-to-end system in which a single deep neural network learns to map sensory input directly into appropriate warning and driving responses. (2) A mediated hybrid recognition system in which a system is created by combining independent modules that detect each semantic feature. While some researchers believe that deep learning can solve any problem, others believe that a more engineered and symbolic approach is needed to cope with complex environments with less data. Deep learning alone has achieved state-of-the-art results in many areas, from complex gameplay to predicting protein structures. In particular, in image classification and recognition, deep learning models have achieved accuracies as high as humans. But sometimes it can be very difficult to debug if the deep learning model doesn't work. Deep learning models can be vulnerable and are very sensitive to changes in data distribution. Generalization can be problematic. It's usually hard to prove why it works or doesn't. Deep learning models can also be vulnerable to adversarial attacks. Here, we combine deep learning-based object recognition and tracking with an adaptive neurosymbolic network agent, called the Non-Axiomatic Reasoning System (NARS), that can adapt to its environment by building concepts based on perceptual sequences. We achieved an improved intersection-over-union (IOU) object recognition performance of 0.65 in the adaptive retraining model compared to IOU 0.31 in the COCO data pre-trained model. We improved the object detection limits using RADAR sensors in a simulated environment, and demonstrated the weaving car detection capability by combining deep learning-based object detection and tracking with a neurosymbolic model.
Probabilistic Inverse Optimal Transport
Dec 17, 2021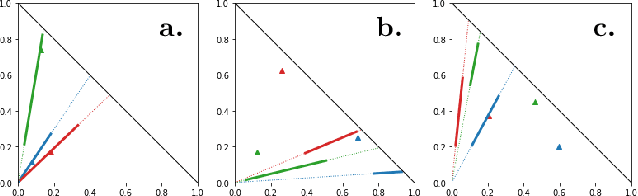
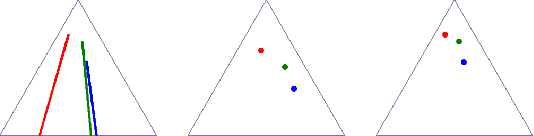
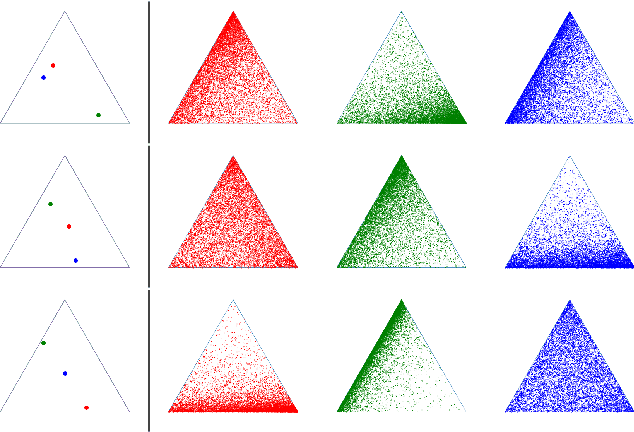
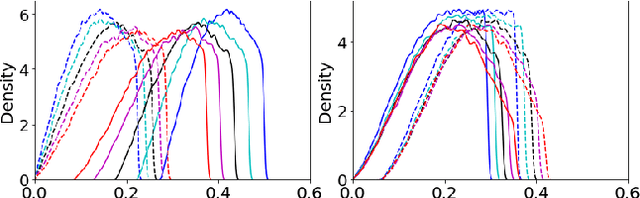
Optimal transport (OT) formalizes the problem of finding an optimal coupling between probability measures given a cost matrix. The inverse problem of inferring the cost given a coupling is Inverse Optimal Transport (IOT). IOT is less well understood than OT. We formalize and systematically analyze the properties of IOT using tools from the study of entropy-regularized OT. Theoretical contributions include characterization of the manifold of cross-ratio equivalent costs, the implications of model priors, and derivation of an MCMC sampler. Empirical contributions include visualizations of cross-ratio equivalent effect on basic examples and simulations validating theoretical results.
Neurosymbolic Systems of Perception & Cognition: The Role of Attention
Dec 02, 2021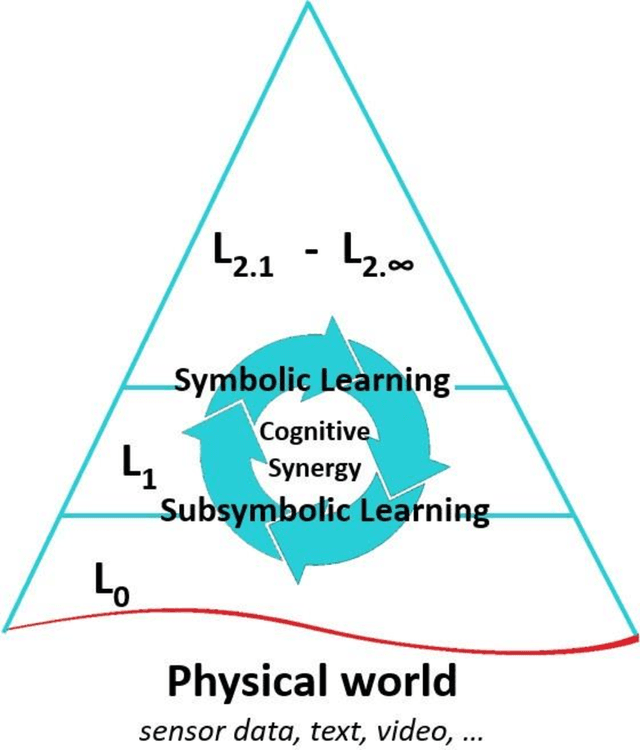

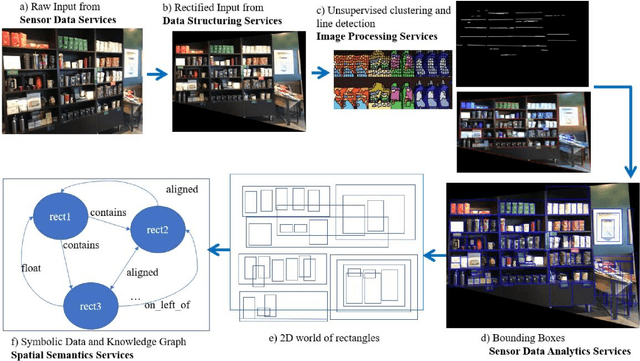
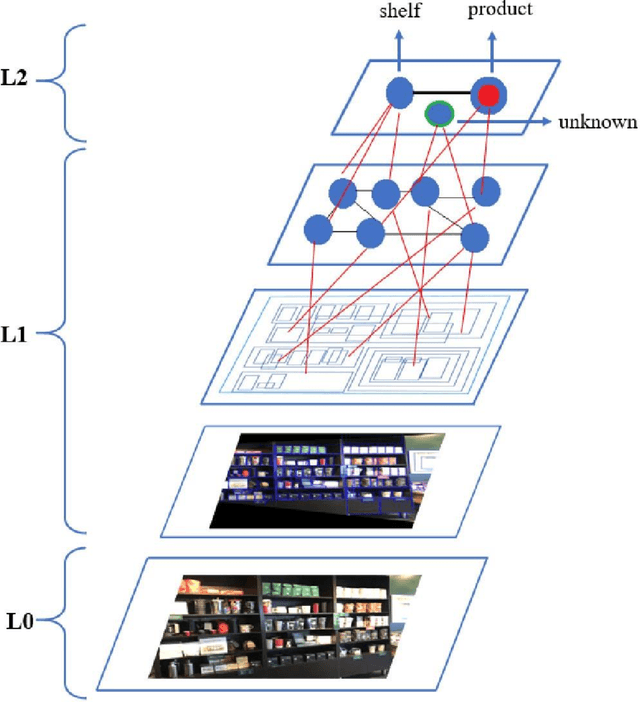
A cognitive architecture aimed at cumulative learning must provide the necessary information and control structures to allow agents to learn incrementally and autonomously from their experience. This involves managing an agent's goals as well as continuously relating sensory information to these in its perception-cognition information stack. The more varied the environment of a learning agent is, the more general and flexible must be these mechanisms to handle a wider variety of relevant patterns, tasks, and goal structures. While many researchers agree that information at different levels of abstraction likely differs in its makeup and structure and processing mechanisms, agreement on the particulars of such differences is not generally shared in the research community. A binary processing architecture (often referred to as System-1 and System-2) has been proposed as a model of cognitive processing for low- and high-level information, respectively. We posit that cognition is not binary in this way and that knowledge at any level of abstraction involves what we refer to as neurosymbolic information, meaning that data at both high and low levels must contain both symbolic and subsymbolic information. Further, we argue that the main differentiating factor between the processing of high and low levels of data abstraction can be largely attributed to the nature of the involved attention mechanisms. We describe the key arguments behind this view and review relevant evidence from the literature.
Dynamic Parameterized Network for CTR Prediction
Nov 09, 2021
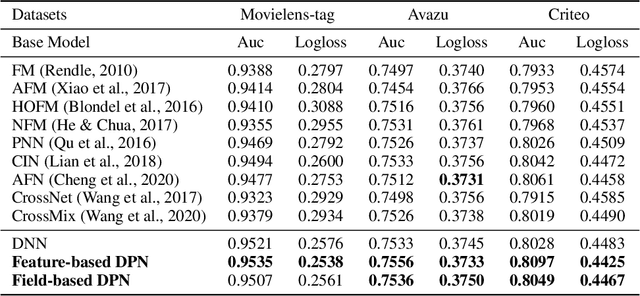
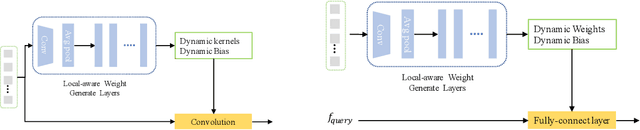
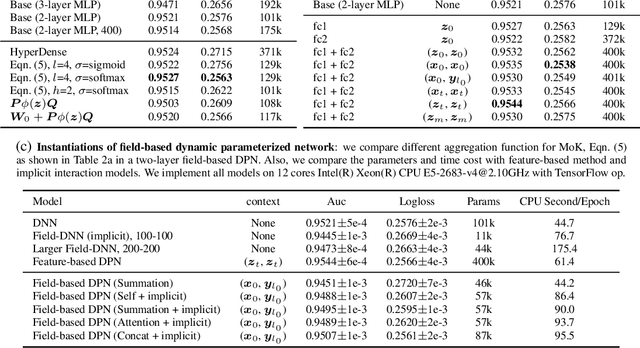
Learning to capture feature relations effectively and efficiently is essential in click-through rate (CTR) prediction of modern recommendation systems. Most existing CTR prediction methods model such relations either through tedious manually-designed low-order interactions or through inflexible and inefficient high-order interactions, which both require extra DNN modules for implicit interaction modeling. In this paper, we proposed a novel plug-in operation, Dynamic Parameterized Operation (DPO), to learn both explicit and implicit interaction instance-wisely. We showed that the introduction of DPO into DNN modules and Attention modules can respectively benefit two main tasks in CTR prediction, enhancing the adaptiveness of feature-based modeling and improving user behavior modeling with the instance-wise locality. Our Dynamic Parameterized Networks significantly outperforms state-of-the-art methods in the offline experiments on the public dataset and real-world production dataset, together with an online A/B test. Furthermore, the proposed Dynamic Parameterized Networks has been deployed in the ranking system of one of the world's largest e-commerce companies, serving the main traffic of hundreds of millions of active users.
DeepAg: Deep Learning Approach for Measuring the Effects of Outlier Events on Agricultural Production and Policy
Nov 06, 2021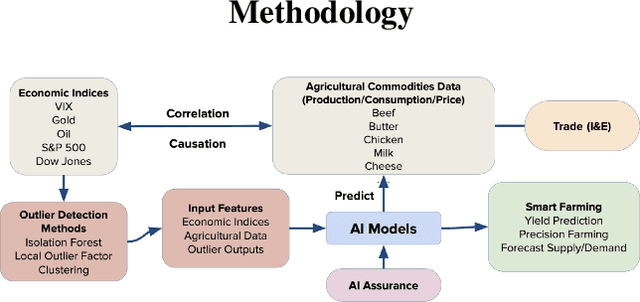
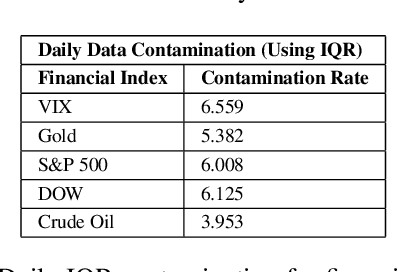
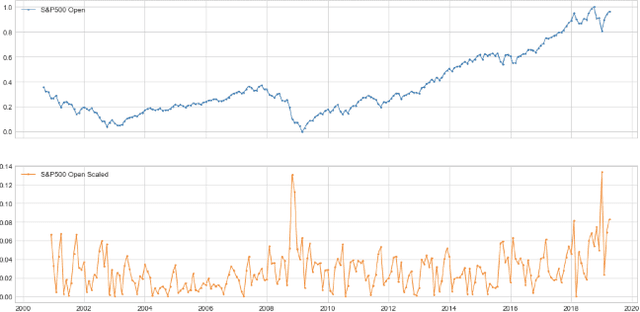
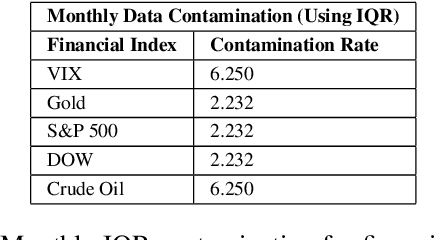
Quantitative metrics that measure the global economy's equilibrium have strong and interdependent relationships with the agricultural supply chain and international trade flows. Sudden shocks in these processes caused by outlier events such as trade wars, pandemics, or weather can have complex effects on the global economy. In this paper, we propose a novel framework, namely: DeepAg, that employs econometrics and measures the effects of outlier events detection using Deep Learning (DL) to determine relationships between commonplace financial indices (such as the DowJones), and the production values of agricultural commodities (such as Cheese and Milk). We employed a DL technique called Long Short-Term Memory (LSTM) networks successfully to predict commodity production with high accuracy and also present five popular models (regression and boosting) as baselines to measure the effects of outlier events. The results indicate that DeepAg with outliers' considerations (using Isolation Forests) outperforms baseline models, as well as the same model without outliers detection. Outlier events make a considerable impact when predicting commodity production with respect to financial indices. Moreover, we present the implications of DeepAg on public policy, provide insights for policymakers and farmers, and for operational decisions in the agricultural ecosystem. Data are collected, models developed, and the results are recorded and presented.