 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Instruction-Following Through Minimum Bayes Risk
Oct 07, 2024General-purpose LLM judges capable of human-level evaluation provide not only a scalable and accurate way of evaluating instruction-following LLMs but also new avenues for supervising and improving their performance. One promising way of leveraging LLM judges for supervision is through Minimum Bayes Risk (MBR) decoding, which uses a reference-based evaluator to select a high-quality output from amongst a set of candidate outputs. In the first part of this work, we explore using MBR decoding as a method for improving the test-time performance of instruction-following LLMs. We find that MBR decoding with reference-based LLM judges substantially improves over greedy decoding, best-of-N decoding with reference-free judges and MBR decoding with lexical and embedding-based metrics on AlpacaEval and MT-Bench. These gains are consistent across LLMs with up to 70B parameters, demonstrating that smaller LLM judges can be used to supervise much larger LLMs. Then, seeking to retain the improvements from MBR decoding while mitigating additional test-time costs, we explore iterative self-training on MBR-decoded outputs. We find that self-training using Direct Preference Optimisation leads to significant performance gains, such that the self-trained models with greedy decoding generally match and sometimes exceed the performance of their base models with MBR decoding.
EuroLLM: Multilingual Language Models for Europe
Sep 24, 2024The quality of open-weight LLMs has seen significant improvement, yet they remain predominantly focused on English. In this paper, we introduce the EuroLLM project, aimed at developing a suite of open-weight multilingual LLMs capable of understanding and generating text in all official European Union languages, as well as several additional relevant languages. We outline the progress made to date, detailing our data collection and filtering process, the development of scaling laws, the creation of our multilingual tokenizer, and the data mix and modeling configurations. Additionally, we release our initial models: EuroLLM-1.7B and EuroLLM-1.7B-Instruct and report their performance on multilingual general benchmarks and machine translation.
DOCE: Finding the Sweet Spot for Execution-Based Code Generation
Aug 25, 2024



Recently, a diverse set of decoding and reranking procedures have been shown effective for LLM-based code generation. However, a comprehensive framework that links and experimentally compares these methods is missing. We address this by proposing Decoding Objectives for Code Execution, a comprehensive framework that includes candidate generation, $n$-best reranking, minimum Bayes risk (MBR) decoding, and self-debugging as the core components. We then study the contributions of these components through execution-based evaluation metrics. Our findings highlight the importance of execution-based methods and the difference gap between execution-based and execution-free methods. Furthermore, we assess the impact of filtering based on trial unit tests, a simple and effective strategy that has been often overlooked in prior works. We also propose self-debugging on multiple candidates, obtaining state-of-the-art performance on reranking for code generation. We expect our framework to provide a solid guideline for future research on code generation.
CMU's IWSLT 2024 Simultaneous Speech Translation System
Aug 14, 2024This paper describes CMU's submission to the IWSLT 2024 Simultaneous Speech Translation (SST) task for translating English speech to German text in a streaming manner. Our end-to-end speech-to-text (ST) system integrates the WavLM speech encoder, a modality adapter, and the Llama2-7B-Base model as the decoder. We employ a two-stage training approach: initially, we align the representations of speech and text, followed by full fine-tuning. Both stages are trained on MuST-c v2 data with cross-entropy loss. We adapt our offline ST model for SST using a simple fixed hold-n policy. Experiments show that our model obtains an offline BLEU score of 31.1 and a BLEU score of 29.5 under 2 seconds latency on the MuST-C-v2 tst-COMMON.
Is Context Helpful for Chat Translation Evaluation?
Mar 13, 2024



Despite the recent success of automatic metrics for assessing translation quality, their application in evaluating the quality of machine-translated chats has been limited. Unlike more structured texts like news, chat conversations are often unstructured, short, and heavily reliant on contextual information. This poses questions about the reliability of existing sentence-level metrics in this domain as well as the role of context in assessing the translation quality. Motivated by this, we conduct a meta-evaluation of existing sentence-level automatic metrics, primarily designed for structured domains such as news, to assess the quality of machine-translated chats. We find that reference-free metrics lag behind reference-based ones, especially when evaluating translation quality in out-of-English settings. We then investigate how incorporating conversational contextual information in these metrics affects their performance. Our findings show that augmenting neural learned metrics with contextual information helps improve correlation with human judgments in the reference-free scenario and when evaluating translations in out-of-English settings. Finally, we propose a new evaluation metric, Context-MQM, that utilizes bilingual context with a large language model (LLM) and further validate that adding context helps even for LLM-based evaluation metrics.
Tower: An Open Multilingual Large Language Model for Translation-Related Tasks
Feb 27, 2024



While general-purpose large language models (LLMs) demonstrate proficiency on multiple tasks within the domain of translation, approaches based on open LLMs are competitive only when specializing on a single task. In this paper, we propose a recipe for tailoring LLMs to multiple tasks present in translation workflows. We perform continued pretraining on a multilingual mixture of monolingual and parallel data, creating TowerBase, followed by finetuning on instructions relevant for translation processes, creating TowerInstruct. Our final model surpasses open alternatives on several tasks relevant to translation workflows and is competitive with general-purpose closed LLMs. To facilitate future research, we release the Tower models, our specialization dataset, an evaluation framework for LLMs focusing on the translation ecosystem, and a collection of model generations, including ours, on our benchmark.
CroissantLLM: A Truly Bilingual French-English Language Model
Feb 02, 2024



We introduce CroissantLLM, a 1.3B language model pretrained on a set of 3T English and French tokens, to bring to the research and industrial community a high-performance, fully open-sourced bilingual model that runs swiftly on consumer-grade local hardware. To that end, we pioneer the approach of training an intrinsically bilingual model with a 1:1 English-to-French pretraining data ratio, a custom tokenizer, and bilingual finetuning datasets. We release the training dataset, notably containing a French split with manually curated, high-quality, and varied data sources. To assess performance outside of English, we craft a novel benchmark, FrenchBench, consisting of an array of classification and generation tasks, covering various orthogonal aspects of model performance in the French Language. Additionally, rooted in transparency and to foster further Large Language Model research, we release codebases, and dozens of checkpoints across various model sizes, training data distributions, and training steps, as well as fine-tuned Chat models, and strong translation models. We evaluate our model through the FMTI framework, and validate 81 % of the transparency criteria, far beyond the scores of even most open initiatives. This work enriches the NLP landscape, breaking away from previous English-centric work in order to strengthen our understanding of multilinguality in language models.
Context-aware Neural Machine Translation for English-Japanese Business Scene Dialogues
Nov 20, 2023Despite the remarkable advancements in machine translation, the current sentence-level paradigm faces challenges when dealing with highly-contextual languages like Japanese. In this paper, we explore how context-awareness can improve the performance of the current Neural Machine Translation (NMT) models for English-Japanese business dialogues translation, and what kind of context provides meaningful information to improve translation. As business dialogue involves complex discourse phenomena but offers scarce training resources, we adapted a pretrained mBART model, finetuning on multi-sentence dialogue data, which allows us to experiment with different contexts. We investigate the impact of larger context sizes and propose novel context tokens encoding extra-sentential information, such as speaker turn and scene type. We make use of Conditional Cross-Mutual Information (CXMI) to explore how much of the context the model uses and generalise CXMI to study the impact of the extra-sentential context. Overall, we find that models leverage both preceding sentences and extra-sentential context (with CXMI increasing with context size) and we provide a more focused analysis on honorifics translation. Regarding translation quality, increased source-side context paired with scene and speaker information improves the model performance compared to previous work and our context-agnostic baselines, measured in BLEU and COMET metrics.
* MT Summit 2023, research track, link to paper in proceedings: https://aclanthology.org/2023.mtsummit-research.23/
Aligning Neural Machine Translation Models: Human Feedback in Training and Inference
Nov 15, 2023



Reinforcement learning from human feedback (RLHF) is a recent technique to improve the quality of the text generated by a language model, making it closer to what humans would generate. A core ingredient in RLHF's success in aligning and improving large language models (LLMs) is its reward model, trained using human feedback on model outputs. In machine translation (MT), where metrics trained from human annotations can readily be used as reward models, recent methods using minimum Bayes risk decoding and reranking have succeeded in improving the final quality of translation. In this study, we comprehensively explore and compare techniques for integrating quality metrics as reward models into the MT pipeline. This includes using the reward model for data filtering, during the training phase through RL, and at inference time by employing reranking techniques, and we assess the effects of combining these in a unified approach. Our experimental results, conducted across multiple translation tasks, underscore the crucial role of effective data filtering, based on estimated quality, in harnessing the full potential of RL in enhancing MT quality. Furthermore, our findings demonstrate the effectiveness of combining RL training with reranking techniques, showcasing substantial improvements in translation quality.
The Devil is in the Errors: Leveraging Large Language Models for Fine-grained Machine Translation Evaluation
Aug 14, 2023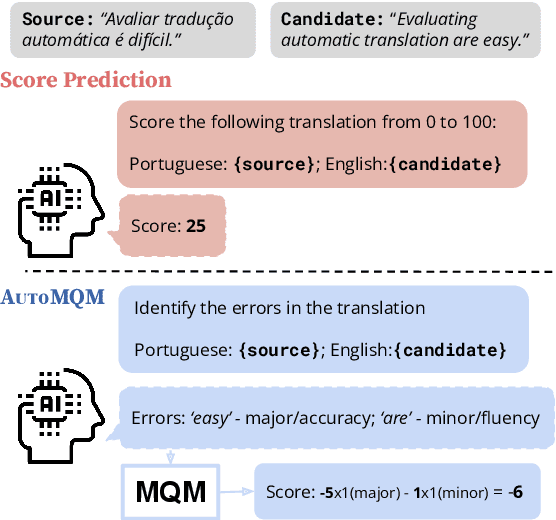

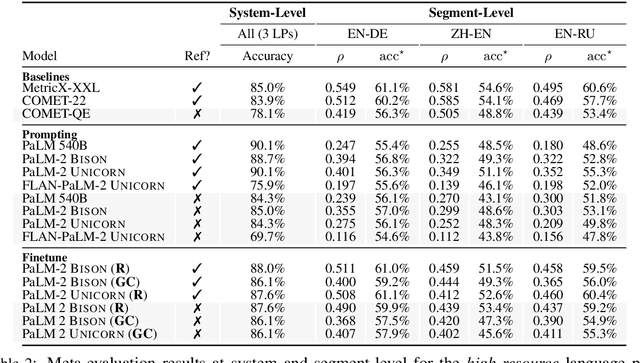
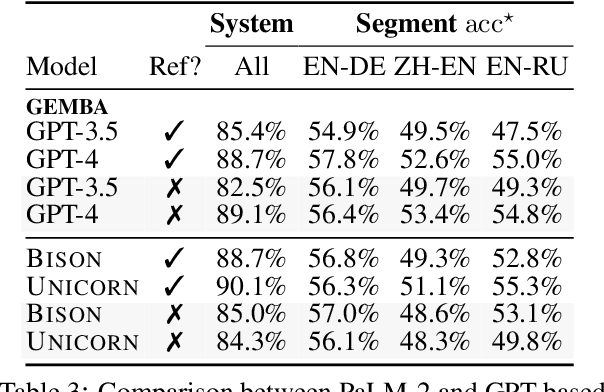
Automatic evaluation of machine translation (MT) is a critical tool driving the rapid iterative development of MT systems. While considerable progress has been made on estimating a single scalar quality score, current metrics lack the informativeness of more detailed schemes that annotate individual errors, such as Multidimensional Quality Metrics (MQM). In this paper, we help fill this gap by proposing AutoMQM, a prompting technique which leverages the reasoning and in-context learning capabilities of large language models (LLMs) and asks them to identify and categorize errors in translations. We start by evaluating recent LLMs, such as PaLM and PaLM-2, through simple score prediction prompting, and we study the impact of labeled data through in-context learning and finetuning. We then evaluate AutoMQM with PaLM-2 models, and we find that it improves performance compared to just prompting for scores (with particularly large gains for larger models) while providing interpretability through error spans that align with human annotations.