 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuroLLM-22B: Technical Report
Feb 05, 2026This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.
EuroLLM-9B: Technical Report
Jun 04, 2025



This report presents EuroLLM-9B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-9B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. We describe the pre-training data collection and filtering pipeline, including the creation of EuroFilter, an AI-based multilingual filter, as well as the design of EuroBlocks-Synthetic, a novel synthetic dataset for post-training that enhances language coverage for European languages. Evaluation results demonstrate EuroLLM-9B's competitive performance on multilingual benchmarks and machine translation tasks, establishing it as the leading open European-made LLM of its size. To support open research and adoption, we release all major components of this work, including the base and instruction-tuned models, the EuroFilter classifier, and the synthetic post-training dataset.
EuroGEST: Investigating gender stereotypes in multilingual language models
Jun 04, 2025Large language models increasingly support multiple languages, yet most benchmarks for gender bias remain English-centric. We introduce EuroGEST, a dataset designed to measure gender-stereotypical reasoning in LLMs across English and 29 European languages. EuroGEST builds on an existing expert-informed benchmark covering 16 gender stereotypes, expanded in this work using translation tools, quality estimation metrics, and morphological heuristics. Human evaluations confirm that our data generation method results in high accuracy of both translations and gender labels across languages. We use EuroGEST to evaluate 24 multilingual language models from six model families, demonstrating that the strongest stereotypes in all models across all languages are that women are 'beautiful', 'empathetic' and 'neat' and men are 'leaders', 'strong, tough' and 'professional'. We also show that larger models encode gendered stereotypes more strongly and that instruction finetuning does not consistently reduce gendered stereotypes. Our work highlights the need for more multilingual studies of fairness in LLMs and offers scalable methods and resources to audit gender bias across languages.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025



Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
EuroLLM: Multilingual Language Models for Europe
Sep 24, 2024The quality of open-weight LLMs has seen significant improvement, yet they remain predominantly focused on English. In this paper, we introduce the EuroLLM project, aimed at developing a suite of open-weight multilingual LLMs capable of understanding and generating text in all official European Union languages, as well as several additional relevant languages. We outline the progress made to date, detailing our data collection and filtering process, the development of scaling laws, the creation of our multilingual tokenizer, and the data mix and modeling configurations. Additionally, we release our initial models: EuroLLM-1.7B and EuroLLM-1.7B-Instruct and report their performance on multilingual general benchmarks and machine translation.
No Train but Gain: Language Arithmetic for training-free Language Adapters enhancement
Apr 24, 2024



Modular deep learning is the state-of-the-art solution for lifting the curse of multilinguality, preventing the impact of negative interference and enabling cross-lingual performance in Multilingual Pre-trained Language Models. However, a trade-off of this approach is the reduction in positive transfer learning from closely related languages. In response, we introduce a novel method called language arithmetic, which enables training-free post-processing to address this limitation. Inspired by the task arithmetic framework, we apply learning via addition to the language adapters, transitioning the framework from a multi-task to a multilingual setup. The effectiveness of the proposed solution is demonstrated on three downstream tasks in a MAD-X-based set of cross-lingual schemes, acting as a post-processing procedure. Language arithmetic consistently improves the baselines with significant gains in the most challenging cases of zero-shot and low-resource applications. Our code and models are available at https://github.com/mklimasz/language-arithmetic .
Is Modularity Transferable? A Case Study through the Lens of Knowledge Distillation
Mar 27, 2024The rise of Modular Deep Learning showcases its potential in various Natural Language Processing applications. Parameter-efficient fine-tuning (PEFT) modularity has been shown to work for various use cases, from domain adaptation to multilingual setups. However, all this work covers the case where the modular components are trained and deployed within one single Pre-trained Language Model (PLM). This model-specific setup is a substantial limitation on the very modularity that modular architectures are trying to achieve. We ask whether current modular approaches are transferable between models and whether we can transfer the modules from more robust and larger PLMs to smaller ones. In this work, we aim to fill this gap via a lens of Knowledge Distillation, commonly used for model compression, and present an extremely straightforward approach to transferring pre-trained, task-specific PEFT modules between same-family PLMs. Moreover, we propose a method that allows the transfer of modules between incompatible PLMs without any change in the inference complexity. The experiments on Named Entity Recognition, Natural Language Inference, and Paraphrase Identification tasks over multiple languages and PEFT methods showcase the initial potential of transferable modularity.
COMBO: State-of-the-Art Morphosyntactic Analysis
Sep 11, 2021
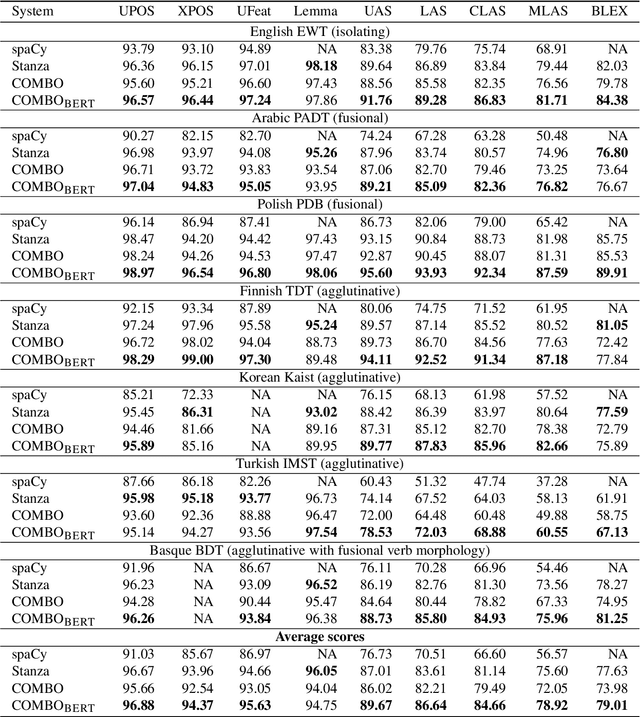
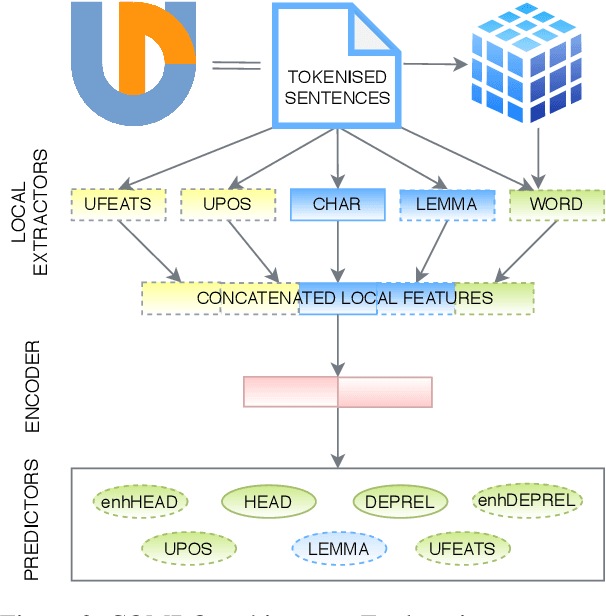

We introduce COMBO - a fully neural NLP system for accurate part-of-speech tagging, morphological analysis, lemmatisation, and (enhanced) dependency parsing. It predicts categorical morphosyntactic features whilst also exposes their vector representations, extracted from hidden layers. COMBO is an easy to install Python package with automatically downloadable pre-trained models for over 40 languages. It maintains a balance between efficiency and quality. As it is an end-to-end system and its modules are jointly trained, its training is competitively fast. As its models are optimised for accuracy, they achieve often better prediction quality than SOTA. The COMBO library is available at: https://gitlab.clarin-pl.eu/syntactic-tools/combo.
COMBO: a new module for EUD parsing
Jul 08, 2021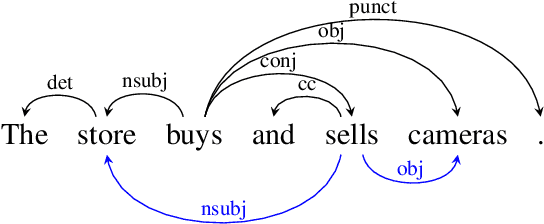

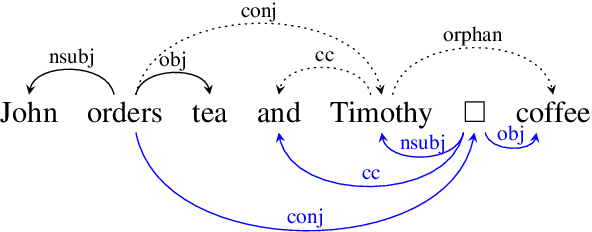
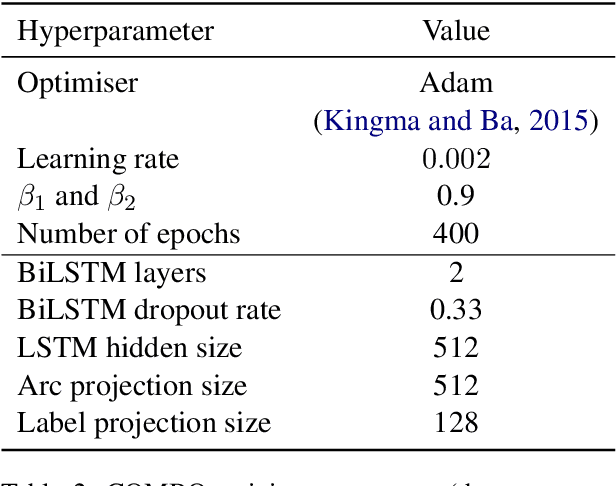
We introduce the COMBO-based approach for EUD parsing and its implementation, which took part in the IWPT 2021 EUD shared task. The goal of this task is to parse raw texts in 17 languages into Enhanced Universal Dependencies (EUD). The proposed approach uses COMBO to predict UD trees and EUD graphs. These structures are then merged into the final EUD graphs. Some EUD edge labels are extended with case information using a single language-independent expansion rule. In the official evaluation, the solution ranked fourth, achieving an average ELAS of 83.79%. The source code is available at https://gitlab.clarin-pl.eu/syntactic-tools/combo.