 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamically Addressing Unseen Rumor via Continual Learning
Apr 18, 2021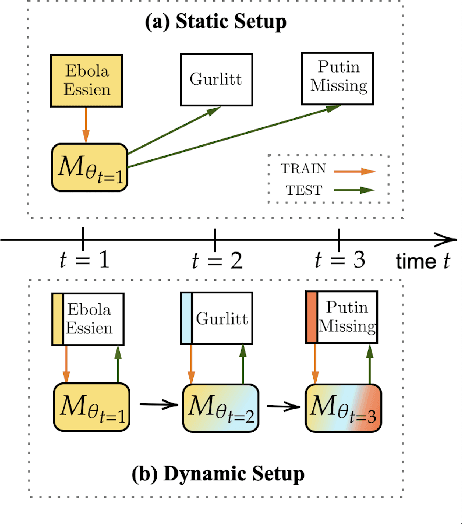
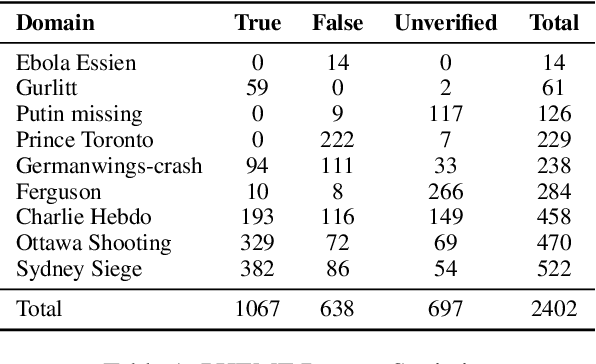
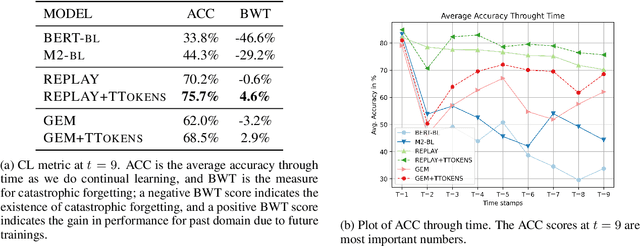
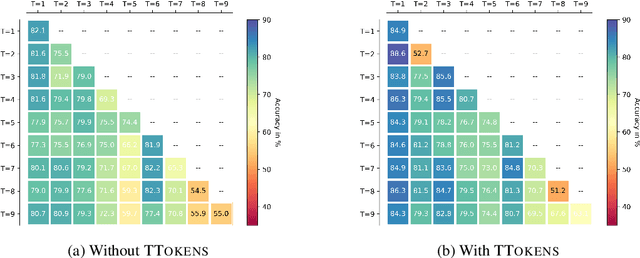
Rumors are often associated with newly emerging events, thus, an ability to deal with unseen rumors is crucial for a rumor veracity classification model. Previous works address this issue by improving the model's generalizability, with an assumption that the model will stay unchanged even after the new outbreak of an event. In this work, we propose an alternative solution to continuously update the model in accordance with the dynamics of rumor domain creations. The biggest technical challenge associated with this new approach is the catastrophic forgetting of previous learnings due to new learnings. We adopt continual learning strategies that control the new learnings to avoid catastrophic forgetting and propose an additional strategy that can jointly be used to strengthen the forgetting alleviation.
IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation
Apr 16, 2021
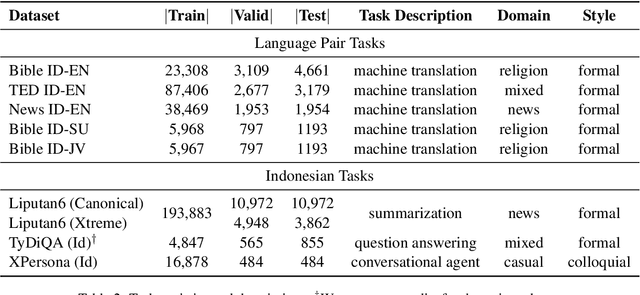
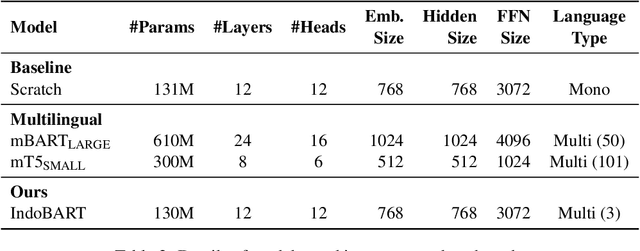
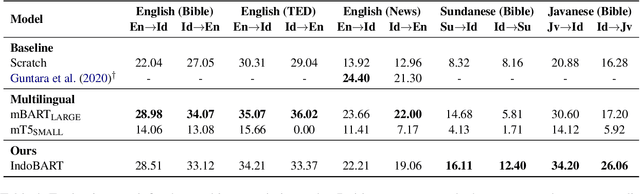
A benchmark provides an ecosystem to measure the advancement of models with standard datasets and automatic and human evaluation metrics. We introduce IndoNLG, the first such benchmark for the Indonesian language for natural language generation (NLG). It covers six tasks: summarization, question answering, open chitchat, as well as three different language-pairs of machine translation tasks. We provide a vast and clean pre-training corpus of Indonesian, Sundanese, and Javanese datasets called Indo4B-Plus, which is used to train our pre-trained NLG model, IndoBART. We evaluate the effectiveness and efficiency of IndoBART by conducting extensive evaluation on all IndoNLG tasks. Our findings show that IndoBART achieves competitive performance on Indonesian tasks with five times fewer parameters compared to the largest multilingual model in our benchmark, mBART-LARGE (Liu et al., 2020), and an almost 4x and 2.5x faster inference time on the CPU and GPU respectively. We additionally demonstrate the ability of IndoBART to learn Javanese and Sundanese, and it achieves decent performance on machine translation tasks.
On Unifying Misinformation Detection
Apr 12, 2021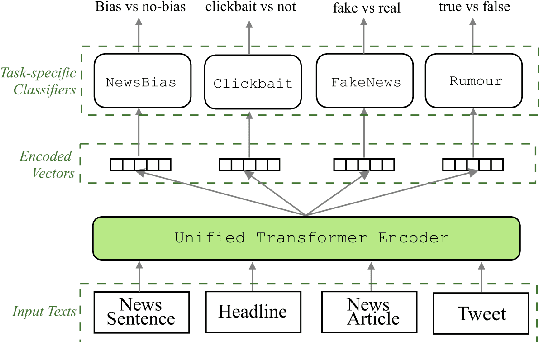

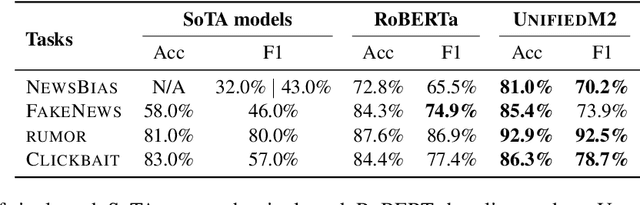
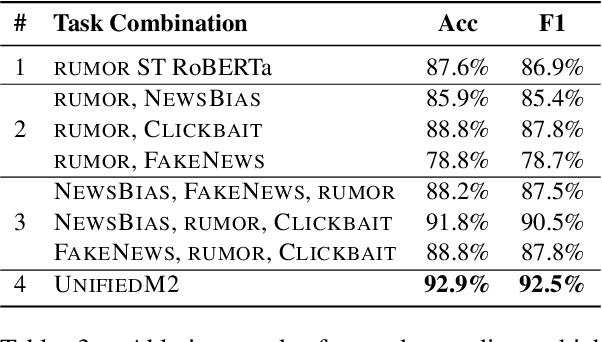
In this paper, we introduce UnifiedM2, a general-purpose misinformation model that jointly models multiple domains of misinformation with a single, unified setup. The model is trained to handle four tasks: detecting news bias, clickbait, fake news, and verifying rumors. By grouping these tasks together, UnifiedM2learns a richer representation of misinformation, which leads to state-of-the-art or comparable performance across all tasks. Furthermore, we demonstrate that UnifiedM2's learned representation is helpful for few-shot learning of unseen misinformation tasks/datasets and model's generalizability to unseen events.
Mitigating Media Bias through Neutral Article Generation
Apr 01, 2021

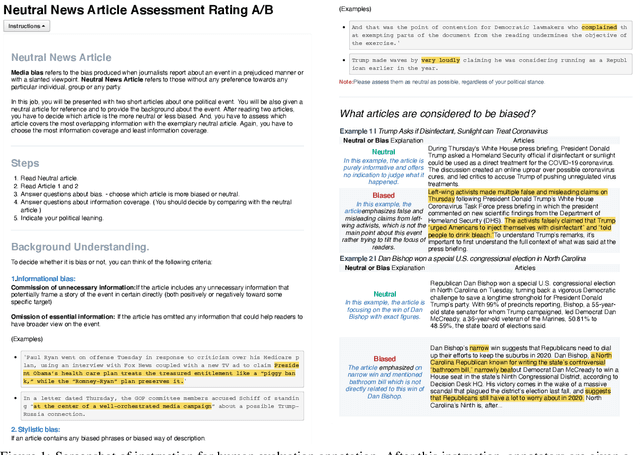

Media bias can lead to increased political polarization, and thus, the need for automatic mitigation methods is growing. Existing mitigation work displays articles from multiple news outlets to provide diverse news coverage, but without neutralizing the bias inherent in each of the displayed articles. Therefore, we propose a new task, a single neutralized article generation out of multiple biased articles, to facilitate more efficient access to balanced and unbiased information. In this paper, we compile a new dataset NeuWS, define an automatic evaluation metric, and provide baselines and multiple analyses to serve as a solid starting point for the proposed task. Lastly, we obtain a human evaluation to demonstrate the alignment between our metric and human judgment.
Multimodal End-to-End Sparse Model for Emotion Recognition
Mar 27, 2021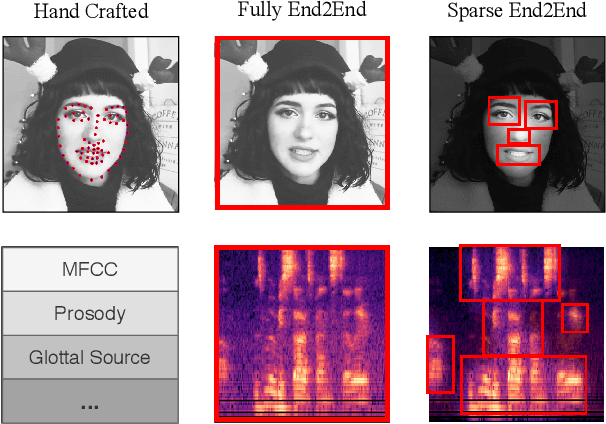
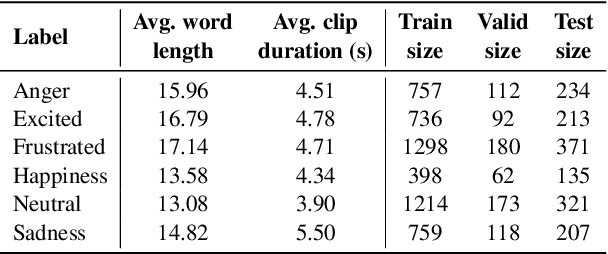
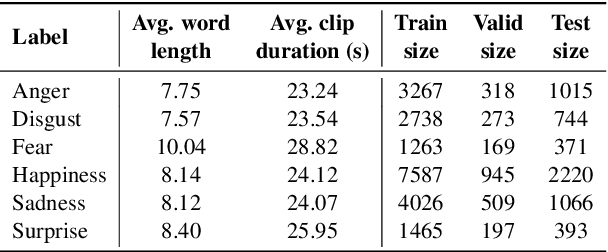
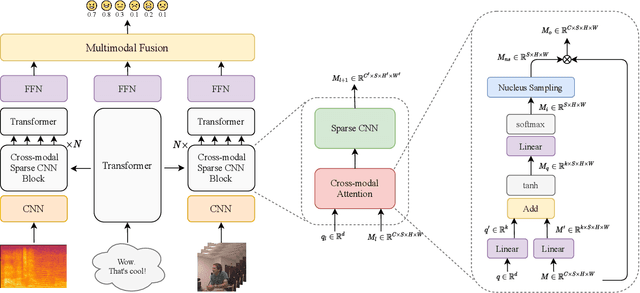
Existing works on multimodal affective computing tasks, such as emotion recognition, generally adopt a two-phase pipeline, first extracting feature representations for each single modality with hand-crafted algorithms and then performing end-to-end learning with the extracted features. However, the extracted features are fixed and cannot be further fine-tuned on different target tasks, and manually finding feature extraction algorithms does not generalize or scale well to different tasks, which can lead to sub-optimal performance. In this paper, we develop a fully end-to-end model that connects the two phases and optimizes them jointly. In addition, we restructure the current datasets to enable the fully end-to-end training. Furthermore, to reduce the computational overhead brought by the end-to-end model, we introduce a sparse cross-modal attention mechanism for the feature extraction. Experimental results show that our fully end-to-end model significantly surpasses the current state-of-the-art models based on the two-phase pipeline. Moreover, by adding the sparse cross-modal attention, our model can maintain performance with around half the computation in the feature extraction part.
Are Multilingual Models Effective in Code-Switching?
Mar 24, 2021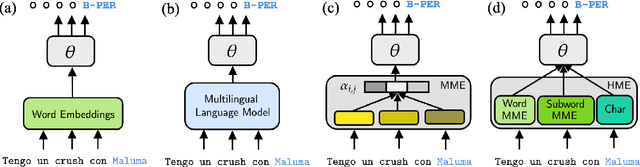
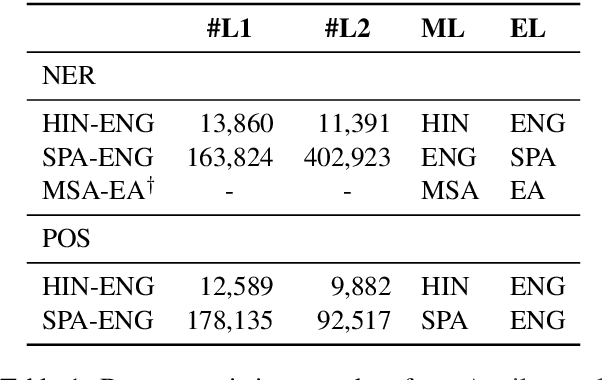
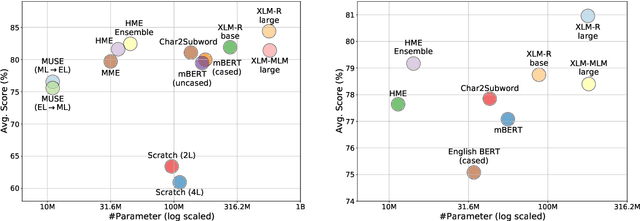
Multilingual language models have shown decent performance in multilingual and cross-lingual natural language understanding tasks. However, the power of these multilingual models in code-switching tasks has not been fully explored. In this paper, we study the effectiveness of multilingual language models to understand their capability and adaptability to the mixed-language setting by considering the inference speed, performance, and number of parameters to measure their practicality. We conduct experiments in three language pairs on named entity recognition and part-of-speech tagging and compare them with existing methods, such as using bilingual embeddings and multilingual meta-embeddings. Our findings suggest that pre-trained multilingual models do not necessarily guarantee high-quality representations on code-switching, while using meta-embeddings achieves similar results with significantly fewer parameters.
Towards Few-Shot Fact-Checking via Perplexity
Mar 17, 2021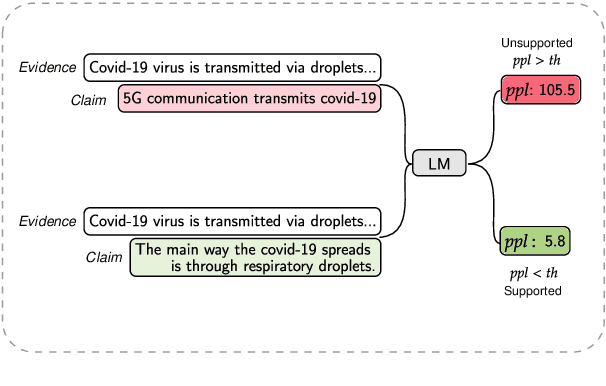

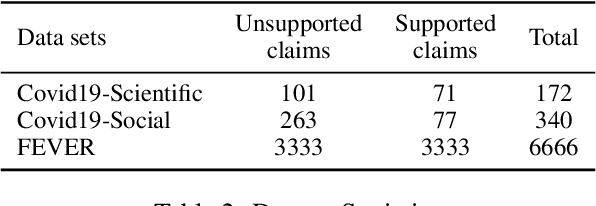
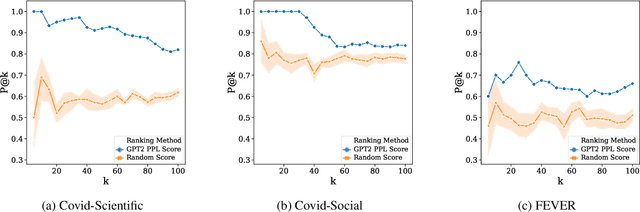
Few-shot learning has drawn researchers' attention to overcome the problem of data scarcity. Recently, large pre-trained language models have shown great performance in few-shot learning for various downstream tasks, such as question answering and machine translation. Nevertheless, little exploration has been made to achieve few-shot learning for the fact-checking task. However, fact-checking is an important problem, especially when the amount of information online is growing exponentially every day. In this paper, we propose a new way of utilizing the powerful transfer learning ability of a language model via a perplexity score. The most notable strength of our methodology lies in its capability in few-shot learning. With only two training samples, our methodology can already outperform the Major Class baseline by more than absolute 10% on the F1-Macro metric across multiple datasets. Through experiments, we empirically verify the plausibility of the rather surprising usage of the perplexity score in the context of fact-checking and highlight the strength of our few-shot methodology by comparing it to strong fine-tuning-based baseline models. Moreover, we construct and publicly release two new fact-checking datasets related to COVID-19.
Model Generalization on COVID-19 Fake News Detection
Jan 11, 2021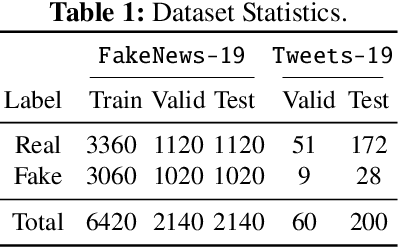
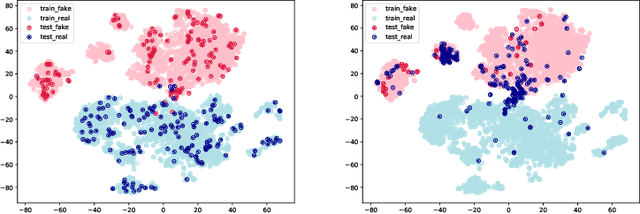

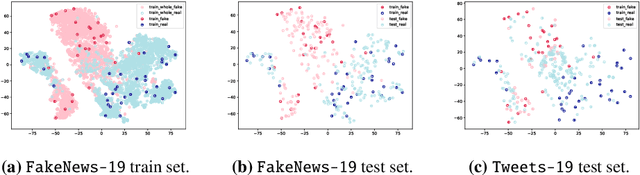
Amid the pandemic COVID-19, the world is facing unprecedented infodemic with the proliferation of both fake and real information. Considering the problematic consequences that the COVID-19 fake-news have brought, the scientific community has put effort to tackle it. To contribute to this fight against the infodemic, we aim to achieve a robust model for the COVID-19 fake-news detection task proposed at CONSTRAINT 2021 (FakeNews-19) by taking two separate approaches: 1) fine-tuning transformers based language models with robust loss functions and 2) removing harmful training instances through influence calculation. We further evaluate the robustness of our models by evaluating on different COVID-19 misinformation test set (Tweets-19) to understand model generalization ability. With the first approach, we achieve 98.13% for weighted F1 score (W-F1) for the shared task, whereas 38.18% W-F1 on the Tweets-19 highest. On the contrary, by performing influence data cleansing, our model with 99% cleansing percentage can achieve 54.33% W-F1 score on Tweets-19 with a trade-off. By evaluating our models on two COVID-19 fake-news test sets, we suggest the importance of model generalization ability in this task to step forward to tackle the COVID-19 fake-news problem in online social media platforms.
CrossNER: Evaluating Cross-Domain Named Entity Recognition
Dec 13, 2020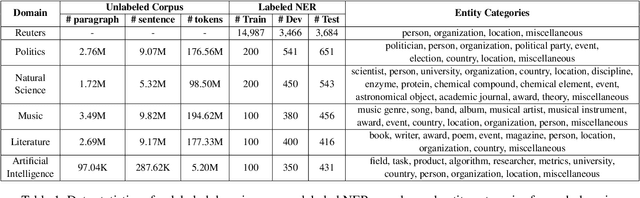
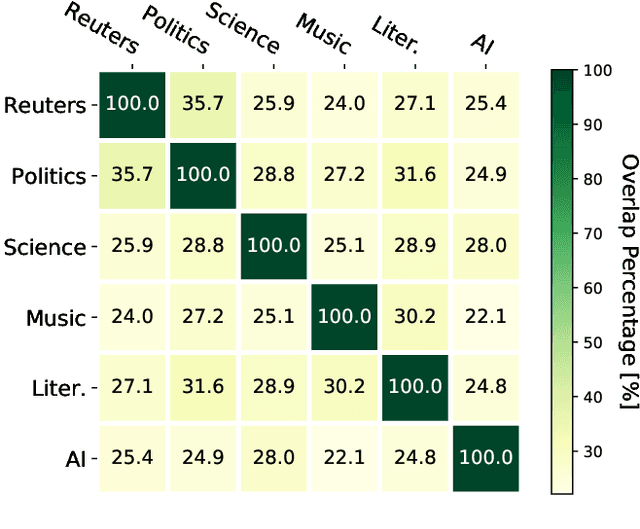
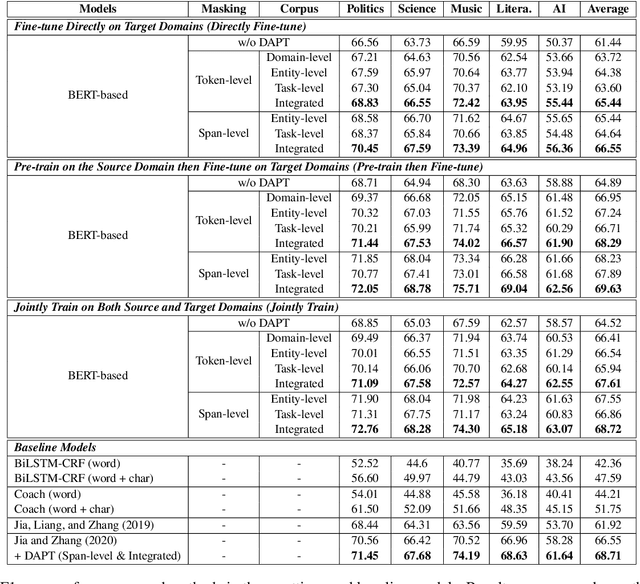
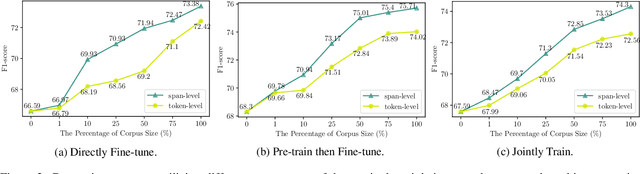
Cross-domain named entity recognition (NER) models are able to cope with the scarcity issue of NER samples in target domains. However, most of the existing NER benchmarks lack domain-specialized entity types or do not focus on a certain domain, leading to a less effective cross-domain evaluation. To address these obstacles, we introduce a cross-domain NER dataset (CrossNER), a fully-labeled collection of NER data spanning over five diverse domains with specialized entity categories for different domains. Additionally, we also provide a domain-related corpus since using it to continue pre-training language models (domain-adaptive pre-training) is effective for the domain adaptation. We then conduct comprehensive experiments to explore the effectiveness of leveraging different levels of the domain corpus and pre-training strategies to do domain-adaptive pre-training for the cross-domain task. Results show that focusing on the fractional corpus containing domain-specialized entities and utilizing a more challenging pre-training strategy in domain-adaptive pre-training are beneficial for the NER domain adaptation, and our proposed method can consistently outperform existing cross-domain NER baselines. Nevertheless, experiments also illustrate the challenge of this cross-domain NER task. We hope that our dataset and baselines will catalyze research in the NER domain adaptation area. The code and data are available at https://github.com/zliucr/CrossNER.
A Study on the Autoregressive and non-Autoregressive Multi-label Learning
Dec 03, 2020Extreme classification tasks are multi-label tasks with an extremely large number of labels (tags). These tasks are hard because the label space is usually (i) very large, e.g. thousands or millions of labels, (ii) very sparse, i.e. very few labels apply to each input document, and (iii) highly correlated, meaning that the existence of one label changes the likelihood of predicting all other labels. In this work, we propose a self-attention based variational encoder-model to extract the label-label and label-feature dependencies jointly and to predict labels for a given input. In more detail, we propose a non-autoregressive latent variable model and compare it to a strong autoregressive baseline that predicts a label based on all previously generated labels. Our model can therefore be used to predict all labels in parallel while still including both label-label and label-feature dependencies through latent variables, and compares favourably to the autoregressive baseline. We apply our models to four standard extreme classification natural language data sets, and one news videos dataset for automated label detection from a lexicon of semantic concepts. Experimental results show that although the autoregressive models, where use a given order of the labels for chain-order label prediction, work great for the small scale labels or the prediction of the highly ranked label, but our non-autoregressive model surpasses them by around 2% to 6% when we need to predict more labels, or the dataset has a larger number of the labels.