 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNER-BERT: A Pre-trained Model for Low-Resource Entity Tagging
Dec 01, 2021
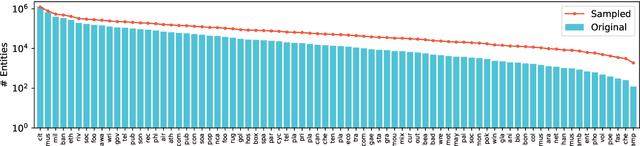

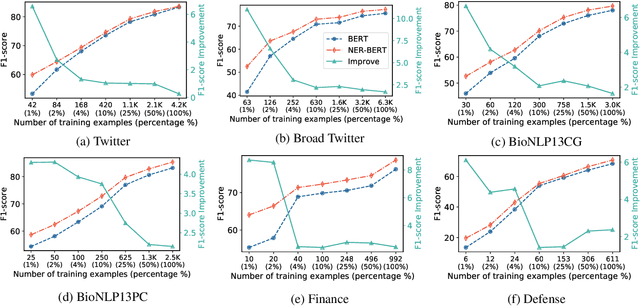
Named entity recognition (NER) models generally perform poorly when large training datasets are unavailable for low-resource domains. Recently, pre-training a large-scale language model has become a promising direction for coping with the data scarcity issue. However, the underlying discrepancies between the language modeling and NER task could limit the models' performance, and pre-training for the NER task has rarely been studied since the collected NER datasets are generally small or large but with low quality. In this paper, we construct a massive NER corpus with a relatively high quality, and we pre-train a NER-BERT model based on the created dataset. Experimental results show that our pre-trained model can significantly outperform BERT as well as other strong baselines in low-resource scenarios across nine diverse domains. Moreover, a visualization of entity representations further indicates the effectiveness of NER-BERT for categorizing a variety of entities.
Confucius, Cyberpunk and Mr. Science: Comparing AI ethics between China and the EU
Nov 15, 2021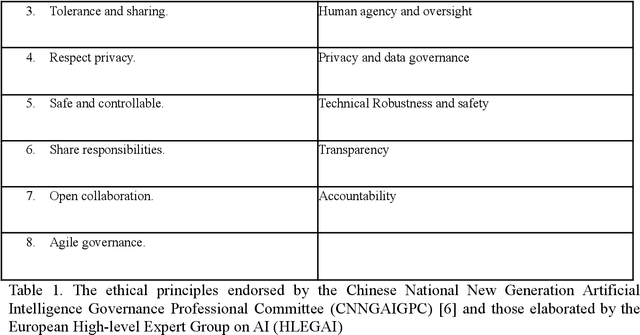
The exponential development and application of artificial intelligence triggered an unprecedented global concern for potential social and ethical issues. Stakeholders from different industries, international foundations, governmental organisations and standards institutions quickly improvised and created various codes of ethics attempting to regulate AI. A major concern is the large homogeneity and presumed consensualism around these principles. While it is true that some ethical doctrines, such as the famous Kantian deontology, aspire to universalism, they are however not universal in practice. In fact, ethical pluralism is more about differences in which relevant questions to ask rather than different answers to a common question. When people abide by different moral doctrines, they tend to disagree on the very approach to an issue. Even when people from different cultures happen to agree on a set of common principles, it does not necessarily mean that they share the same understanding of these concepts and what they entail. In order to better understand the philosophical roots and cultural context underlying ethical principles in AI, we propose to analyse and compare the ethical principles endorsed by the Chinese National New Generation Artificial Intelligence Governance Professional Committee (CNNGAIGPC) and those elaborated by the European High-level Expert Group on AI (HLEGAI). China and the EU have very different political systems and diverge in their cultural heritages. In our analysis, we wish to highlight that principles that seem similar a priori may actually have different meanings, derived from different approaches and reflect distinct goals.
Few-Shot Bot: Prompt-Based Learning for Dialogue Systems
Oct 15, 2021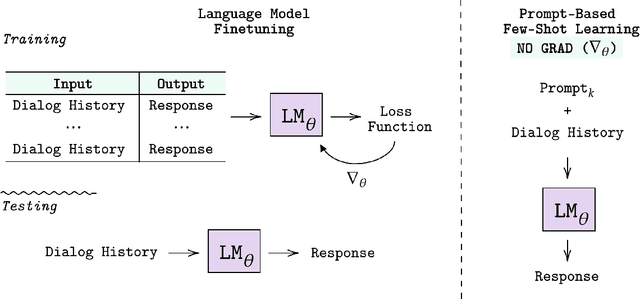
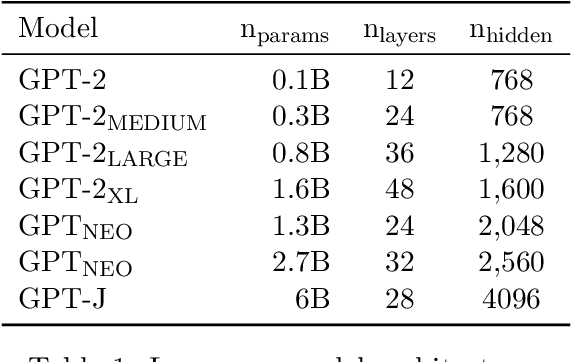
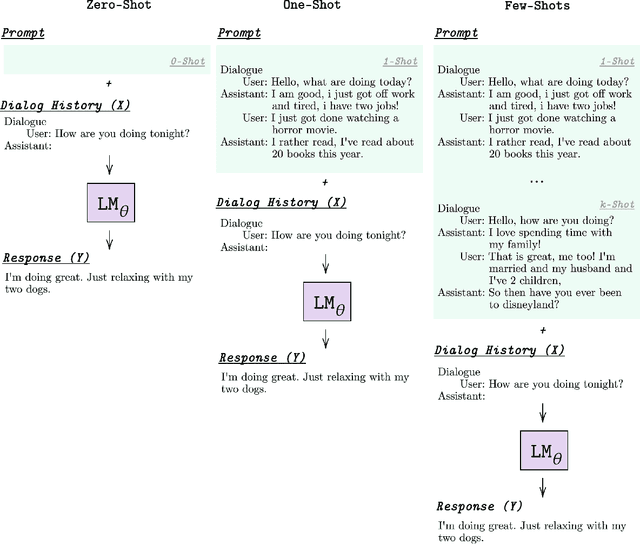
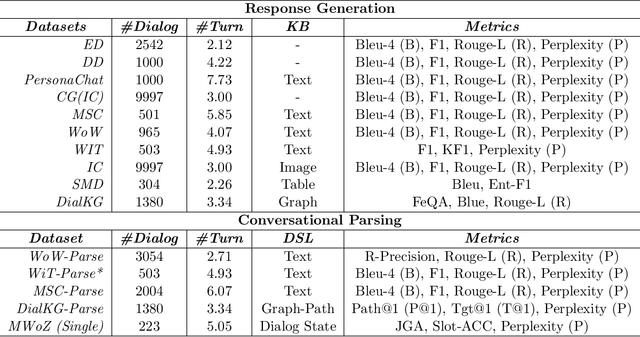
Learning to converse using only a few examples is a great challenge in conversational AI. The current best conversational models, which are either good chit-chatters (e.g., BlenderBot) or goal-oriented systems (e.g., MinTL), are language models (LMs) fine-tuned on large conversational datasets. Training these models is expensive, both in terms of computational resources and time, and it is hard to keep them up to date with new conversational skills. A simple yet unexplored solution is prompt-based few-shot learning (Brown et al. 2020) which does not require gradient-based fine-tuning but instead uses a few examples in the LM context as the only source of learning. In this paper, we explore prompt-based few-shot learning in dialogue tasks. We benchmark LMs of different sizes in nine response generation tasks, which include four knowledge-grounded tasks, a task-oriented generations task, three open-chat tasks, and controlled stylistic generation, and five conversational parsing tasks, which include dialogue state tracking, graph path generation, persona information extraction, document retrieval, and internet query generation. The current largest released LM (GPT-J-6B) using prompt-based few-shot learning, and thus requiring no training, achieves competitive performance to fully trained state-of-the-art models. Moreover, we propose a novel prompt-based few-shot classifier, that also does not require any fine-tuning, to select the most appropriate prompt given a dialogue history. Finally, by combining the power of prompt-based few-shot learning and a Skill Selector, we create an end-to-end chatbot named the Few-Shot Bot (FSB), which automatically selects the most appropriate conversational skill, queries different knowledge bases or the internet, and uses the retrieved knowledge to generate a human-like response, all using only few dialogue examples per skill.
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization
Oct 01, 2021
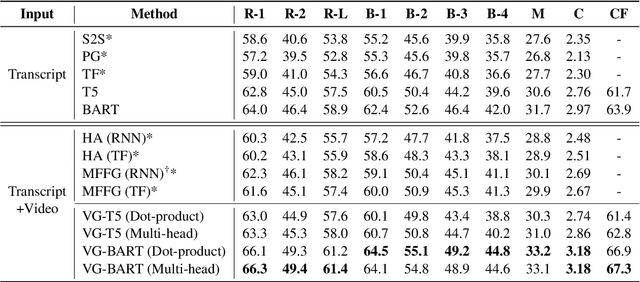
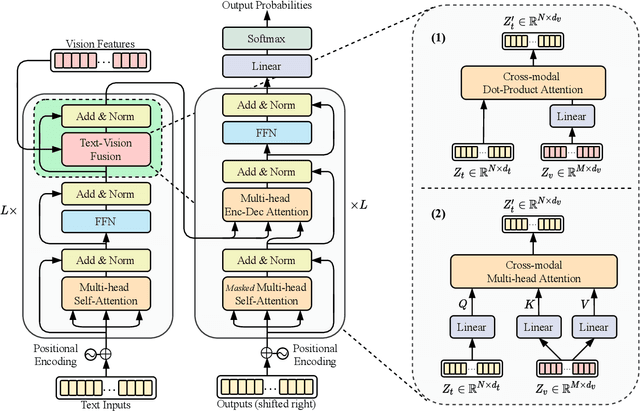

Multimodal abstractive summarization (MAS) models that summarize videos (vision modality) and their corresponding transcripts (text modality) are able to extract the essential information from massive multimodal data on the Internet. Recently, large-scale generative pre-trained language models (GPLMs) have been shown to be effective in text generation tasks. However, existing MAS models cannot leverage GPLMs' powerful generation ability. To fill this research gap, we aim to study two research questions: 1) how to inject visual information into GPLMs without hurting their generation ability; and 2) where is the optimal place in GPLMs to inject the visual information? In this paper, we present a simple yet effective method to construct vision guided (VG) GPLMs for the MAS task using attention-based add-on layers to incorporate visual information while maintaining their original text generation ability. Results show that our best model significantly surpasses the prior state-of-the-art model by 5.7 ROUGE-1, 5.3 ROUGE-2, and 5.1 ROUGE-L scores on the How2 dataset, and our visual guidance method contributes 83.6% of the overall improvement. Furthermore, we conduct thorough ablation studies to analyze the effectiveness of various modality fusion methods and fusion locations.
Language Models are Few-shot Multilingual Learners
Sep 16, 2021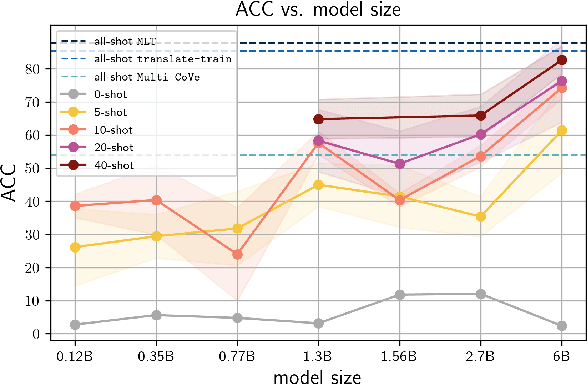
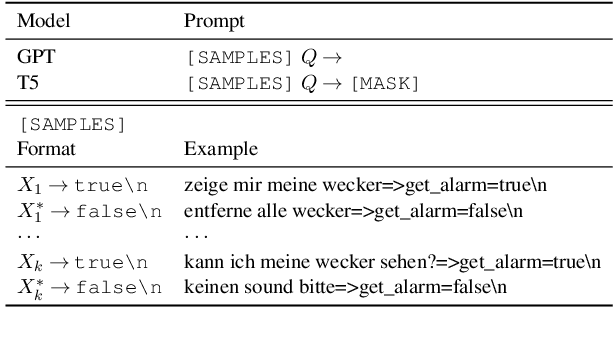
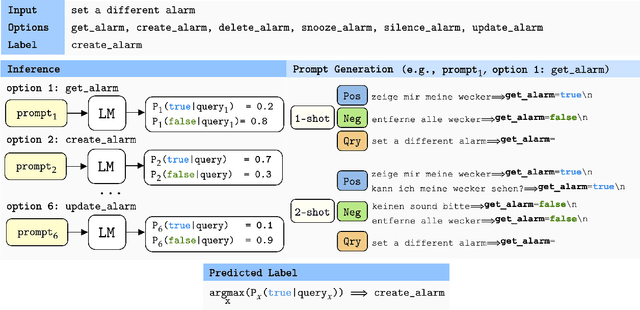
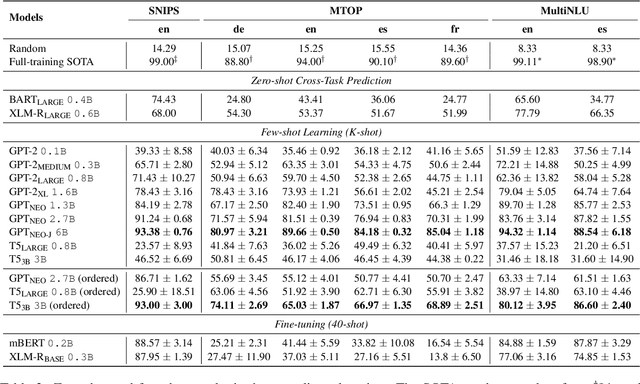
General-purpose language models have demonstrated impressive capabilities, performing on par with state-of-the-art approaches on a range of downstream natural language processing (NLP) tasks and benchmarks when inferring instructions from very few examples. Here, we evaluate the multilingual skills of the GPT and T5 models in conducting multi-class classification on non-English languages without any parameter updates. We show that, given a few English examples as context, pre-trained language models can predict not only English test samples but also non-English ones. Finally, we find the in-context few-shot cross-lingual prediction results of language models are significantly better than random prediction, and they are competitive compared to the existing state-of-the-art cross-lingual models.
Greenformer: Factorization Toolkit for Efficient Deep Neural Networks
Sep 14, 2021

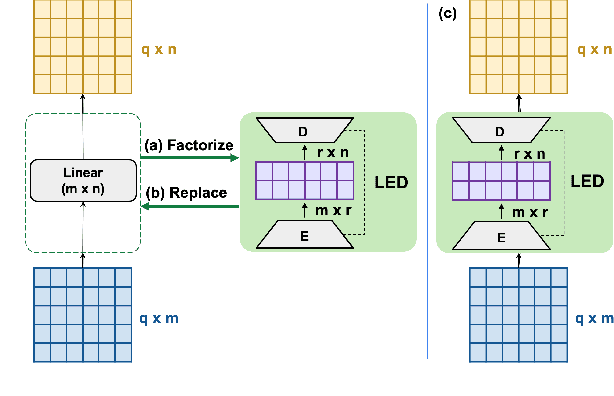
While the recent advances in deep neural networks (DNN) bring remarkable success, the computational cost also increases considerably. In this paper, we introduce Greenformer, a toolkit to accelerate the computation of neural networks through matrix factorization while maintaining performance. Greenformer can be easily applied with a single line of code to any DNN model. Our experimental results show that Greenformer is effective for a wide range of scenarios. We provide the showcase of Greenformer at https://samuelcahyawijaya.github.io/greenformer-demo/.
Zero-Shot Dialogue State Tracking via Cross-Task Transfer
Sep 10, 2021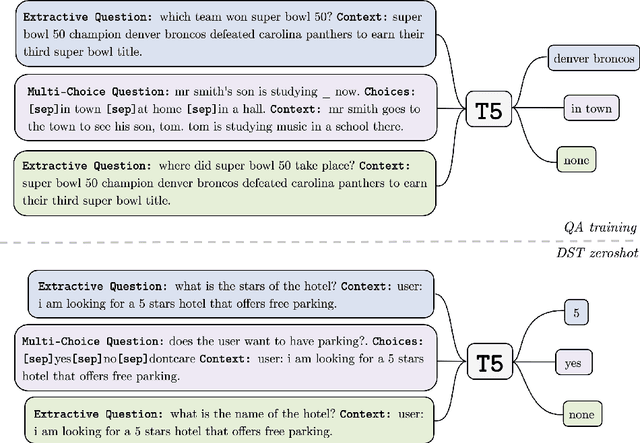
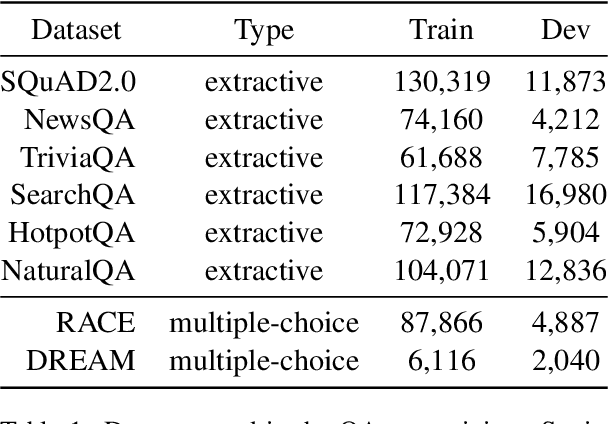
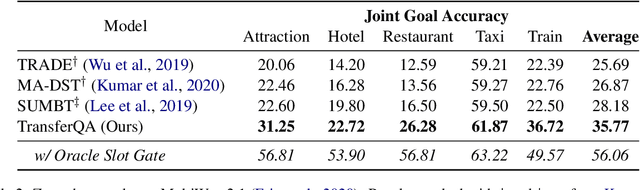
Zero-shot transfer learning for dialogue state tracking (DST) enables us to handle a variety of task-oriented dialogue domains without the expense of collecting in-domain data. In this work, we propose to transfer the \textit{cross-task} knowledge from general question answering (QA) corpora for the zero-shot DST task. Specifically, we propose TransferQA, a transferable generative QA model that seamlessly combines extractive QA and multi-choice QA via a text-to-text transformer framework, and tracks both categorical slots and non-categorical slots in DST. In addition, we introduce two effective ways to construct unanswerable questions, namely, negative question sampling and context truncation, which enable our model to handle "none" value slots in the zero-shot DST setting. The extensive experiments show that our approaches substantially improve the existing zero-shot and few-shot results on MultiWoz. Moreover, compared to the fully trained baseline on the Schema-Guided Dialogue dataset, our approach shows better generalization ability in unseen domains.
Assessing Political Prudence of Open-domain Chatbots
Jun 11, 2021

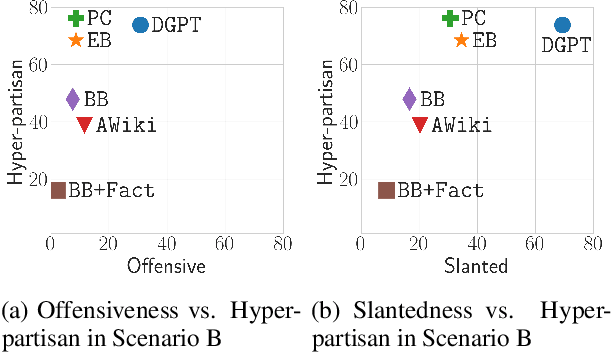
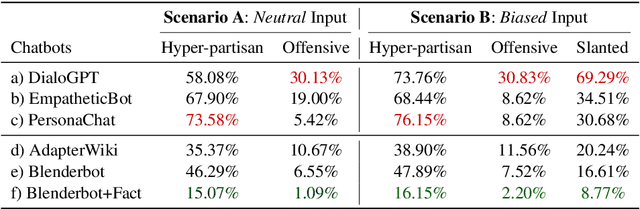
Politically sensitive topics are still a challenge for open-domain chatbots. However, dealing with politically sensitive content in a responsible, non-partisan, and safe behavior way is integral for these chatbots. Currently, the main approach to handling political sensitivity is by simply changing such a topic when it is detected. This is safe but evasive and results in a chatbot that is less engaging. In this work, as a first step towards a politically safe chatbot, we propose a group of metrics for assessing their political prudence. We then conduct political prudence analysis of various chatbots and discuss their behavior from multiple angles through our automatic metric and human evaluation metrics. The testsets and codebase are released to promote research in this area.
CAiRE in DialDoc21: Data Augmentation for Information-Seeking Dialogue System
Jun 08, 2021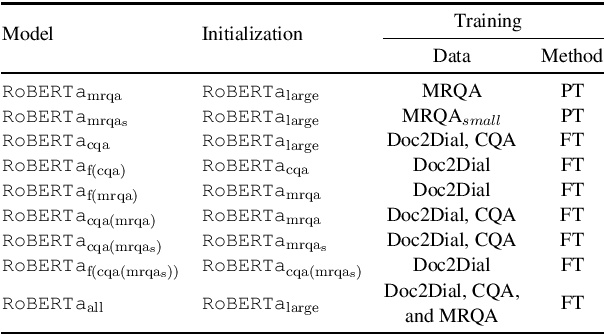
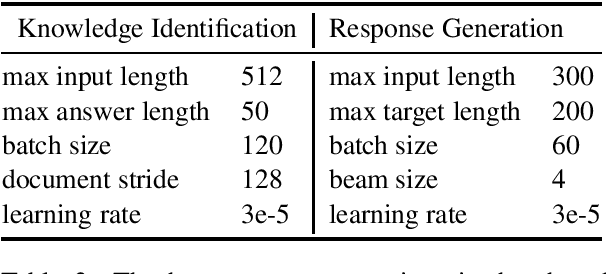
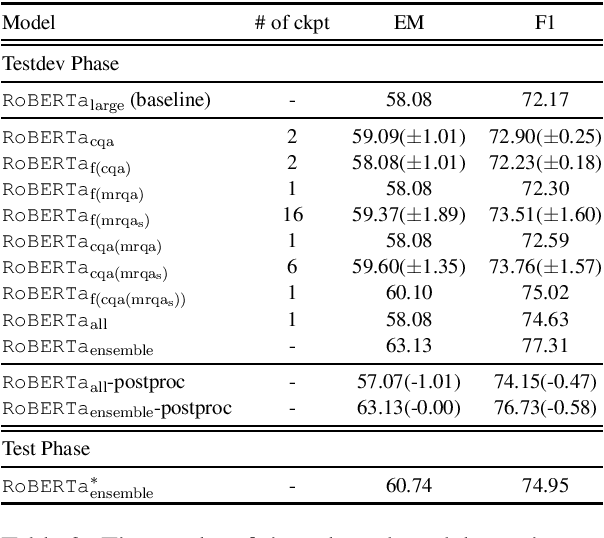
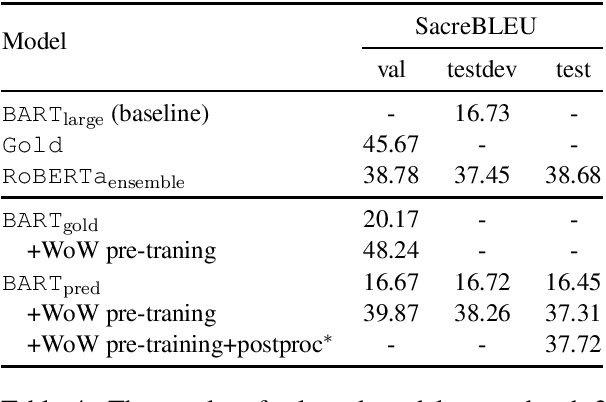
Information-seeking dialogue systems, including knowledge identification and response generation, aim to respond to users with fluent, coherent, and informative responses based on users' needs, which. To tackle this challenge, we utilize data augmentation methods and several training techniques with the pre-trained language models to learn a general pattern of the task and thus achieve promising performance. In DialDoc21 competition, our system achieved 74.95 F1 score and 60.74 Exact Match score in subtask 1, and 37.72 SacreBLEU score in subtask 2. Empirical analysis is provided to explain the effectiveness of our approaches.
X2Parser: Cross-Lingual and Cross-Domain Framework for Task-Oriented Compositional Semantic Parsing
Jun 07, 2021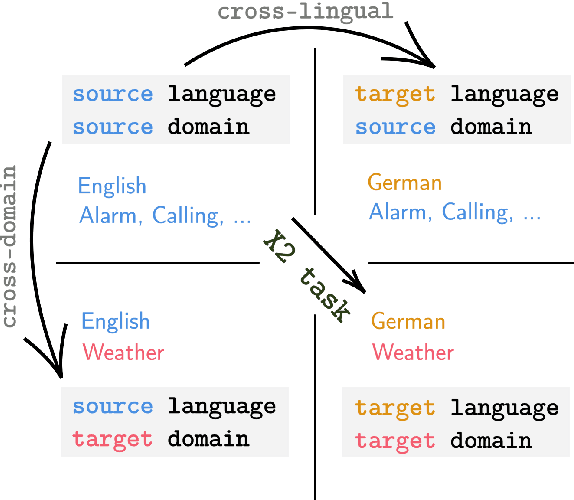
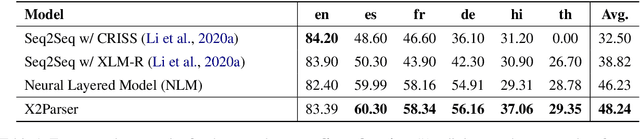
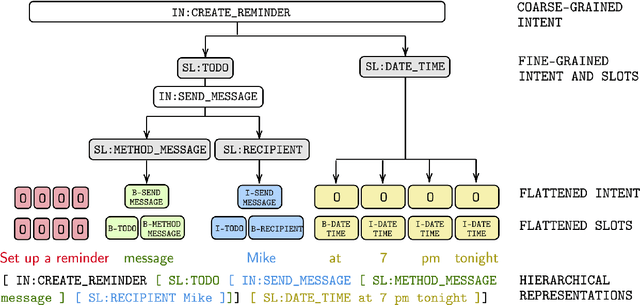

Task-oriented compositional semantic parsing (TCSP) handles complex nested user queries and serves as an essential component of virtual assistants. Current TCSP models rely on numerous training data to achieve decent performance but fail to generalize to low-resource target languages or domains. In this paper, we present X2Parser, a transferable Cross-lingual and Cross-domain Parser for TCSP. Unlike previous models that learn to generate the hierarchical representations for nested intents and slots, we propose to predict flattened intents and slots representations separately and cast both prediction tasks into sequence labeling problems. After that, we further propose a fertility-based slot predictor that first learns to dynamically detect the number of labels for each token, and then predicts the slot types. Experimental results illustrate that our model can significantly outperform existing strong baselines in cross-lingual and cross-domain settings, and our model can also achieve a good generalization ability on target languages of target domains. Furthermore, our model tackles the problem in an efficient non-autoregressive way that reduces the latency by up to 66% compared to the generative model.