 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Tracking Using Weakly Supervised Human Motion Prediction
Oct 19, 2022
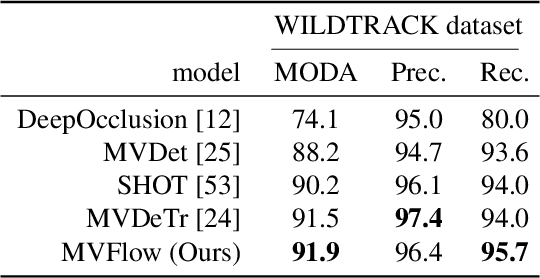
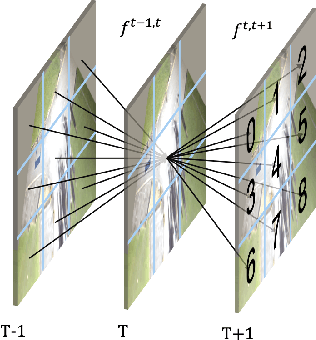
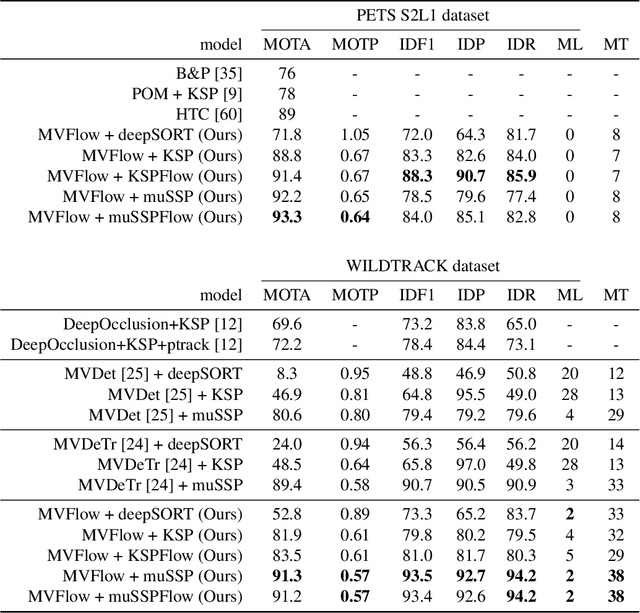
Multi-view approaches to people-tracking have the potential to better handle occlusions than single-view ones in crowded scenes. They often rely on the tracking-by-detection paradigm, which involves detecting people first and then connecting the detections. In this paper, we argue that an even more effective approach is to predict people motion over time and infer people's presence in individual frames from these. This enables to enforce consistency both over time and across views of a single temporal frame. We validate our approach on the PETS2009 and WILDTRACK datasets and demonstrate that it outperforms state-of-the-art methods.
Two-level Data Augmentation for Calibrated Multi-view Detection
Oct 19, 2022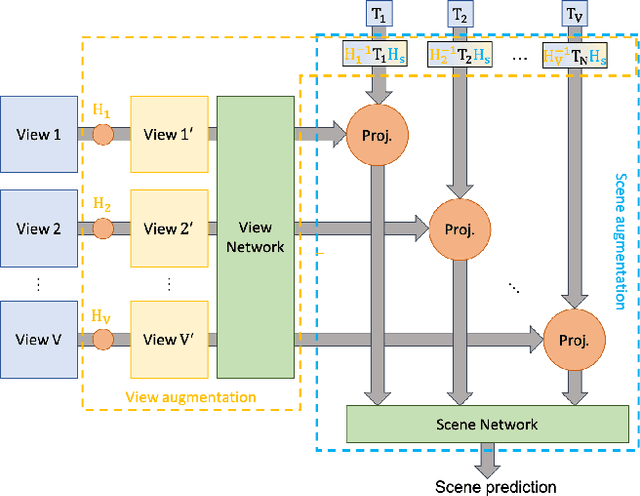
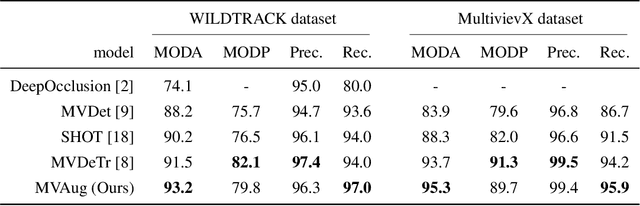

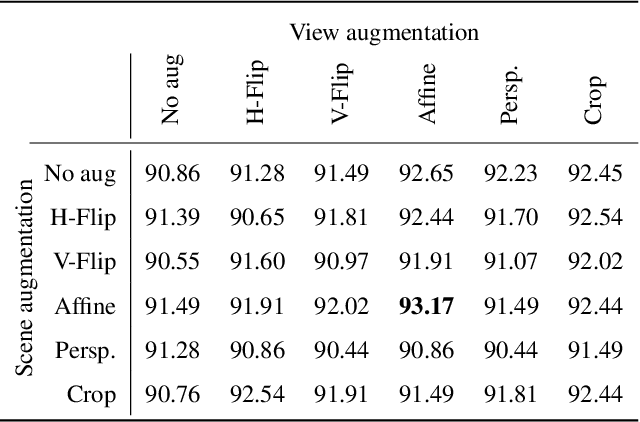
Data augmentation has proven its usefulness to improve model generalization and performance. While it is commonly applied in computer vision application when it comes to multi-view systems, it is rarely used. Indeed geometric data augmentation can break the alignment among views. This is problematic since multi-view data tend to be scarce and it is expensive to annotate. In this work we propose to solve this issue by introducing a new multi-view data augmentation pipeline that preserves alignment among views. Additionally to traditional augmentation of the input image we also propose a second level of augmentation applied directly at the scene level. When combined with our simple multi-view detection model, our two-level augmentation pipeline outperforms all existing baselines by a significant margin on the two main multi-view multi-person detection datasets WILDTRACK and MultiviewX.
Perspective Aware Road Obstacle Detection
Oct 04, 2022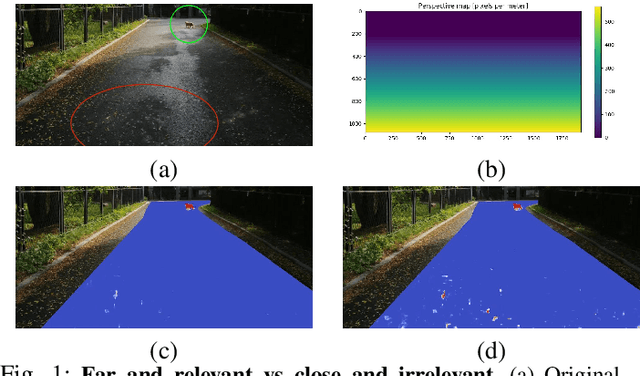

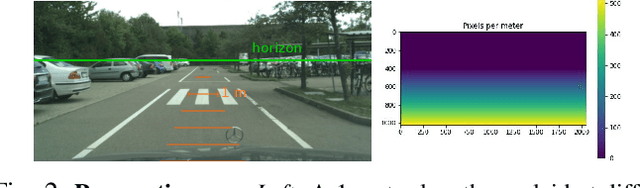

While road obstacle detection techniques have become increasingly effective, they typically ignore the fact that, in practice, the apparent size of the obstacles decreases as their distance to the vehicle increases. In this paper, we account for this by computing a scale map encoding the apparent size of a hypothetical object at every image location. We then leverage this perspective map to (i) generate training data by injecting synthetic objects onto the road in a more realistic fashion than existing methods; and (ii) incorporate perspective information in the decoding part of the detection network to guide the obstacle detector. Our results on standard benchmarks show that, together, these two strategies significantly boost the obstacle detection performance, allowing our approach to consistently outperform state-of-the-art methods in terms of instance-level obstacle detection.
DIG: Draping Implicit Garment over the Human Body
Sep 24, 2022
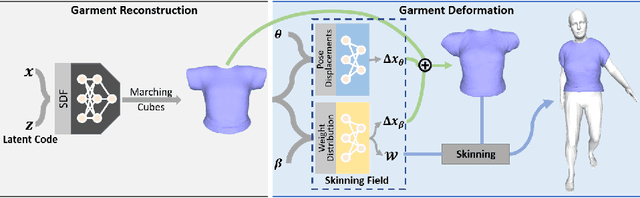

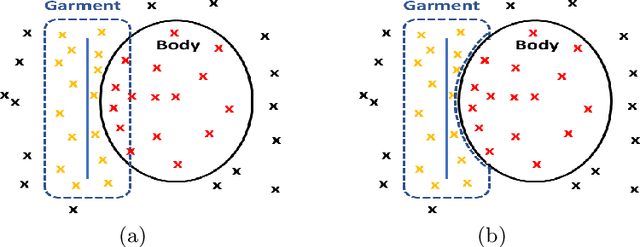
Existing data-driven methods for draping garments over human bodies, despite being effective, cannot handle garments of arbitrary topology and are typically not end-to-end differentiable. To address these limitations, we propose an end-to-end differentiable pipeline that represents garments using implicit surfaces and learns a skinning field conditioned on shape and pose parameters of an articulated body model. To limit body-garment interpenetrations and artifacts, we propose an interpenetration-aware pre-processing strategy of training data and a novel training loss that penalizes self-intersections while draping garments. We demonstrate that our method yields more accurate results for garment reconstruction and deformation with respect to state of the art methods. Furthermore, we show that our method, thanks to its end-to-end differentiability, allows to recover body and garments parameters jointly from image observations, something that previous work could not do.
Learning to Simulate Realistic LiDARs
Sep 22, 2022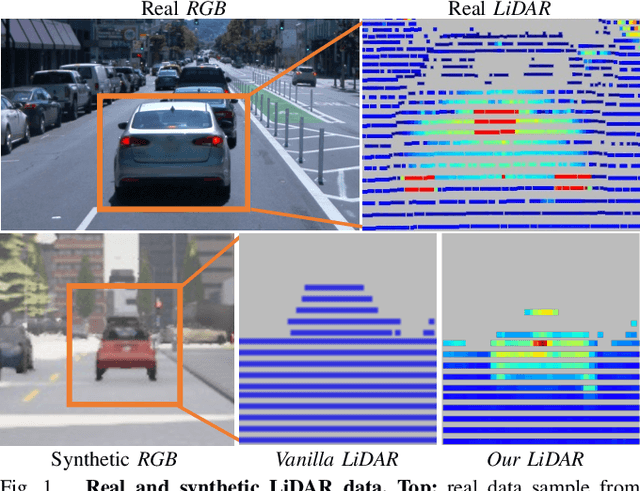
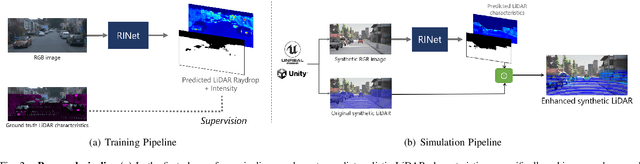


Simulating realistic sensors is a challenging part in data generation for autonomous systems, often involving carefully handcrafted sensor design, scene properties, and physics modeling. To alleviate this, we introduce a pipeline for data-driven simulation of a realistic LiDAR sensor. We propose a model that learns a mapping between RGB images and corresponding LiDAR features such as raydrop or per-point intensities directly from real datasets. We show that our model can learn to encode realistic effects such as dropped points on transparent surfaces or high intensity returns on reflective materials. When applied to naively raycasted point clouds provided by off-the-shelf simulator software, our model enhances the data by predicting intensities and removing points based on the scene's appearance to match a real LiDAR sensor. We use our technique to learn models of two distinct LiDAR sensors and use them to improve simulated LiDAR data accordingly. Through a sample task of vehicle segmentation, we show that enhancing simulated point clouds with our technique improves downstream task performance.
3D Pose Based Feedback for Physical Exercises
Aug 05, 2022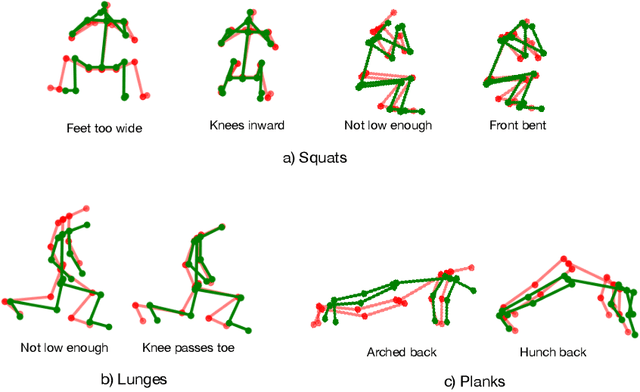
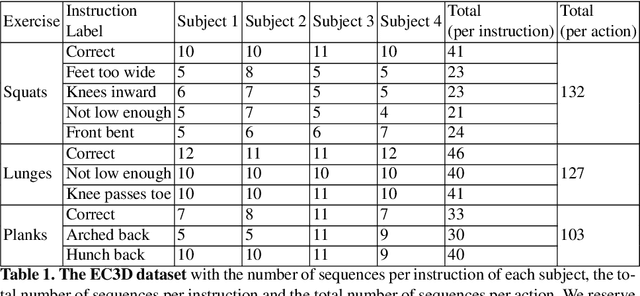
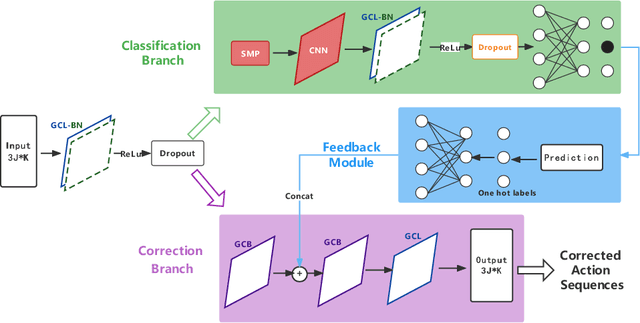
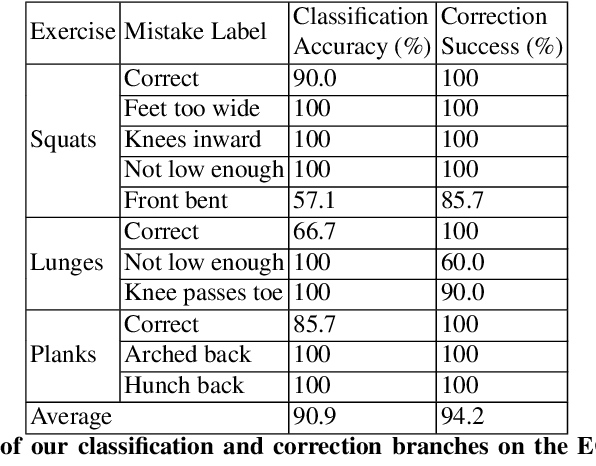
Unsupervised self-rehabilitation exercises and physical training can cause serious injuries if performed incorrectly. We introduce a learning-based framework that identifies the mistakes made by a user and proposes corrective measures for easier and safer individual training. Our framework does not rely on hard-coded, heuristic rules. Instead, it learns them from data, which facilitates its adaptation to specific user needs. To this end, we use a Graph Convolutional Network (GCN) architecture acting on the user's pose sequence to model the relationship between the body joints trajectories. To evaluate our approach, we introduce a dataset with 3 different physical exercises. Our approach yields 90.9% mistake identification accuracy and successfully corrects 94.2% of the mistakes.
Enforcing connectivity of 3D linear structures using their 2D projections
Jul 14, 2022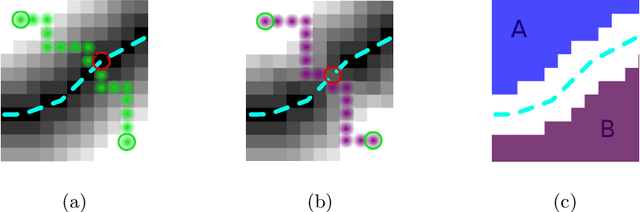
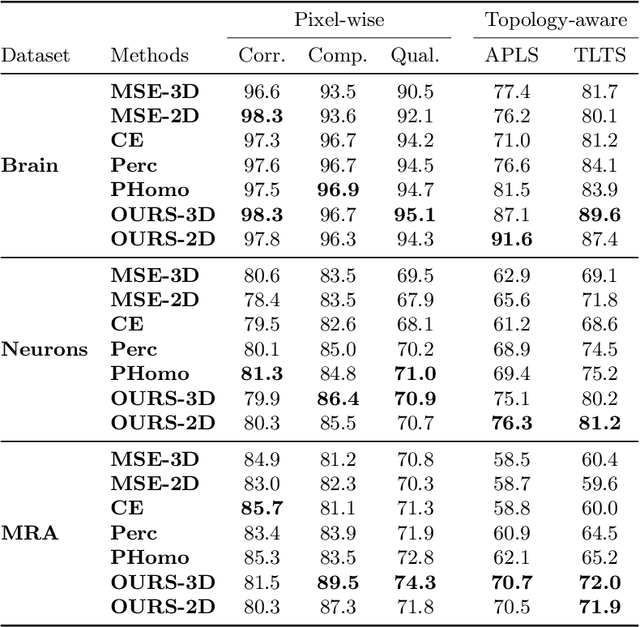
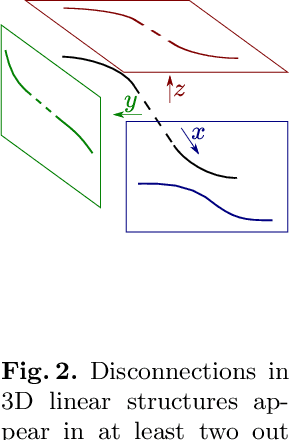
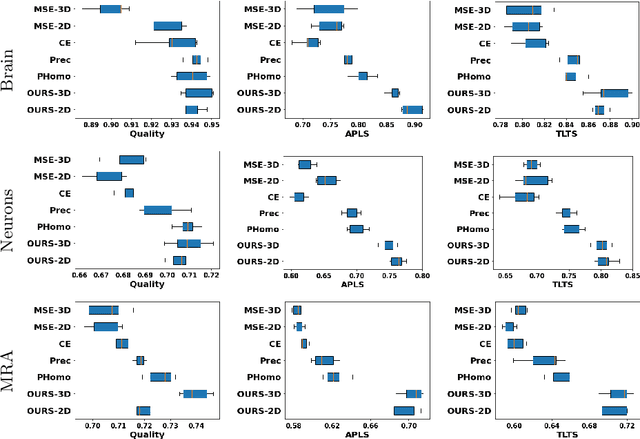
Many biological and medical tasks require the delineation of 3D curvilinear structures such as blood vessels and neurites from image volumes. This is typically done using neural networks trained by minimizing voxel-wise loss functions that do not capture the topological properties of these structures. As a result, the connectivity of the recovered structures is often wrong, which lessens their usefulness. In this paper, we propose to improve the 3D connectivity of our results by minimizing a sum of topology-aware losses on their 2D projections. This suffices to increase the accuracy and to reduce the annotation effort required to provide the required annotated training data.
Neural Annotation Refinement: Development of a New 3D Dataset for Adrenal Gland Analysis
Jul 08, 2022



The human annotations are imperfect, especially when produced by junior practitioners. Multi-expert consensus is usually regarded as golden standard, while this annotation protocol is too expensive to implement in many real-world projects. In this study, we propose a method to refine human annotation, named Neural Annotation Refinement (NeAR). It is based on a learnable implicit function, which decodes a latent vector into represented shape. By integrating the appearance as an input of implicit functions, the appearance-aware NeAR fixes the annotation artefacts. Our method is demonstrated on the application of adrenal gland analysis. We first show that the NeAR can repair distorted golden standards on a public adrenal gland segmentation dataset. Besides, we develop a new Adrenal gLand ANalysis (ALAN) dataset with the proposed NeAR, where each case consists of a 3D shape of adrenal gland and its diagnosis label (normal vs. abnormal) assigned by experts. We show that models trained on the shapes repaired by the NeAR can diagnose adrenal glands better than the original ones. The ALAN dataset will be open-source, with 1,584 shapes for adrenal gland diagnosis, which serves as a new benchmark for medical shape analysis. Code and dataset are available at https://github.com/M3DV/NeAR.
Deep Active Latent Surfaces for Medical Geometries
Jun 21, 2022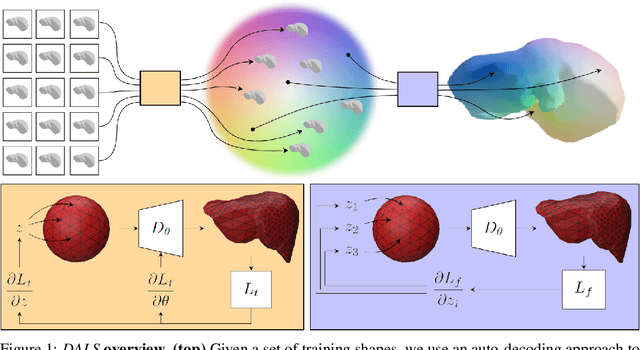

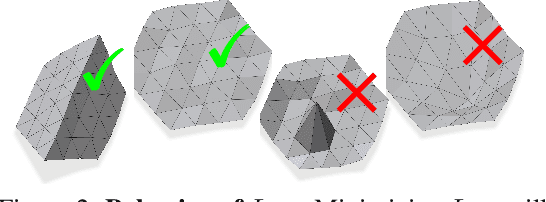
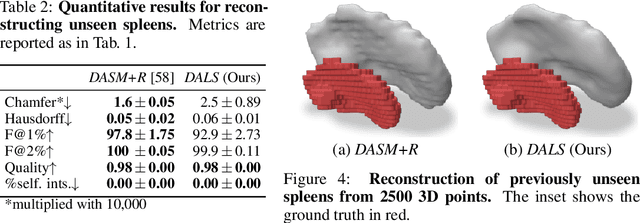
Shape priors have long been known to be effective when reconstructing 3D shapes from noisy or incomplete data. When using a deep-learning based shape representation, this often involves learning a latent representation, which can be either in the form of a single global vector or of multiple local ones. The latter allows more flexibility but is prone to overfitting. In this paper, we advocate a hybrid approach representing shapes in terms of 3D meshes with a separate latent vector at each vertex. During training the latent vectors are constrained to have the same value, which avoids overfitting. For inference, the latent vectors are updated independently while imposing spatial regularization constraints. We show that this gives us both flexibility and generalization capabilities, which we demonstrate on several medical image processing tasks.
On Triangulation as a Form of Self-Supervision for 3D Human Pose Estimation
Mar 29, 2022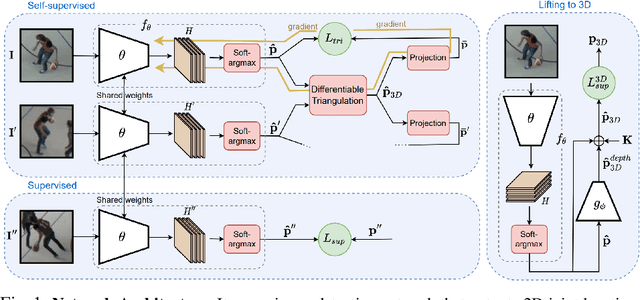

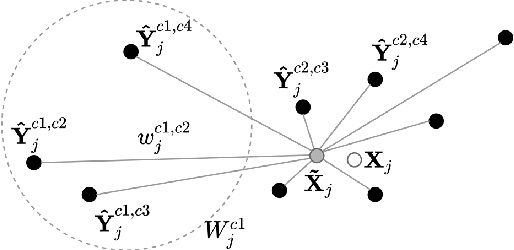
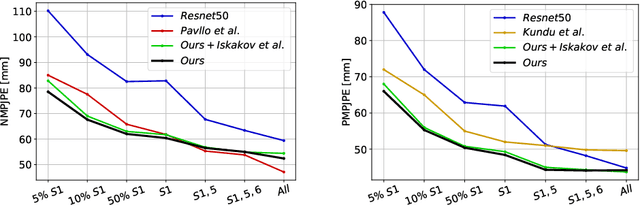
Supervised approaches to 3D pose estimation from single images are remarkably effective when labeled data is abundant. Therefore, much of the recent attention has shifted towards semi and (or) weakly supervised learning. Generating an effective form of supervision with little annotations still poses major challenges in crowded scenes. However, since it is easy to observe a scene from multiple cameras, we propose to impose multi-view geometrical constraints by means of a differentiable triangulation and to use it as form of self-supervision during training when no labels are available. We therefore train a 2D pose estimator in such a way that its predictions correspond to the re-projection of the triangulated 3D one and train an auxiliary network on them to produce the final 3D poses. We complement the triangulation with a weighting mechanism that nullify the impact of noisy predictions caused by self-occlusion or occlusion from other subjects. Our experimental results on Human3.6M and MPI-INF-3DHP substantiate the significance of our weighting strategy where we obtain state-of-the-art results in the semi and weakly supervised learning setup. We also contribute a new multi-player sports dataset that features occlusion, and show the effectiveness of our algorithm over baseline triangulation methods.