 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Latent Surfaces for Medical Geometries
Jun 21, 2022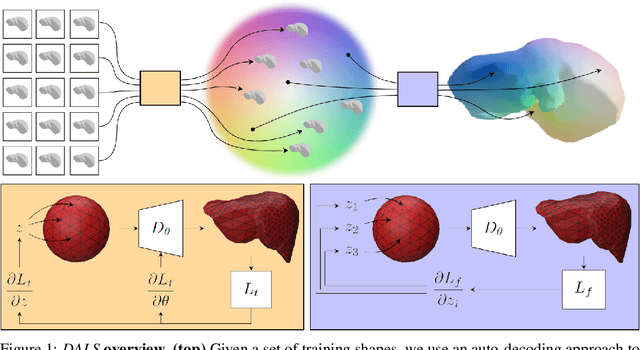

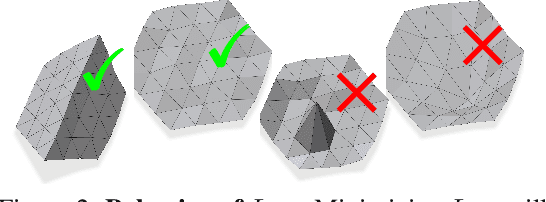
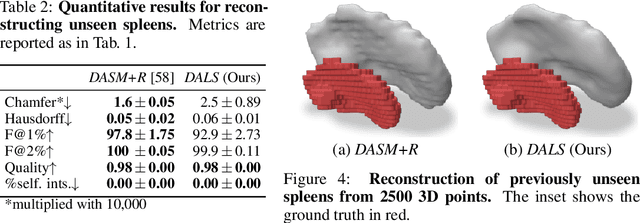
Shape priors have long been known to be effective when reconstructing 3D shapes from noisy or incomplete data. When using a deep-learning based shape representation, this often involves learning a latent representation, which can be either in the form of a single global vector or of multiple local ones. The latter allows more flexibility but is prone to overfitting. In this paper, we advocate a hybrid approach representing shapes in terms of 3D meshes with a separate latent vector at each vertex. During training the latent vectors are constrained to have the same value, which avoids overfitting. For inference, the latent vectors are updated independently while imposing spatial regularization constraints. We show that this gives us both flexibility and generalization capabilities, which we demonstrate on several medical image processing tasks.
Review of Serial and Parallel Min-Cut/Max-Flow Algorithms for Computer Vision
Feb 01, 2022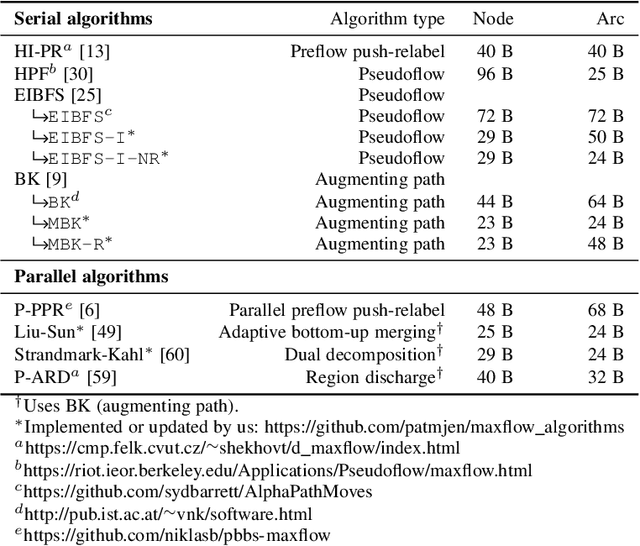
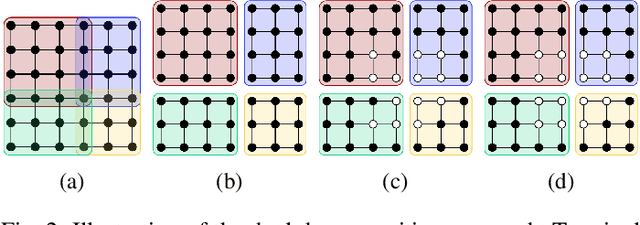
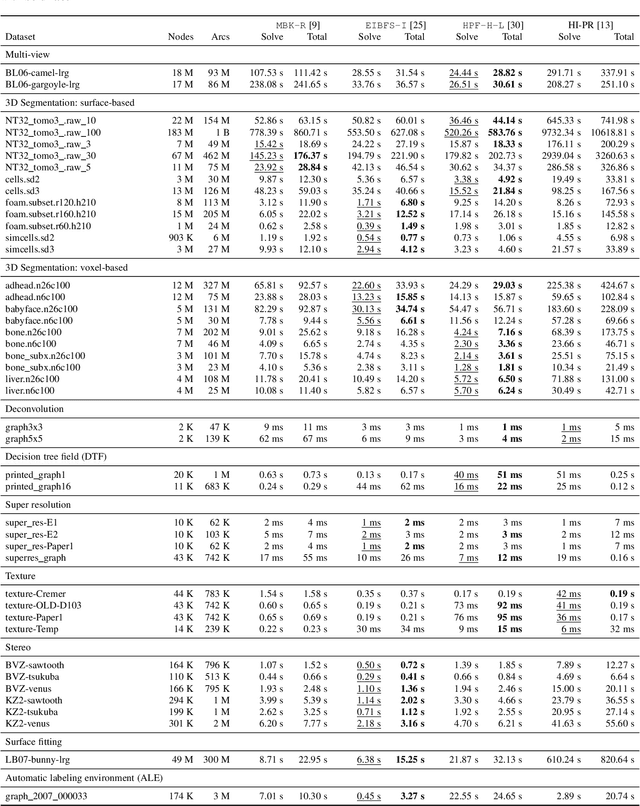
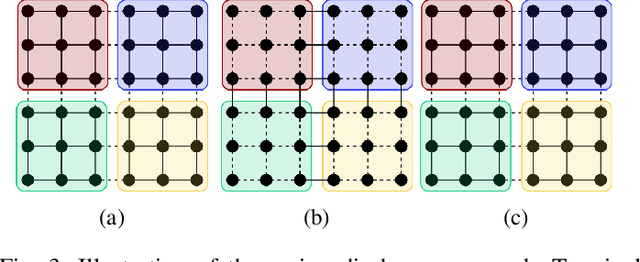
Minimum cut / maximum flow (min-cut/max-flow) algorithms are used to solve a variety of problems in computer vision and thus significant effort has been put into developing fast min-cut/max-flow algorithms. This makes it difficult to choose an optimal algorithm for a given problem - especially for parallel algorithms, which have not been thoroughly compared. In this paper, we review the state-of-the-art min-cut/max-flow algorithms for unstructured graphs in computer vision. We evaluate run time performance and memory use of various implementations of both serial and parallel algorithms on a set of graph cut problems. Our results show that the Hochbaum pseudoflow algorithm is the fastest serial algorithm closely followed by the Excesses Incremental Breadth First Search algorithm, while the Boykov-Kolmogorov algorithm is the most memory efficient. The best parallel algorithm is the adaptive bottom-up merging approach by Liu and Sun. Additionally, we show significant variations in performance between different implementations the same algorithms highlighting the importance of low-level implementation details. Finally, we note that existing parallel min-cut/max-flow algorithms can significantly outperform serial algorithms on large problems but suffers from added overhead on small to medium problems. Implementations of all algorithms are available at https://github.com/patmjen/maxflow_algorithms