 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Distance Function
Oct 29, 2024



Unsigned Distance Functions (UDFs) can be used to represent non-watertight surfaces in a deep learning framework. However, UDFs tend to be brittle and difficult to learn, in part because the surface is located exactly where the UDF is non-differentiable. In this work, we show that Gradient Distance Functions (GDFs) can remedy this by being differentiable at the surface while still being able to represent open surfaces. This is done by associating to each 3D point a 3D vector whose norm is taken to be the unsigned distance to the surface and whose orientation is taken to be the direction towards the closest surface point. We demonstrate the effectiveness of GDFs on ShapeNet Car, Multi-Garment, and 3D-Scene datasets with both single-shape reconstruction networks or categorical auto-decoders.
A Latent Implicit 3D Shape Model for Multiple Levels of Detail
Sep 10, 2024



Implicit neural representations map a shape-specific latent code and a 3D coordinate to its corresponding signed distance (SDF) value. However, this approach only offers a single level of detail. Emulating low levels of detail can be achieved with shallow networks, but the generated shapes are typically not smooth. Alternatively, some network designs offer multiple levels of detail, but are limited to overfitting a single object. To address this, we propose a new shape modeling approach, which enables multiple levels of detail and guarantees a smooth surface at each level. At the core, we introduce a novel latent conditioning for a multiscale and bandwith-limited neural architecture. This results in a deep parameterization of multiple shapes, where early layers quickly output approximated SDF values. This allows to balance speed and accuracy within a single network and enhance the efficiency of implicit scene rendering. We demonstrate that by limiting the bandwidth of the network, we can maintain smooth surfaces across all levels of detail. At finer levels, reconstruction quality is on par with the state of the art models, which are limited to a single level of detail.
Learning to Simulate Realistic LiDARs
Sep 22, 2022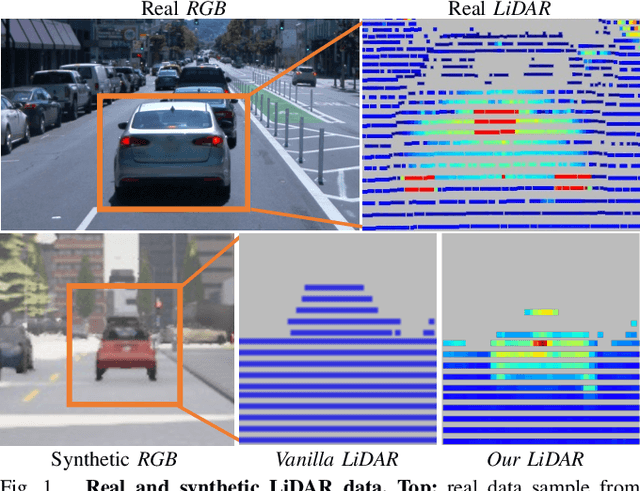
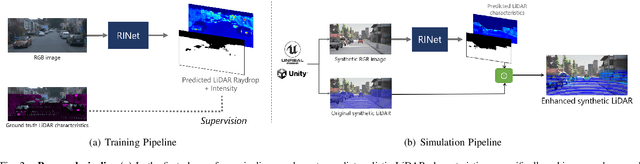


Simulating realistic sensors is a challenging part in data generation for autonomous systems, often involving carefully handcrafted sensor design, scene properties, and physics modeling. To alleviate this, we introduce a pipeline for data-driven simulation of a realistic LiDAR sensor. We propose a model that learns a mapping between RGB images and corresponding LiDAR features such as raydrop or per-point intensities directly from real datasets. We show that our model can learn to encode realistic effects such as dropped points on transparent surfaces or high intensity returns on reflective materials. When applied to naively raycasted point clouds provided by off-the-shelf simulator software, our model enhances the data by predicting intensities and removing points based on the scene's appearance to match a real LiDAR sensor. We use our technique to learn models of two distinct LiDAR sensors and use them to improve simulated LiDAR data accordingly. Through a sample task of vehicle segmentation, we show that enhancing simulated point clouds with our technique improves downstream task performance.
MeshUDF: Fast and Differentiable Meshing of Unsigned Distance Field Networks
Nov 29, 2021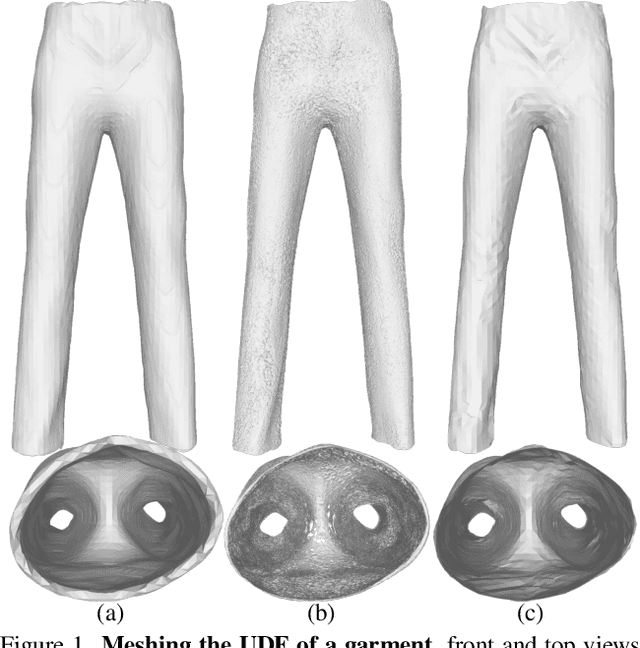
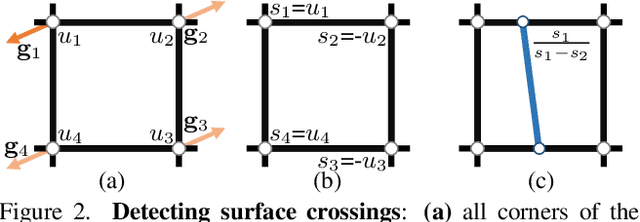
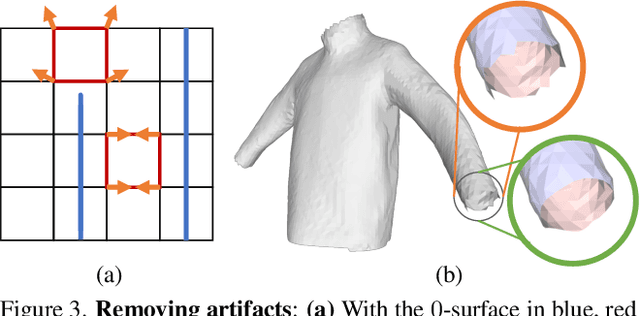

Recent work modelling 3D open surfaces train deep neural networks to approximate Unsigned Distance Fields (UDFs) and implicitly represent shapes. To convert this representation to an explicit mesh, they either use computationally expensive methods to mesh a dense point cloud sampling of the surface, or distort the surface by inflating it into a Signed Distance Field (SDF). By contrast, we propose to directly mesh deep UDFs as open surfaces with an extension of marching cubes, by locally detecting surface crossings. Our method is order of magnitude faster than meshing a dense point cloud, and more accurate than inflating open surfaces. Moreover, we make our surface extraction differentiable, and show it can help fit sparse supervision signals.
DeepMesh: Differentiable Iso-Surface Extraction
Jun 20, 2021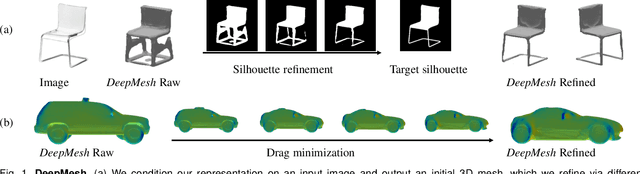
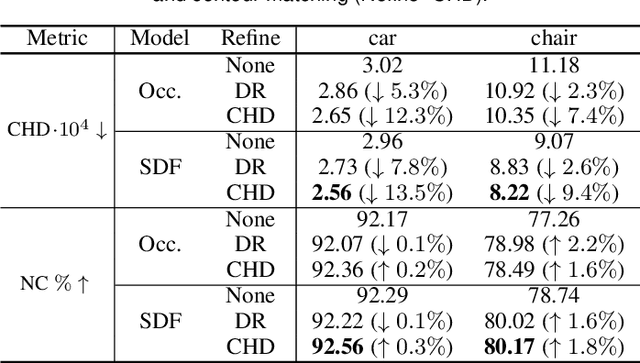
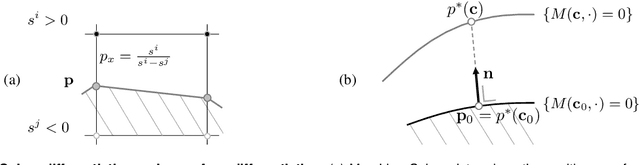
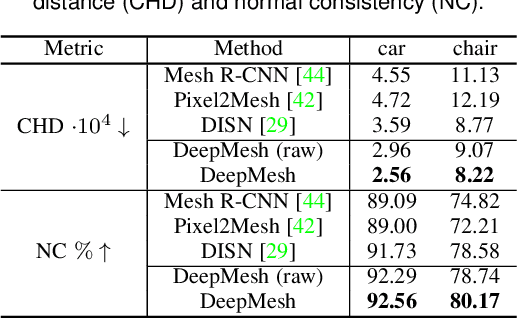
Geometric Deep Learning has recently made striking progress with the advent of continuous Deep Implicit Fields. They allow for detailed modeling of watertight surfaces of arbitrary topology while not relying on a 3D Euclidean grid, resulting in a learnable parameterization that is unlimited in resolution. Unfortunately, these methods are often unsuitable for applications that require an explicit mesh-based surface representation because converting an implicit field to such a representation relies on the Marching Cubes algorithm, which cannot be differentiated with respect to the underlying implicit field. In this work, we remove this limitation and introduce a differentiable way to produce explicit surface mesh representations from Deep Implicit Fields. Our key insight is that by reasoning on how implicit field perturbations impact local surface geometry, one can ultimately differentiate the 3D location of surface samples with respect to the underlying deep implicit field. We exploit this to define DeepMesh -- end-to-end differentiable mesh representation that can vary its topology. We use two different applications to validate our theoretical insight: Single view 3D Reconstruction via Differentiable Rendering and Physically-Driven Shape Optimization. In both cases our end-to-end differentiable parameterization gives us an edge over state-of-the-art algorithms.
Sketch2Mesh: Reconstructing and Editing 3D Shapes from Sketches
Apr 01, 2021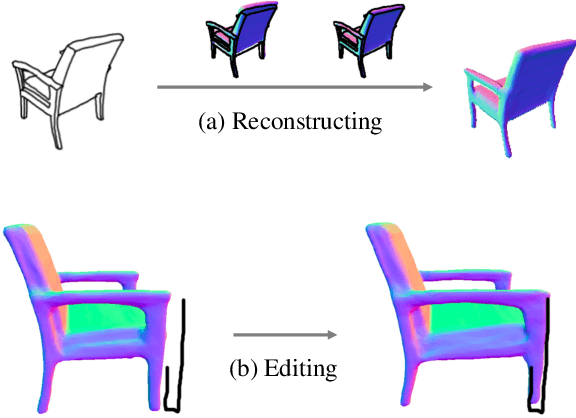

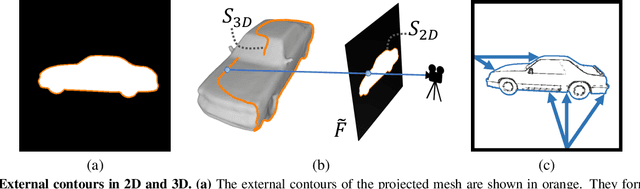
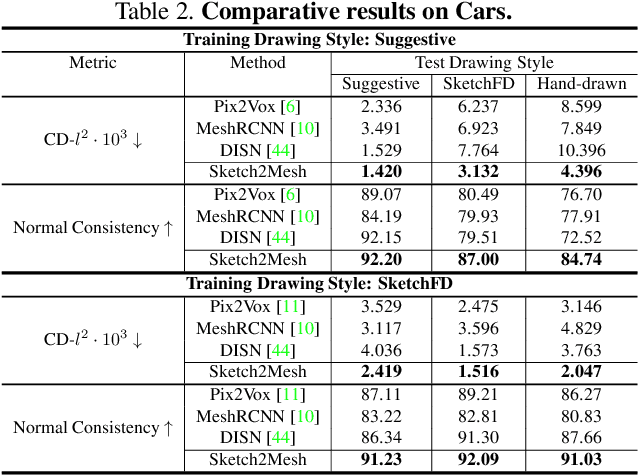
Reconstructing 3D shape from 2D sketches has long been an open problem because the sketches only provide very sparse and ambiguous information. In this paper, we use an encoder/decoder architecture for the sketch to mesh translation. This enables us to leverage its latent parametrization to represent and refine a 3D mesh so that its projections match the external contours outlined in the sketch. We will show that this approach is easy to deploy, robust to style changes, and effective. Furthermore, it can be used for shape refinement given only single pen strokes. We compare our approach to state-of-the-art methods on sketches -- both hand-drawn and synthesized -- and demonstrate that we outperform them.
AnalogNet: Convolutional Neural Network Inference on Analog Focal Plane Sensor Processors
Jun 21, 2020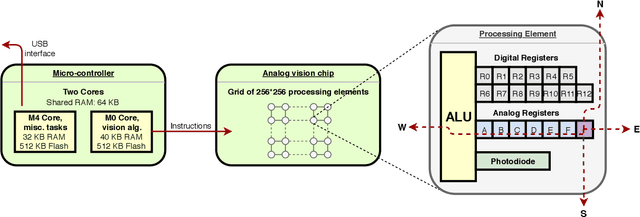
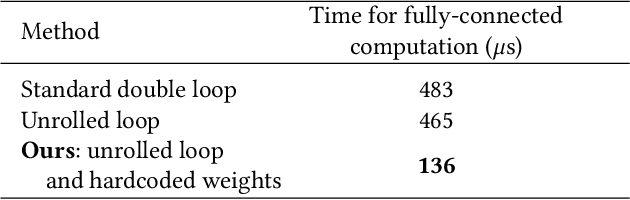


We present a high-speed, energy-efficient Convolutional Neural Network (CNN) architecture utilising the capabilities of a unique class of devices known as analog Focal Plane Sensor Processors (FPSP), in which the sensor and the processor are embedded together on the same silicon chip. Unlike traditional vision systems, where the sensor array sends collected data to a separate processor for processing, FPSPs allow data to be processed on the imaging device itself. This unique architecture enables ultra-fast image processing and high energy efficiency, at the expense of limited processing resources and approximate computations. In this work, we show how to convert standard CNNs to FPSP code, and demonstrate a method of training networks to increase their robustness to analog computation errors. Our proposed architecture, coined AnalogNet, reaches a testing accuracy of 96.9% on the MNIST handwritten digits recognition task, at a speed of 2260 FPS, for a cost of 0.7 mJ per frame.
UCLID-Net: Single View Reconstruction in Object Space
Jun 16, 2020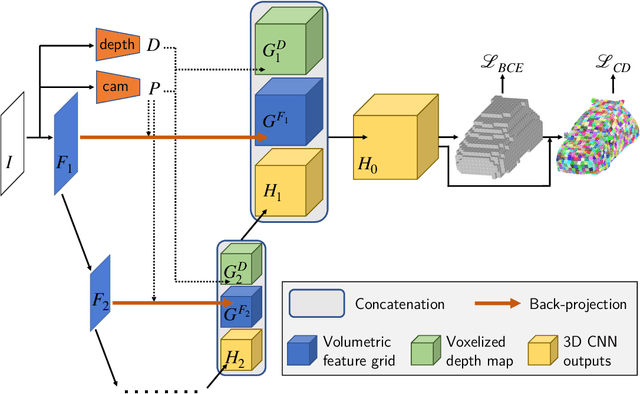

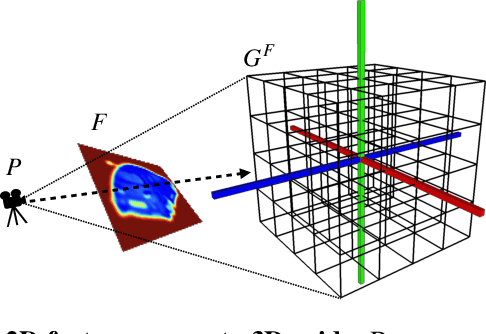

Most state-of-the-art deep geometric learning single-view reconstruction approaches rely on encoder-decoder architectures that output either shape parametrizations or implicit representations. However, these representations rarely preserve the Euclidean structure of the 3D space objects exist in. In this paper, we show that building a geometry preserving 3-dimensional latent space helps the network concurrently learn global shape regularities and local reasoning in the object coordinate space and, as a result, boosts performance. We demonstrate both on ShapeNet synthetic images, which are often used for benchmarking purposes, and on real-world images that our approach outperforms state-of-the-art ones. Furthermore, the single-view pipeline naturally extends to multi-view reconstruction, which we also show.