 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCode: Robustness Evaluation of Code Generation Models
Dec 20, 2022



Code generation models have achieved impressive performance. However, they tend to be brittle as slight edits to a prompt could lead to very different generations; these robustness properties, critical for user experience when deployed in real-life applications, are not well understood. Most existing works on robustness in text or code tasks have focused on classification, while robustness in generation tasks is an uncharted area and to date there is no comprehensive benchmark for robustness in code generation. In this paper, we propose ReCode, a comprehensive robustness evaluation benchmark for code generation models. We customize over 30 transformations specifically for code on docstrings, function and variable names, code syntax, and code format. They are carefully designed to be natural in real-life coding practice, preserve the original semantic meaning, and thus provide multifaceted assessments of a model's robustness performance. With human annotators, we verified that over 90% of the perturbed prompts do not alter the semantic meaning of the original prompt. In addition, we define robustness metrics for code generation models considering the worst-case behavior under each type of perturbation, taking advantage of the fact that executing the generated code can serve as objective evaluation. We demonstrate ReCode on SOTA models using HumanEval, MBPP, as well as function completion tasks derived from them. Interesting observations include: better robustness for CodeGen over InCoder and GPT-J; models are most sensitive to syntax perturbations; more challenging robustness evaluation on MBPP over HumanEval.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022



We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
ContraGen: Effective Contrastive Learning For Causal Language Model
Oct 03, 2022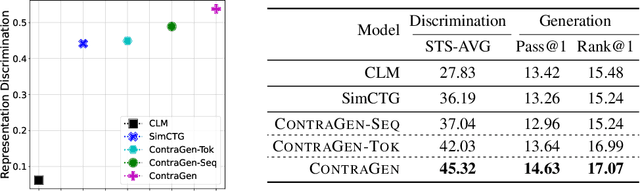
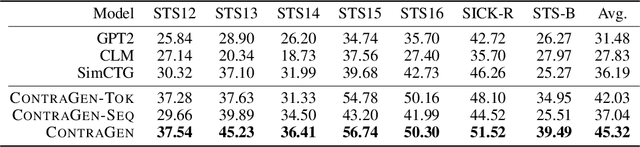
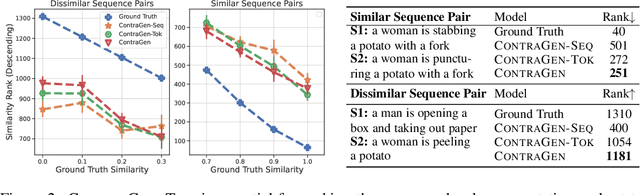
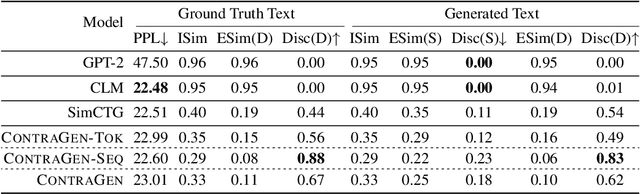
Despite exciting progress in large-scale language generation, the expressiveness of its representations is severely limited by the \textit{anisotropy} issue where the hidden representations are distributed into a narrow cone in the vector space. To address this issue, we present ContraGen, a novel contrastive learning framework to improve the representation with better uniformity and discrimination. We assess ContraGen on a wide range of downstream tasks in natural and programming languages. We show that ContraGen can effectively enhance both uniformity and discrimination of the representations and lead to the desired improvement on various language understanding tasks where discriminative representations are crucial for attaining good performance. Specifically, we attain $44\%$ relative improvement on the Semantic Textual Similarity tasks and $34\%$ on Code-to-Code Search tasks. Furthermore, by improving the expressiveness of the representations, ContraGen also boosts the source code generation capability with $9\%$ relative improvement on execution accuracy on the HumanEval benchmark.
Debiasing Neural Retrieval via In-batch Balancing Regularization
May 18, 2022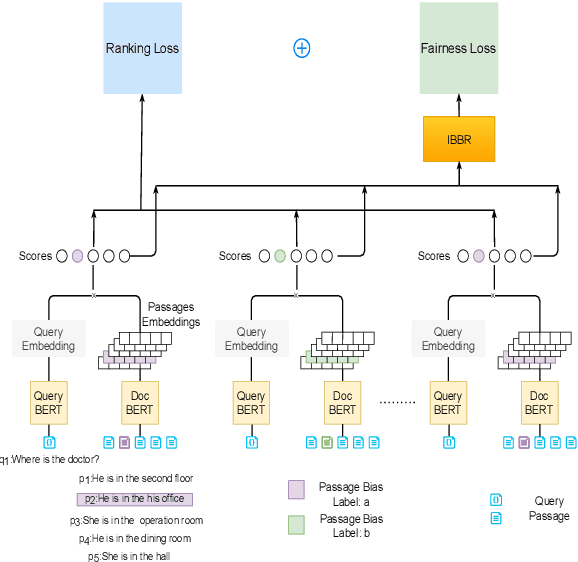
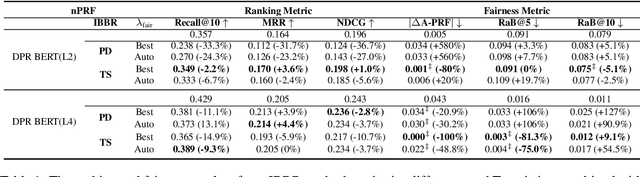
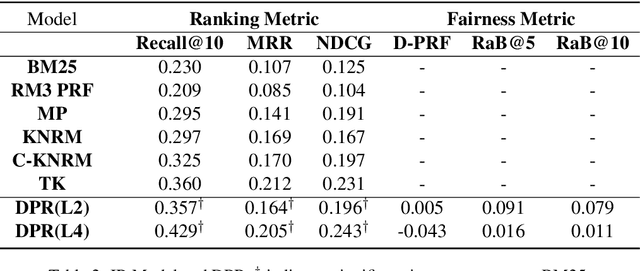
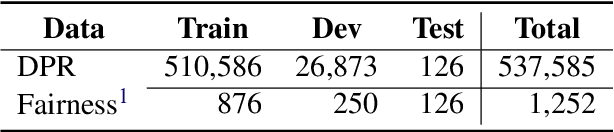
People frequently interact with information retrieval (IR) systems, however, IR models exhibit biases and discrimination towards various demographics. The in-processing fair ranking methods provide a trade-offs between accuracy and fairness through adding a fairness-related regularization term in the loss function. However, there haven't been intuitive objective functions that depend on the click probability and user engagement to directly optimize towards this. In this work, we propose the In-Batch Balancing Regularization (IBBR) to mitigate the ranking disparity among subgroups. In particular, we develop a differentiable \textit{normed Pairwise Ranking Fairness} (nPRF) and leverage the T-statistics on top of nPRF over subgroups as a regularization to improve fairness. Empirical results with the BERT-based neural rankers on the MS MARCO Passage Retrieval dataset with the human-annotated non-gendered queries benchmark \citep{rekabsaz2020neural} show that our IBBR method with nPRF achieves significantly less bias with minimal degradation in ranking performance compared with the baseline.
DQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization
Mar 21, 2022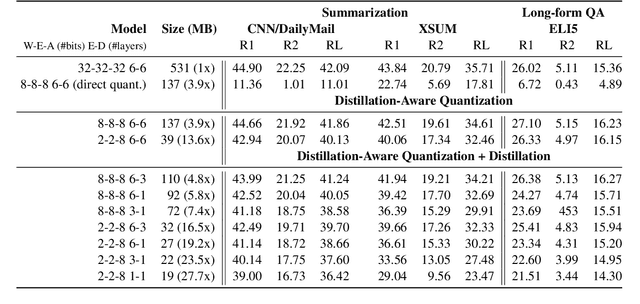
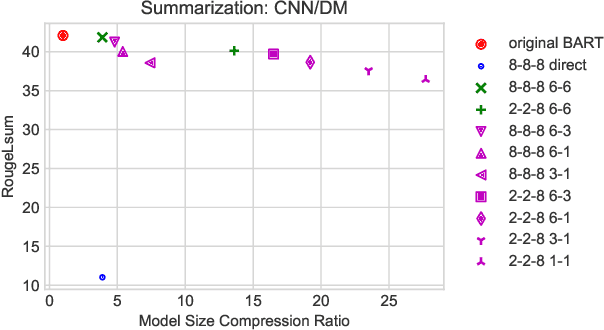
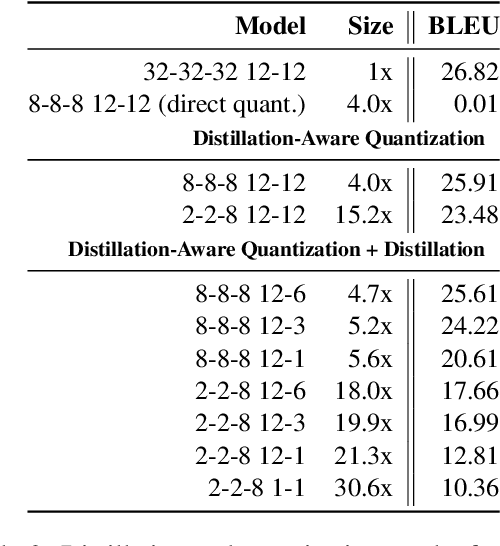
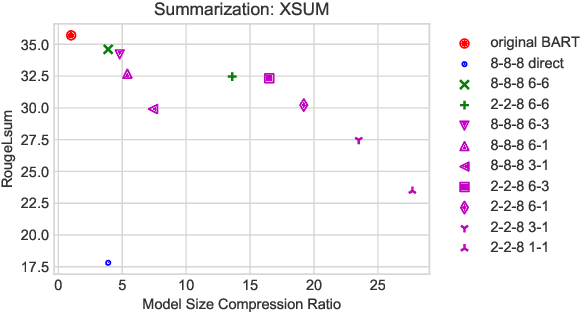
Large-scale pre-trained sequence-to-sequence models like BART and T5 achieve state-of-the-art performance on many generative NLP tasks. However, such models pose a great challenge in resource-constrained scenarios owing to their large memory requirements and high latency. To alleviate this issue, we propose to jointly distill and quantize the model, where knowledge is transferred from the full-precision teacher model to the quantized and distilled low-precision student model. Empirical analyses show that, despite the challenging nature of generative tasks, we were able to achieve a 16.5x model footprint compression ratio with little performance drop relative to the full-precision counterparts on multiple summarization and QA datasets. We further pushed the limit of compression ratio to 27.7x and presented the performance-efficiency trade-off for generative tasks using pre-trained models. To the best of our knowledge, this is the first work aiming to effectively distill and quantize sequence-to-sequence pre-trained models for language generation tasks.
Kronecker Factorization for Preventing Catastrophic Forgetting in Large-scale Medical Entity Linking
Nov 11, 2021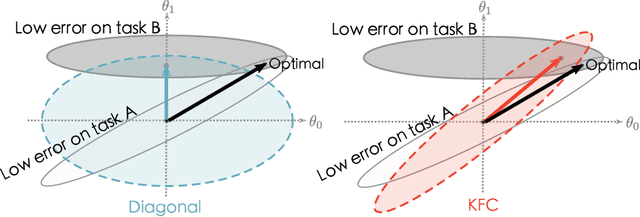
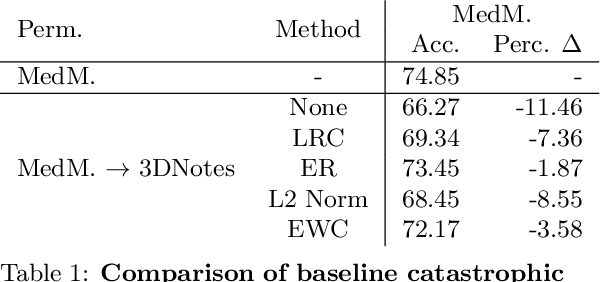

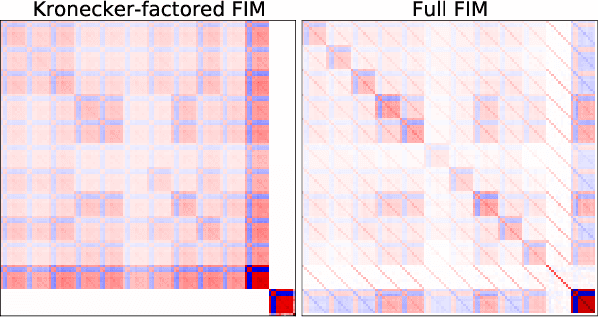
Multi-task learning is useful in NLP because it is often practically desirable to have a single model that works across a range of tasks. In the medical domain, sequential training on tasks may sometimes be the only way to train models, either because access to the original (potentially sensitive) data is no longer available, or simply owing to the computational costs inherent to joint retraining. A major issue inherent to sequential learning, however, is catastrophic forgetting, i.e., a substantial drop in accuracy on prior tasks when a model is updated for a new task. Elastic Weight Consolidation is a recently proposed method to address this issue, but scaling this approach to the modern large models used in practice requires making strong independence assumptions about model parameters, limiting its effectiveness. In this work, we apply Kronecker Factorization--a recent approach that relaxes independence assumptions--to prevent catastrophic forgetting in convolutional and Transformer-based neural networks at scale. We show the effectiveness of this technique on the important and illustrative task of medical entity linking across three datasets, demonstrating the capability of the technique to be used to make efficient updates to existing methods as new medical data becomes available. On average, the proposed method reduces catastrophic forgetting by 51% when using a BERT-based model, compared to a 27% reduction using standard Elastic Weight Consolidation, while maintaining spatial complexity proportional to the number of model parameters.
Knowledge Enhanced Pretrained Language Models: A Compreshensive Survey
Oct 16, 2021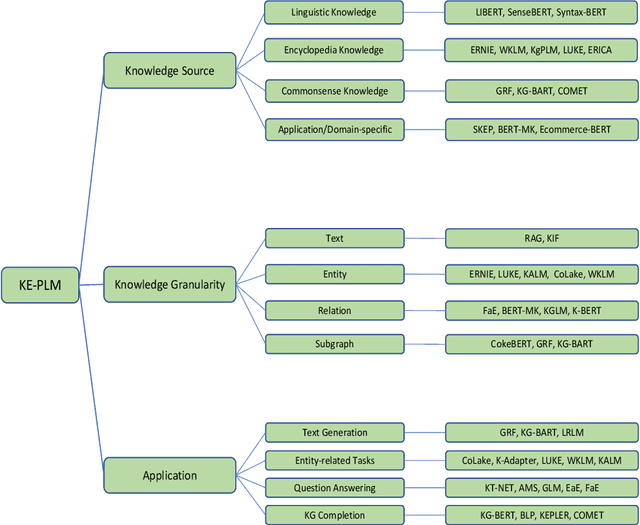

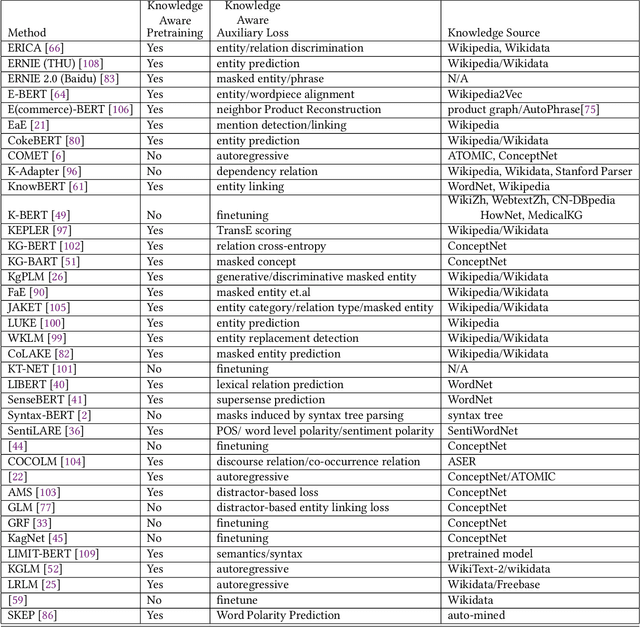
Pretrained Language Models (PLM) have established a new paradigm through learning informative contextualized representations on large-scale text corpus. This new paradigm has revolutionized the entire field of natural language processing, and set the new state-of-the-art performance for a wide variety of NLP tasks. However, though PLMs could store certain knowledge/facts from training corpus, their knowledge awareness is still far from satisfactory. To address this issue, integrating knowledge into PLMs have recently become a very active research area and a variety of approaches have been developed. In this paper, we provide a comprehensive survey of the literature on this emerging and fast-growing field - Knowledge Enhanced Pretrained Language Models (KE-PLMs). We introduce three taxonomies to categorize existing work. Besides, we also survey the various NLU and NLG applications on which KE-PLM has demonstrated superior performance over vanilla PLMs. Finally, we discuss challenges that face KE-PLMs and also promising directions for future research.
Improving Early Sepsis Prediction with Multi Modal Learning
Jul 23, 2021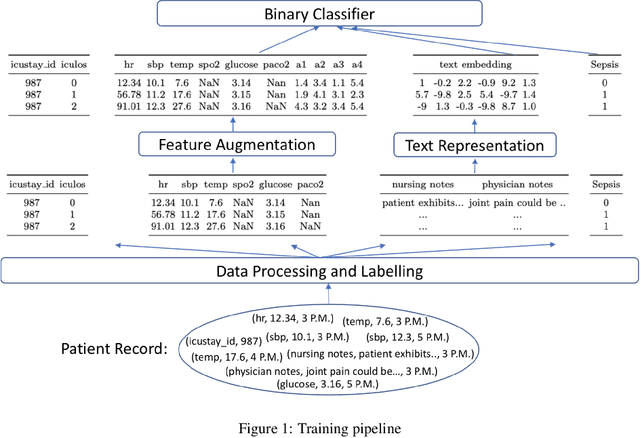
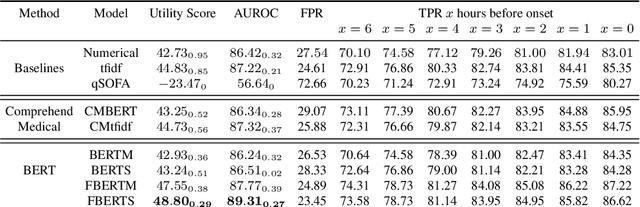
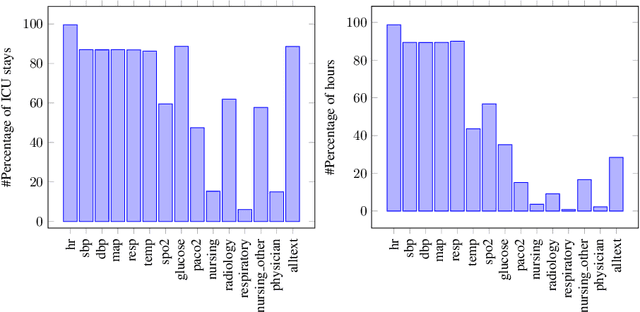
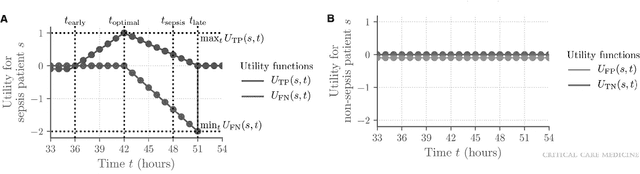
Sepsis is a life-threatening disease with high morbidity, mortality and healthcare costs. The early prediction and administration of antibiotics and intravenous fluids is considered crucial for the treatment of sepsis and can save potentially millions of lives and billions in health care costs. Professional clinical care practitioners have proposed clinical criterion which aid in early detection of sepsis; however, performance of these criterion is often limited. Clinical text provides essential information to estimate the severity of the sepsis in addition to structured clinical data. In this study, we explore how clinical text can complement structured data towards early sepsis prediction task. In this paper, we propose multi modal model which incorporates both structured data in the form of patient measurements as well as textual notes on the patient. We employ state-of-the-art NLP models such as BERT and a highly specialized NLP model in Amazon Comprehend Medical to represent the text. On the MIMIC-III dataset containing records of ICU admissions, we show that by using these notes, one achieves an improvement of 6.07 points in a standard utility score for Sepsis prediction and 2.89% in AUROC score. Our methods significantly outperforms a clinical criteria suggested by experts, qSOFA, as well as the winning model of the PhysioNet Computing in Cardiology Challenge for predicting Sepsis.
Neural Entity Recognition with Gazetteer based Fusion
May 27, 2021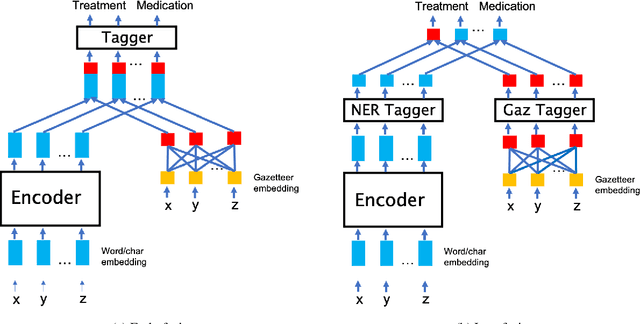
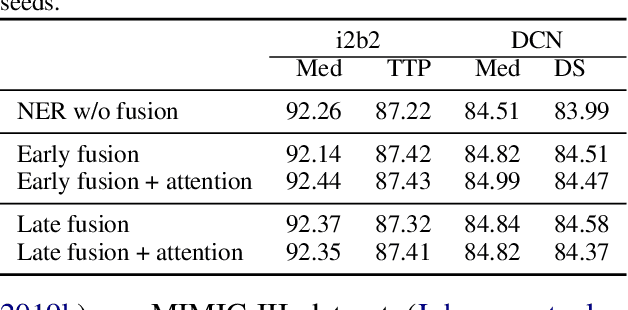
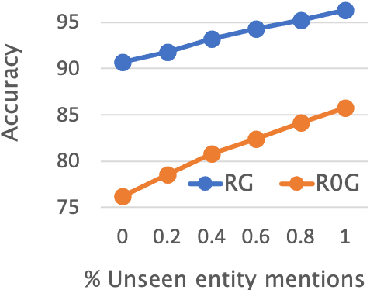
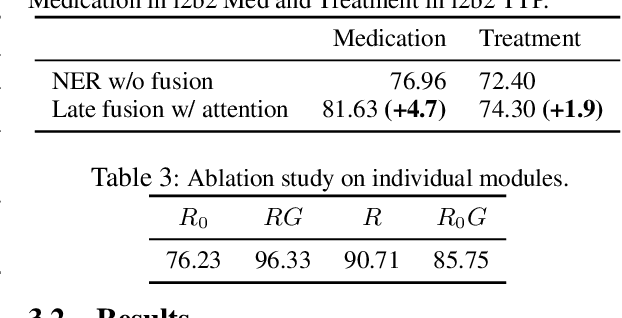
Incorporating external knowledge into Named Entity Recognition (NER) systems has been widely studied in the generic domain. In this paper, we focus on clinical domain where only limited data is accessible and interpretability is important. Recent advancement in technology and the acceleration of clinical trials has resulted in the discovery of new drugs, procedures as well as medical conditions. These factors motivate towards building robust zero-shot NER systems which can quickly adapt to new medical terminology. We propose an auxiliary gazetteer model and fuse it with an NER system, which results in better robustness and interpretability across different clinical datasets. Our gazetteer based fusion model is data efficient, achieving +1.7 micro-F1 gains on the i2b2 dataset using 20% training data, and brings + 4.7 micro-F1 gains on novel entity mentions never presented during training. Moreover, our fusion model is able to quickly adapt to new mentions in gazetteers without re-training and the gains from the proposed fusion model are transferable to related datasets.
Zero-shot Medical Entity Retrieval without Annotation: Learning From Rich Knowledge Graph Semantics
May 26, 2021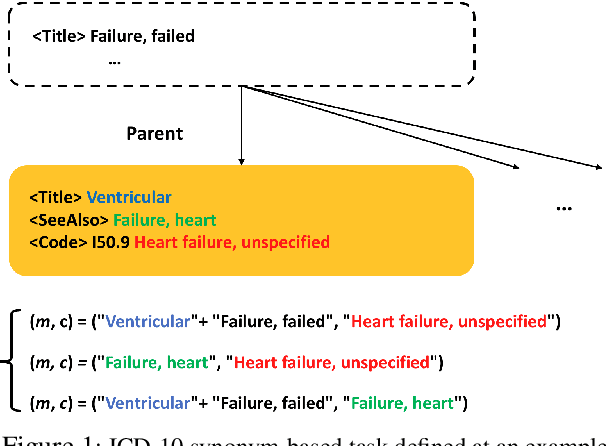
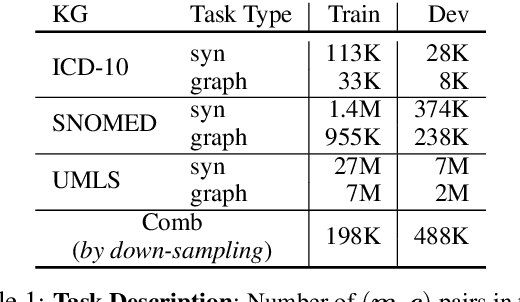
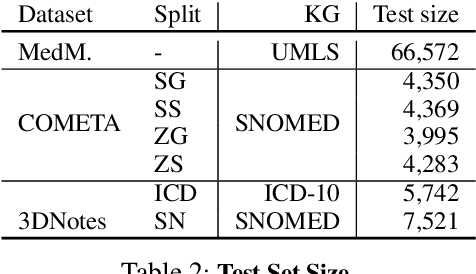
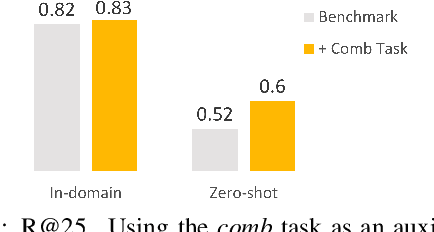
Medical entity retrieval is an integral component for understanding and communicating information across various health systems. Current approaches tend to work well on specific medical domains but generalize poorly to unseen sub-specialties. This is of increasing concern under a public health crisis as new medical conditions and drug treatments come to light frequently. Zero-shot retrieval is challenging due to the high degree of ambiguity and variability in medical corpora, making it difficult to build an accurate similarity measure between mentions and concepts. Medical knowledge graphs (KG), however, contain rich semantics including large numbers of synonyms as well as its curated graphical structures. To take advantage of this valuable information, we propose a suite of learning tasks designed for training efficient zero-shot entity retrieval models. Without requiring any human annotation, our knowledge graph enriched architecture significantly outperforms common zero-shot benchmarks including BM25 and Clinical BERT with 7% to 30% higher recall across multiple major medical ontologies, such as UMLS, SNOMED, and ICD-10.