 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Is Missing in IRM Training and Evaluation? Challenges and Solutions
Mar 04, 2023



Invariant risk minimization (IRM) has received increasing attention as a way to acquire environment-agnostic data representations and predictions, and as a principled solution for preventing spurious correlations from being learned and for improving models' out-of-distribution generalization. Yet, recent works have found that the optimality of the originally-proposed IRM optimization (IRM) may be compromised in practice or could be impossible to achieve in some scenarios. Therefore, a series of advanced IRM algorithms have been developed that show practical improvement over IRM. In this work, we revisit these recent IRM advancements, and identify and resolve three practical limitations in IRM training and evaluation. First, we find that the effect of batch size during training has been chronically overlooked in previous studies, leaving room for further improvement. We propose small-batch training and highlight the improvements over a set of large-batch optimization techniques. Second, we find that improper selection of evaluation environments could give a false sense of invariance for IRM. To alleviate this effect, we leverage diversified test-time environments to precisely characterize the invariance of IRM when applied in practice. Third, we revisit (Ahuja et al. (2020))'s proposal to convert IRM into an ensemble game and identify a limitation when a single invariant predictor is desired instead of an ensemble of individual predictors. We propose a new IRM variant to address this limitation based on a novel viewpoint of ensemble IRM games as consensus-constrained bi-level optimization. Lastly, we conduct extensive experiments (covering 7 existing IRM variants and 7 datasets) to justify the practical significance of revisiting IRM training and evaluation in a principled manner.
Toward Theoretical Guidance for Two Common Questions in Practical Cross-Validation based Hyperparameter Selection
Jan 12, 2023



We show, to our knowledge, the first theoretical treatments of two common questions in cross-validation based hyperparameter selection: (1) After selecting the best hyperparameter using a held-out set, we train the final model using {\em all} of the training data -- since this may or may not improve future generalization error, should one do this? (2) During optimization such as via SGD (stochastic gradient descent), we must set the optimization tolerance $\rho$ -- since it trades off predictive accuracy with computation cost, how should one set it? Toward these problems, we introduce the {\em hold-in risk} (the error due to not using the whole training data), and the {\em model class mis-specification risk} (the error due to having chosen the wrong model class) in a theoretical view which is simple, general, and suggests heuristics that can be used when faced with a dataset instance. In proof-of-concept studies in synthetic data where theoretical quantities can be controlled, we show that these heuristics can, respectively, (1) always perform at least as well as always performing retraining or never performing retraining, (2) either improve performance or reduce computational overhead by $2\times$ with no loss in predictive performance.
Advancing Model Pruning via Bi-level Optimization
Oct 12, 2022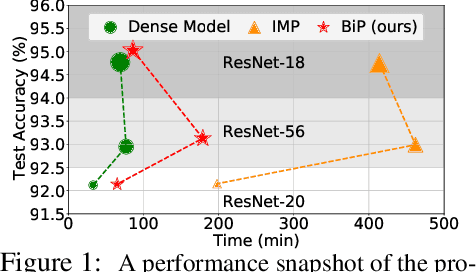
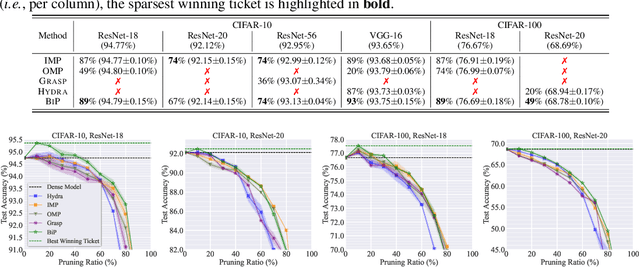
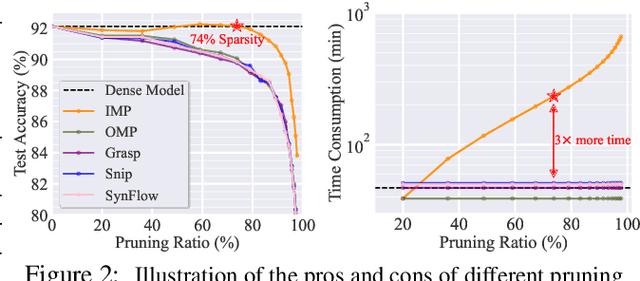
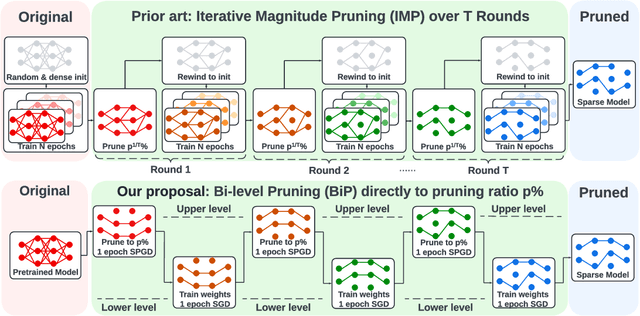
The deployment constraints in practical applications necessitate the pruning of large-scale deep learning models, i.e., promoting their weight sparsity. As illustrated by the Lottery Ticket Hypothesis (LTH), pruning also has the potential of improving their generalization ability. At the core of LTH, iterative magnitude pruning (IMP) is the predominant pruning method to successfully find 'winning tickets'. Yet, the computation cost of IMP grows prohibitively as the targeted pruning ratio increases. To reduce the computation overhead, various efficient 'one-shot' pruning methods have been developed, but these schemes are usually unable to find winning tickets as good as IMP. This raises the question of how to close the gap between pruning accuracy and pruning efficiency? To tackle it, we pursue the algorithmic advancement of model pruning. Specifically, we formulate the pruning problem from a fresh and novel viewpoint, bi-level optimization (BLO). We show that the BLO interpretation provides a technically-grounded optimization base for an efficient implementation of the pruning-retraining learning paradigm used in IMP. We also show that the proposed bi-level optimization-oriented pruning method (termed BiP) is a special class of BLO problems with a bi-linear problem structure. By leveraging such bi-linearity, we theoretically show that BiP can be solved as easily as first-order optimization, thus inheriting the computation efficiency. Through extensive experiments on both structured and unstructured pruning with 5 model architectures and 4 data sets, we demonstrate that BiP can find better winning tickets than IMP in most cases, and is computationally as efficient as the one-shot pruning schemes, demonstrating 2-7 times speedup over IMP for the same level of model accuracy and sparsity.
Navigating Ensemble Configurations for Algorithmic Fairness
Oct 11, 2022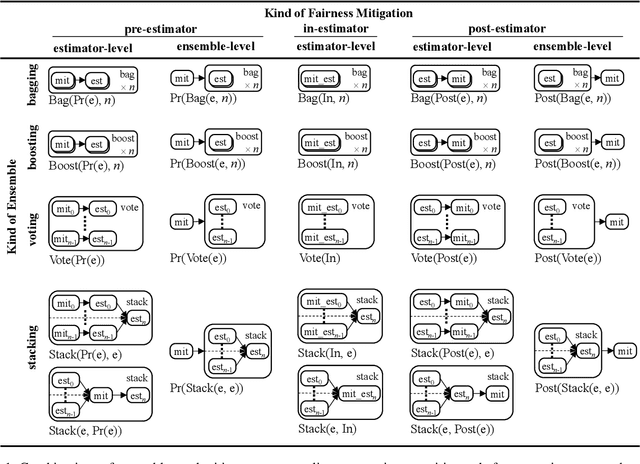
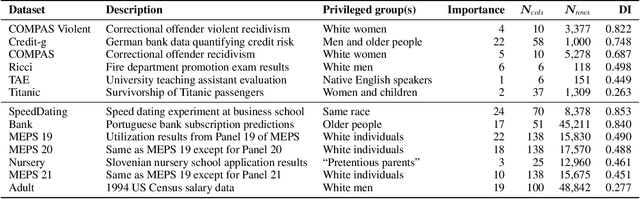

Bias mitigators can improve algorithmic fairness in machine learning models, but their effect on fairness is often not stable across data splits. A popular approach to train more stable models is ensemble learning, but unfortunately, it is unclear how to combine ensembles with mitigators to best navigate trade-offs between fairness and predictive performance. To that end, we built an open-source library enabling the modular composition of 8 mitigators, 4 ensembles, and their corresponding hyperparameters, and we empirically explored the space of configurations on 13 datasets. We distilled our insights from this exploration in the form of a guidance diagram for practitioners that we demonstrate is robust and reproducible.
Min-Max Bilevel Multi-objective Optimization with Applications in Machine Learning
Mar 03, 2022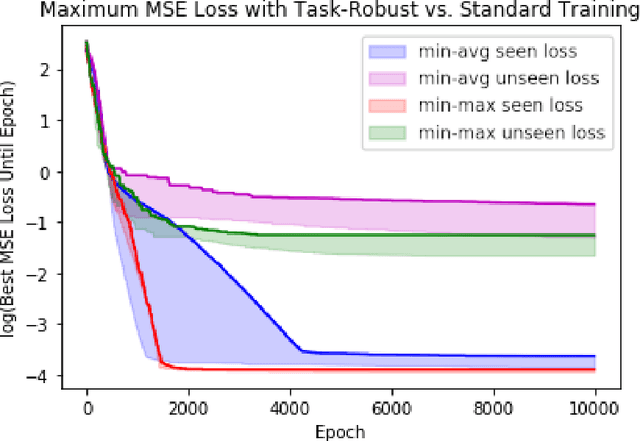
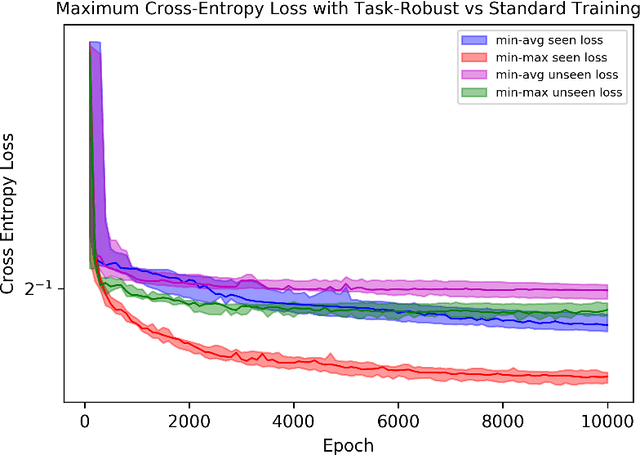
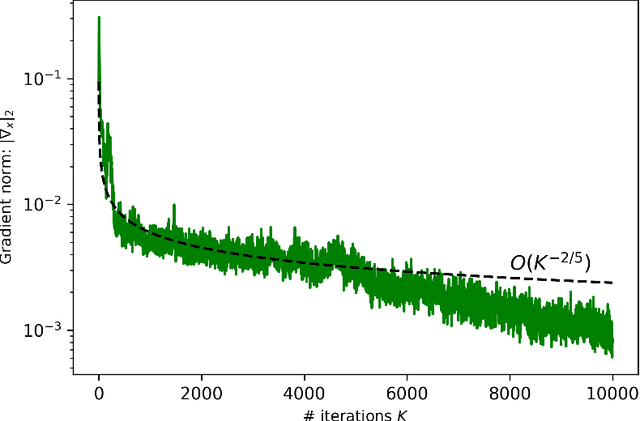
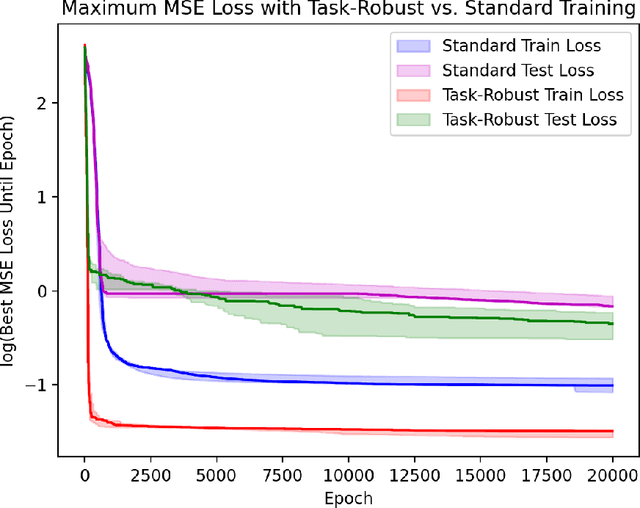
This paper is the first to propose a generic min-max bilevel multi-objective optimization framework, highlighting applications in representation learning and hyperparameter optimization. In many machine learning applications such as meta-learning, multi-task learning, and representation learning, a subset of the parameters are shared by all the tasks, while each specific task has its own set of additional parameters. By leveraging the recent advances of nonconvex min-max optimization, we propose a gradient descent-ascent bilevel optimization (MORBiT) algorithm which is able to extract a set of shared parameters that is robust over all tasks and further overcomes the distributional shift between training and testing tasks. Theoretical analyses show that MORBiT converges to the first-order stationary point at a rate of $\mathcal{O}(\sqrt{n}K^{-2/5})$ for a class of nonconvex problems, where $K$ denotes the total number of iterations and $n$ denotes the number of tasks. Overall, we formulate a min-max bilevel multi-objective optimization problem, provide a single loop two-timescale algorithm with convergence rate guarantees, and show theoretical bounds on the generalization abilities of the optimizer. Experimental results on sinusoid regression and representation learning showcase the superiority of MORBiT over state-of-the-art methods, validating our convergence and generalization results.
Single-shot Hyper-parameter Optimization for Federated Learning: A General Algorithm & Analysis
Feb 16, 2022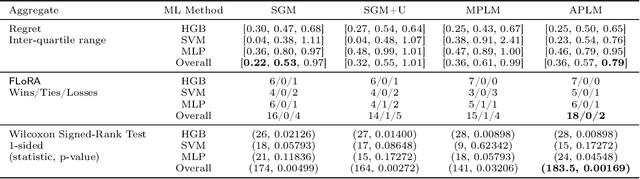
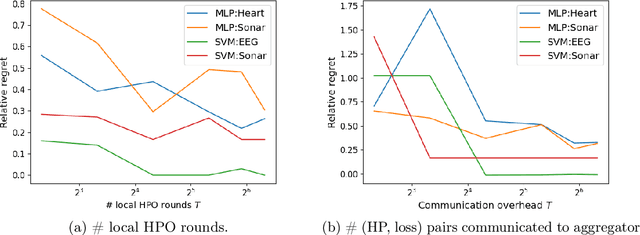
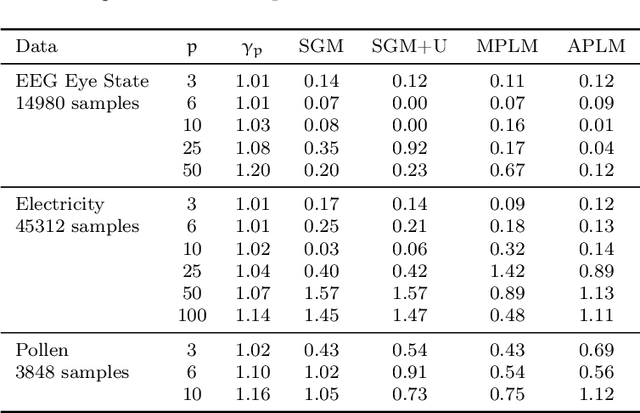

We address the relatively unexplored problem of hyper-parameter optimization (HPO) for federated learning (FL-HPO). We introduce Federated Loss SuRface Aggregation (FLoRA), a general FL-HPO solution framework that can address use cases of tabular data and any Machine Learning (ML) model including gradient boosting training algorithms and therefore further expands the scope of FL-HPO. FLoRA enables single-shot FL-HPO: identifying a single set of good hyper-parameters that are subsequently used in a single FL training. Thus, it enables FL-HPO solutions with minimal additional communication overhead compared to FL training without HPO. We theoretically characterize the optimality gap of FL-HPO, which explicitly accounts for the heterogeneous non-IID nature of the parties' local data distributions, a dominant characteristic of FL systems. Our empirical evaluation of FLoRA for multiple ML algorithms on seven OpenML datasets demonstrates significant model accuracy improvements over the considered baseline, and robustness to increasing number of parties involved in FL-HPO training.
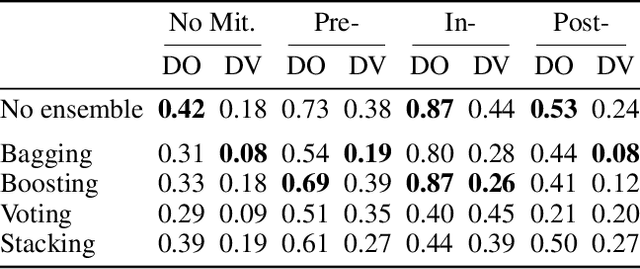
An Empirical Study of Modular Bias Mitigators and Ensembles
Feb 01, 2022
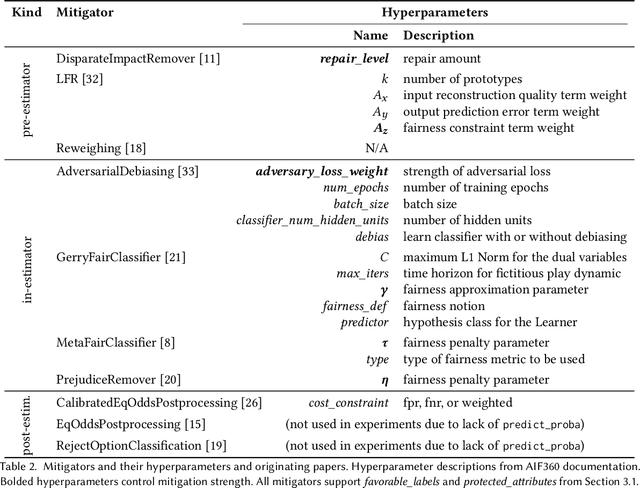

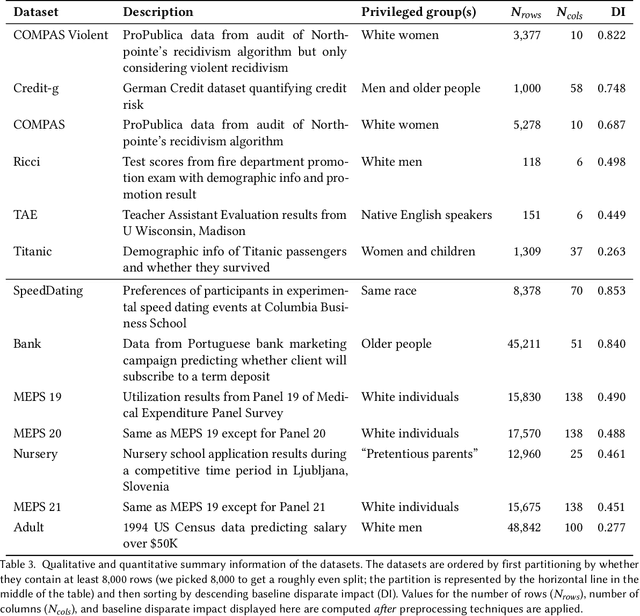
There are several bias mitigators that can reduce algorithmic bias in machine learning models but, unfortunately, the effect of mitigators on fairness is often not stable when measured across different data splits. A popular approach to train more stable models is ensemble learning. Ensembles, such as bagging, boosting, voting, or stacking, have been successful at making predictive performance more stable. One might therefore ask whether we can combine the advantages of bias mitigators and ensembles? To explore this question, we first need bias mitigators and ensembles to work together. We built an open-source library enabling the modular composition of 10 mitigators, 4 ensembles, and their corresponding hyperparameters. Based on this library, we empirically explored the space of combinations on 13 datasets, including datasets commonly used in fairness literature plus datasets newly curated by our library. Furthermore, we distilled the results into a guidance diagram for practitioners. We hope this paper will contribute towards improving stability in bias mitigation.
FLoRA: Single-shot Hyper-parameter Optimization for Federated Learning
Dec 15, 2021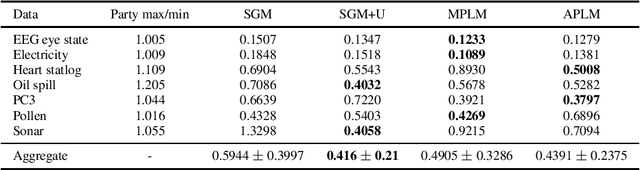
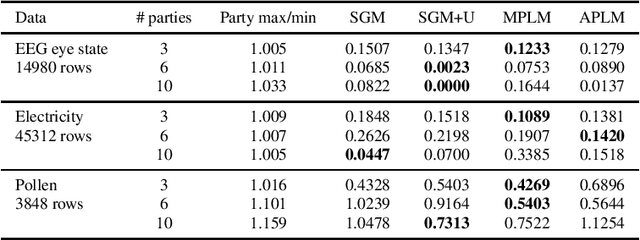

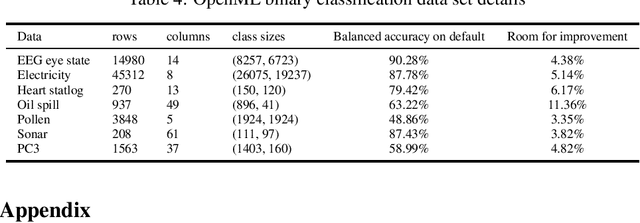
We address the relatively unexplored problem of hyper-parameter optimization (HPO) for federated learning (FL-HPO). We introduce Federated Loss suRface Aggregation (FLoRA), the first FL-HPO solution framework that can address use cases of tabular data and gradient boosting training algorithms in addition to stochastic gradient descent/neural networks commonly addressed in the FL literature. The framework enables single-shot FL-HPO, by first identifying a good set of hyper-parameters that are used in a **single** FL training. Thus, it enables FL-HPO solutions with minimal additional communication overhead compared to FL training without HPO. Our empirical evaluation of FLoRA for Gradient Boosted Decision Trees on seven OpenML data sets demonstrates significant model accuracy improvements over the considered baseline, and robustness to increasing number of parties involved in FL-HPO training.
Federated Nearest Neighbor Classification with a Colony of Fruit-Flies: With Supplement
Dec 14, 2021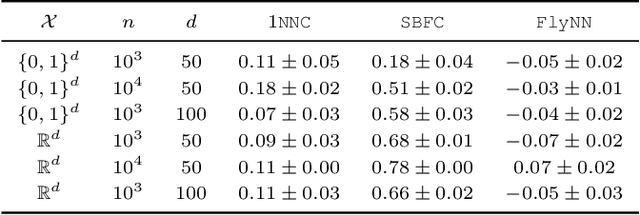
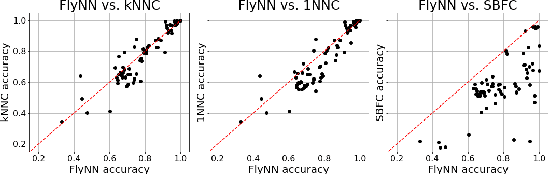
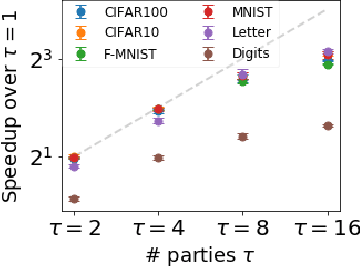
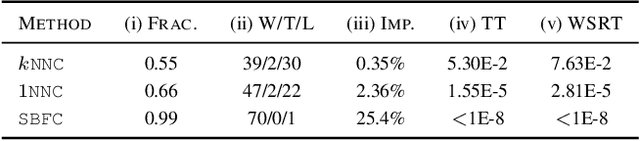
The mathematical formalization of a neurological mechanism in the olfactory circuit of a fruit-fly as a locality sensitive hash (Flyhash) and bloom filter (FBF) has been recently proposed and "reprogrammed" for various machine learning tasks such as similarity search, outlier detection and text embeddings. We propose a novel reprogramming of this hash and bloom filter to emulate the canonical nearest neighbor classifier (NNC) in the challenging Federated Learning (FL) setup where training and test data are spread across parties and no data can leave their respective parties. Specifically, we utilize Flyhash and FBF to create the FlyNN classifier, and theoretically establish conditions where FlyNN matches NNC. We show how FlyNN is trained exactly in a FL setup with low communication overhead to produce FlyNNFL, and how it can be differentially private. Empirically, we demonstrate that (i) FlyNN matches NNC accuracy across 70 OpenML datasets, (ii) FlyNNFL training is highly scalable with low communication overhead, providing up to $8\times$ speedup with $16$ parties.
Sign-MAML: Efficient Model-Agnostic Meta-Learning by SignSGD
Sep 15, 2021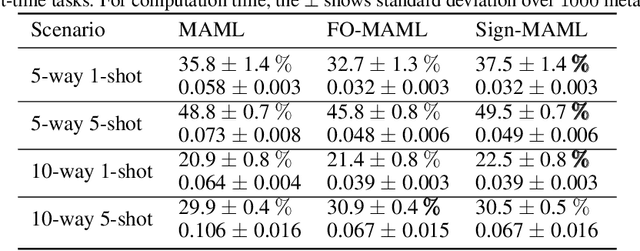
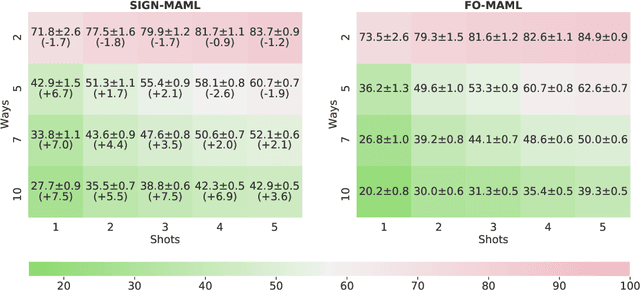
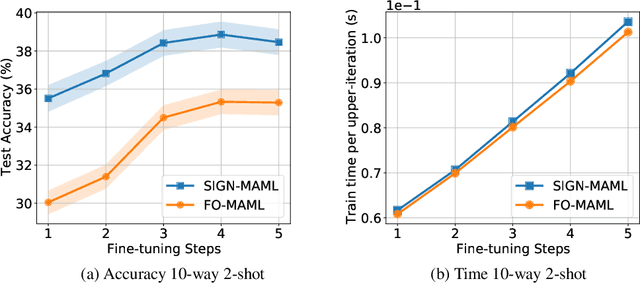
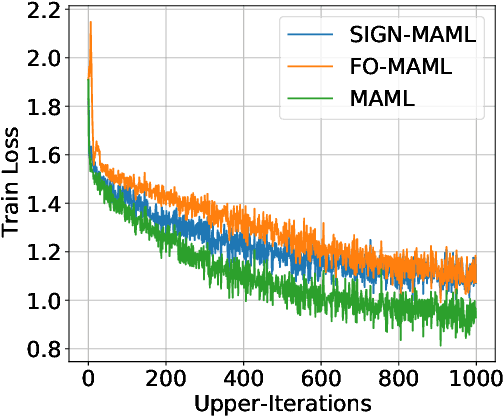
We propose a new computationally-efficient first-order algorithm for Model-Agnostic Meta-Learning (MAML). The key enabling technique is to interpret MAML as a bilevel optimization (BLO) problem and leverage the sign-based SGD(signSGD) as a lower-level optimizer of BLO. We show that MAML, through the lens of signSGD-oriented BLO, naturally yields an alternating optimization scheme that just requires first-order gradients of a learned meta-model. We term the resulting MAML algorithm Sign-MAML. Compared to the conventional first-order MAML (FO-MAML) algorithm, Sign-MAML is theoretically-grounded as it does not impose any assumption on the absence of second-order derivatives during meta training. In practice, we show that Sign-MAML outperforms FO-MAML in various few-shot image classification tasks, and compared to MAML, it achieves a much more graceful tradeoff between classification accuracy and computation efficiency.