 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Plan to Action: How Well Do Agents Follow the Plan?
Apr 13, 2026Agents aspire to eliminate the need for task-specific prompt crafting through autonomous reason-act-observe loops. Still, they are commonly instructed to follow a task-specific plan for guidance, e.g., to resolve software issues following phases for navigation, reproduction, patch, and validation. Unfortunately, it is unknown to what extent agents actually follow such instructed plans. Without such an analysis, determining the extent agents comply with a given plan, it is impossible to assess whether a solution was reached through correct strategic reasoning or through other means, e.g., data contamination or overfitting to a benchmark. This paper presents the first extensive, systematic analysis of plan compliance in programming agents, examining 16,991 trajectories from SWE-agent across four LLMs on SWE-bench Verified and SWE-bench Pro under eight plan variations. Without an explicit plan, agents fall back on workflows internalized during training, which are often incomplete, overfit, or inconsistently applied. Providing the standard plan improves issue resolution, and we observe that periodic plan reminders can mitigate plan violations and improve task success. A subpar plan hurts performance even more than no plan at all. Surprisingly, augmenting a plan with additional task-relevant phases in the early stage can degrade performance, particularly when these phases do not align with the model's internal problem-solving strategy. These findings highlight a research gap: fine-tuning paradigms that teach models to follow instructed plans, rather than encoding task-specific plans in them. This requires teaching models to reason and act adaptively, rather than memorizing workflows.
Resolving Java Code Repository Issues with iSWE Agent
Mar 11, 2026Resolving issues on code repositories is an important part of software engineering. Various recent systems automatically resolve issues using large language models and agents, often with impressive performance. Unfortunately, most of these models and agents focus primarily on Python, and their performance on other programming languages is lower. In particular, a lot of enterprise software is written in Java, yet automated issue resolution for Java is under-explored. This paper introduces iSWE Agent, an automated issue resolver with an emphasis on Java. It consists of two sub-agents, one for localization and the other for editing. Both have access to novel tools based on rule-based Java static analysis and transformation. Using this approach, iSWE achieves state-of-the-art issue resolution rates across the Java splits of both Multi-SWE-bench and SWE-PolyBench. More generally, we hope that by combining the best of rule-based and model-based techniques, this paper contributes towards improving enterprise software development.
Representing Prompting Patterns with PDL: Compliance Agent Case Study
Jul 08, 2025Prompt engineering for LLMs remains complex, with existing frameworks either hiding complexity behind restrictive APIs or providing inflexible canned patterns that resist customization -- making sophisticated agentic programming challenging. We present the Prompt Declaration Language (PDL), a novel approach to prompt representation that tackles this fundamental complexity by bringing prompts to the forefront, enabling manual and automatic prompt tuning while capturing the composition of LLM calls together with rule-based code and external tools. By abstracting away the plumbing for such compositions, PDL aims at improving programmer productivity while providing a declarative representation that is amenable to optimization. This paper demonstrates PDL's utility through a real-world case study of a compliance agent. Tuning the prompting pattern of this agent yielded up to 4x performance improvement compared to using a canned agent and prompt pattern.
AutoPDL: Automatic Prompt Optimization for LLM Agents
Apr 06, 2025



The performance of large language models (LLMs) depends on how they are prompted, with choices spanning both the high-level prompting pattern (e.g., Zero-Shot, CoT, ReAct, ReWOO) and the specific prompt content (instructions and few-shot demonstrations). Manually tuning this combination is tedious, error-prone, and non-transferable across LLMs or tasks. Therefore, this paper proposes AutoPDL, an automated approach to discover good LLM agent configurations. Our method frames this as a structured AutoML problem over a combinatorial space of agentic and non-agentic prompting patterns and demonstrations, using successive halving to efficiently navigate this space. We introduce a library implementing common prompting patterns using the PDL prompt programming language. AutoPDL solutions are human-readable, editable, and executable PDL programs that use this library. This approach also enables source-to-source optimization, allowing human-in-the-loop refinement and reuse. Evaluations across three tasks and six LLMs (ranging from 8B to 70B parameters) show consistent accuracy gains ($9.5\pm17.5$ percentage points), up to 68.9pp, and reveal that selected prompting strategies vary across models and tasks.
Otter: Generating Tests from Issues to Validate SWE Patches
Feb 07, 2025While there has been plenty of work on generating tests from existing code, there has been limited work on generating tests from issues. A correct test must validate the code patch that resolves the issue. In this work, we focus on the scenario where the code patch does not exist yet. This approach supports two major use-cases. First, it supports TDD (test-driven development), the discipline of "test first, write code later" that has well-documented benefits for human software engineers. Second, it also validates SWE (software engineering) agents, which generate code patches for resolving issues. This paper introduces Otter, an LLM-based solution for generating tests from issues. Otter augments LLMs with rule-based analysis to check and repair their outputs, and introduces a novel self-reflective action planning stage. Experiments show Otter outperforming state-of-the-art systems for generating tests from issues, in addition to enhancing systems that generate patches from issues. We hope that Otter helps make developers more productive at resolving issues and leads to more robust, well-tested code.
TDD-Bench Verified: Can LLMs Generate Tests for Issues Before They Get Resolved?
Dec 03, 2024



Test-driven development (TDD) is the practice of writing tests first and coding later, and the proponents of TDD expound its numerous benefits. For instance, given an issue on a source code repository, tests can clarify the desired behavior among stake-holders before anyone writes code for the agreed-upon fix. Although there has been a lot of work on automated test generation for the practice "write code first, test later", there has been little such automation for TDD. Ideally, tests for TDD should be fail-to-pass (i.e., fail before the issue is resolved and pass after) and have good adequacy with respect to covering the code changed during issue resolution. This paper introduces TDD-Bench Verified, a high-quality benchmark suite of 449 issues mined from real-world GitHub code repositories. The benchmark's evaluation harness runs only relevant tests in isolation for simple yet accurate coverage measurements, and the benchmark's dataset is filtered both by human judges and by execution in the harness. This paper also presents Auto-TDD, an LLM-based solution that takes as input an issue description and a codebase (prior to issue resolution) and returns as output a test that can be used to validate the changes made for resolving the issue. Our evaluation shows that Auto-TDD yields a better fail-to-pass rate than the strongest prior work while also yielding high coverage adequacy. Overall, we hope that this work helps make developers more productive at resolving issues while simultaneously leading to more robust fixes.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024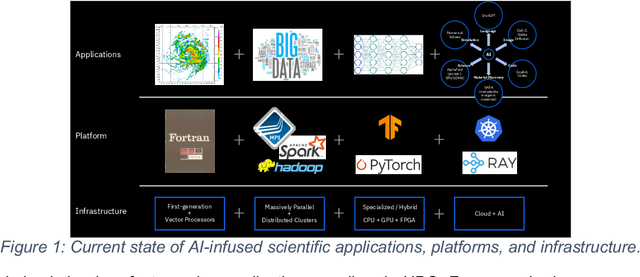
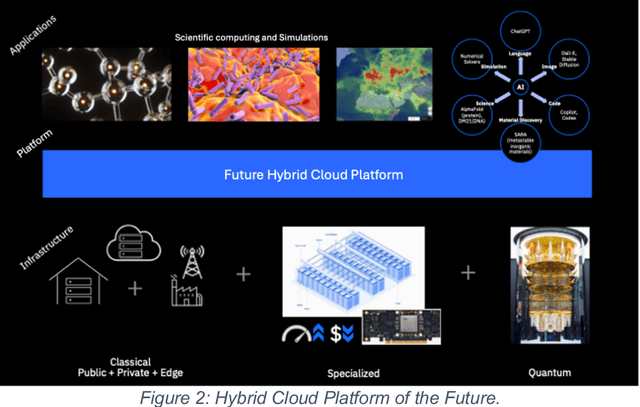
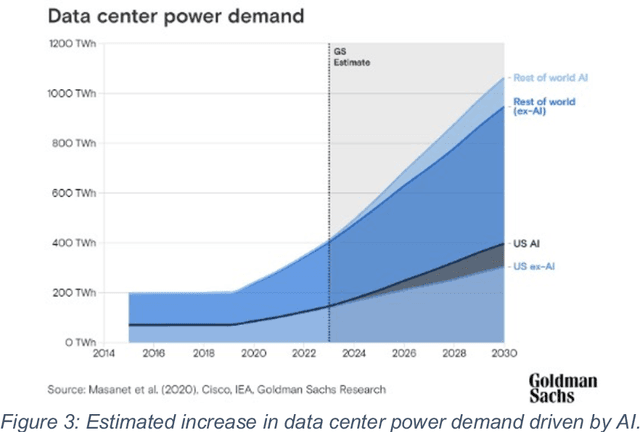
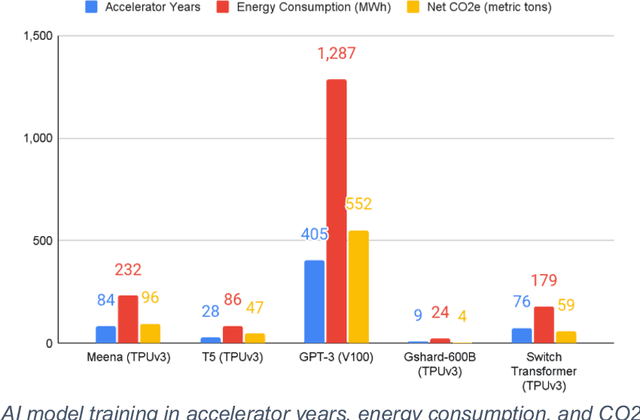
This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
PDL: A Declarative Prompt Programming Language
Oct 24, 2024



Large language models (LLMs) have taken the world by storm by making many previously difficult uses of AI feasible. LLMs are controlled via highly expressive textual prompts and return textual answers. Unfortunately, this unstructured text as input and output makes LLM-based applications brittle. This motivates the rise of prompting frameworks, which mediate between LLMs and the external world. However, existing prompting frameworks either have a high learning curve or take away control over the exact prompts from the developer. To overcome this dilemma, this paper introduces the Prompt Declaration Language (PDL). PDL is a simple declarative data-oriented language that puts prompts at the forefront, based on YAML. PDL works well with many LLM platforms and LLMs. It supports writing interactive applications that call LLMs and tools, and makes it easy to implement common use-cases such as chatbots, RAG, or agents. We hope PDL will make prompt programming simpler, less brittle, and more enjoyable.
Learning Transfers over Several Programming Languages
Oct 25, 2023



Large language models (LLMs) have recently become remarkably good at improving developer productivity for high-resource programming languages. These models use two kinds of data: large amounts of unlabeled code samples for pretraining and relatively smaller amounts of labeled code samples for fine-tuning or in-context learning. Unfortunately, many programming languages are low-resource, lacking labeled samples for most tasks and often even lacking unlabeled samples. Therefore, users of low-resource languages (e.g., legacy or new languages) miss out on the benefits of LLMs. Cross-lingual transfer learning uses data from a source language to improve model performance on a target language. It has been well-studied for natural languages, but has received little attention for programming languages. This paper reports extensive experiments on four tasks using a transformer-based LLM and 11 to 41 programming languages to explore the following questions. First, how well cross-lingual transfer works for a given task across different language pairs. Second, given a task and target language, how to best choose a source language. Third, the characteristics of a language pair that are predictive of transfer performance, and fourth, how that depends on the given task.
A Suite of Fairness Datasets for Tabular Classification
Jul 31, 2023



There have been many papers with algorithms for improving fairness of machine-learning classifiers for tabular data. Unfortunately, most use only very few datasets for their experimental evaluation. We introduce a suite of functions for fetching 20 fairness datasets and providing associated fairness metadata. Hopefully, these will lead to more rigorous experimental evaluations in future fairness-aware machine learning research.