 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutnam 2025 Problems in Rocq using Opus 4.6 and Rocq-MCP
Mar 20, 2026We report on an experiment in which Claude Opus~4.6, equipped with a suite of Model Context Protocol (MCP) tools for the Rocq proof assistant, autonomously proved 10 of 12 problems from the 2025 Putnam Mathematical Competition. The MCP tools, designed with Claude by analyzing logs from a prior experiment on miniF2F-Rocq, encode a "compile-first, interactive-fallback" strategy. Running on an isolated VM with no internet access, the agent deployed 141 subagents over 17.7 hours of active compute (51.6h wall-clock), consuming approximately 1.9 billion tokens. All proofs are publicly available.
Inference Plans for Hybrid Particle Filtering
Aug 21, 2024



Advanced probabilistic programming languages (PPLs) use hybrid inference systems to combine symbolic exact inference and Monte Carlo methods to improve inference performance. These systems use heuristics to partition random variables within the program into variables that are encoded symbolically and variables that are encoded with sampled values, and the heuristics are not necessarily aligned with the performance evaluation metrics used by the developer. In this work, we present inference plans, a programming interface that enables developers to control the partitioning of random variables during hybrid particle filtering. We further present Siren, a new PPL that enables developers to use annotations to specify inference plans the inference system must implement. To assist developers with statically reasoning about whether an inference plan can be implemented, we present an abstract-interpretation-based static analysis for Siren for determining inference plan satisfiability. We prove the analysis is sound with respect to Siren's semantics. Our evaluation applies inference plans to three different hybrid particle filtering algorithms on a suite of benchmarks and shows that the control provided by inference plans enables speed ups of 1.76x on average and up to 206x to reach target accuracy, compared to the inference plans implemented by default heuristics; the results also show that inference plans improve accuracy by 1.83x on average and up to 595x with less or equal runtime, compared to the default inference plans. We further show that the static analysis is precise in practice, identifying all satisfiable inference plans in 27 out of the 33 benchmark-algorithm combinations.
Automatic Rao-Blackwellization for Sequential Monte Carlo with Belief Propagation
Dec 15, 2023


Exact Bayesian inference on state-space models~(SSM) is in general untractable, and unfortunately, basic Sequential Monte Carlo~(SMC) methods do not yield correct approximations for complex models. In this paper, we propose a mixed inference algorithm that computes closed-form solutions using belief propagation as much as possible, and falls back to sampling-based SMC methods when exact computations fail. This algorithm thus implements automatic Rao-Blackwellization and is even exact for Gaussian tree models.
Learning GraphQL Query Costs (Extended Version)
Aug 26, 2021
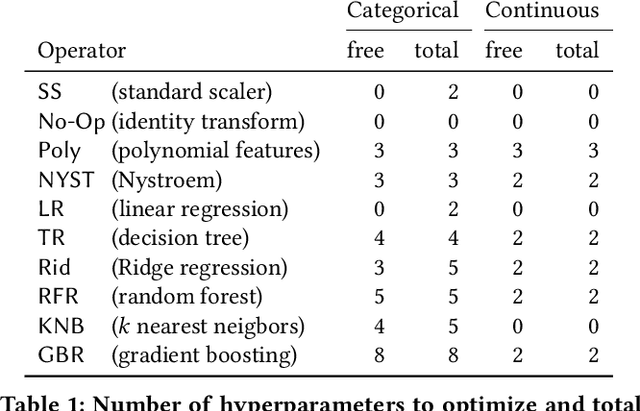
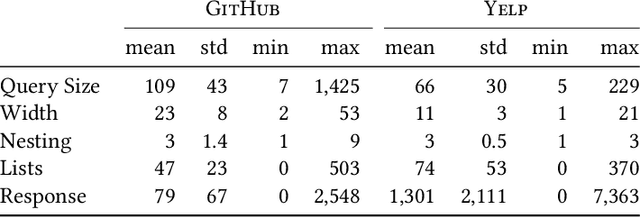

GraphQL is a query language for APIs and a runtime for executing those queries, fetching the requested data from existing microservices, REST APIs, databases, or other sources. Its expressiveness and its flexibility have made it an attractive candidate for API providers in many industries, especially through the web. A major drawback to blindly servicing a client's query in GraphQL is that the cost of a query can be unexpectedly large, creating computation and resource overload for the provider, and API rate-limit overages and infrastructure overload for the client. To mitigate these drawbacks, it is necessary to efficiently estimate the cost of a query before executing it. Estimating query cost is challenging, because GraphQL queries have a nested structure, GraphQL APIs follow different design conventions, and the underlying data sources are hidden. Estimates based on worst-case static query analysis have had limited success because they tend to grossly overestimate cost. We propose a machine-learning approach to efficiently and accurately estimate the query cost. We also demonstrate the power of this approach by testing it on query-response data from publicly available commercial APIs. Our framework is efficient and predicts query costs with high accuracy, consistently outperforming the static analysis by a large margin.
Lale: Consistent Automated Machine Learning
Jul 04, 2020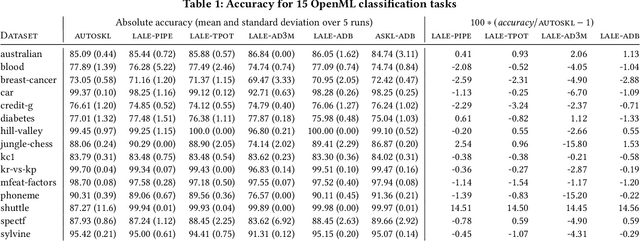
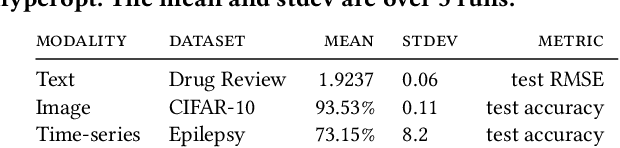

Automated machine learning makes it easier for data scientists to develop pipelines by searching over possible choices for hyperparameters, algorithms, and even pipeline topologies. Unfortunately, the syntax for automated machine learning tools is inconsistent with manual machine learning, with each other, and with error checks. Furthermore, few tools support advanced features such as topology search or higher-order operators. This paper introduces Lale, a library of high-level Python interfaces that simplifies and unifies automated machine learning in a consistent way.
Mining Documentation to Extract Hyperparameter Schemas
Jul 02, 2020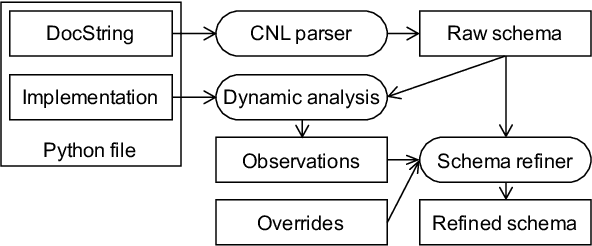
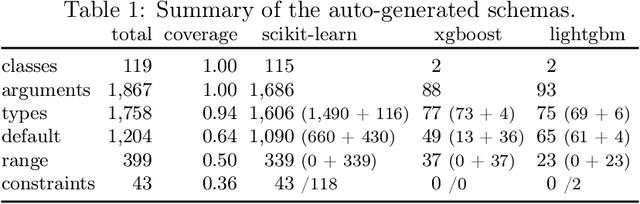

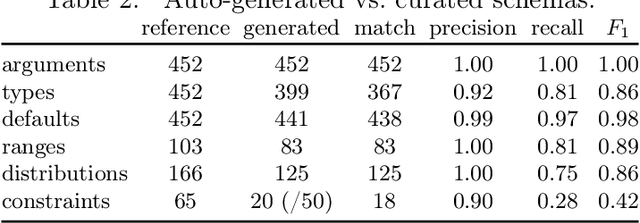
AI automation tools need machine-readable hyperparameter schemas to define their search spaces. At the same time, AI libraries often come with good human-readable documentation. While such documentation contains most of the necessary information, it is unfortunately not ready to consume by tools. This paper describes how to automatically mine Python docstrings in AI libraries to extract JSON Schemas for their hyperparameters. We evaluate our approach on 119 transformers and estimators from three different libraries and find that it is effective at extracting machine-readable schemas. Our vision is to reduce the burden to manually create and maintain such schemas for AI automation tools and broaden the reach of automation to larger libraries and richer schemas.
Extending Stan for Deep Probabilistic Programming
Sep 30, 2018
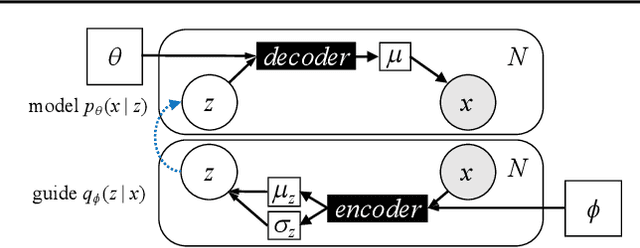

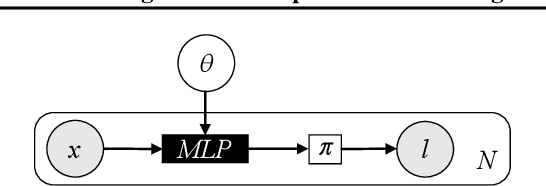
Deep probabilistic programming combines deep neural networks (for automatic hierarchical representation learning) with probabilistic models (for principled handling of uncertainty). Unfortunately, it is difficult to write deep probabilistic models, because existing programming frameworks lack concise, high-level, and clean ways to express them. To ease this task, we extend Stan, a popular high-level probabilistic programming language, to use deep neural networks written in PyTorch. Training deep probabilistic models works best with variational inference, so we also extend Stan for that. We implement these extensions by translating Stan programs to Pyro. Our translation clarifies the relationship between different families of probabilistic programming languages. Overall, our paper is a step towards making deep probabilistic programming easier.
Deep Probabilistic Programming Languages: A Qualitative Study
Apr 17, 2018



Deep probabilistic programming languages try to combine the advantages of deep learning with those of probabilistic programming languages. If successful, this would be a big step forward in machine learning and programming languages. Unfortunately, as of now, this new crop of languages is hard to use and understand. This paper addresses this problem directly by explaining deep probabilistic programming languages and indirectly by characterizing their current strengths and weaknesses.