 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel WaveNet: Fast High-Fidelity Speech Synthesis
Nov 28, 2017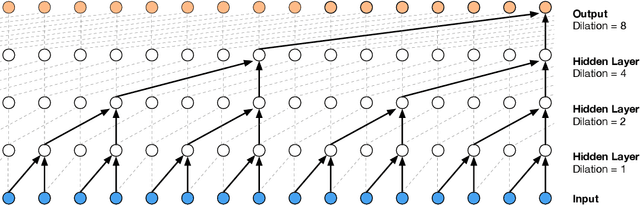
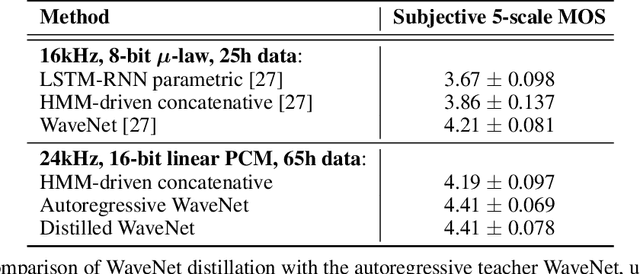
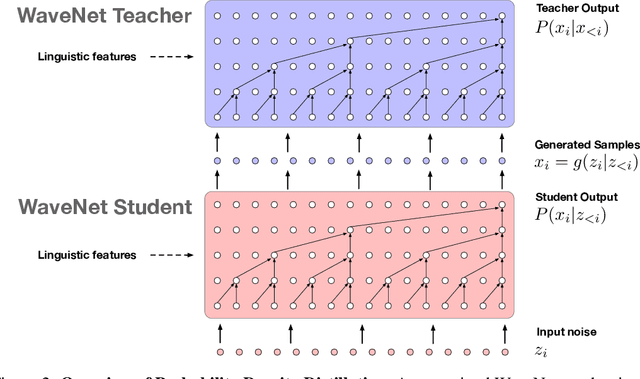
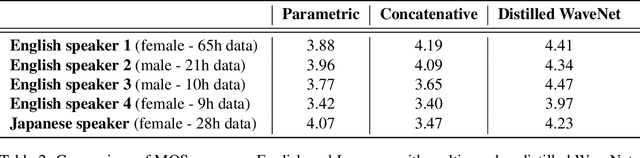
The recently-developed WaveNet architecture is the current state of the art in realistic speech synthesis, consistently rated as more natural sounding for many different languages than any previous system. However, because WaveNet relies on sequential generation of one audio sample at a time, it is poorly suited to today's massively parallel computers, and therefore hard to deploy in a real-time production setting. This paper introduces Probability Density Distillation, a new method for training a parallel feed-forward network from a trained WaveNet with no significant difference in quality. The resulting system is capable of generating high-fidelity speech samples at more than 20 times faster than real-time, and is deployed online by Google Assistant, including serving multiple English and Japanese voices.
Population Based Training of Neural Networks
Nov 28, 2017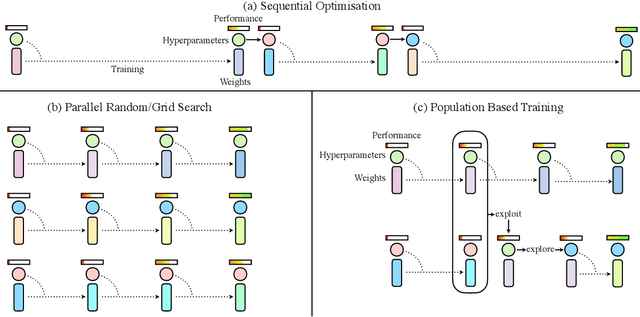

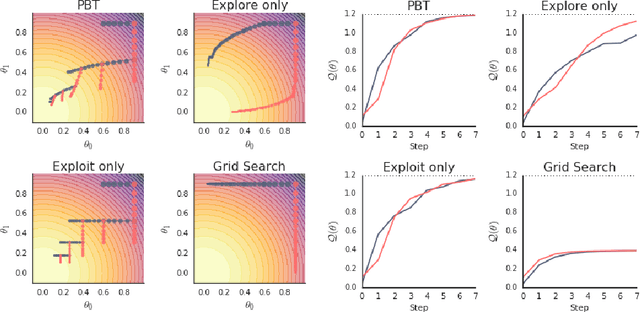
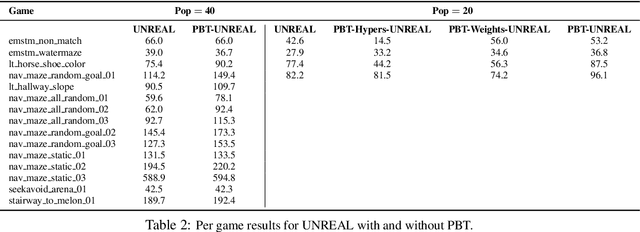
Neural networks dominate the modern machine learning landscape, but their training and success still suffer from sensitivity to empirical choices of hyperparameters such as model architecture, loss function, and optimisation algorithm. In this work we present \emph{Population Based Training (PBT)}, a simple asynchronous optimisation algorithm which effectively utilises a fixed computational budget to jointly optimise a population of models and their hyperparameters to maximise performance. Importantly, PBT discovers a schedule of hyperparameter settings rather than following the generally sub-optimal strategy of trying to find a single fixed set to use for the whole course of training. With just a small modification to a typical distributed hyperparameter training framework, our method allows robust and reliable training of models. We demonstrate the effectiveness of PBT on deep reinforcement learning problems, showing faster wall-clock convergence and higher final performance of agents by optimising over a suite of hyperparameters. In addition, we show the same method can be applied to supervised learning for machine translation, where PBT is used to maximise the BLEU score directly, and also to training of Generative Adversarial Networks to maximise the Inception score of generated images. In all cases PBT results in the automatic discovery of hyperparameter schedules and model selection which results in stable training and better final performance.
StarCraft II: A New Challenge for Reinforcement Learning
Aug 16, 2017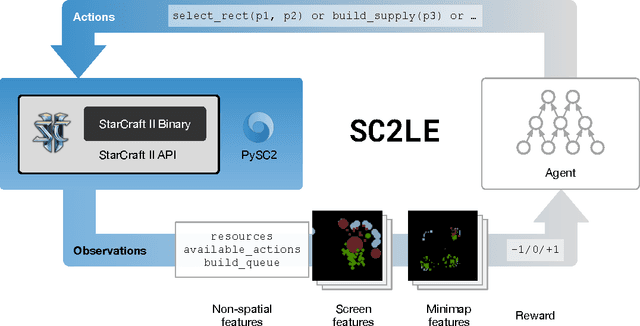
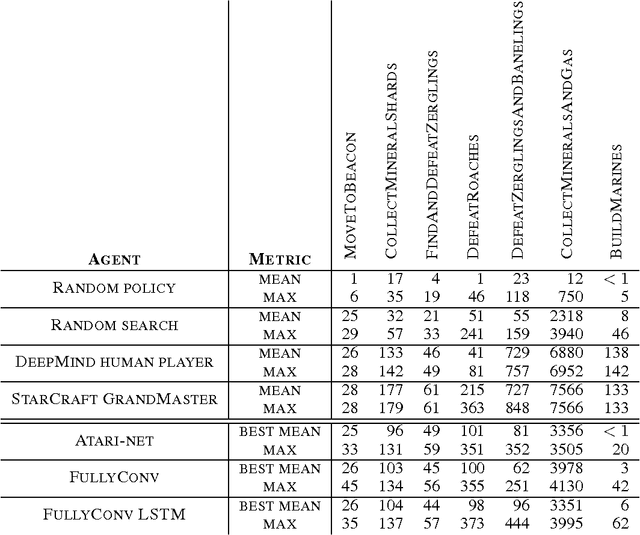

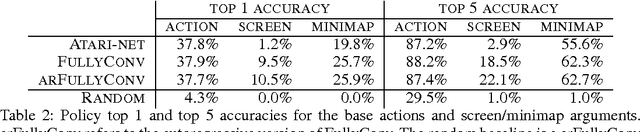
This paper introduces SC2LE (StarCraft II Learning Environment), a reinforcement learning environment based on the StarCraft II game. This domain poses a new grand challenge for reinforcement learning, representing a more difficult class of problems than considered in most prior work. It is a multi-agent problem with multiple players interacting; there is imperfect information due to a partially observed map; it has a large action space involving the selection and control of hundreds of units; it has a large state space that must be observed solely from raw input feature planes; and it has delayed credit assignment requiring long-term strategies over thousands of steps. We describe the observation, action, and reward specification for the StarCraft II domain and provide an open source Python-based interface for communicating with the game engine. In addition to the main game maps, we provide a suite of mini-games focusing on different elements of StarCraft II gameplay. For the main game maps, we also provide an accompanying dataset of game replay data from human expert players. We give initial baseline results for neural networks trained from this data to predict game outcomes and player actions. Finally, we present initial baseline results for canonical deep reinforcement learning agents applied to the StarCraft II domain. On the mini-games, these agents learn to achieve a level of play that is comparable to a novice player. However, when trained on the main game, these agents are unable to make significant progress. Thus, SC2LE offers a new and challenging environment for exploring deep reinforcement learning algorithms and architectures.
Learning model-based planning from scratch
Jul 19, 2017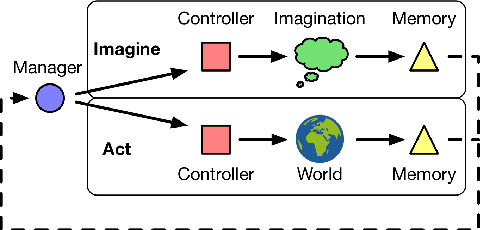
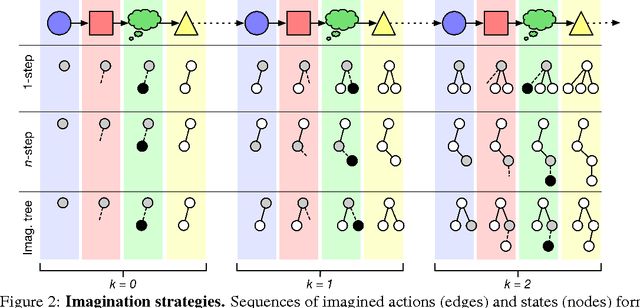
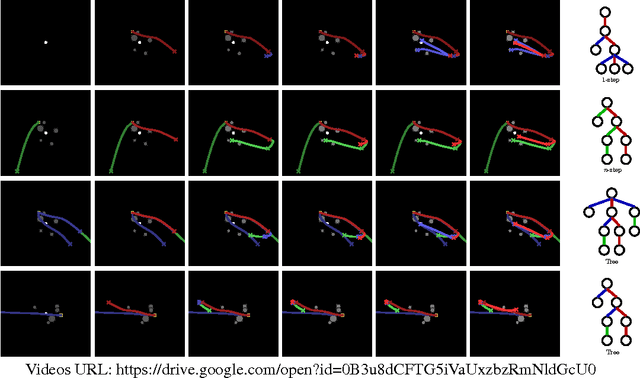
Conventional wisdom holds that model-based planning is a powerful approach to sequential decision-making. It is often very challenging in practice, however, because while a model can be used to evaluate a plan, it does not prescribe how to construct a plan. Here we introduce the "Imagination-based Planner", the first model-based, sequential decision-making agent that can learn to construct, evaluate, and execute plans. Before any action, it can perform a variable number of imagination steps, which involve proposing an imagined action and evaluating it with its model-based imagination. All imagined actions and outcomes are aggregated, iteratively, into a "plan context" which conditions future real and imagined actions. The agent can even decide how to imagine: testing out alternative imagined actions, chaining sequences of actions together, or building a more complex "imagination tree" by navigating flexibly among the previously imagined states using a learned policy. And our agent can learn to plan economically, jointly optimizing for external rewards and computational costs associated with using its imagination. We show that our architecture can learn to solve a challenging continuous control problem, and also learn elaborate planning strategies in a discrete maze-solving task. Our work opens a new direction toward learning the components of a model-based planning system and how to use them.
Decoupled Neural Interfaces using Synthetic Gradients
Jul 03, 2017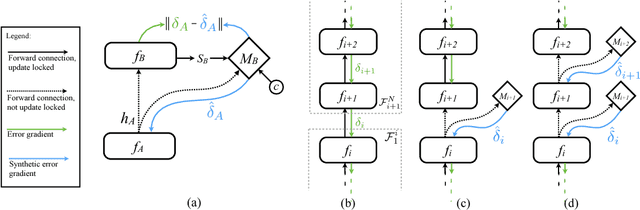
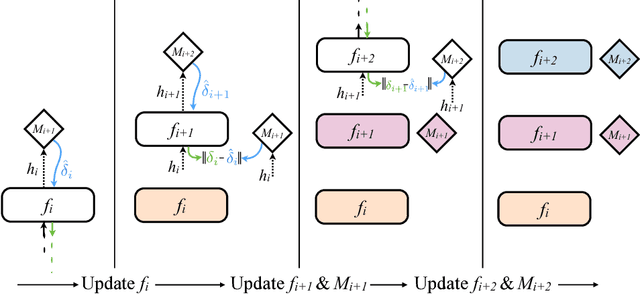

Training directed neural networks typically requires forward-propagating data through a computation graph, followed by backpropagating error signal, to produce weight updates. All layers, or more generally, modules, of the network are therefore locked, in the sense that they must wait for the remainder of the network to execute forwards and propagate error backwards before they can be updated. In this work we break this constraint by decoupling modules by introducing a model of the future computation of the network graph. These models predict what the result of the modelled subgraph will produce using only local information. In particular we focus on modelling error gradients: by using the modelled synthetic gradient in place of true backpropagated error gradients we decouple subgraphs, and can update them independently and asynchronously i.e. we realise decoupled neural interfaces. We show results for feed-forward models, where every layer is trained asynchronously, recurrent neural networks (RNNs) where predicting one's future gradient extends the time over which the RNN can effectively model, and also a hierarchical RNN system with ticking at different timescales. Finally, we demonstrate that in addition to predicting gradients, the same framework can be used to predict inputs, resulting in models which are decoupled in both the forward and backwards pass -- amounting to independent networks which co-learn such that they can be composed into a single functioning corporation.
Neural Message Passing for Quantum Chemistry
Jun 12, 2017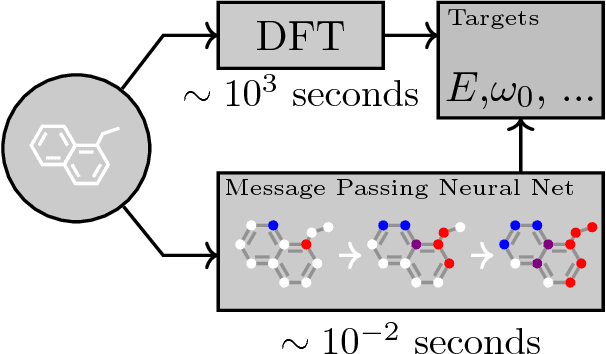

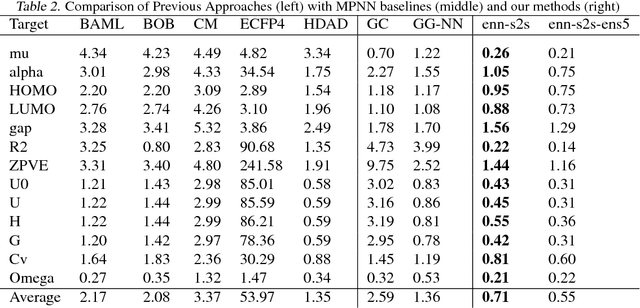
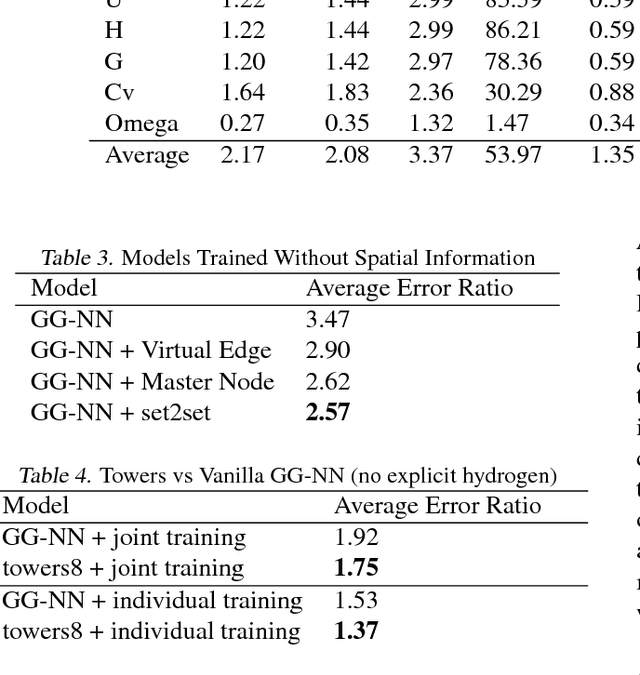
Supervised learning on molecules has incredible potential to be useful in chemistry, drug discovery, and materials science. Luckily, several promising and closely related neural network models invariant to molecular symmetries have already been described in the literature. These models learn a message passing algorithm and aggregation procedure to compute a function of their entire input graph. At this point, the next step is to find a particularly effective variant of this general approach and apply it to chemical prediction benchmarks until we either solve them or reach the limits of the approach. In this paper, we reformulate existing models into a single common framework we call Message Passing Neural Networks (MPNNs) and explore additional novel variations within this framework. Using MPNNs we demonstrate state of the art results on an important molecular property prediction benchmark; these results are strong enough that we believe future work should focus on datasets with larger molecules or more accurate ground truth labels.
Metacontrol for Adaptive Imagination-Based Optimization
May 07, 2017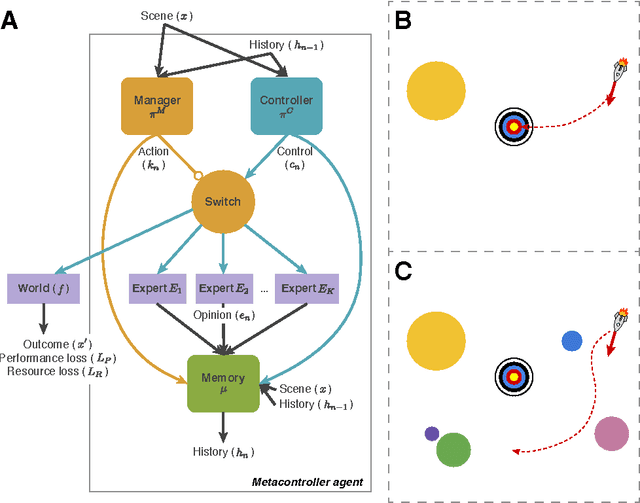
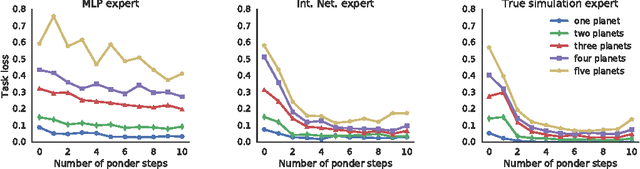
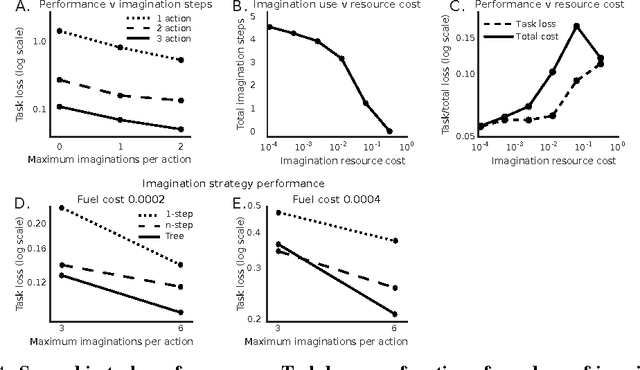
Many machine learning systems are built to solve the hardest examples of a particular task, which often makes them large and expensive to run---especially with respect to the easier examples, which might require much less computation. For an agent with a limited computational budget, this "one-size-fits-all" approach may result in the agent wasting valuable computation on easy examples, while not spending enough on hard examples. Rather than learning a single, fixed policy for solving all instances of a task, we introduce a metacontroller which learns to optimize a sequence of "imagined" internal simulations over predictive models of the world in order to construct a more informed, and more economical, solution. The metacontroller component is a model-free reinforcement learning agent, which decides both how many iterations of the optimization procedure to run, as well as which model to consult on each iteration. The models (which we call "experts") can be state transition models, action-value functions, or any other mechanism that provides information useful for solving the task, and can be learned on-policy or off-policy in parallel with the metacontroller. When the metacontroller, controller, and experts were trained with "interaction networks" (Battaglia et al., 2016) as expert models, our approach was able to solve a challenging decision-making problem under complex non-linear dynamics. The metacontroller learned to adapt the amount of computation it performed to the difficulty of the task, and learned how to choose which experts to consult by factoring in both their reliability and individual computational resource costs. This allowed the metacontroller to achieve a lower overall cost (task loss plus computational cost) than more traditional fixed policy approaches. These results demonstrate that our approach is a powerful framework for using...
Neural Episodic Control
Mar 06, 2017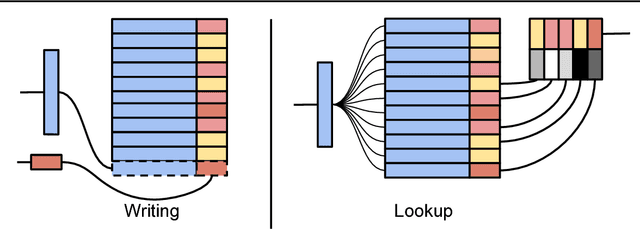
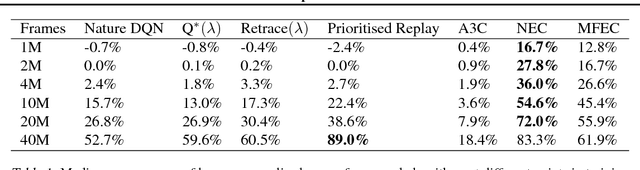
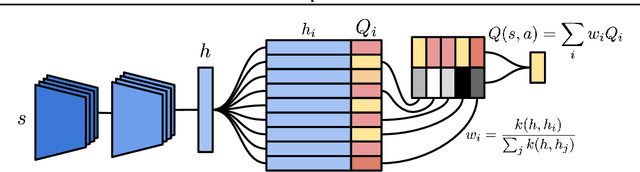
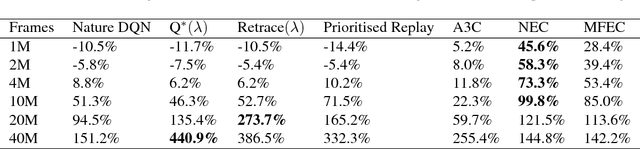
Deep reinforcement learning methods attain super-human performance in a wide range of environments. Such methods are grossly inefficient, often taking orders of magnitudes more data than humans to achieve reasonable performance. We propose Neural Episodic Control: a deep reinforcement learning agent that is able to rapidly assimilate new experiences and act upon them. Our agent uses a semi-tabular representation of the value function: a buffer of past experience containing slowly changing state representations and rapidly updated estimates of the value function. We show across a wide range of environments that our agent learns significantly faster than other state-of-the-art, general purpose deep reinforcement learning agents.
Understanding Synthetic Gradients and Decoupled Neural Interfaces
Mar 01, 2017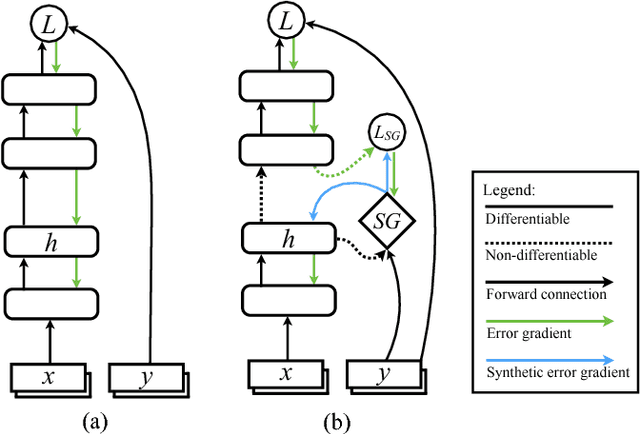
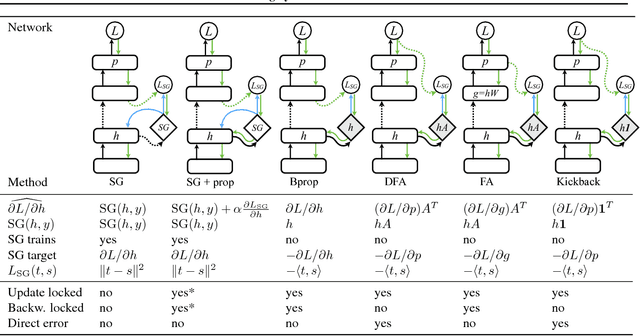
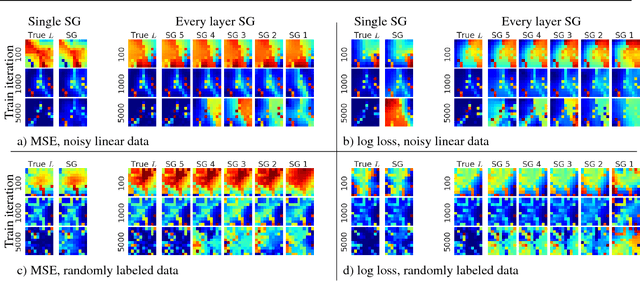
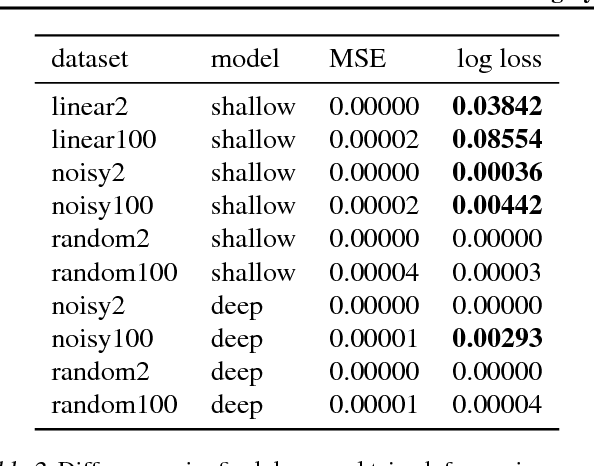
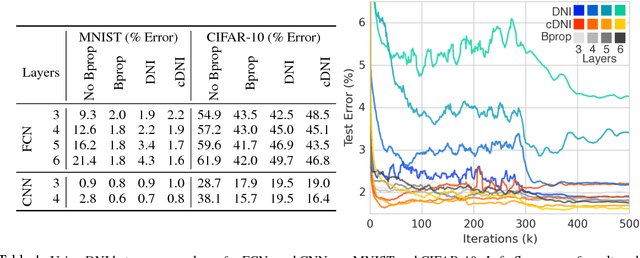
When training neural networks, the use of Synthetic Gradients (SG) allows layers or modules to be trained without update locking - without waiting for a true error gradient to be backpropagated - resulting in Decoupled Neural Interfaces (DNIs). This unlocked ability of being able to update parts of a neural network asynchronously and with only local information was demonstrated to work empirically in Jaderberg et al (2016). However, there has been very little demonstration of what changes DNIs and SGs impose from a functional, representational, and learning dynamics point of view. In this paper, we study DNIs through the use of synthetic gradients on feed-forward networks to better understand their behaviour and elucidate their effect on optimisation. We show that the incorporation of SGs does not affect the representational strength of the learning system for a neural network, and prove the convergence of the learning system for linear and deep linear models. On practical problems we investigate the mechanism by which synthetic gradient estimators approximate the true loss, and, surprisingly, how that leads to drastically different layer-wise representations. Finally, we also expose the relationship of using synthetic gradients to other error approximation techniques and find a unifying language for discussion and comparison.
Understanding deep learning requires rethinking generalization
Feb 26, 2017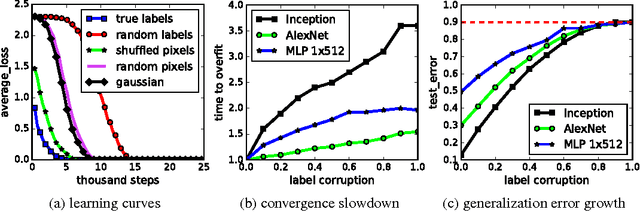
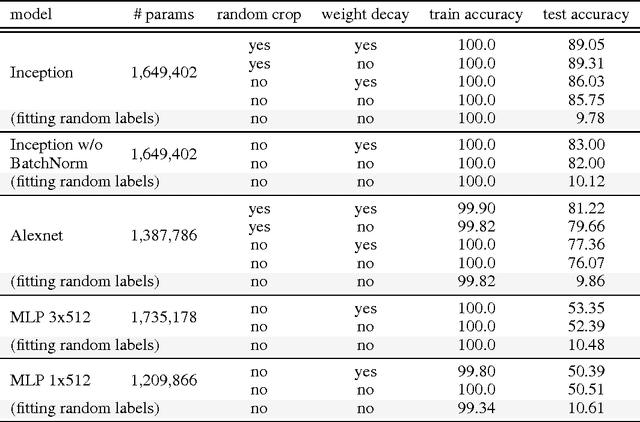
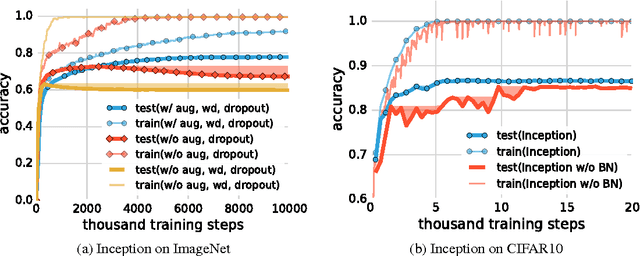
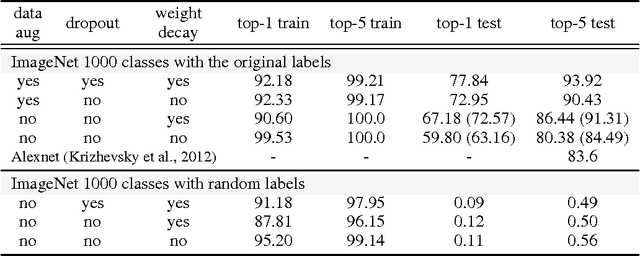
Despite their massive size, successful deep artificial neural networks can exhibit a remarkably small difference between training and test performance. Conventional wisdom attributes small generalization error either to properties of the model family, or to the regularization techniques used during training. Through extensive systematic experiments, we show how these traditional approaches fail to explain why large neural networks generalize well in practice. Specifically, our experiments establish that state-of-the-art convolutional networks for image classification trained with stochastic gradient methods easily fit a random labeling of the training data. This phenomenon is qualitatively unaffected by explicit regularization, and occurs even if we replace the true images by completely unstructured random noise. We corroborate these experimental findings with a theoretical construction showing that simple depth two neural networks already have perfect finite sample expressivity as soon as the number of parameters exceeds the number of data points as it usually does in practice. We interpret our experimental findings by comparison with traditional models.