 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks for Deep Off-Policy Evaluation
Mar 30, 2021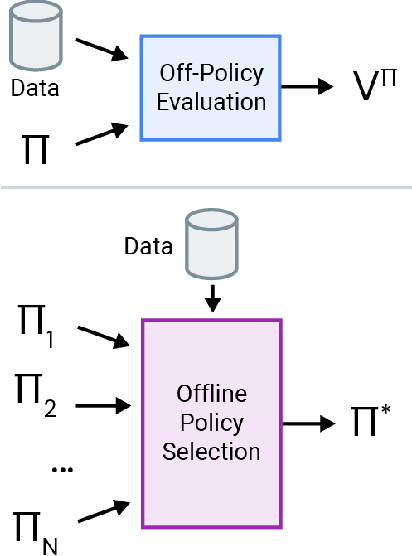
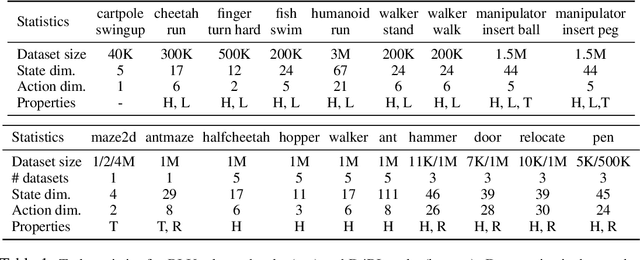
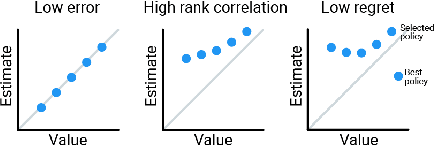
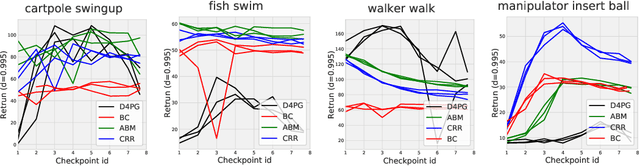
Off-policy evaluation (OPE) holds the promise of being able to leverage large, offline datasets for both evaluating and selecting complex policies for decision making. The ability to learn offline is particularly important in many real-world domains, such as in healthcare, recommender systems, or robotics, where online data collection is an expensive and potentially dangerous process. Being able to accurately evaluate and select high-performing policies without requiring online interaction could yield significant benefits in safety, time, and cost for these applications. While many OPE methods have been proposed in recent years, comparing results between papers is difficult because currently there is a lack of a comprehensive and unified benchmark, and measuring algorithmic progress has been challenging due to the lack of difficult evaluation tasks. In order to address this gap, we present a collection of policies that in conjunction with existing offline datasets can be used for benchmarking off-policy evaluation. Our tasks include a range of challenging high-dimensional continuous control problems, with wide selections of datasets and policies for performing policy selection. The goal of our benchmark is to provide a standardized measure of progress that is motivated from a set of principles designed to challenge and test the limits of existing OPE methods. We perform an evaluation of state-of-the-art algorithms and provide open-source access to our data and code to foster future research in this area.
Policy Information Capacity: Information-Theoretic Measure for Task Complexity in Deep Reinforcement Learning
Mar 23, 2021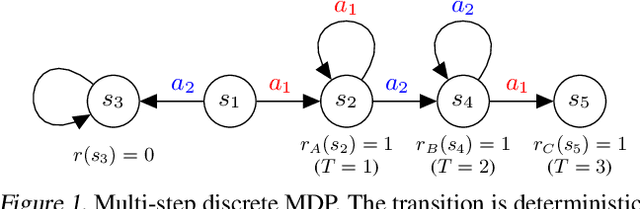
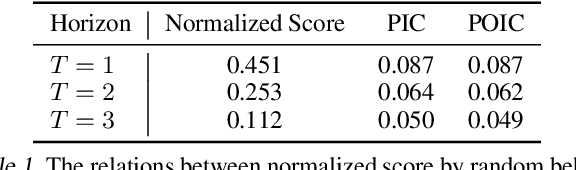
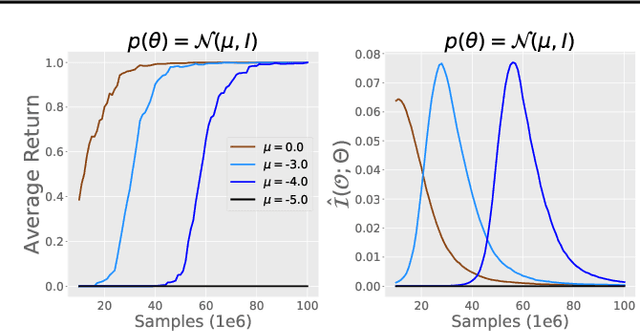
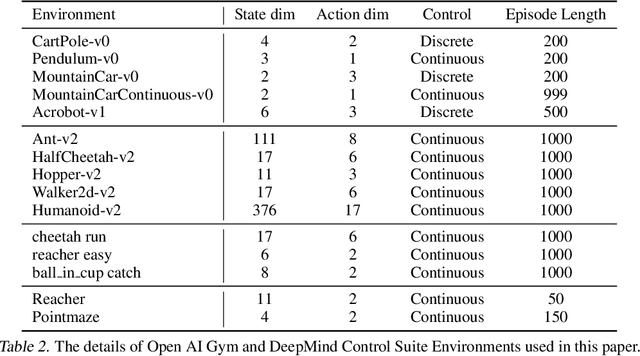
Progress in deep reinforcement learning (RL) research is largely enabled by benchmark task environments. However, analyzing the nature of those environments is often overlooked. In particular, we still do not have agreeable ways to measure the difficulty or solvability of a task, given that each has fundamentally different actions, observations, dynamics, rewards, and can be tackled with diverse RL algorithms. In this work, we propose policy information capacity (PIC) -- the mutual information between policy parameters and episodic return -- and policy-optimal information capacity (POIC) -- between policy parameters and episodic optimality -- as two environment-agnostic, algorithm-agnostic quantitative metrics for task difficulty. Evaluating our metrics across toy environments as well as continuous control benchmark tasks from OpenAI Gym and DeepMind Control Suite, we empirically demonstrate that these information-theoretic metrics have higher correlations with normalized task solvability scores than a variety of alternatives. Lastly, we show that these metrics can also be used for fast and compute-efficient optimizations of key design parameters such as reward shaping, policy architectures, and MDP properties for better solvability by RL algorithms without ever running full RL experiments.
Near Optimal Policy Optimization via REPS
Mar 17, 2021Since its introduction a decade ago, \emph{relative entropy policy search} (REPS) has demonstrated successful policy learning on a number of simulated and real-world robotic domains, not to mention providing algorithmic components used by many recently proposed reinforcement learning (RL) algorithms. While REPS is commonly known in the community, there exist no guarantees on its performance when using stochastic and gradient-based solvers. In this paper we aim to fill this gap by providing guarantees and convergence rates for the sub-optimality of a policy learned using first-order optimization methods applied to the REPS objective. We first consider the setting in which we are given access to exact gradients and demonstrate how near-optimality of the objective translates to near-optimality of the policy. We then consider the practical setting of stochastic gradients, and introduce a technique that uses \emph{generative} access to the underlying Markov decision process to compute parameter updates that maintain favorable convergence to the optimal regularized policy.
Offline Reinforcement Learning with Fisher Divergence Critic Regularization
Mar 14, 2021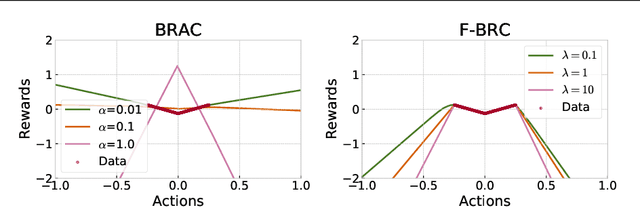
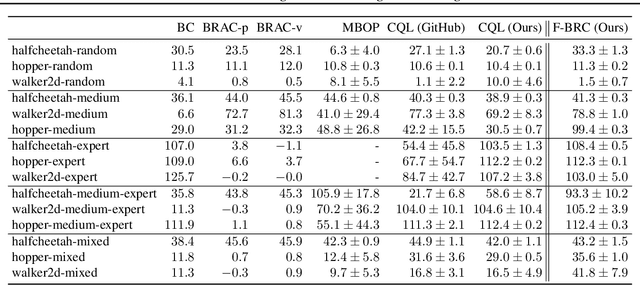
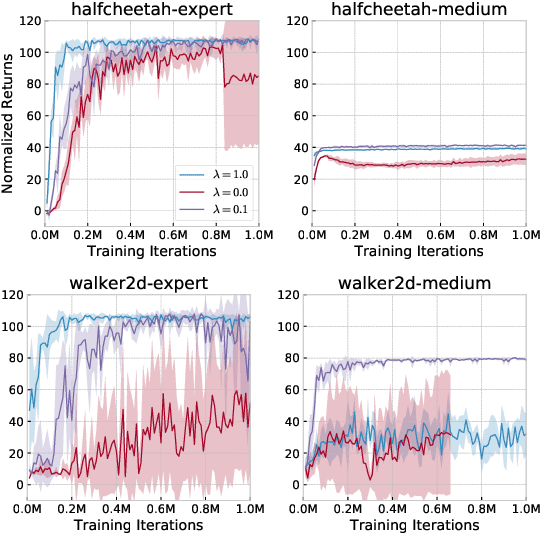
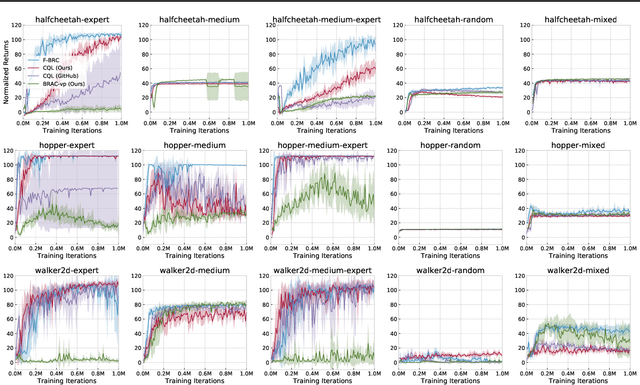
Many modern approaches to offline Reinforcement Learning (RL) utilize behavior regularization, typically augmenting a model-free actor critic algorithm with a penalty measuring divergence of the policy from the offline data. In this work, we propose an alternative approach to encouraging the learned policy to stay close to the data, namely parameterizing the critic as the log-behavior-policy, which generated the offline data, plus a state-action value offset term, which can be learned using a neural network. Behavior regularization then corresponds to an appropriate regularizer on the offset term. We propose using a gradient penalty regularizer for the offset term and demonstrate its equivalence to Fisher divergence regularization, suggesting connections to the score matching and generative energy-based model literature. We thus term our resulting algorithm Fisher-BRC (Behavior Regularized Critic). On standard offline RL benchmarks, Fisher-BRC achieves both improved performance and faster convergence over existing state-of-the-art methods.
Representation Matters: Offline Pretraining for Sequential Decision Making
Feb 11, 2021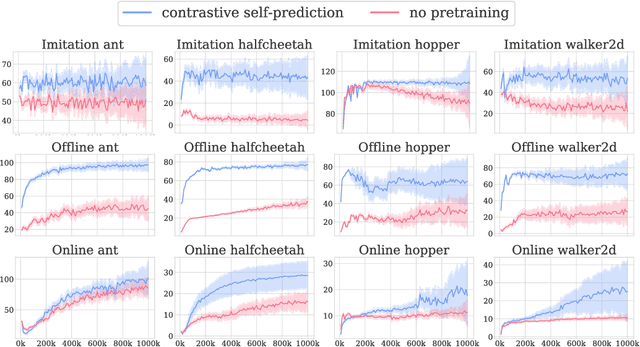

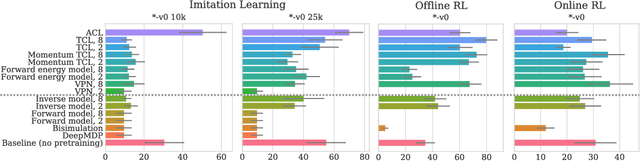
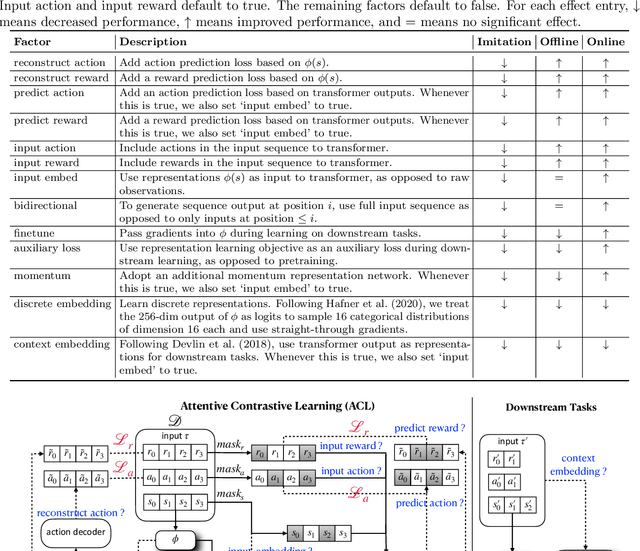
The recent success of supervised learning methods on ever larger offline datasets has spurred interest in the reinforcement learning (RL) field to investigate whether the same paradigms can be translated to RL algorithms. This research area, known as offline RL, has largely focused on offline policy optimization, aiming to find a return-maximizing policy exclusively from offline data. In this paper, we consider a slightly different approach to incorporating offline data into sequential decision-making. We aim to answer the question, what unsupervised objectives applied to offline datasets are able to learn state representations which elevate performance on downstream tasks, whether those downstream tasks be online RL, imitation learning from expert demonstrations, or even offline policy optimization based on the same offline dataset? Through a variety of experiments utilizing standard offline RL datasets, we find that the use of pretraining with unsupervised learning objectives can dramatically improve the performance of policy learning algorithms that otherwise yield mediocre performance on their own. Extensive ablations further provide insights into what components of these unsupervised objectives -- e.g., reward prediction, continuous or discrete representations, pretraining or finetuning -- are most important and in which settings.
Offline Policy Selection under Uncertainty
Dec 12, 2020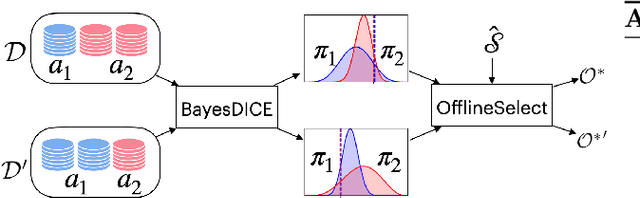
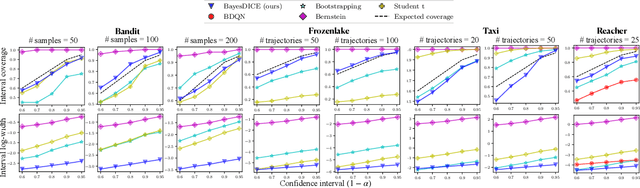
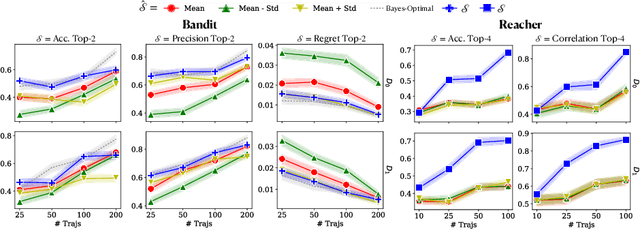
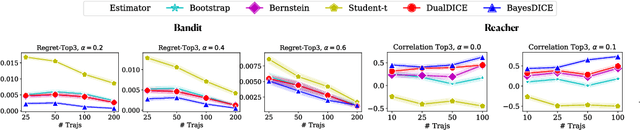
The presence of uncertainty in policy evaluation significantly complicates the process of policy ranking and selection in real-world settings. We formally consider offline policy selection as learning preferences over a set of policy prospects given a fixed experience dataset. While one can select or rank policies based on point estimates of their policy values or high-confidence intervals, access to the full distribution over one's belief of the policy value enables more flexible selection algorithms under a wider range of downstream evaluation metrics. We propose BayesDICE for estimating this belief distribution in terms of posteriors of distribution correction ratios derived from stochastic constraints (as opposed to explicit likelihood, which is not available). Empirically, BayesDICE is highly competitive to existing state-of-the-art approaches in confidence interval estimation. More importantly, we show how the belief distribution estimated by BayesDICE may be used to rank policies with respect to any arbitrary downstream policy selection metric, and we empirically demonstrate that this selection procedure significantly outperforms existing approaches, such as ranking policies according to mean or high-confidence lower bound value estimates.
OPAL: Offline Primitive Discovery for Accelerating Offline Reinforcement Learning
Oct 27, 2020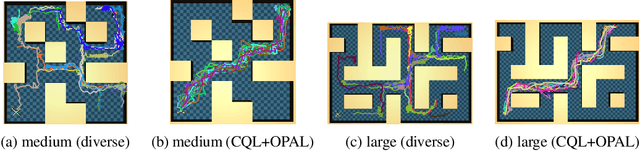

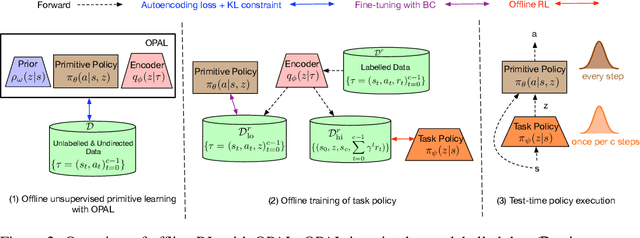

Reinforcement learning (RL) has achieved impressive performance in a variety of online settings in which an agent's ability to query the environment for transitions and rewards is effectively unlimited. However, in many practical applications, the situation is reversed: an agent may have access to large amounts of undirected offline experience data, while access to the online environment is severely limited. In this work, we focus on this offline setting. Our main insight is that, when presented with offline data composed of a variety of behaviors, an effective way to leverage this data is to extract a continuous space of recurring and temporally extended primitive behaviors before using these primitives for downstream task learning. Primitives extracted in this way serve two purposes: they delineate the behaviors that are supported by the data from those that are not, making them useful for avoiding distributional shift in offline RL; and they provide a degree of temporal abstraction, which reduces the effective horizon yielding better learning in theory, and improved offline RL in practice. In addition to benefiting offline policy optimization, we show that performing offline primitive learning in this way can also be leveraged for improving few-shot imitation learning as well as exploration and transfer in online RL on a variety of benchmark domains. Visualizations are available at https://sites.google.com/view/opal-iclr
CoinDICE: Off-Policy Confidence Interval Estimation
Oct 22, 2020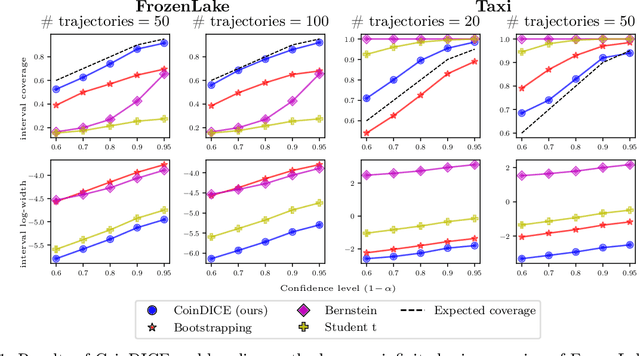
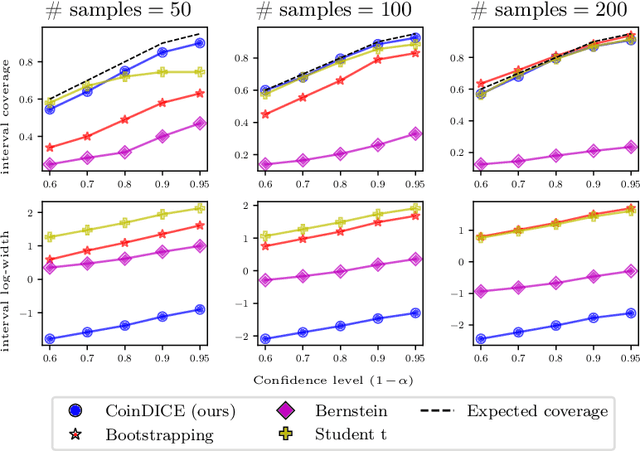
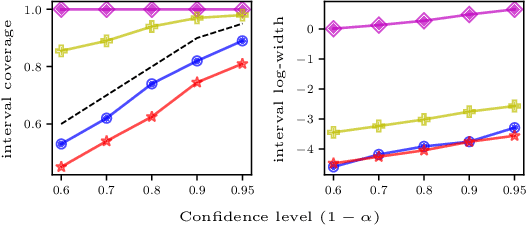
We study high-confidence behavior-agnostic off-policy evaluation in reinforcement learning, where the goal is to estimate a confidence interval on a target policy's value, given only access to a static experience dataset collected by unknown behavior policies. Starting from a function space embedding of the linear program formulation of the $Q$-function, we obtain an optimization problem with generalized estimating equation constraints. By applying the generalized empirical likelihood method to the resulting Lagrangian, we propose CoinDICE, a novel and efficient algorithm for computing confidence intervals. Theoretically, we prove the obtained confidence intervals are valid, in both asymptotic and finite-sample regimes. Empirically, we show in a variety of benchmarks that the confidence interval estimates are tighter and more accurate than existing methods.
Statistical Bootstrapping for Uncertainty Estimation in Off-Policy Evaluation
Jul 27, 2020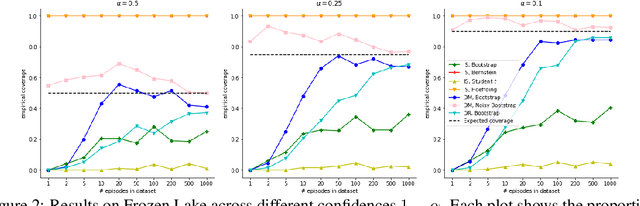
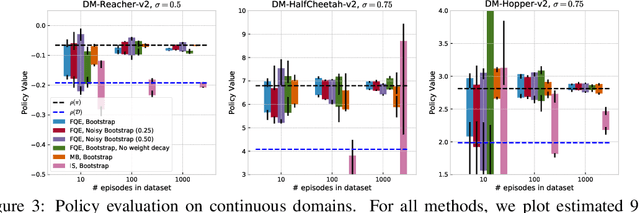
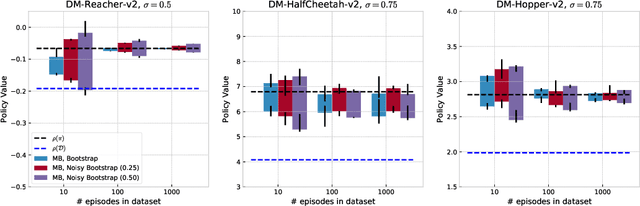
In reinforcement learning, it is typical to use the empirically observed transitions and rewards to estimate the value of a policy via either model-based or Q-fitting approaches. Although straightforward, these techniques in general yield biased estimates of the true value of the policy. In this work, we investigate the potential for statistical bootstrapping to be used as a way to take these biased estimates and produce calibrated confidence intervals for the true value of the policy. We identify conditions - specifically, sufficient data size and sufficient coverage - under which statistical bootstrapping in this setting is guaranteed to yield correct confidence intervals. In practical situations, these conditions often do not hold, and so we discuss and propose mechanisms that can be employed to mitigate their effects. We evaluate our proposed method and show that it can yield accurate confidence intervals in a variety of conditions, including challenging continuous control environments and small data regimes.
Off-Policy Evaluation via the Regularized Lagrangian
Jul 07, 2020

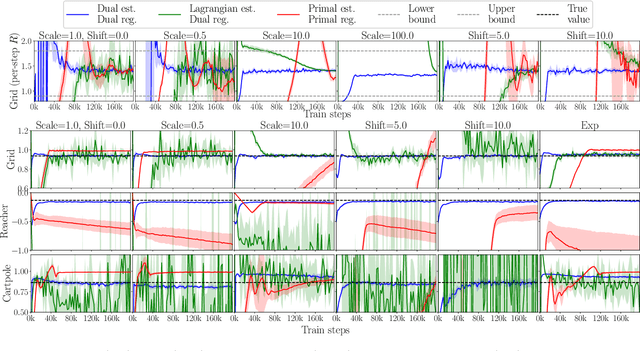
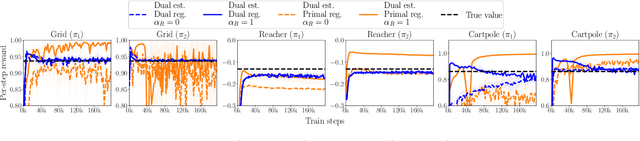
The recently proposed distribution correction estimation (DICE) family of estimators has advanced the state of the art in off-policy evaluation from behavior-agnostic data. While these estimators all perform some form of stationary distribution correction, they arise from different derivations and objective functions. In this paper, we unify these estimators as regularized Lagrangians of the same linear program. The unification allows us to expand the space of DICE estimators to new alternatives that demonstrate improved performance. More importantly, by analyzing the expanded space of estimators both mathematically and empirically we find that dual solutions offer greater flexibility in navigating the tradeoff between optimization stability and estimation bias, and generally provide superior estimates in practice.