 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose Language Counts as High Quality? Measuring Language Ideologies in Text Data Selection
Jan 26, 2022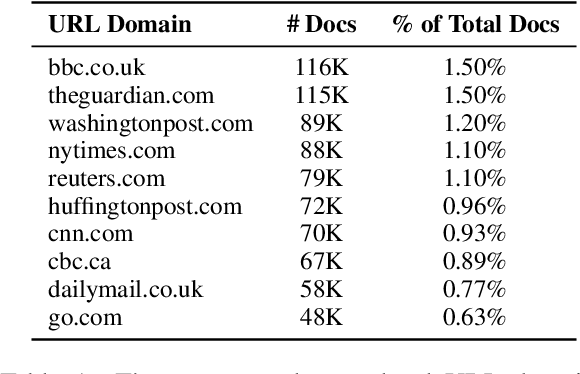
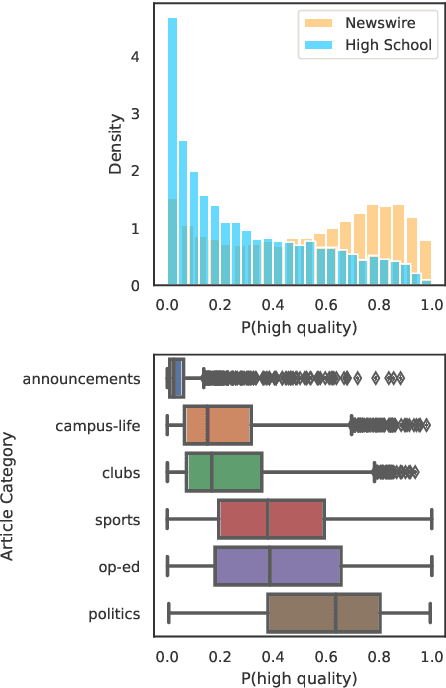
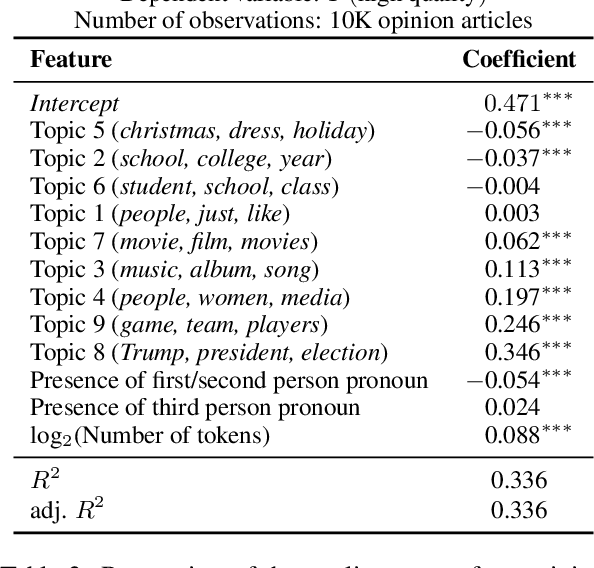
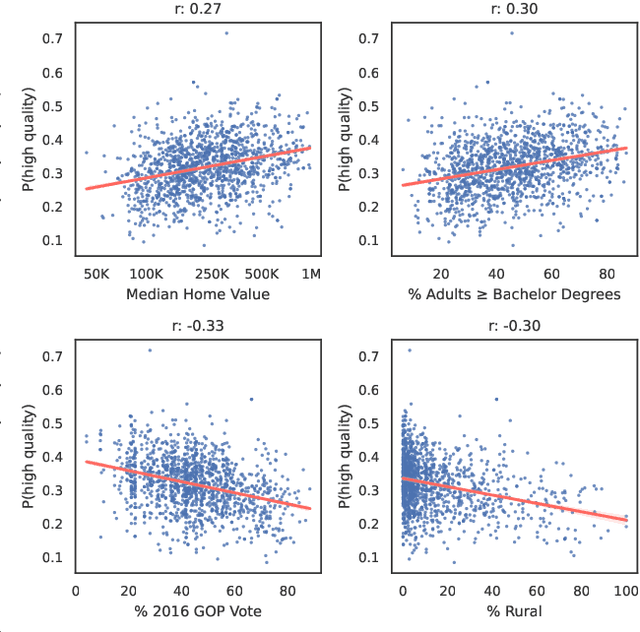
Language models increasingly rely on massive web dumps for diverse text data. However, these sources are rife with undesirable content. As such, resources like Wikipedia, books, and newswire often serve as anchors for automatically selecting web text most suitable for language modeling, a process typically referred to as quality filtering. Using a new dataset of U.S. high school newspaper articles -- written by students from across the country -- we investigate whose language is preferred by the quality filter used for GPT-3. We find that newspapers from larger schools, located in wealthier, educated, and urban ZIP codes are more likely to be classified as high quality. We then demonstrate that the filter's measurement of quality is unaligned with other sensible metrics, such as factuality or literary acclaim. We argue that privileging any corpus as high quality entails a language ideology, and more care is needed to construct training corpora for language models, with better transparency and justification for the inclusion or exclusion of various texts.
UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models
Jan 20, 2022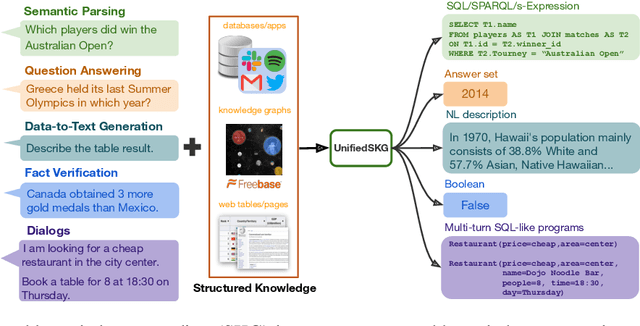
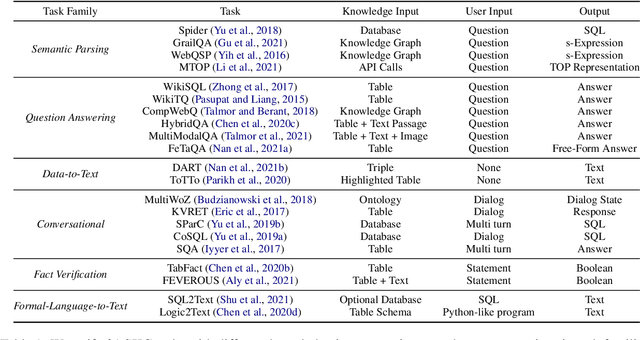
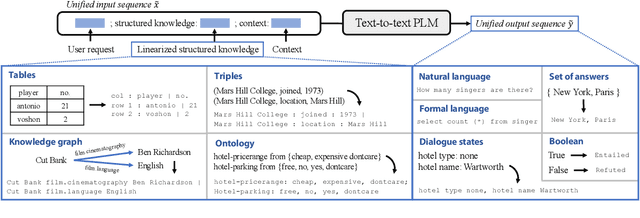
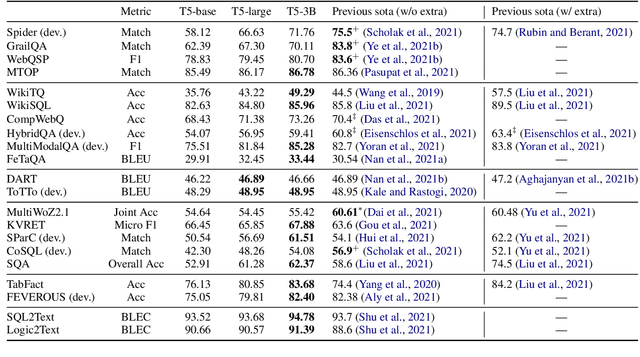
Structured knowledge grounding (SKG) leverages structured knowledge to complete user requests, such as semantic parsing over databases and question answering over knowledge bases. Since the inputs and outputs of SKG tasks are heterogeneous, they have been studied separately by different communities, which limits systematic and compatible research on SKG. In this paper, we overcome this limitation by proposing the SKG framework, which unifies 21 SKG tasks into a text-to-text format, aiming to promote systematic SKG research, instead of being exclusive to a single task, domain, or dataset. We use UnifiedSKG to benchmark T5 with different sizes and show that T5, with simple modifications when necessary, achieves state-of-the-art performance on almost all of the 21 tasks. We further demonstrate that multi-task prefix-tuning improves the performance on most tasks, largely improving the overall performance. UnifiedSKG also facilitates the investigation of zero-shot and few-shot learning, and we show that T0, GPT-3, and Codex struggle in zero-shot and few-shot learning for SKG. We also use UnifiedSKG to conduct a series of controlled experiments on structured knowledge encoding variants across SKG tasks. UnifiedSKG is easily extensible to more tasks, and it is open-sourced at https://github.com/hkunlp/unifiedskg Latest collections at https://unifiedskg.com.
WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation
Jan 16, 2022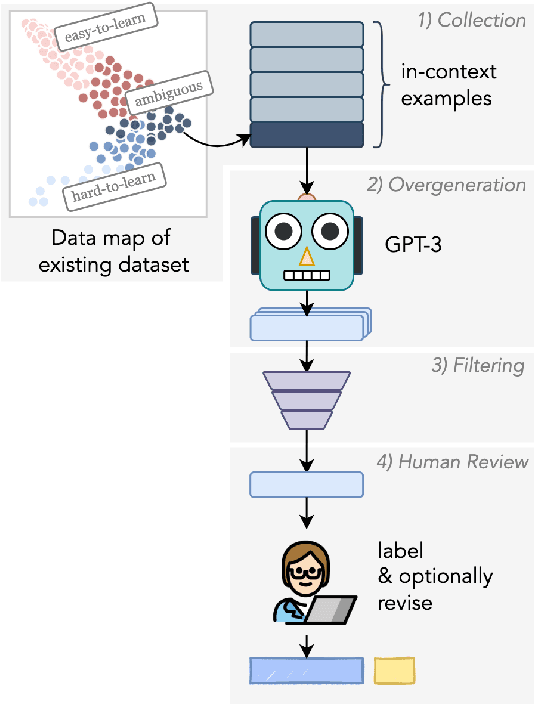
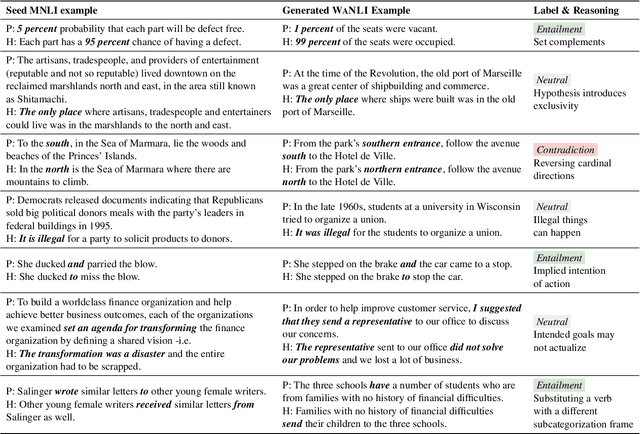
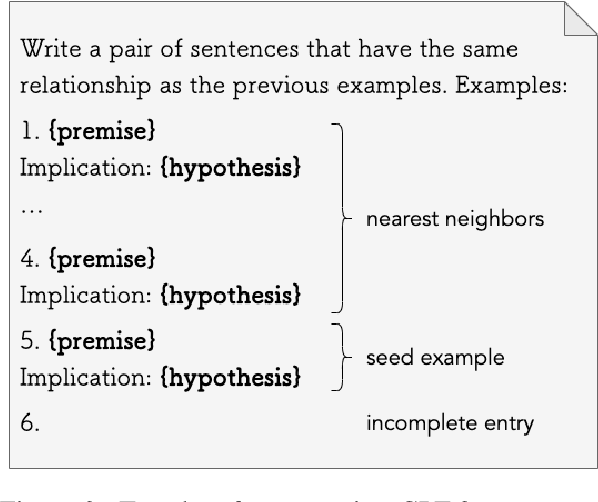
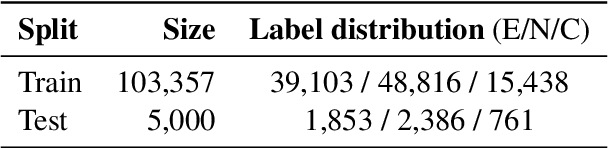
A recurring challenge of crowdsourcing NLP datasets at scale is that human writers often rely on repetitive patterns when crafting examples, leading to a lack of linguistic diversity. We introduce a novel paradigm for dataset creation based on human and machine collaboration, which brings together the generative strength of language models and the evaluative strength of humans. Starting with an existing dataset, MultiNLI, our approach uses dataset cartography to automatically identify examples that demonstrate challenging reasoning patterns, and instructs GPT-3 to compose new examples with similar patterns. Machine generated examples are then automatically filtered, and finally revised and labeled by human crowdworkers to ensure quality. The resulting dataset, WANLI, consists of 108,357 natural language inference (NLI) examples that present unique empirical strengths over existing NLI datasets. Remarkably, training a model on WANLI instead of MNLI (which is 4 times larger) improves performance on seven out-of-domain test sets we consider, including by 11% on HANS and 9% on Adversarial NLI. Moreover, combining MNLI with WANLI is more effective than combining with other augmentation sets that have been introduced. Our results demonstrate the potential of natural language generation techniques to curate NLP datasets of enhanced quality and diversity.
Computational Lens on Cognition: Study Of Autobiographical Versus Imagined Stories With Large-Scale Language Models
Jan 07, 2022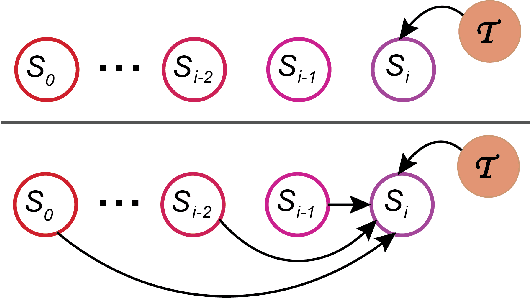
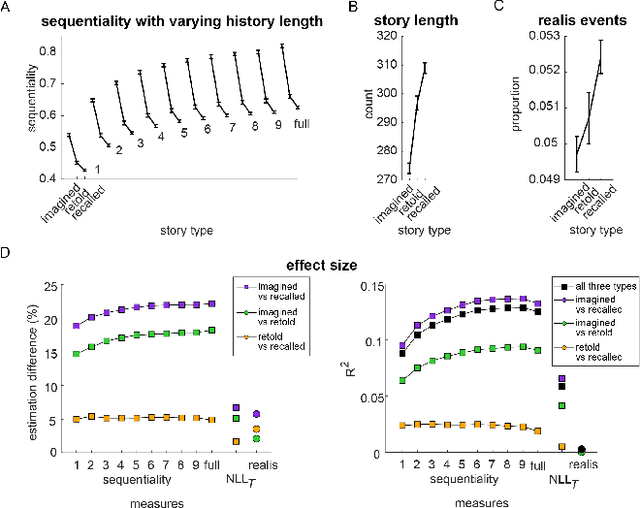
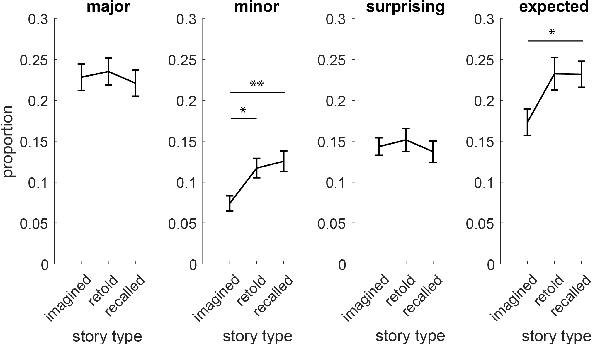
Lifelong experiences and learned knowledge lead to shared expectations about how common situations tend to unfold. Such knowledge enables people to interpret story narratives and identify salient events effortlessly. We study differences in the narrative flow of events in autobiographical versus imagined stories using GPT-3, one of the largest neural language models created to date. The diary-like stories were written by crowdworkers about either a recently experienced event or an imagined event on the same topic. To analyze the narrative flow of events of these stories, we measured sentence *sequentiality*, which compares the probability of a sentence with and without its preceding story context. We found that imagined stories have higher sequentiality than autobiographical stories, and that the sequentiality of autobiographical stories is higher when they are retold than when freshly recalled. Through an annotation of events in story sentences, we found that the story types contain similar proportions of major salient events, but that the autobiographical stories are denser in factual minor events. Furthermore, in comparison to imagined stories, autobiographical stories contain more concrete words and words related to the first person, cognitive processes, time, space, numbers, social words, and core drives and needs. Our findings highlight the opportunity to investigate memory and cognition with large-scale statistical language models.
NeuroLogic A*esque Decoding: Constrained Text Generation with Lookahead Heuristics
Dec 16, 2021

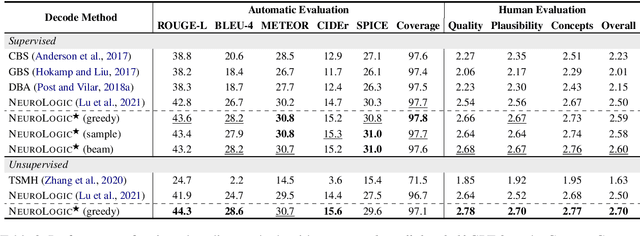
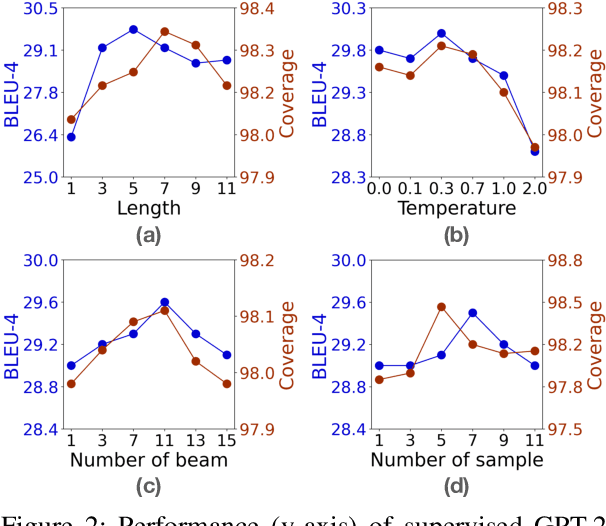
The dominant paradigm for neural text generation is left-to-right decoding from autoregressive language models. Constrained or controllable generation under complex lexical constraints, however, requires foresight to plan ahead feasible future paths. Drawing inspiration from the A* search algorithm, we propose NeuroLogic A*esque, a decoding algorithm that incorporates heuristic estimates of future cost. We develop efficient lookahead heuristics that are efficient for large-scale language models, making our method a drop-in replacement for common techniques such as beam search and top-k sampling. To enable constrained generation, we build on NeuroLogic decoding (Lu et al., 2021), combining its flexibility in incorporating logical constraints with A*esque estimates of future constraint satisfaction. Our approach outperforms competitive baselines on five generation tasks, and achieves new state-of-the-art performance on table-to-text generation, constrained machine translation, and keyword-constrained generation. The improvements are particularly notable on tasks that require complex constraint satisfaction or in few-shot or zero-shot settings. NeuroLogic A*esque illustrates the power of decoding for improving and enabling new capabilities of large-scale language models.
Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand
Dec 08, 2021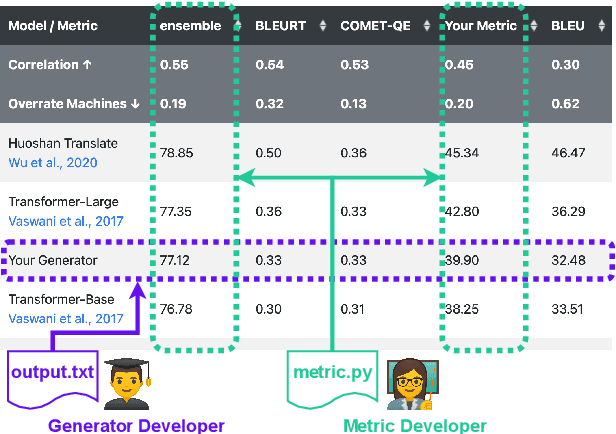
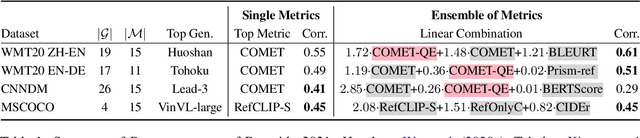
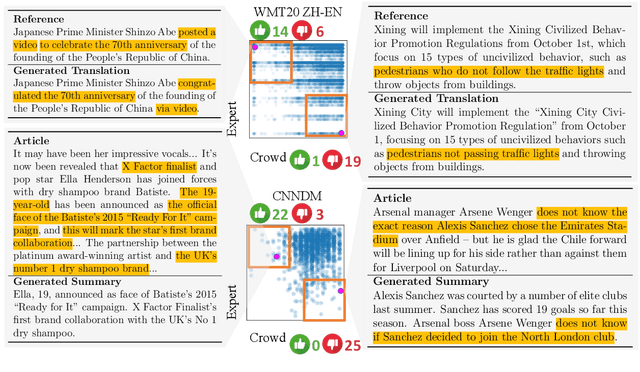

Natural language processing researchers have identified limitations of evaluation methodology for generation tasks, with new questions raised about the validity of automatic metrics and of crowdworker judgments. Meanwhile, efforts to improve generation models tend to focus on simple n-gram overlap metrics (e.g., BLEU, ROUGE). We argue that new advances on models and metrics should each more directly benefit and inform the other. We therefore propose a generalization of leaderboards, bidimensional leaderboards (Billboards), that simultaneously tracks progress in language generation tasks and metrics for their evaluation. Unlike conventional unidimensional leaderboards that sort submitted systems by predetermined metrics, a Billboard accepts both generators and evaluation metrics as competing entries. A Billboard automatically creates an ensemble metric that selects and linearly combines a few metrics based on a global analysis across generators. Further, metrics are ranked based on their correlations with human judgments. We release four Billboards for machine translation, summarization, and image captioning. We demonstrate that a linear ensemble of a few diverse metrics sometimes substantially outperforms existing metrics in isolation. Our mixed-effects model analysis shows that most automatic metrics, especially the reference-based ones, overrate machine over human generation, demonstrating the importance of updating metrics as generation models become stronger (and perhaps more similar to humans) in the future.
Transparent Human Evaluation for Image Captioning
Nov 17, 2021

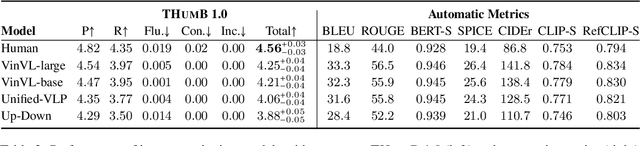
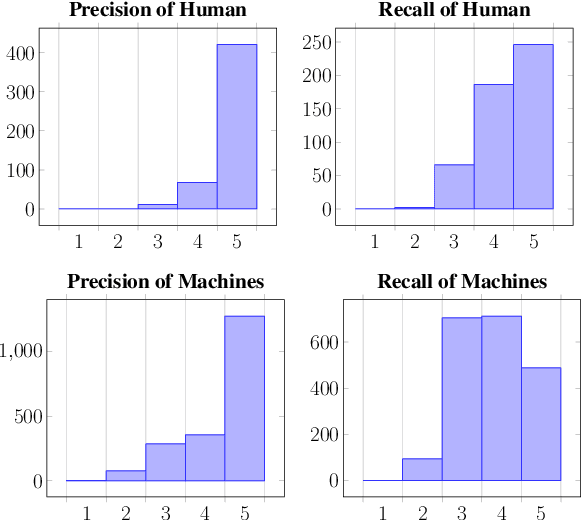
We establish a rubric-based human evaluation protocol for image captioning models. Our scoring rubrics and their definitions are carefully developed based on machine- and human-generated captions on the MSCOCO dataset. Each caption is evaluated along two main dimensions in a tradeoff (precision and recall) as well as other aspects that measure the text quality (fluency, conciseness, and inclusive language). Our evaluations demonstrate several critical problems of the current evaluation practice. Human-generated captions show substantially higher quality than machine-generated ones, especially in coverage of salient information (i.e., recall), while all automatic metrics say the opposite. Our rubric-based results reveal that CLIPScore, a recent metric that uses image features, better correlates with human judgments than conventional text-only metrics because it is more sensitive to recall. We hope that this work will promote a more transparent evaluation protocol for image captioning and its automatic metrics.
Annotators with Attitudes: How Annotator Beliefs And Identities Bias Toxic Language Detection
Nov 15, 2021

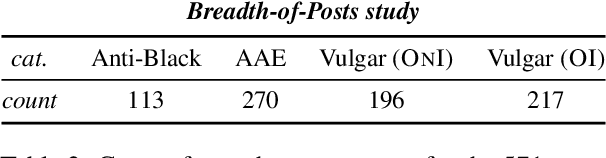
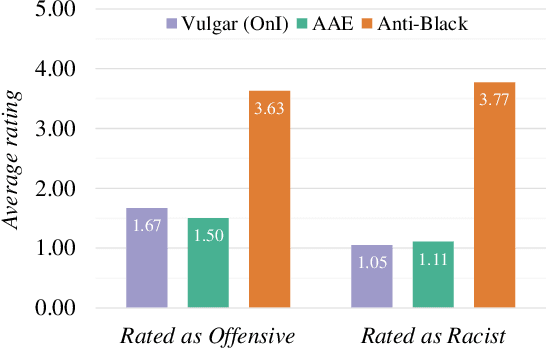
The perceived toxicity of language can vary based on someone's identity and beliefs, but this variation is often ignored when collecting toxic language datasets, resulting in dataset and model biases. We seek to understand the who, why, and what behind biases in toxicity annotations. In two online studies with demographically and politically diverse participants, we investigate the effect of annotator identities (who) and beliefs (why), drawing from social psychology research about hate speech, free speech, racist beliefs, political leaning, and more. We disentangle what is annotated as toxic by considering posts with three characteristics: anti-Black language, African American English (AAE) dialect, and vulgarity. Our results show strong associations between annotator identity and beliefs and their ratings of toxicity. Notably, more conservative annotators and those who scored highly on our scale for racist beliefs were less likely to rate anti-Black language as toxic, but more likely to rate AAE as toxic. We additionally present a case study illustrating how a popular toxicity detection system's ratings inherently reflect only specific beliefs and perspectives. Our findings call for contextualizing toxicity labels in social variables, which raises immense implications for toxic language annotation and detection.
Time Waits for No One! Analysis and Challenges of Temporal Misalignment
Nov 14, 2021

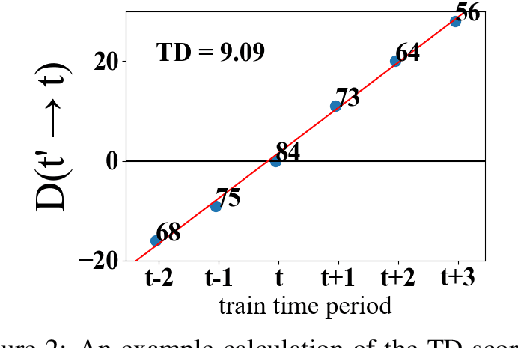
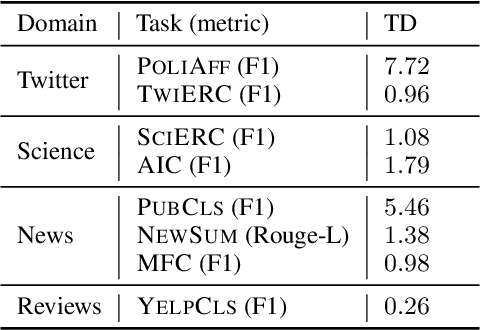
When an NLP model is trained on text data from one time period and tested or deployed on data from another, the resulting temporal misalignment can degrade end-task performance. In this work, we establish a suite of eight diverse tasks across different domains (social media, science papers, news, and reviews) and periods of time (spanning five years or more) to quantify the effects of temporal misalignment. Our study is focused on the ubiquitous setting where a pretrained model is optionally adapted through continued domain-specific pretraining, followed by task-specific finetuning. We establish a suite of tasks across multiple domains to study temporal misalignment in modern NLP systems. We find stronger effects of temporal misalignment on task performance than have been previously reported. We also find that, while temporal adaptation through continued pretraining can help, these gains are small compared to task-specific finetuning on data from the target time period. Our findings motivate continued research to improve temporal robustness of NLP models.
ABC: Attention with Bounded-memory Control
Oct 06, 2021
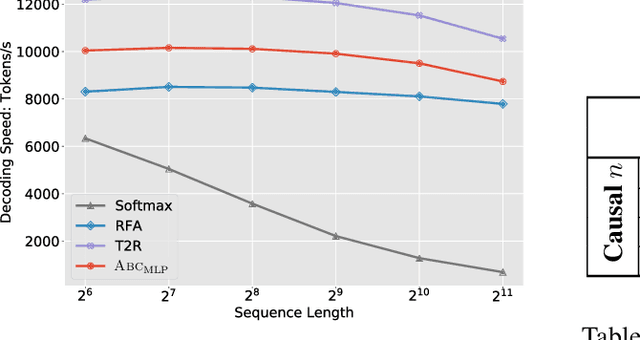
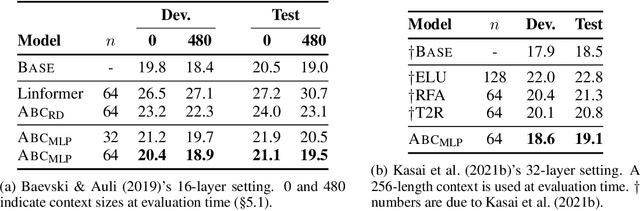
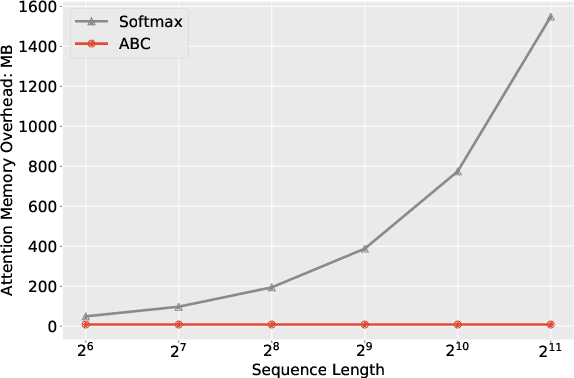
Transformer architectures have achieved state-of-the-art results on a variety of sequence modeling tasks. However, their attention mechanism comes with a quadratic complexity in sequence lengths, making the computational overhead prohibitive, especially for long sequences. Attention context can be seen as a random-access memory with each token taking a slot. Under this perspective, the memory size grows linearly with the sequence length, and so does the overhead of reading from it. One way to improve the efficiency is to bound the memory size. We show that disparate approaches can be subsumed into one abstraction, attention with bounded-memory control (ABC), and they vary in their organization of the memory. ABC reveals new, unexplored possibilities. First, it connects several efficient attention variants that would otherwise seem apart. Second, this abstraction gives new insights--an established approach (Wang et al., 2020b) previously thought to be not applicable in causal attention, actually is. Last, we present a new instance of ABC, which draws inspiration from existing ABC approaches, but replaces their heuristic memory-organizing functions with a learned, contextualized one. Our experiments on language modeling, machine translation, and masked language model finetuning show that our approach outperforms previous efficient attention models; compared to the strong transformer baselines, it significantly improves the inference time and space efficiency with no or negligible accuracy loss.