 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFAD: Coarse-to-Fine Action Detector for Spatiotemporal Action Localization
Aug 19, 2020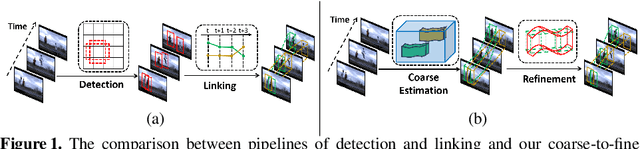
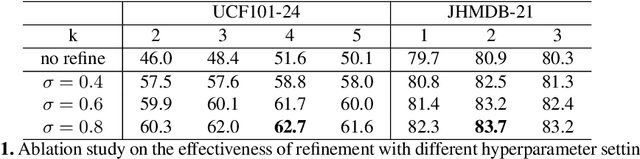
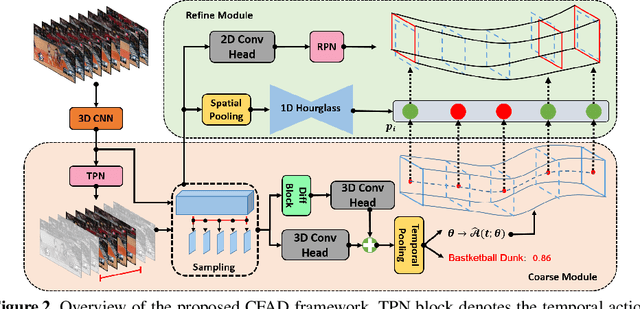
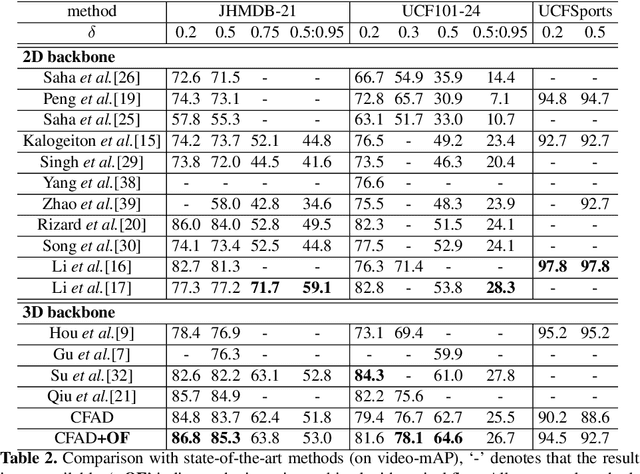
Most current pipelines for spatio-temporal action localization connect frame-wise or clip-wise detection results to generate action proposals, where only local information is exploited and the efficiency is hindered by dense per-frame localization. In this paper, we propose Coarse-to-Fine Action Detector (CFAD),an original end-to-end trainable framework for efficient spatio-temporal action localization. The CFAD introduces a new paradigm that first estimates coarse spatio-temporal action tubes from video streams, and then refines the tubes' location based on key timestamps. This concept is implemented by two key components, the Coarse and Refine Modules in our framework. The parameterized modeling of long temporal information in the Coarse Module helps obtain accurate initial tube estimation, while the Refine Module selectively adjusts the tube location under the guidance of key timestamps. Against other methods, theproposed CFAD achieves competitive results on action detection benchmarks of UCF101-24, UCFSports and JHMDB-21 with inference speed that is 3.3x faster than the nearest competitors.
Video Question Answering on Screencast Tutorials
Aug 02, 2020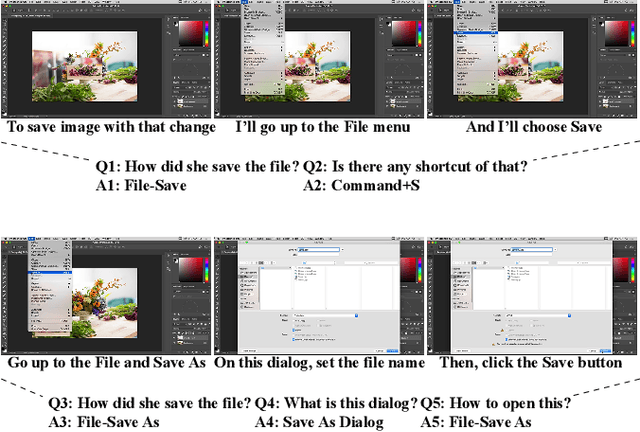
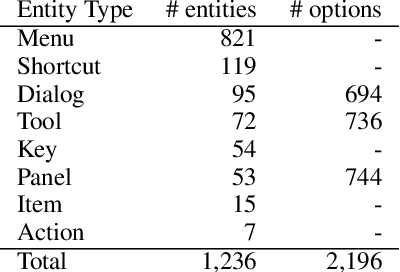
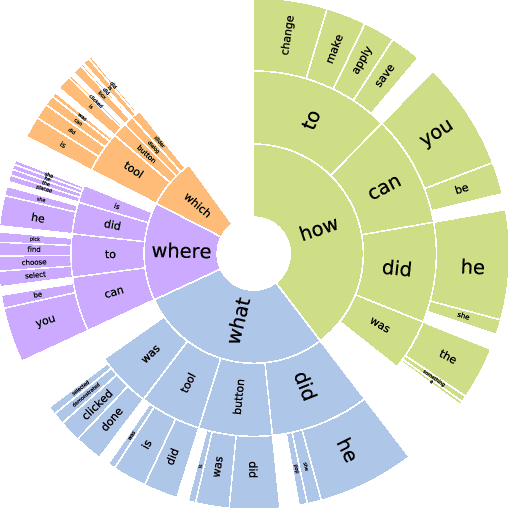
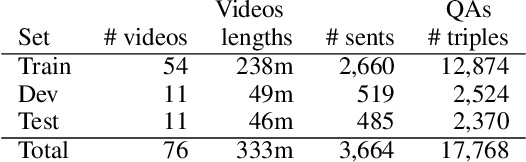
This paper presents a new video question answering task on screencast tutorials. We introduce a dataset including question, answer and context triples from the tutorial videos for a software. Unlike other video question answering works, all the answers in our dataset are grounded to the domain knowledge base. An one-shot recognition algorithm is designed to extract the visual cues, which helps enhance the performance of video question answering. We also propose several baseline neural network architectures based on various aspects of video contexts from the dataset. The experimental results demonstrate that our proposed models significantly improve the question answering performances by incorporating multi-modal contexts and domain knowledge.
Ultrahigh dimensional instrument detection using graph learning: an application to high dimensional GIS-census data for house pricing
Jul 30, 2020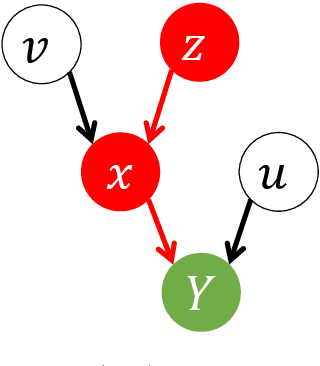
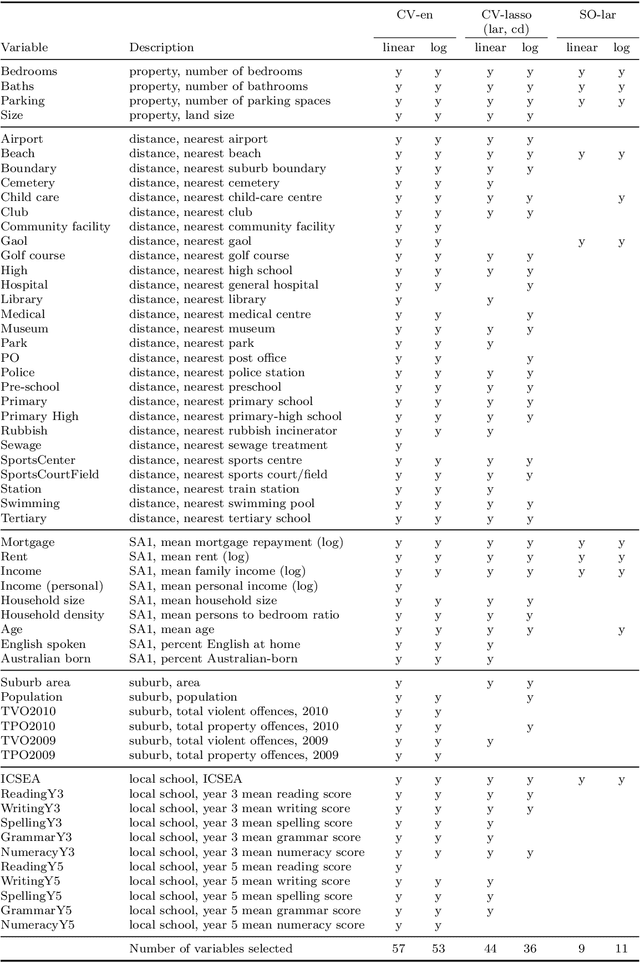
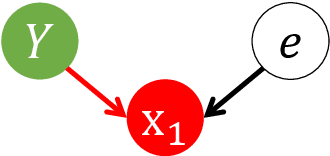
The exogeneity bias and instrument validation have always been critical topics in statistics, machine learning and biostatistics. In the era of big data, such issues typically come with dimensionality issue and, hence, require even more attention than ever. In this paper we ensemble two well-known tools from machine learning and biostatistics -- stable variable selection and random graph -- and apply them to estimating the house pricing mechanics and the follow-up socio-economic effect on the 2010 Sydney house data. The estimation is conducted on an over-200-gigabyte ultrahigh dimensional database consisting of local education data, GIS information, census data, house transaction and other socio-economic records. The technique ensemble carefully improves the variable selection sparisty, stability and robustness to high dimensionality, complicated causal structures and the consequent multicollinearity, which is ultimately helpful on the data-driven recovery of a sparse and intuitive causal structure. The new ensemble also reveals its efficiency and effectiveness on endogeneity detection, instrument validation, weak instruments pruning and selection of proper instruments. From the perspective of machine learning, the estimation result both aligns with and confirms the facts of Sydney house market, the classical economic theories and the previous findings of simultaneous equations modeling. Moreover, the estimation result is totally consistent with and supported by the classical econometric tool like two-stage least square regression and different instrument tests (the code can be found at https://github.com/isaac2math/solar_graph_learning).
Solar: a least-angle regression for accurate and stable variable selection in high-dimensional data
Jul 30, 2020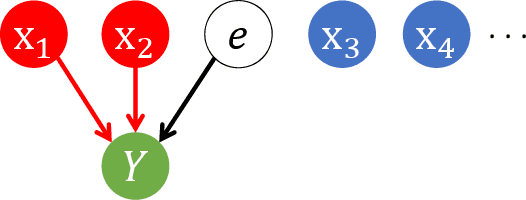

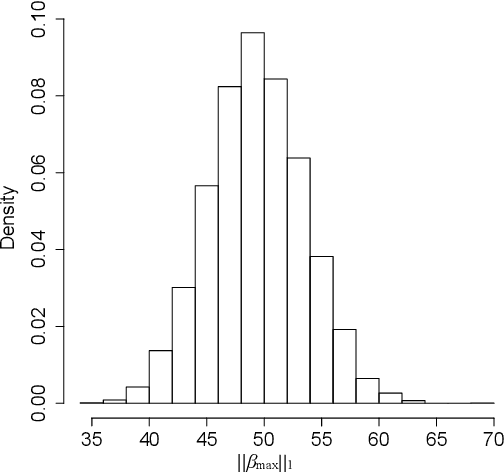
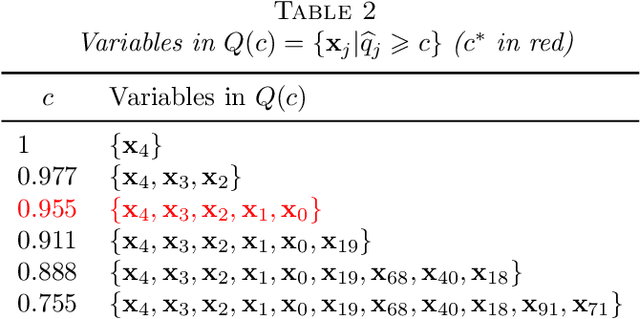
We propose a new least-angle regression algorithm for variable selection in high-dimensional data, called \emph{subsample-ordered least-angle regression (solar)}. Solar relies on the average $L_0$ solution path computed across subsamples and largely alleviates several known high-dimensional issues with least-angle regression. Using examples based on directed acyclic graphs, we illustrate the advantages of solar in comparison to least-angle regression, forward regression and variable screening. Simulations demonstrate that, with a similar computation load, solar yields substantial improvements over two lasso solvers (least-angle regression for lasso and coordinate-descent) in terms of the sparsity (37-64\% reduction in the average number of selected variables), stability and accuracy of variable selection. Simulations also demonstrate that solar enhances the robustness of variable selection to different settings of the irrepresentable condition and to variations in the dependence structures assumed in regression analysis. We provide a Python package \texttt{solarpy} for the algorithm.
Accuracy and stability of solar variable selection comparison under complicated dependence structures
Jul 30, 2020
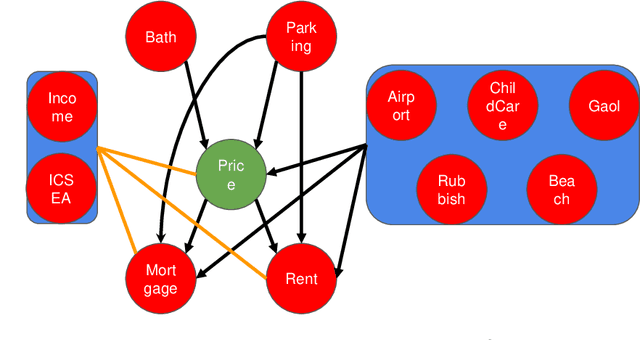
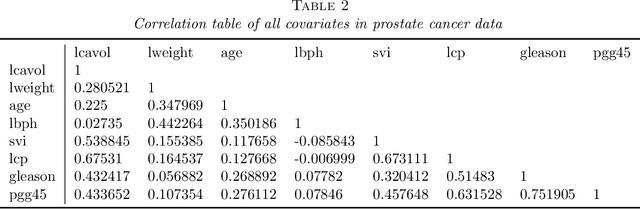

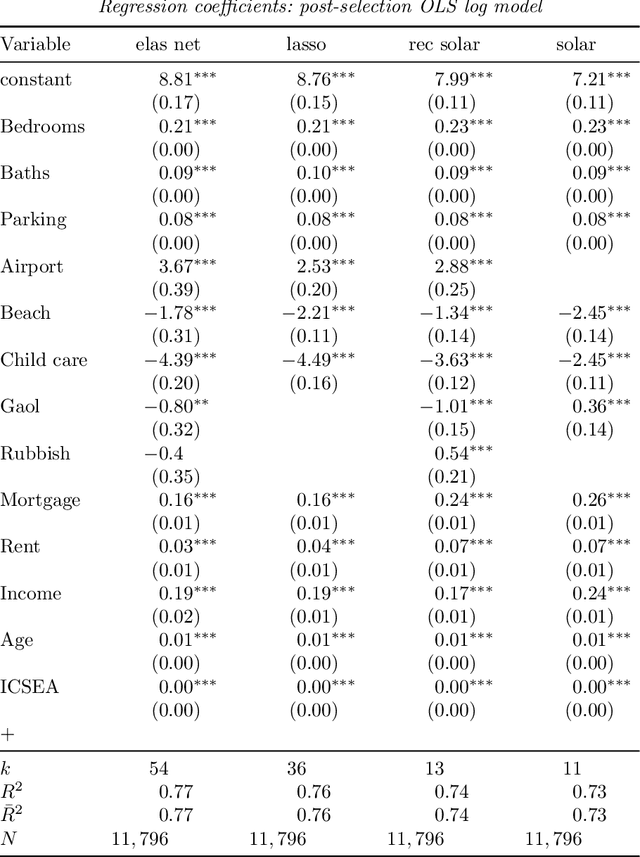
In this paper we focus on the variable-selection peformance of solar on the empirical data with complicated dependence structures and, hence, severe multicollinearity and grouping effect issues. We choose the prostate cancer data and the Sydney house price data and apply two lasso solvers, elastic net and solar on them (code can be found at \url{https://github.com/isaac2math/}). The results shows that (i) lasso is affected by the grouping effect and randomly drop variables with high correlations, resulting unreliable and uninterpretable results; (ii) elastic net is more robust to grouping effect; however, it completely lose variable-selection sparsity when the dependence structure of the data is complicated; (iii) solar demonstrates its superior robustness to complicated dependence structures and grouping effect, returning variable-selection results with better stability and sparsity. Also, such stability and sparsity make solar a reliable variable pre-estimation filter of a linear dependence structure esimation (linear probablistic graph learning). The linear probablistic graph estimated on the variable selected by solar returns an intuitive, sparse and stable dependence structure.
Rademacher upper bounds for cross-validation errors with an application to the lasso
Jul 30, 2020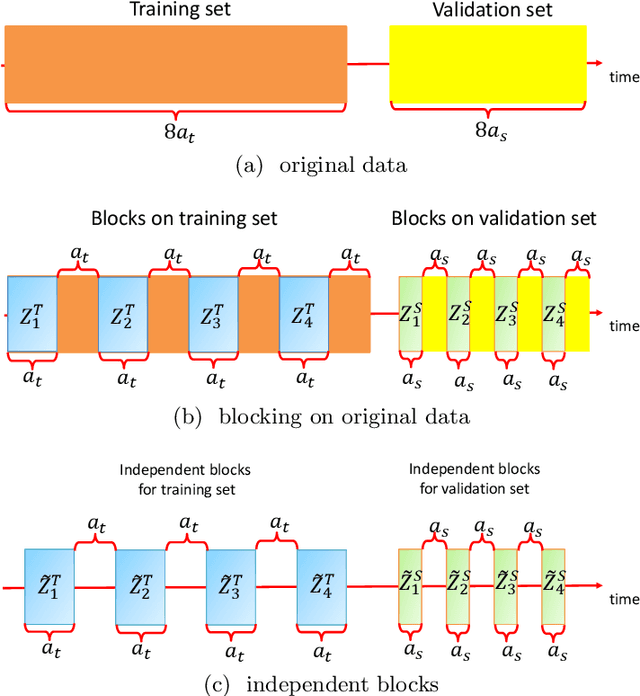
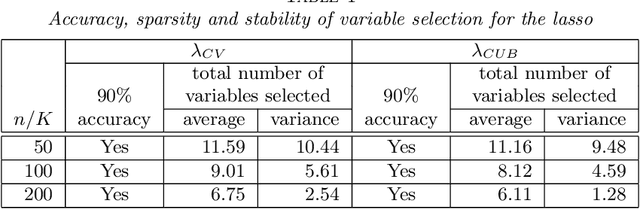
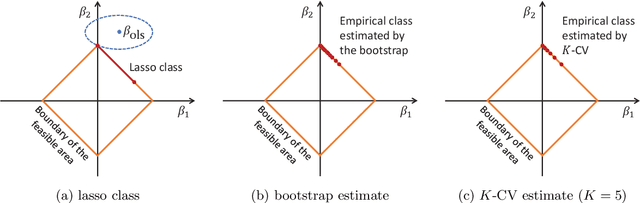
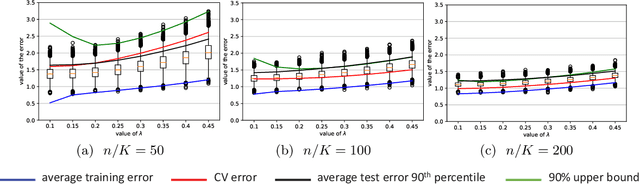
We establish a general upper bound for $K$-fold cross-validation ($K$-CV) errors that can be adapted to many $K$-CV-based estimators and learning algorithms. Based on Rademacher complexity of the model and the Orlicz-$\Psi_{\nu}$ norm of the error process, the CV error upper bound applies to both light-tail and heavy-tail error distributions. We also extend the CV error upper bound to $\beta$-mixing data using the technique of independent blocking. We provide a Python package (\texttt{CVbound}, \url{https://github.com/isaac2math}) for computing the CV error upper bound in $K$-CV-based algorithms. Using the lasso as an example, we demonstrate in simulations that the upper bounds are tight and stable across different parameter settings and random seeds. As well as accurately bounding the CV errors for the lasso, the minimizer of the new upper bounds can be used as a criterion for variable selection. Compared with the CV-error minimizer, simulations show that tuning the lasso penalty parameter according to the minimizer of the upper bound yields a more sparse and more stable model that retains all of the relevant variables.
Incorporating Reinforced Adversarial Learning in Autoregressive Image Generation
Jul 20, 2020
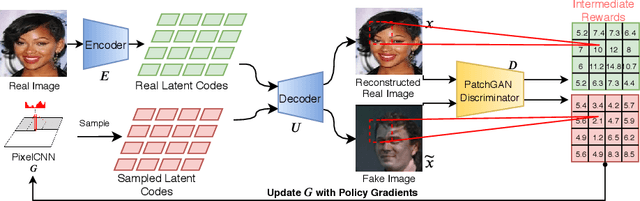


Autoregressive models recently achieved comparable results versus state-of-the-art Generative Adversarial Networks (GANs) with the help of Vector Quantized Variational AutoEncoders (VQ-VAE). However, autoregressive models have several limitations such as exposure bias and their training objective does not guarantee visual fidelity. To address these limitations, we propose to use Reinforced Adversarial Learning (RAL) based on policy gradient optimization for autoregressive models. By applying RAL, we enable a similar process for training and testing to address the exposure bias issue. In addition, visual fidelity has been further optimized with adversarial loss inspired by their strong counterparts: GANs. Due to the slow sampling speed of autoregressive models, we propose to use partial generation for faster training. RAL also empowers the collaboration between different modules of the VQ-VAE framework. To our best knowledge, the proposed method is first to enable adversarial learning in autoregressive models for image generation. Experiments on synthetic and real-world datasets show improvements over the MLE trained models. The proposed method improves both negative log-likelihood (NLL) and Fr\'echet Inception Distance (FID), which indicates improvements in terms of visual quality and diversity. The proposed method achieves state-of-the-art results on Celeba for 64 $\times$ 64 image resolution, showing promise for large scale image generation.
Multiple Sound Sources Localization from Coarse to Fine
Jul 14, 2020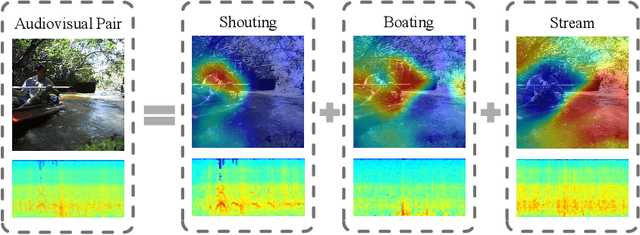
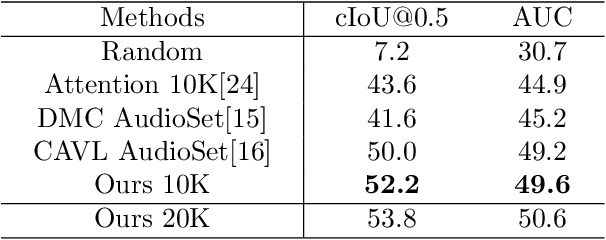


How to visually localize multiple sound sources in unconstrained videos is a formidable problem, especially when lack of the pairwise sound-object annotations. To solve this problem, we develop a two-stage audiovisual learning framework that disentangles audio and visual representations of different categories from complex scenes, then performs cross-modal feature alignment in a coarse-to-fine manner. Our model achieves state-of-the-art results on public dataset of localization, as well as considerable performance on multi-source sound localization in complex scenes. We then employ the localization results for sound separation and obtain comparable performance to existing methods. These outcomes demonstrate our model's ability in effectively aligning sounds with specific visual sources. Code is available at https://github.com/shvdiwnkozbw/Multi-Source-Sound-Localization
AOWS: Adaptive and optimal network width search with latency constraints
May 21, 2020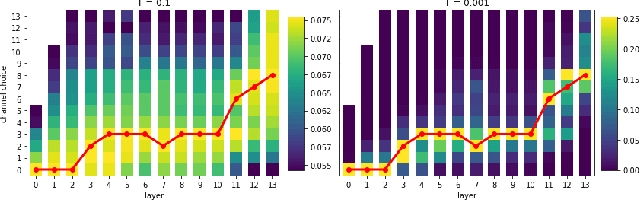
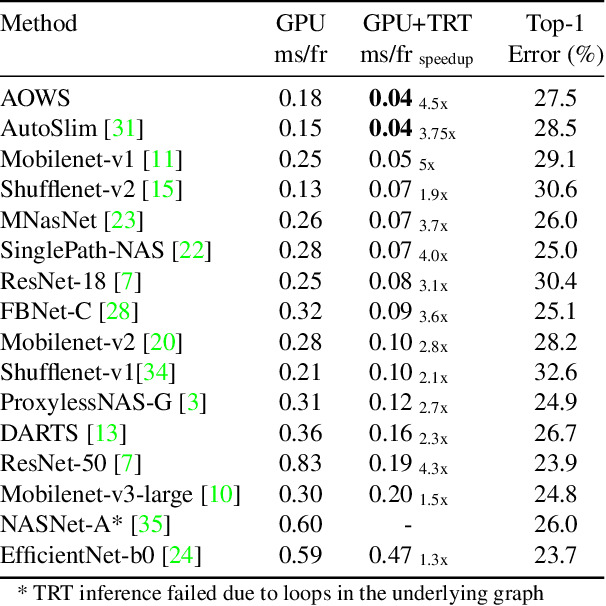
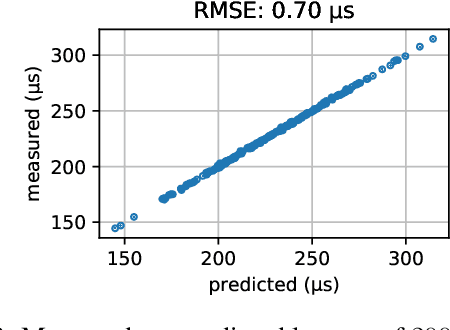
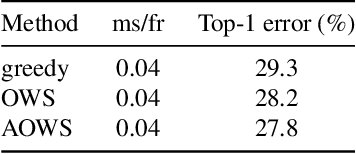
Neural architecture search (NAS) approaches aim at automatically finding novel CNN architectures that fit computational constraints while maintaining a good performance on the target platform. We introduce a novel efficient one-shot NAS approach to optimally search for channel numbers, given latency constraints on a specific hardware. We first show that we can use a black-box approach to estimate a realistic latency model for a specific inference platform, without the need for low-level access to the inference computation. Then, we design a pairwise MRF to score any channel configuration and use dynamic programming to efficiently decode the best performing configuration, yielding an optimal solution for the network width search. Finally, we propose an adaptive channel configuration sampling scheme to gradually specialize the training phase to the target computational constraints. Experiments on ImageNet classification show that our approach can find networks fitting the resource constraints on different target platforms while improving accuracy over the state-of-the-art efficient networks.
Human in Events: A Large-Scale Benchmark for Human-centric Video Analysis in Complex Events
May 19, 2020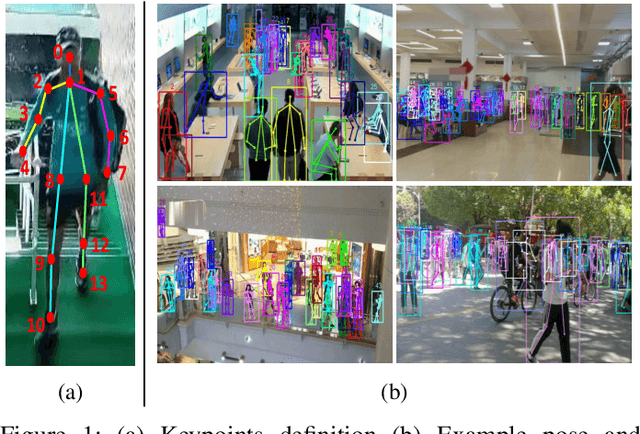
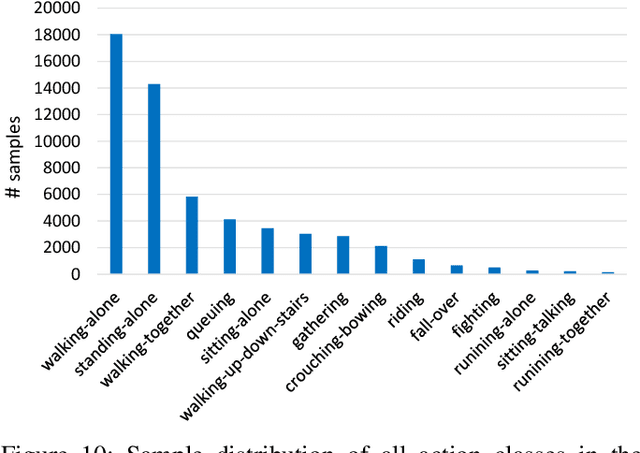
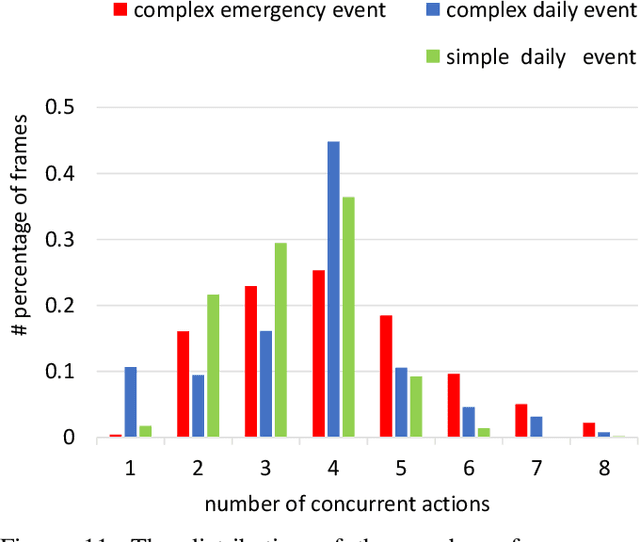
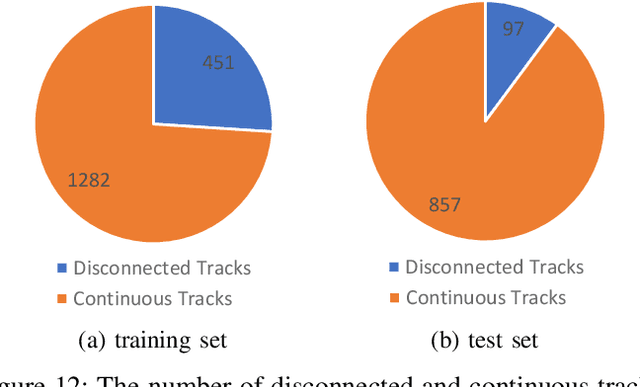
Along with the development of the modern smart city, human-centric video analysis is encountering the challenge of diverse and complex events in real scenes. A complex event relates to dense crowds, anomalous individual, or collective behavior. However, limited by the scale of available surveillance video datasets, few existing human analysis approaches report their performances on such complex events. To this end, we present a new large-scale dataset, named Human-in-Events or HiEve (human-centric video analysis in complex events), for understanding human motions, poses, and actions in a variety of realistic events, especially crowd & complex events. It contains a record number of poses (>1M), the largest number of action labels (>56k) for complex events, and one of the largest number of trajectories lasting for long terms (with average trajectory length >480). Besides, an online evaluation server is built for researchers to evaluate their approaches. Furthermore, we conduct extensive experiments on recent video analysis approaches, demonstrating that the HiEve is a challenging dataset for human-centric video analysis. We expect that the dataset will advance the development of cutting-edge techniques in human-centric analysis and the understanding of complex events. The dataset is available at http://humaninevents.org