 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashionSearchNet-v2: Learning Attribute Representations with Localization for Image Retrieval with Attribute Manipulation
Nov 28, 2021
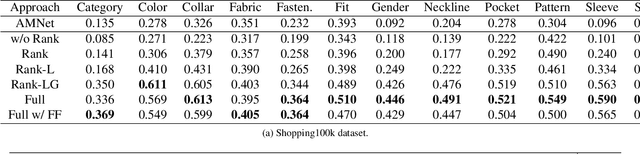
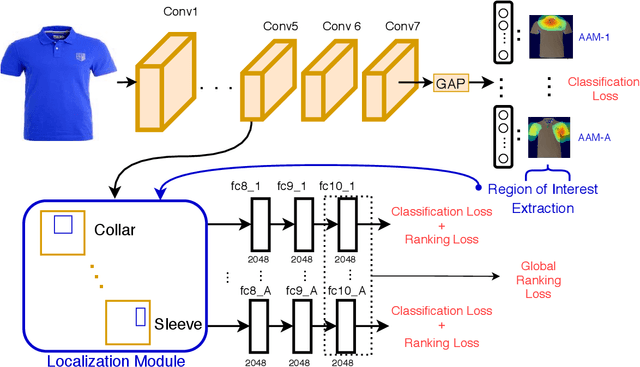
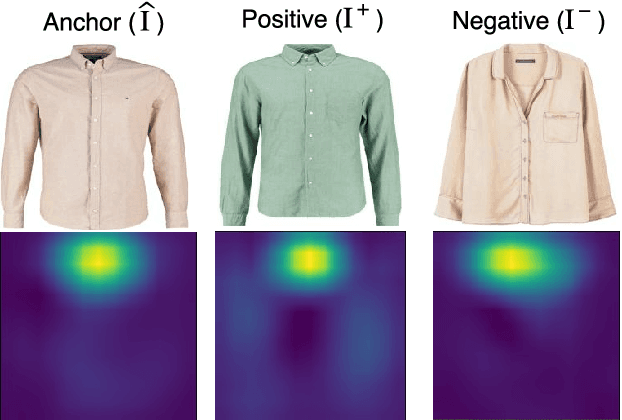
The focus of this paper is on the problem of image retrieval with attribute manipulation. Our proposed work is able to manipulate the desired attributes of the query image while maintaining its other attributes. For example, the collar attribute of the query image can be changed from round to v-neck to retrieve similar images from a large dataset. A key challenge in e-commerce is that images have multiple attributes where users would like to manipulate and it is important to estimate discriminative feature representations for each of these attributes. The proposed FashionSearchNet-v2 architecture is able to learn attribute specific representations by leveraging on its weakly-supervised localization module, which ignores the unrelated features of attributes in the feature space, thus improving the similarity learning. The network is jointly trained with the combination of attribute classification and triplet ranking loss to estimate local representations. These local representations are then merged into a single global representation based on the instructed attribute manipulation where desired images can be retrieved with a distance metric. The proposed method also provides explainability for its retrieval process to help provide additional information on the attention of the network. Experiments performed on several datasets that are rich in terms of the number of attributes show that FashionSearchNet-v2 outperforms the other state-of-the-art attribute manipulation techniques. Different than our earlier work (FashionSearchNet), we propose several improvements in the learning procedure and show that the proposed FashionSearchNet-v2 can be generalized to different domains other than fashion.
Incorporating Reinforced Adversarial Learning in Autoregressive Image Generation
Jul 20, 2020
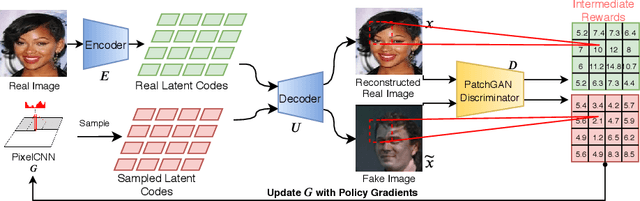


Autoregressive models recently achieved comparable results versus state-of-the-art Generative Adversarial Networks (GANs) with the help of Vector Quantized Variational AutoEncoders (VQ-VAE). However, autoregressive models have several limitations such as exposure bias and their training objective does not guarantee visual fidelity. To address these limitations, we propose to use Reinforced Adversarial Learning (RAL) based on policy gradient optimization for autoregressive models. By applying RAL, we enable a similar process for training and testing to address the exposure bias issue. In addition, visual fidelity has been further optimized with adversarial loss inspired by their strong counterparts: GANs. Due to the slow sampling speed of autoregressive models, we propose to use partial generation for faster training. RAL also empowers the collaboration between different modules of the VQ-VAE framework. To our best knowledge, the proposed method is first to enable adversarial learning in autoregressive models for image generation. Experiments on synthetic and real-world datasets show improvements over the MLE trained models. The proposed method improves both negative log-likelihood (NLL) and Fr\'echet Inception Distance (FID), which indicates improvements in terms of visual quality and diversity. The proposed method achieves state-of-the-art results on Celeba for 64 $\times$ 64 image resolution, showing promise for large scale image generation.