 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-body SE(3) Equivariance for Unsupervised Rigid Segmentation and Motion Estimation
Jun 08, 2023A truly generalizable approach to rigid segmentation and motion estimation is fundamental to 3D understanding of articulated objects and moving scenes. In view of the tightly coupled relationship between segmentation and motion estimates, we present an SE(3) equivariant architecture and a training strategy to tackle this task in an unsupervised manner. Our architecture comprises two lightweight and inter-connected heads that predict segmentation masks using point-level invariant features and motion estimates from SE(3) equivariant features without the prerequisites of category information. Our unified training strategy can be performed online while jointly optimizing the two predictions by exploiting the interrelations among scene flow, segmentation mask, and rigid transformations. We show experiments on four datasets as evidence of the superiority of our method both in terms of model performance and computational efficiency with only 0.25M parameters and 0.92G FLOPs. To the best of our knowledge, this is the first work designed for category-agnostic part-level SE(3) equivariance in dynamic point clouds.
Fusion of Radio and Camera Sensor Data for Accurate Indoor Positioning
Feb 01, 2023



Indoor positioning systems have received a lot of attention recently due to their importance for many location-based services, e.g. indoor navigation and smart buildings. Lightweight solutions based on WiFi and inertial sensing have gained popularity, but are not fit for demanding applications, such as expert museum guides and industrial settings, which typically require sub-meter location information. In this paper, we propose a novel positioning system, RAVEL (Radio And Vision Enhanced Localization), which fuses anonymous visual detections captured by widely available camera infrastructure, with radio readings (e.g. WiFi radio data). Although visual trackers can provide excellent positioning accuracy, they are plagued by issues such as occlusions and people entering/exiting the scene, preventing their use as a robust tracking solution. By incorporating radio measurements, visually ambiguous or missing data can be resolved through multi-hypothesis tracking. We evaluate our system in a complex museum environment with dim lighting and multiple people moving around in a space cluttered with exhibit stands. Our experiments show that although the WiFi measurements are not by themselves sufficiently accurate, when they are fused with camera data, they become a catalyst for pulling together ambiguous, fragmented, and anonymous visual tracklets into accurate and continuous paths, yielding typical errors below 1 meter.
Tracking People in Highly Dynamic Industrial Environments
Feb 01, 2023



To date, the majority of positioning systems have been designed to operate within environments that have long-term stable macro-structure with potential small-scale dynamics. These assumptions allow the existing positioning systems to produce and utilize stable maps. However, in highly dynamic industrial settings these assumptions are no longer valid and the task of tracking people is more challenging due to the rapid large-scale changes in structure. In this paper we propose a novel positioning system for tracking people in highly dynamic industrial environments, such as construction sites. The proposed system leverages the existing CCTV camera infrastructure found in many industrial settings along with radio and inertial sensors within each worker's mobile phone to accurately track multiple people. This multi-target multi-sensor tracking framework also allows our system to use cross-modality training in order to deal with the environment dynamics. In particular, we show how our system uses cross-modality training in order to automatically keep track environmental changes (i.e. new walls) by utilizing occlusion maps. In addition, we show how these maps can be used in conjunction with social forces to accurately predict human motion and increase the tracking accuracy. We have conducted extensive real-world experiments in a construction site showing significant accuracy improvement via cross-modality training and the use of social forces.
Sample, Crop, Track: Self-Supervised Mobile 3D Object Detection for Urban Driving LiDAR
Sep 21, 2022
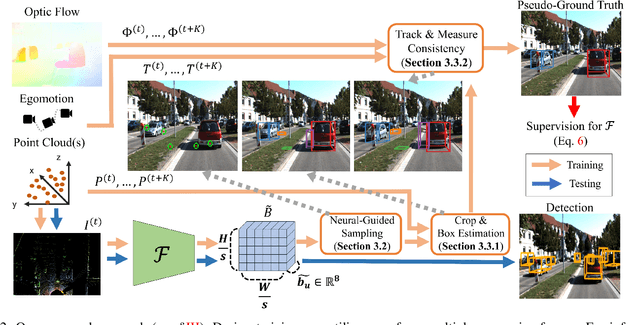
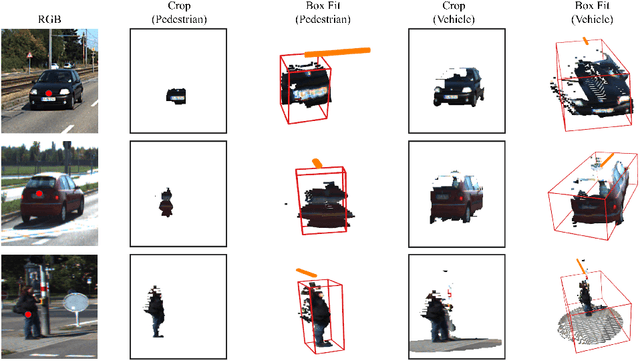
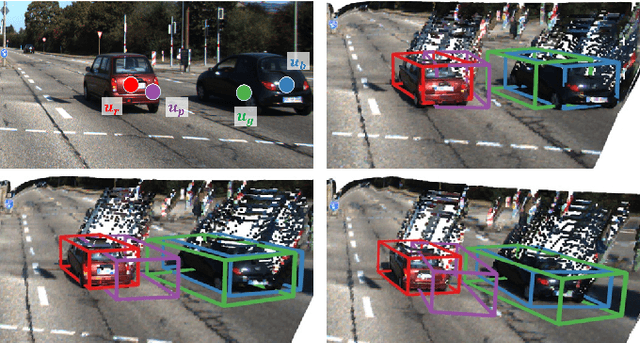
Deep learning has led to great progress in the detection of mobile (i.e. movement-capable) objects in urban driving scenes in recent years. Supervised approaches typically require the annotation of large training sets; there has thus been great interest in leveraging weakly, semi- or self-supervised methods to avoid this, with much success. Whilst weakly and semi-supervised methods require some annotation, self-supervised methods have used cues such as motion to relieve the need for annotation altogether. However, a complete absence of annotation typically degrades their performance, and ambiguities that arise during motion grouping can inhibit their ability to find accurate object boundaries. In this paper, we propose a new self-supervised mobile object detection approach called SCT. This uses both motion cues and expected object sizes to improve detection performance, and predicts a dense grid of 3D oriented bounding boxes to improve object discovery. We significantly outperform the state-of-the-art self-supervised mobile object detection method TCR on the KITTI tracking benchmark, and achieve performance that is within 30% of the fully supervised PV-RCNN++ method for IoUs <= 0.5.
When the Sun Goes Down: Repairing Photometric Losses for All-Day Depth Estimation
Jun 28, 2022
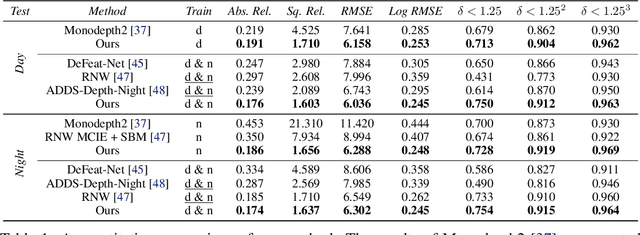
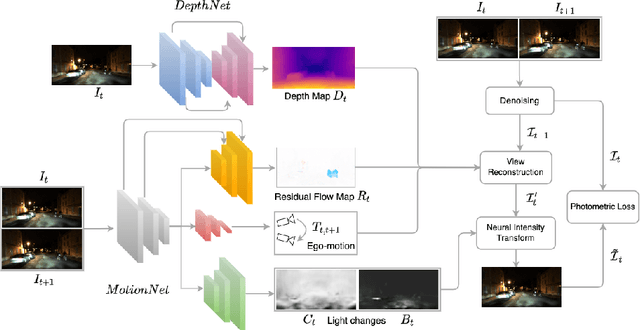
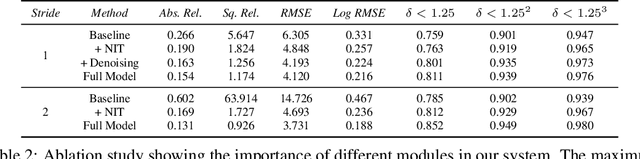
Self-supervised deep learning methods for joint depth and ego-motion estimation can yield accurate trajectories without needing ground-truth training data. However, as they typically use photometric losses, their performance can degrade significantly when the assumptions these losses make (e.g. temporal illumination consistency, a static scene, and the absence of noise and occlusions) are violated. This limits their use for e.g. nighttime sequences, which tend to contain many point light sources (including on dynamic objects) and low signal-to-noise ratio (SNR) in darker image regions. In this paper, we show how to use a combination of three techniques to allow the existing photometric losses to work for both day and nighttime images. First, we introduce a per-pixel neural intensity transformation to compensate for the light changes that occur between successive frames. Second, we predict a per-pixel residual flow map that we use to correct the reprojection correspondences induced by the estimated ego-motion and depth from the networks. And third, we denoise the training images to improve the robustness and accuracy of our approach. These changes allow us to train a single model for both day and nighttime images without needing separate encoders or extra feature networks like existing methods. We perform extensive experiments and ablation studies on the challenging Oxford RobotCar dataset to demonstrate the efficacy of our approach for both day and nighttime sequences.
RangeUDF: Semantic Surface Reconstruction from 3D Point Clouds
Apr 19, 2022

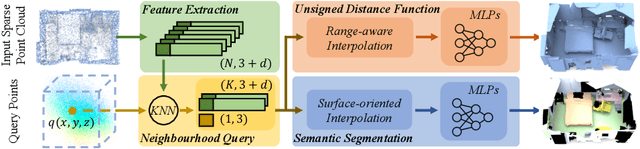
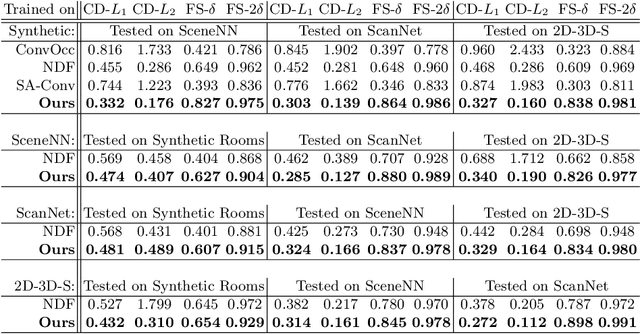
We present RangeUDF, a new implicit representation based framework to recover the geometry and semantics of continuous 3D scene surfaces from point clouds. Unlike occupancy fields or signed distance fields which can only model closed 3D surfaces, our approach is not restricted to any type of topology. Being different from the existing unsigned distance fields, our framework does not suffer from any surface ambiguity. In addition, our RangeUDF can jointly estimate precise semantics for continuous surfaces. The key to our approach is a range-aware unsigned distance function together with a surface-oriented semantic segmentation module. Extensive experiments show that RangeUDF clearly surpasses state-of-the-art approaches for surface reconstruction on four point cloud datasets. Moreover, RangeUDF demonstrates superior generalization capability across multiple unseen datasets, which is nearly impossible for all existing approaches.
Meta-Sampler: Almost-Universal yet Task-Oriented Sampling for Point Clouds
Mar 30, 2022Sampling is a key operation in point-cloud task and acts to increase computational efficiency and tractability by discarding redundant points. Universal sampling algorithms (e.g., Farthest Point Sampling) work without modification across different tasks, models, and datasets, but by their very nature are agnostic about the downstream task/model. As such, they have no implicit knowledge about which points would be best to keep and which to reject. Recent work has shown how task-specific point cloud sampling (e.g., SampleNet) can be used to outperform traditional sampling approaches by learning which points are more informative. However, these learnable samplers face two inherent issues: i) overfitting to a model rather than a task, and \ii) requiring training of the sampling network from scratch, in addition to the task network, somewhat countering the original objective of down-sampling to increase efficiency. In this work, we propose an almost-universal sampler, in our quest for a sampler that can learn to preserve the most useful points for a particular task, yet be inexpensive to adapt to different tasks, models, or datasets. We first demonstrate how training over multiple models for the same task (e.g., shape reconstruction) significantly outperforms the vanilla SampleNet in terms of accuracy by not overfitting the sample network to a particular task network. Second, we show how we can train an almost-universal meta-sampler across multiple tasks. This meta-sampler can then be rapidly fine-tuned when applied to different datasets, networks, or even different tasks, thus amortizing the initial cost of training.
No Pain, Big Gain: Classify Dynamic Point Cloud Sequences with Static Models by Fitting Feature-level Space-time Surfaces
Mar 23, 2022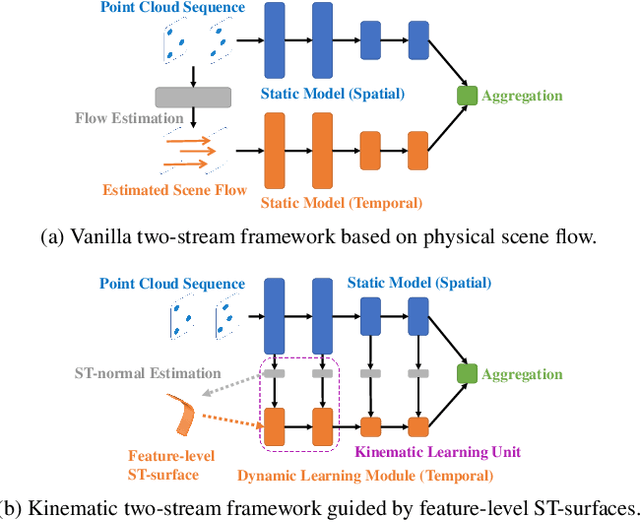
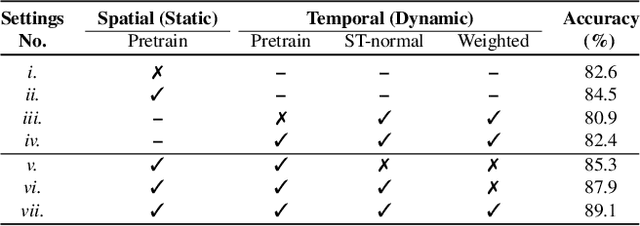
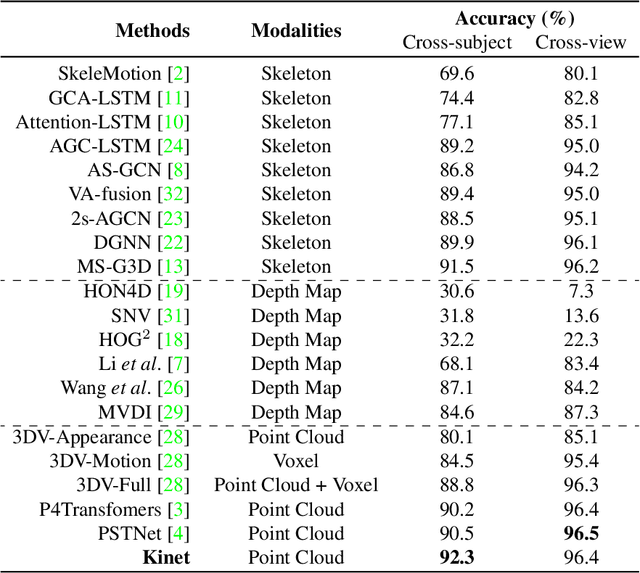
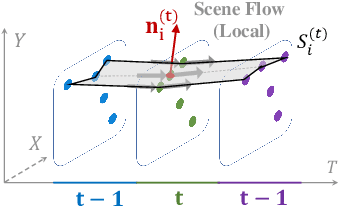
Scene flow is a powerful tool for capturing the motion field of 3D point clouds. However, it is difficult to directly apply flow-based models to dynamic point cloud classification since the unstructured points make it hard or even impossible to efficiently and effectively trace point-wise correspondences. To capture 3D motions without explicitly tracking correspondences, we propose a kinematics-inspired neural network (Kinet) by generalizing the kinematic concept of ST-surfaces to the feature space. By unrolling the normal solver of ST-surfaces in the feature space, Kinet implicitly encodes feature-level dynamics and gains advantages from the use of mature backbones for static point cloud processing. With only minor changes in network structures and low computing overhead, it is painless to jointly train and deploy our framework with a given static model. Experiments on NvGesture, SHREC'17, MSRAction-3D, and NTU-RGBD demonstrate its efficacy in performance, efficiency in both the number of parameters and computational complexity, as well as its versatility to various static backbones. Noticeably, Kinet achieves the accuracy of 93.27% on MSRAction-3D with only 3.20M parameters and 10.35G FLOPS.
Real-Time Hybrid Mapping of Populated Indoor Scenes using a Low-Cost Monocular UAV
Mar 04, 2022
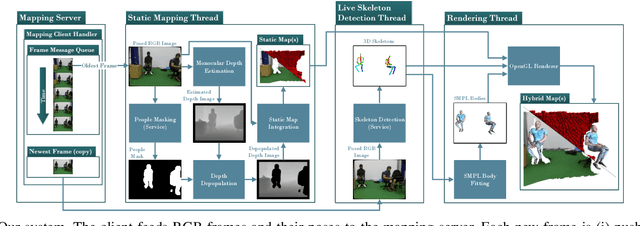
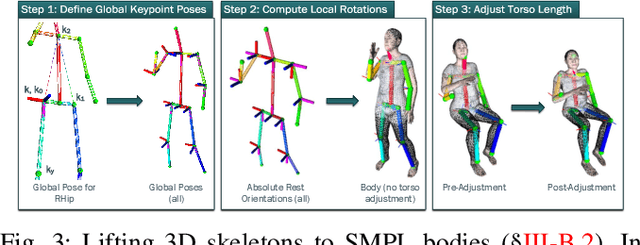
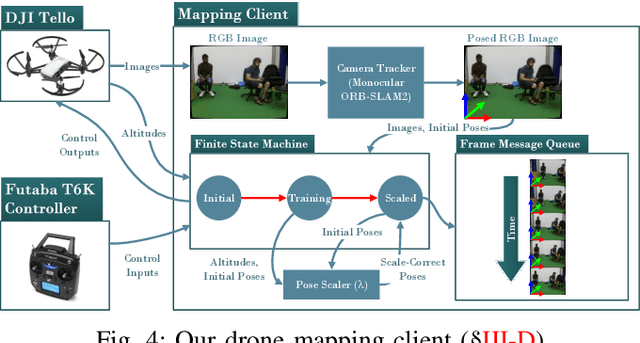
Unmanned aerial vehicles (UAVs) have been used for many applications in recent years, from urban search and rescue, to agricultural surveying, to autonomous underground mine exploration. However, deploying UAVs in tight, indoor spaces, especially close to humans, remains a challenge. One solution, when limited payload is required, is to use micro-UAVs, which pose less risk to humans and typically cost less to replace after a crash. However, micro-UAVs can only carry a limited sensor suite, e.g. a monocular camera instead of a stereo pair or LiDAR, complicating tasks like dense mapping and markerless multi-person 3D human pose estimation, which are needed to operate in tight environments around people. Monocular approaches to such tasks exist, and dense monocular mapping approaches have been successfully deployed for UAV applications. However, despite many recent works on both marker-based and markerless multi-UAV single-person motion capture, markerless single-camera multi-person 3D human pose estimation remains a much earlier-stage technology, and we are not aware of existing attempts to deploy it in an aerial context. In this paper, we present what is thus, to our knowledge, the first system to perform simultaneous mapping and multi-person 3D human pose estimation from a monocular camera mounted on a single UAV. In particular, we show how to loosely couple state-of-the-art monocular depth estimation and monocular 3D human pose estimation approaches to reconstruct a hybrid map of a populated indoor scene in real time. We validate our component-level design choices via extensive experiments on the large-scale ScanNet and GTA-IM datasets. To evaluate our system-level performance, we also construct a new Oxford Hybrid Mapping dataset of populated indoor scenes.
SensatUrban: Learning Semantics from Urban-Scale Photogrammetric Point Clouds
Jan 12, 2022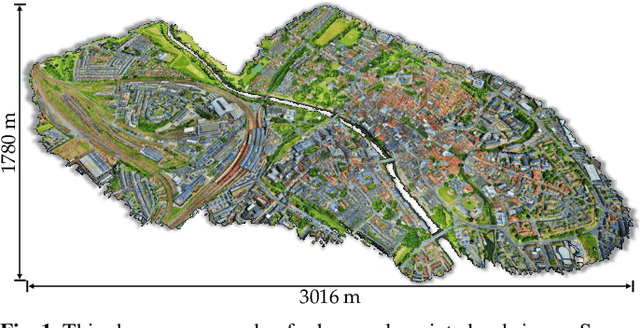
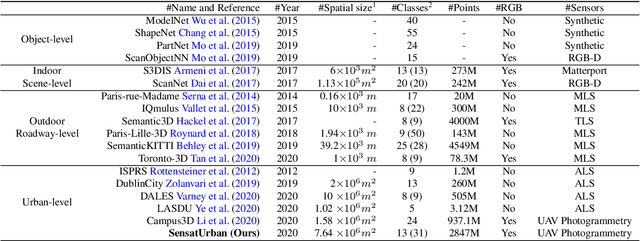
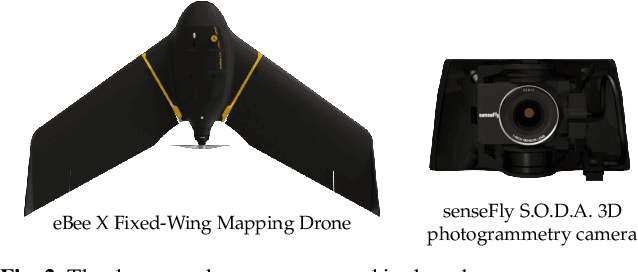

With the recent availability and affordability of commercial depth sensors and 3D scanners, an increasing number of 3D (i.e., RGBD, point cloud) datasets have been publicized to facilitate research in 3D computer vision. However, existing datasets either cover relatively small areas or have limited semantic annotations. Fine-grained understanding of urban-scale 3D scenes is still in its infancy. In this paper, we introduce SensatUrban, an urban-scale UAV photogrammetry point cloud dataset consisting of nearly three billion points collected from three UK cities, covering 7.6 km^2. Each point in the dataset has been labelled with fine-grained semantic annotations, resulting in a dataset that is three times the size of the previous existing largest photogrammetric point cloud dataset. In addition to the more commonly encountered categories such as road and vegetation, urban-level categories including rail, bridge, and river are also included in our dataset. Based on this dataset, we further build a benchmark to evaluate the performance of state-of-the-art segmentation algorithms. In particular, we provide a comprehensive analysis and identify several key challenges limiting urban-scale point cloud understanding. The dataset is available at http://point-cloud-analysis.cs.ox.ac.uk.