 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Transformer for Human Reaction Generation
Jul 04, 2022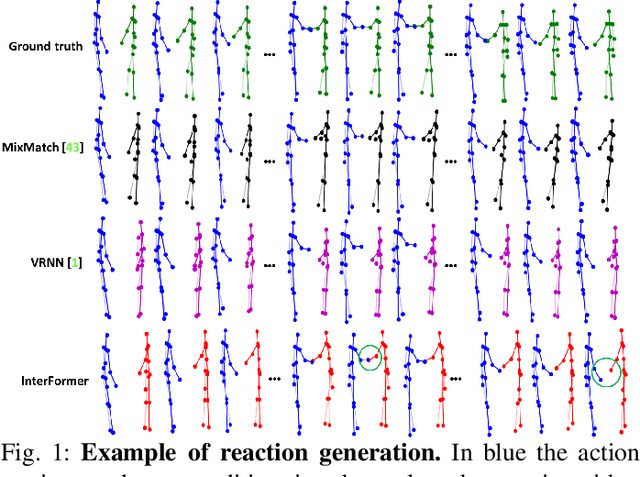
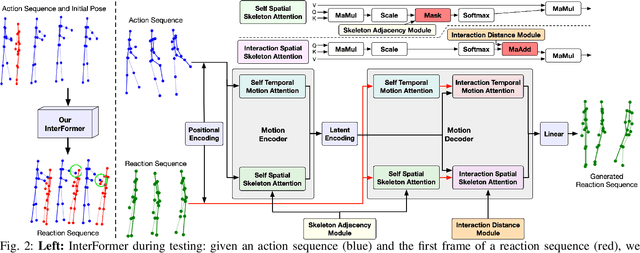
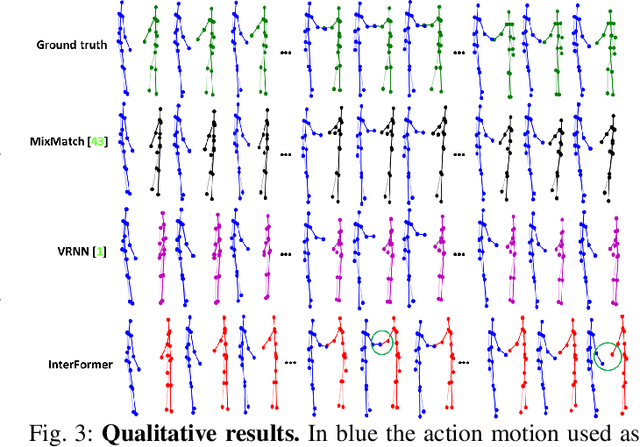
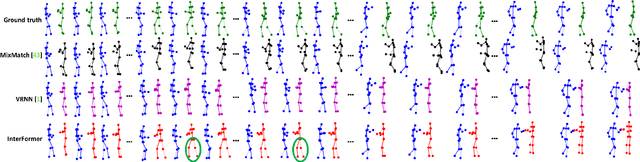
We address the challenging task of human reaction generation which aims to generate a corresponding reaction based on an input action. Most of the existing works do not focus on generating and predicting the reaction and cannot generate the motion when only the action is given as input. To address this limitation, we propose a novel interaction Transformer (InterFormer) consisting of a Transformer network with both temporal and spatial attentions. Specifically, the temporal attention captures the temporal dependencies of the motion of both characters and of their interaction, while the spatial attention learns the dependencies between the different body parts of each character and those which are part of the interaction. Moreover, we propose using graphs to increase the performance of the spatial attention via an interaction distance module that helps focus on nearby joints from both characters. Extensive experiments on the SBU interaction, K3HI, and DuetDance datasets demonstrate the effectiveness of InterFormer. Our method is general and can be used to generate more complex and long-term interactions.
Unsupervised High-Resolution Portrait Gaze Correction and Animation
Jul 01, 2022



This paper proposes a gaze correction and animation method for high-resolution, unconstrained portrait images, which can be trained without the gaze angle and the head pose annotations. Common gaze-correction methods usually require annotating training data with precise gaze, and head pose information. Solving this problem using an unsupervised method remains an open problem, especially for high-resolution face images in the wild, which are not easy to annotate with gaze and head pose labels. To address this issue, we first create two new portrait datasets: CelebGaze and high-resolution CelebHQGaze. Second, we formulate the gaze correction task as an image inpainting problem, addressed using a Gaze Correction Module (GCM) and a Gaze Animation Module (GAM). Moreover, we propose an unsupervised training strategy, i.e., Synthesis-As-Training, to learn the correlation between the eye region features and the gaze angle. As a result, we can use the learned latent space for gaze animation with semantic interpolation in this space. Moreover, to alleviate both the memory and the computational costs in the training and the inference stage, we propose a Coarse-to-Fine Module (CFM) integrated with GCM and GAM. Extensive experiments validate the effectiveness of our method for both the gaze correction and the gaze animation tasks in both low and high-resolution face datasets in the wild and demonstrate the superiority of our method with respect to the state of the arts. Code is available at https://github.com/zhangqianhui/GazeAnimationV2
Spatial Entropy Regularization for Vision Transformers
Jun 09, 2022

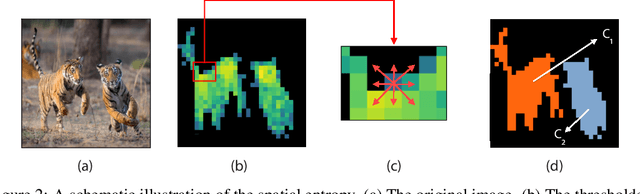
Recent work has shown that the attention maps of Vision Transformers (VTs), when trained with self-supervision, can contain a semantic segmentation structure which does not spontaneously emerge when training is supervised. In this paper, we explicitly encourage the emergence of this spatial clustering as a form of training regularization, this way including a self-supervised pretext task into the standard supervised learning. In more detail, we propose a VT regularization method based on a spatial formulation of the information entropy. By minimizing the proposed spatial entropy, we explicitly ask the VT to produce spatially ordered attention maps, this way including an object-based prior during training. Using extensive experiments, we show that the proposed regularization approach is beneficial with different training scenarios, datasets, downstream tasks and VT architectures. The code will be available upon acceptance.
On the Eigenvalues of Global Covariance Pooling for Fine-grained Visual Recognition
May 26, 2022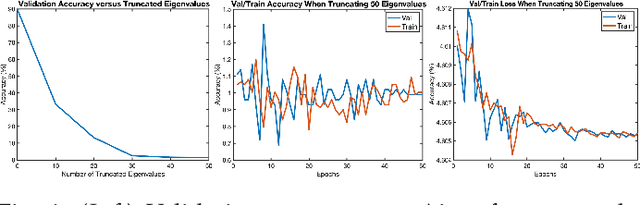

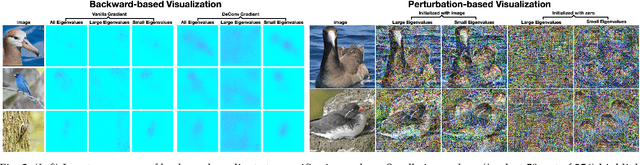
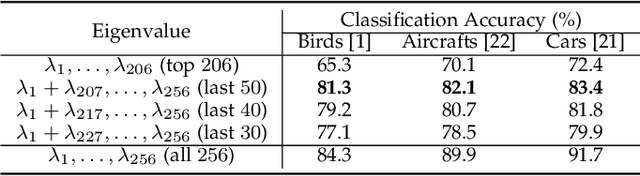
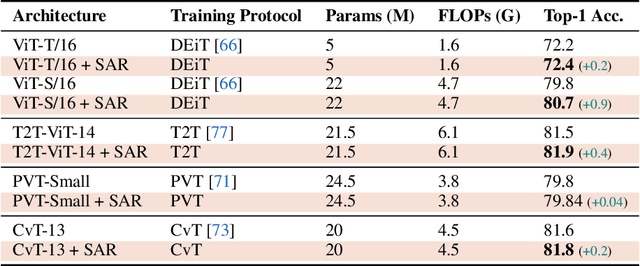
The Fine-Grained Visual Categorization (FGVC) is challenging because the subtle inter-class variations are difficult to be captured. One notable research line uses the Global Covariance Pooling (GCP) layer to learn powerful representations with second-order statistics, which can effectively model inter-class differences. In our previous conference paper, we show that truncating small eigenvalues of the GCP covariance can attain smoother gradient and improve the performance on large-scale benchmarks. However, on fine-grained datasets, truncating the small eigenvalues would make the model fail to converge. This observation contradicts the common assumption that the small eigenvalues merely correspond to the noisy and unimportant information. Consequently, ignoring them should have little influence on the performance. To diagnose this peculiar behavior, we propose two attribution methods whose visualizations demonstrate that the seemingly unimportant small eigenvalues are crucial as they are in charge of extracting the discriminative class-specific features. Inspired by this observation, we propose a network branch dedicated to magnifying the importance of small eigenvalues. Without introducing any additional parameters, this branch simply amplifies the small eigenvalues and achieves state-of-the-art performances of GCP methods on three fine-grained benchmarks. Furthermore, the performance is also competitive against other FGVC approaches on larger datasets. Code is available at \href{https://github.com/KingJamesSong/DifferentiableSVD}{https://github.com/KingJamesSong/DifferentiableSVD}.
Breaking the Chain of Gradient Leakage in Vision Transformers
May 25, 2022
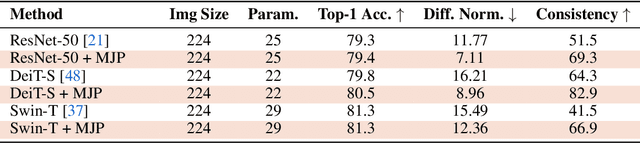
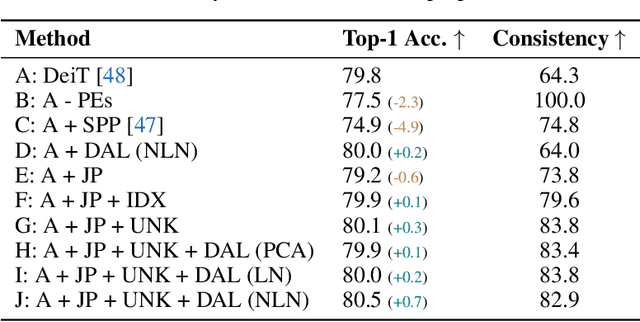
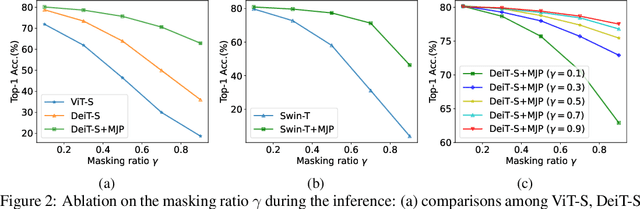
User privacy is of great concern in Federated Learning, while Vision Transformers (ViTs) have been revealed to be vulnerable to gradient-based inversion attacks. We show that the learned low-dimensional spatial prior in position embeddings (PEs) accelerates the training of ViTs. As a side effect, it makes the ViTs tend to be position sensitive and at high risk of privacy leakage. We observe that enhancing the position-insensitive property of a ViT model is a promising way to protect data privacy against these gradient attacks. However, simply removing the PEs may not only harm the convergence and accuracy of ViTs but also places the model at more severe privacy risk. To deal with the aforementioned contradiction, we propose a simple yet efficient Masked Jigsaw Puzzle (MJP) method to break the chain of gradient leakage in ViTs. MJP can be easily plugged into existing ViTs and their derived variants. Extensive experiments demonstrate that our proposed MJP method not only boosts the performance on large-scale datasets (i.e., ImageNet-1K), but can also improve the privacy preservation capacity in the typical gradient attacks by a large margin. Our code is available at: https://github.com/yhlleo/MJP.
LeRaC: Learning Rate Curriculum
May 18, 2022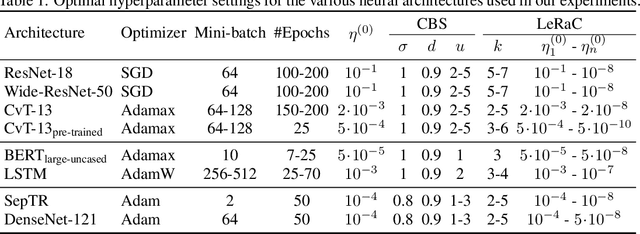
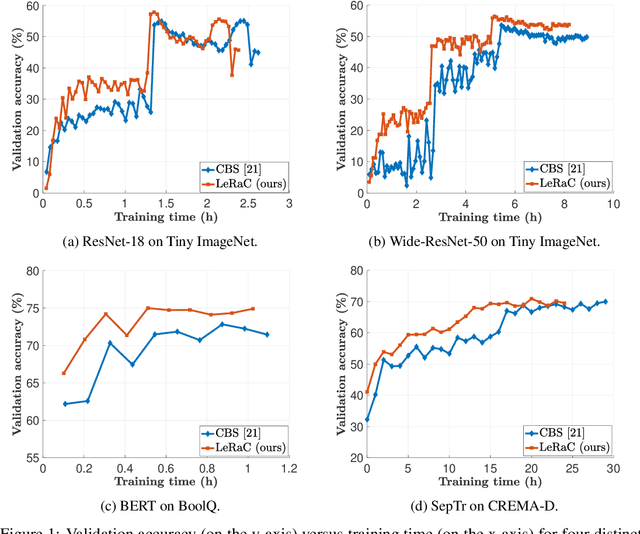
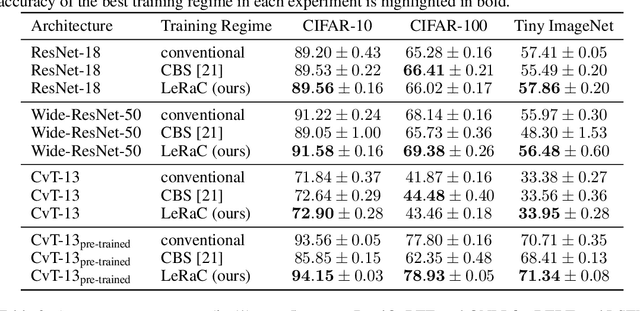
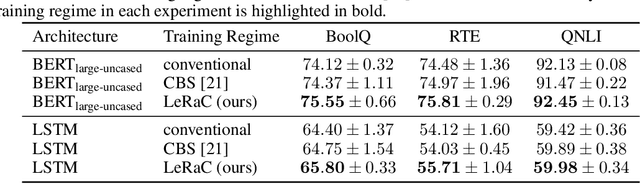
Most curriculum learning methods require an approach to sort the data samples by difficulty, which is often cumbersome to perform. In this work, we propose a novel curriculum learning approach termed Learning Rate Curriculum (LeRaC), which leverages the use of a different learning rate for each layer of a neural network to create a data-free curriculum during the initial training epochs. More specifically, LeRaC assigns higher learning rates to neural layers closer to the input, gradually decreasing the learning rates as the layers are placed farther away from the input. The learning rates increase at various paces during the first training iterations, until they all reach the same value. From this point on, the neural model is trained as usual. This creates a model-level curriculum learning strategy that does not require sorting the examples by difficulty and is compatible with any neural network, generating higher performance levels regardless of the architecture. We conduct comprehensive experiments on eight datasets from the computer vision (CIFAR-10, CIFAR-100, Tiny ImageNet), language (BoolQ, QNLI, RTE) and audio (ESC-50, CREMA-D) domains, considering various convolutional (ResNet-18, Wide-ResNet-50, DenseNet-121), recurrent (LSTM) and transformer (CvT, BERT, SepTr) architectures, comparing our approach with the conventional training regime. Moreover, we also compare with Curriculum by Smoothing (CBS), a state-of-the-art data-free curriculum learning approach. Unlike CBS, our performance improvements over the standard training regime are consistent across all datasets and models. Furthermore, we significantly surpass CBS in terms of training time (there is no additional cost over the standard training regime for LeRaC).
Temporal Alignment for History Representation in Reinforcement Learning
Apr 07, 2022



Environments in Reinforcement Learning are usually only partially observable. To address this problem, a possible solution is to provide the agent with information about the past. However, providing complete observations of numerous steps can be excessive. Inspired by human memory, we propose to represent history with only important changes in the environment and, in our approach, to obtain automatically this representation using self-supervision. Our method (TempAl) aligns temporally-close frames, revealing a general, slowly varying state of the environment. This procedure is based on contrastive loss, which pulls embeddings of nearby observations to each other while pushing away other samples from the batch. It can be interpreted as a metric that captures the temporal relations of observations. We propose to combine both common instantaneous and our history representation and we evaluate TempAl on all available Atari games from the Arcade Learning Environment. TempAl surpasses the instantaneous-only baseline in 35 environments out of 49. The source code of the method and of all the experiments is available at https://github.com/htdt/tempal.
Style-Hallucinated Dual Consistency Learning for Domain Generalized Semantic Segmentation
Apr 06, 2022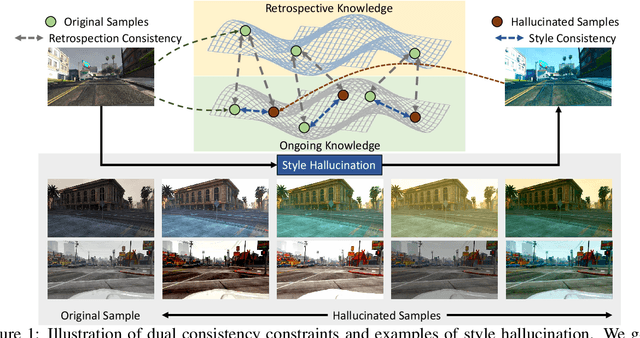
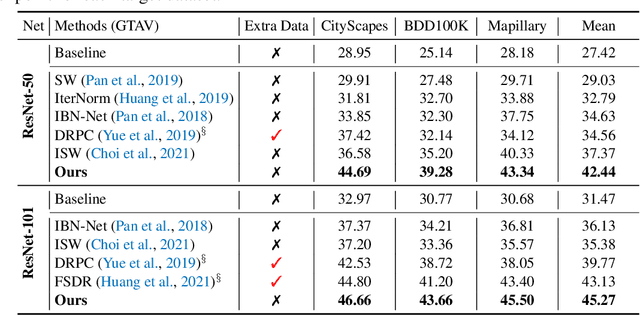
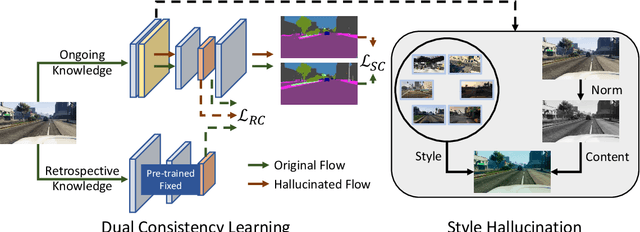
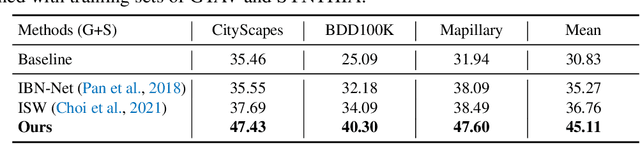
In this paper, we study the task of synthetic-to-real domain generalized semantic segmentation, which aims to learn a model that is robust to unseen real-world scenes using only synthetic data. The large domain shift between synthetic and real-world data, including the limited source environmental variations and the large distribution gap between synthetic and real-world data, significantly hinders the model performance on unseen real-world scenes. In this work, we propose the Style-HAllucinated Dual consistEncy learning (SHADE) framework to handle such domain shift. Specifically, SHADE is constructed based on two consistency constraints, Style Consistency (SC) and Retrospection Consistency (RC). SC enriches the source situations and encourages the model to learn consistent representation across style-diversified samples. RC leverages real-world knowledge to prevent the model from overfitting to synthetic data and thus largely keeps the representation consistent between the synthetic and real-world models. Furthermore, we present a novel style hallucination module (SHM) to generate style-diversified samples that are essential to consistency learning. SHM selects basis styles from the source distribution, enabling the model to dynamically generate diverse and realistic samples during training. Experiments show that our SHADE yields significant improvement and outperforms state-of-the-art methods by 5.07% and 8.35% on the average mIoU of three real-world datasets on single- and multi-source settings respectively.
Cross-View Panorama Image Synthesis
Mar 22, 2022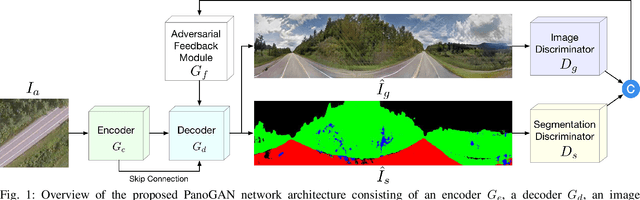
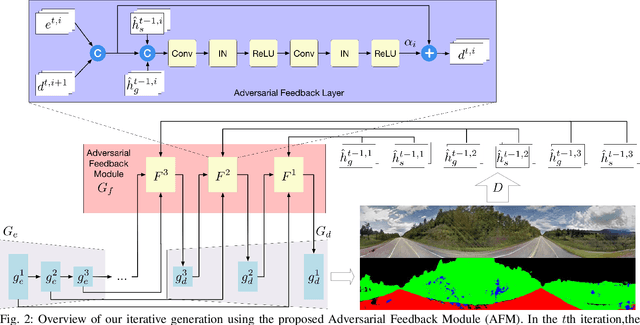
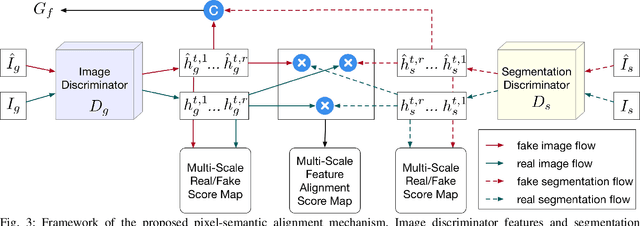

In this paper, we tackle the problem of synthesizing a ground-view panorama image conditioned on a top-view aerial image, which is a challenging problem due to the large gap between the two image domains with different view-points. Instead of learning cross-view mapping in a feedforward pass, we propose a novel adversarial feedback GAN framework named PanoGAN with two key components: an adversarial feedback module and a dual branch discrimination strategy. First, the aerial image is fed into the generator to produce a target panorama image and its associated segmentation map in favor of model training with layout semantics. Second, the feature responses of the discriminator encoded by our adversarial feedback module are fed back to the generator to refine the intermediate representations, so that the generation performance is continually improved through an iterative generation process. Third, to pursue high-fidelity and semantic consistency of the generated panorama image, we propose a pixel-segmentation alignment mechanism under the dual branch discrimiantion strategy to facilitate cooperation between the generator and the discriminator. Extensive experimental results on two challenging cross-view image datasets show that PanoGAN enables high-quality panorama image generation with more convincing details than state-of-the-art approaches. The source code and trained models are available at \url{https://github.com/sswuai/PanoGAN}.
Hyperbolic Vision Transformers: Combining Improvements in Metric Learning
Mar 22, 2022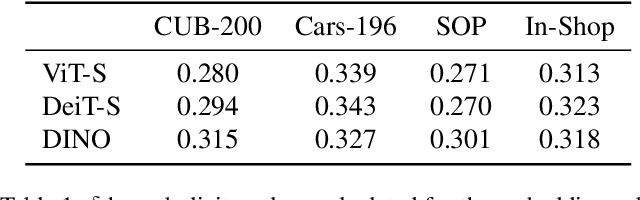

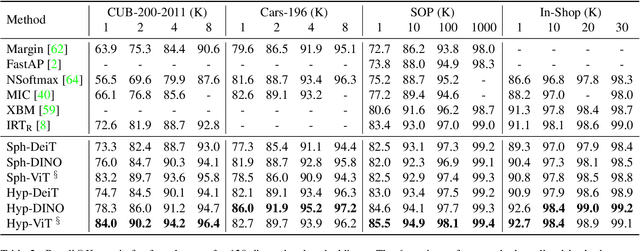
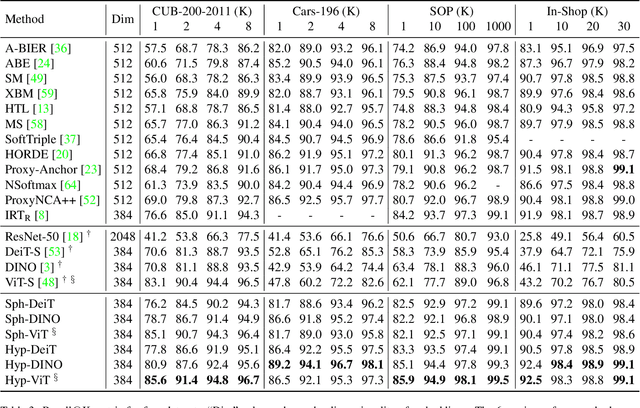
Metric learning aims to learn a highly discriminative model encouraging the embeddings of similar classes to be close in the chosen metrics and pushed apart for dissimilar ones. The common recipe is to use an encoder to extract embeddings and a distance-based loss function to match the representations -- usually, the Euclidean distance is utilized. An emerging interest in learning hyperbolic data embeddings suggests that hyperbolic geometry can be beneficial for natural data. Following this line of work, we propose a new hyperbolic-based model for metric learning. At the core of our method is a vision transformer with output embeddings mapped to hyperbolic space. These embeddings are directly optimized using modified pairwise cross-entropy loss. We evaluate the proposed model with six different formulations on four datasets achieving the new state-of-the-art performance. The source code is available at https://github.com/htdt/hyp_metric.