 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCholecTrack20: A Dataset for Multi-Class Multiple Tool Tracking in Laparoscopic Surgery
Dec 12, 2023Tool tracking in surgical videos is vital in computer-assisted intervention for tasks like surgeon skill assessment, safety zone estimation, and human-machine collaboration during minimally invasive procedures. The lack of large-scale datasets hampers Artificial Intelligence implementation in this domain. Current datasets exhibit overly generic tracking formalization, often lacking surgical context: a deficiency that becomes evident when tools move out of the camera's scope, resulting in rigid trajectories that hinder realistic surgical representation. This paper addresses the need for a more precise and adaptable tracking formalization tailored to the intricacies of endoscopic procedures by introducing CholecTrack20, an extensive dataset meticulously annotated for multi-class multi-tool tracking across three perspectives representing the various ways of considering the temporal duration of a tool trajectory: (1) intraoperative, (2) intracorporeal, and (3) visibility within the camera's scope. The dataset comprises 20 laparoscopic videos with over 35,000 frames and 65,000 annotated tool instances with details on spatial location, category, identity, operator, phase, and surgical visual conditions. This detailed dataset caters to the evolving assistive requirements within a procedure.
Encoding Surgical Videos as Latent Spatiotemporal Graphs for Object and Anatomy-Driven Reasoning
Dec 11, 2023Recently, spatiotemporal graphs have emerged as a concise and elegant manner of representing video clips in an object-centric fashion, and have shown to be useful for downstream tasks such as action recognition. In this work, we investigate the use of latent spatiotemporal graphs to represent a surgical video in terms of the constituent anatomical structures and tools and their evolving properties over time. To build the graphs, we first predict frame-wise graphs using a pre-trained model, then add temporal edges between nodes based on spatial coherence and visual and semantic similarity. Unlike previous approaches, we incorporate long-term temporal edges in our graphs to better model the evolution of the surgical scene and increase robustness to temporary occlusions. We also introduce a novel graph-editing module that incorporates prior knowledge and temporal coherence to correct errors in the graph, enabling improved downstream task performance. Using our graph representations, we evaluate two downstream tasks, critical view of safety prediction and surgical phase recognition, obtaining strong results that demonstrate the quality and flexibility of the learned representations. Code is available at github.com/CAMMA-public/SurgLatentGraph.
Jumpstarting Surgical Computer Vision
Dec 10, 2023



Purpose: General consensus amongst researchers and industry points to a lack of large, representative annotated datasets as the biggest obstacle to progress in the field of surgical data science. Self-supervised learning represents a solution to part of this problem, removing the reliance on annotations. However, the robustness of current self-supervised learning methods to domain shifts remains unclear, limiting our understanding of its utility for leveraging diverse sources of surgical data. Methods: In this work, we employ self-supervised learning to flexibly leverage diverse surgical datasets, thereby learning taskagnostic representations that can be used for various surgical downstream tasks. Based on this approach, to elucidate the impact of pre-training on downstream task performance, we explore 22 different pre-training dataset combinations by modulating three variables: source hospital, type of surgical procedure, and pre-training scale (number of videos). We then finetune the resulting model initializations on three diverse downstream tasks: namely, phase recognition and critical view of safety in laparoscopic cholecystectomy and phase recognition in laparoscopic hysterectomy. Results: Controlled experimentation highlights sizable boosts in performance across various tasks, datasets, and labeling budgets. However, this performance is intricately linked to the composition of the pre-training dataset, robustly proven through several study stages. Conclusion: The composition of pre-training datasets can severely affect the effectiveness of SSL methods for various downstream tasks and should critically inform future data collection efforts to scale the application of SSL methodologies. Keywords: Self-Supervised Learning, Transfer Learning, Surgical Computer Vision, Endoscopic Videos, Critical View of Safety, Phase Recognition
SAF-IS: a Spatial Annotation Free Framework for Instance Segmentation of Surgical Tools
Sep 04, 2023



Instance segmentation of surgical instruments is a long-standing research problem, crucial for the development of many applications for computer-assisted surgery. This problem is commonly tackled via fully-supervised training of deep learning models, requiring expensive pixel-level annotations to train. In this work, we develop a framework for instance segmentation not relying on spatial annotations for training. Instead, our solution only requires binary tool masks, obtainable using recent unsupervised approaches, and binary tool presence labels, freely obtainable in robot-assisted surgery. Based on the binary mask information, our solution learns to extract individual tool instances from single frames, and to encode each instance into a compact vector representation, capturing its semantic features. Such representations guide the automatic selection of a tiny number of instances (8 only in our experiments), displayed to a human operator for tool-type labelling. The gathered information is finally used to match each training instance with a binary tool presence label, providing an effective supervision signal to train a tool instance classifier. We validate our framework on the EndoVis 2017 and 2018 segmentation datasets. We provide results using binary masks obtained either by manual annotation or as predictions of an unsupervised binary segmentation model. The latter solution yields an instance segmentation approach completely free from spatial annotations, outperforming several state-of-the-art fully-supervised segmentation approaches.
Learning Multi-modal Representations by Watching Hundreds of Surgical Video Lectures
Jul 27, 2023Recent advancements in surgical computer vision applications have been driven by fully-supervised methods, primarily using only visual data. These methods rely on manually annotated surgical videos to predict a fixed set of object categories, limiting their generalizability to unseen surgical procedures and downstream tasks. In this work, we put forward the idea that the surgical video lectures available through open surgical e-learning platforms can provide effective supervisory signals for multi-modal representation learning without relying on manual annotations. We address the surgery-specific linguistic challenges present in surgical video lectures by employing multiple complementary automatic speech recognition systems to generate text transcriptions. We then present a novel method, SurgVLP - Surgical Vision Language Pre-training, for multi-modal representation learning. SurgVLP constructs a new contrastive learning objective to align video clip embeddings with the corresponding multiple text embeddings by bringing them together within a joint latent space. To effectively show the representation capability of the learned joint latent space, we introduce several vision-and-language tasks for surgery, such as text-based video retrieval, temporal activity grounding, and video captioning, as benchmarks for evaluation. We further demonstrate that without using any labeled ground truth, our approach can be employed for traditional vision-only surgical downstream tasks, such as surgical tool, phase, and triplet recognition. The code will be made available at https://github.com/CAMMA-public/SurgVLP
Surgical Action Triplet Detection by Mixed Supervised Learning of Instrument-Tissue Interactions
Jul 18, 2023



Surgical action triplets describe instrument-tissue interactions as (instrument, verb, target) combinations, thereby supporting a detailed analysis of surgical scene activities and workflow. This work focuses on surgical action triplet detection, which is challenging but more precise than the traditional triplet recognition task as it consists of joint (1) localization of surgical instruments and (2) recognition of the surgical action triplet associated with every localized instrument. Triplet detection is highly complex due to the lack of spatial triplet annotation. We analyze how the amount of instrument spatial annotations affects triplet detection and observe that accurate instrument localization does not guarantee better triplet detection due to the risk of erroneous associations with the verbs and targets. To solve the two tasks, we propose MCIT-IG, a two-stage network, that stands for Multi-Class Instrument-aware Transformer-Interaction Graph. The MCIT stage of our network models per class embedding of the targets as additional features to reduce the risk of misassociating triplets. Furthermore, the IG stage constructs a bipartite dynamic graph to model the interaction between the instruments and targets, cast as the verbs. We utilize a mixed-supervised learning strategy that combines weak target presence labels for MCIT and pseudo triplet labels for IG to train our network. We observed that complementing minimal instrument spatial annotations with target embeddings results in better triplet detection. We evaluate our model on the CholecT50 dataset and show improved performance on both instrument localization and triplet detection, topping the leaderboard of the CholecTriplet challenge in MICCAI 2022.
INDEXITY: a web-based collaborative tool for medical video annotation
Jun 26, 2023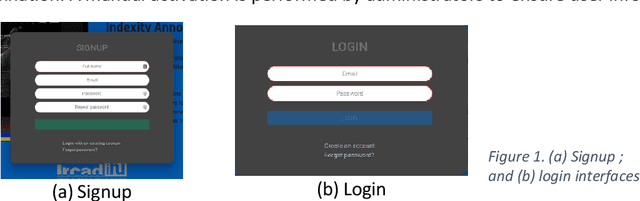
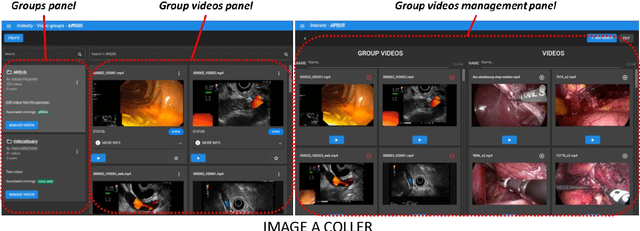
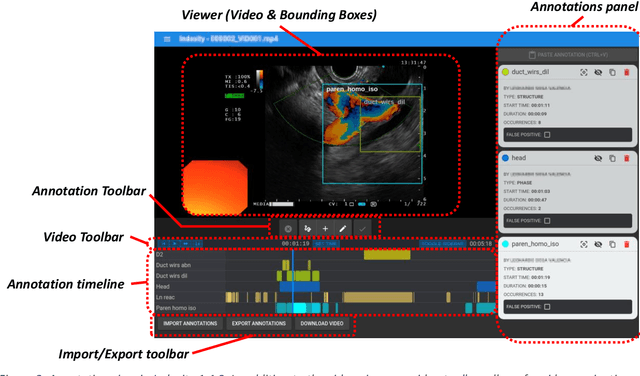
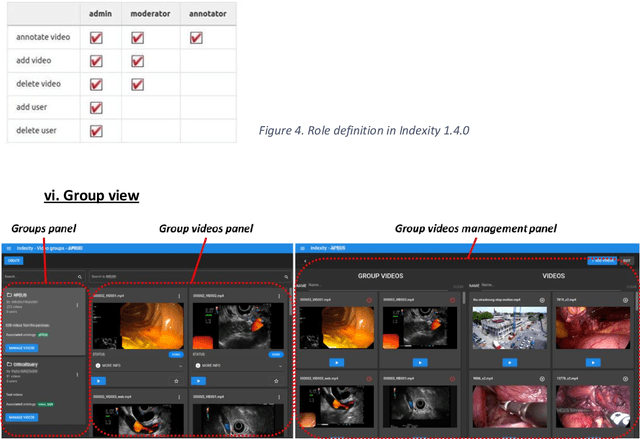
This technical report presents Indexity 1.4.0, a web-based tool designed for medical video annotation in surgical data science projects. We describe the main features available for the management of videos, annotations, ontology and users, as well as the global software architecture.
Surgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023



The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Self-distillation for surgical action recognition
Mar 22, 2023



Surgical scene understanding is a key prerequisite for contextaware decision support in the operating room. While deep learning-based approaches have already reached or even surpassed human performance in various fields, the task of surgical action recognition remains a major challenge. With this contribution, we are the first to investigate the concept of self-distillation as a means of addressing class imbalance and potential label ambiguity in surgical video analysis. Our proposed method is a heterogeneous ensemble of three models that use Swin Transfomers as backbone and the concepts of self-distillation and multi-task learning as core design choices. According to ablation studies performed with the CholecT45 challenge data via cross-validation, the biggest performance boost is achieved by the usage of soft labels obtained by self-distillation. External validation of our method on an independent test set was achieved by providing a Docker container of our inference model to the challenge organizers. According to their analysis, our method outperforms all other solutions submitted to the latest challenge in the field. Our approach thus shows the potential of self-distillation for becoming an important tool in medical image analysis applications.