 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform Masking Prevails in Vision-Language Pretraining
Dec 10, 2022



Masked Language Modeling (MLM) has proven to be an essential component of Vision-Language (VL) pretraining. To implement MLM, the researcher must make two design choices: the masking strategy, which determines which tokens to mask, and the masking rate, which determines how many tokens to mask. Previous work has focused primarily on the masking strategy while setting the masking rate at a default of 15\%. In this paper, we show that increasing this masking rate improves downstream performance while simultaneously reducing performance gap among different masking strategies, rendering the uniform masking strategy competitive to other more complex ones. Surprisingly, we also discover that increasing the masking rate leads to gains in Image-Text Matching (ITM) tasks, suggesting that the role of MLM goes beyond language modeling in VL pretraining.
ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations
Nov 03, 2022Deep learning vision systems are widely deployed across applications where reliability is critical. However, even today's best models can fail to recognize an object when its pose, lighting, or background varies. While existing benchmarks surface examples challenging for models, they do not explain why such mistakes arise. To address this need, we introduce ImageNet-X, a set of sixteen human annotations of factors such as pose, background, or lighting the entire ImageNet-1k validation set as well as a random subset of 12k training images. Equipped with ImageNet-X, we investigate 2,200 current recognition models and study the types of mistakes as a function of model's (1) architecture, e.g. transformer vs. convolutional, (2) learning paradigm, e.g. supervised vs. self-supervised, and (3) training procedures, e.g., data augmentation. Regardless of these choices, we find models have consistent failure modes across ImageNet-X categories. We also find that while data augmentation can improve robustness to certain factors, they induce spill-over effects to other factors. For example, strong random cropping hurts robustness on smaller objects. Together, these insights suggest to advance the robustness of modern vision models, future research should focus on collecting additional data and understanding data augmentation schemes. Along with these insights, we release a toolkit based on ImageNet-X to spur further study into the mistakes image recognition systems make.
Neural Attentive Circuits
Oct 19, 2022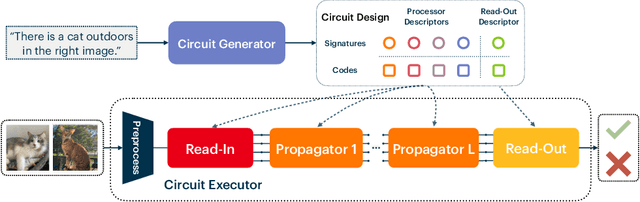
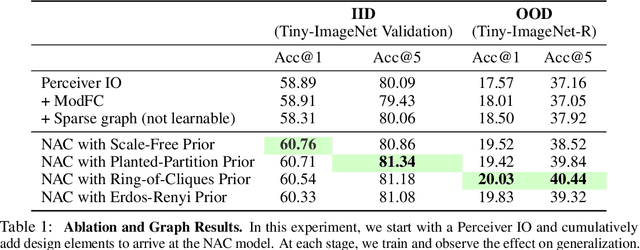
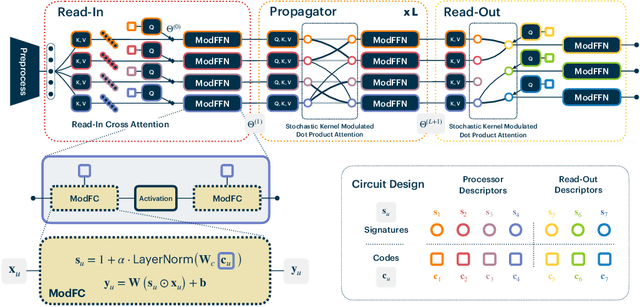

Recent work has seen the development of general purpose neural architectures that can be trained to perform tasks across diverse data modalities. General purpose models typically make few assumptions about the underlying data-structure and are known to perform well in the large-data regime. At the same time, there has been growing interest in modular neural architectures that represent the data using sparsely interacting modules. These models can be more robust out-of-distribution, computationally efficient, and capable of sample-efficient adaptation to new data. However, they tend to make domain-specific assumptions about the data, and present challenges in how module behavior (i.e., parameterization) and connectivity (i.e., their layout) can be jointly learned. In this work, we introduce a general purpose, yet modular neural architecture called Neural Attentive Circuits (NACs) that jointly learns the parameterization and a sparse connectivity of neural modules without using domain knowledge. NACs are best understood as the combination of two systems that are jointly trained end-to-end: one that determines the module configuration and the other that executes it on an input. We demonstrate qualitatively that NACs learn diverse and meaningful module configurations on the NLVR2 dataset without additional supervision. Quantitatively, we show that by incorporating modularity in this way, NACs improve upon a strong non-modular baseline in terms of low-shot adaptation on CIFAR and CUBs dataset by about 10%, and OOD robustness on Tiny ImageNet-R by about 2.5%. Further, we find that NACs can achieve an 8x speedup at inference time while losing less than 3% performance. Finally, we find NACs to yield competitive results on diverse data modalities spanning point-cloud classification, symbolic processing and text-classification from ASCII bytes, thereby confirming its general purpose nature.
The Hidden Uniform Cluster Prior in Self-Supervised Learning
Oct 13, 2022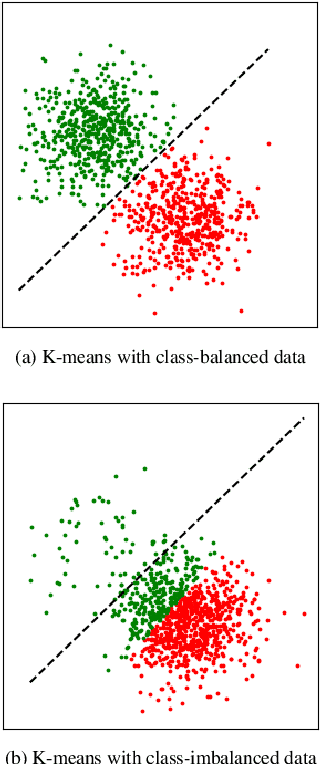
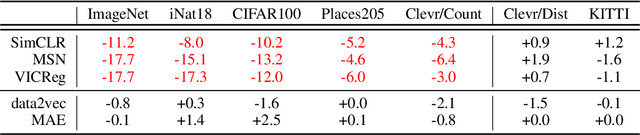


A successful paradigm in representation learning is to perform self-supervised pretraining using tasks based on mini-batch statistics (e.g., SimCLR, VICReg, SwAV, MSN). We show that in the formulation of all these methods is an overlooked prior to learn features that enable uniform clustering of the data. While this prior has led to remarkably semantic representations when pretraining on class-balanced data, such as ImageNet, we demonstrate that it can hamper performance when pretraining on class-imbalanced data. By moving away from conventional uniformity priors and instead preferring power-law distributed feature clusters, we show that one can improve the quality of the learned representations on real-world class-imbalanced datasets. To demonstrate this, we develop an extension of the Masked Siamese Networks (MSN) method to support the use of arbitrary features priors.
Cascaded Video Generation for Videos In-the-Wild
Jun 01, 2022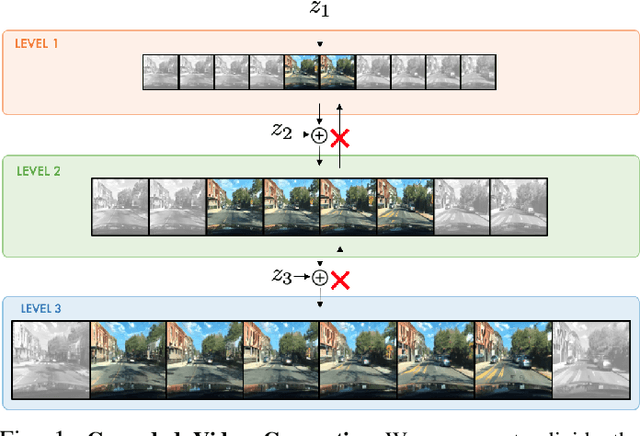

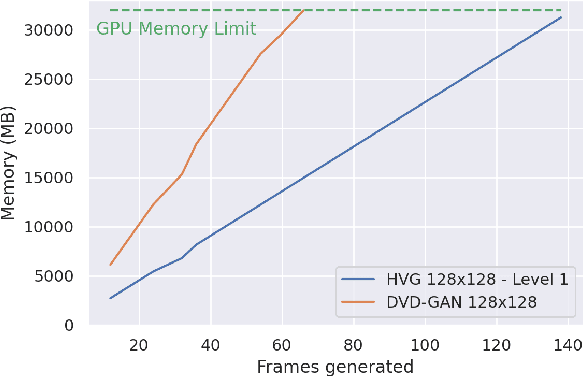

Videos can be created by first outlining a global view of the scene and then adding local details. Inspired by this idea we propose a cascaded model for video generation which follows a coarse to fine approach. First our model generates a low resolution video, establishing the global scene structure, which is then refined by subsequent cascade levels operating at larger resolutions. We train each cascade level sequentially on partial views of the videos, which reduces the computational complexity of our model and makes it scalable to high-resolution videos with many frames. We empirically validate our approach on UCF101 and Kinetics-600, for which our model is competitive with the state-of-the-art. We further demonstrate the scaling capabilities of our model and train a three-level model on the BDD100K dataset which generates 256x256 pixels videos with 48 frames.
Masked Siamese Networks for Label-Efficient Learning
Apr 14, 2022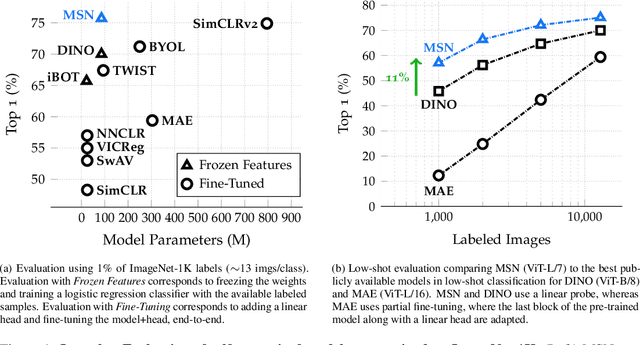
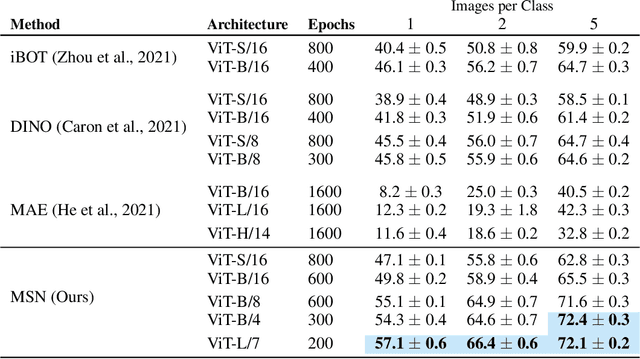

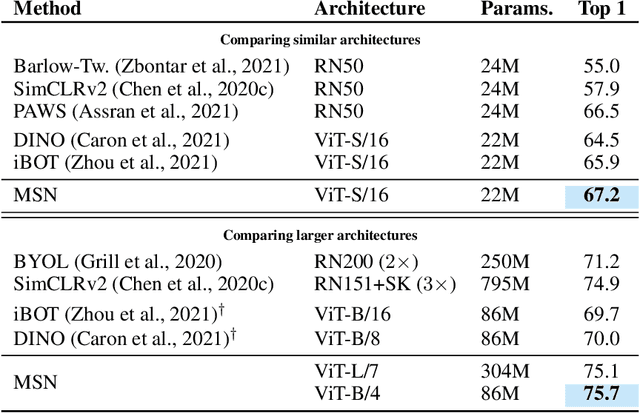
We propose Masked Siamese Networks (MSN), a self-supervised learning framework for learning image representations. Our approach matches the representation of an image view containing randomly masked patches to the representation of the original unmasked image. This self-supervised pre-training strategy is particularly scalable when applied to Vision Transformers since only the unmasked patches are processed by the network. As a result, MSNs improve the scalability of joint-embedding architectures, while producing representations of a high semantic level that perform competitively on low-shot image classification. For instance, on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy, and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark. Our code is publicly available.
BARACK: Partially Supervised Group Robustness With Guarantees
Dec 31, 2021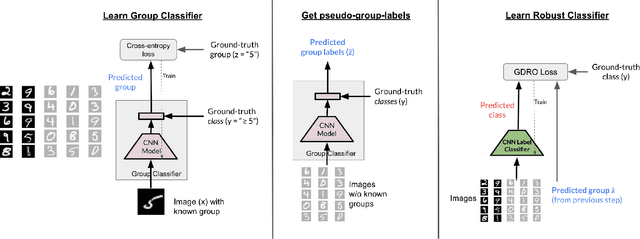



While neural networks have shown remarkable success on classification tasks in terms of average-case performance, they often fail to perform well on certain groups of the data. Such group information may be expensive to obtain; thus, recent works in robustness and fairness have proposed ways to improve worst-group performance even when group labels are unavailable for the training data. However, these methods generally underperform methods that utilize group information at training time. In this work, we assume access to a small number of group labels alongside a larger dataset without group labels. We propose BARACK, a simple two-step framework to utilize this partial group information to improve worst-group performance: train a model to predict the missing group labels for the training data, and then use these predicted group labels in a robust optimization objective. Theoretically, we provide generalization bounds for our approach in terms of the worst-group performance, showing how the generalization error scales with respect to both the total number of training points and the number of training points with group labels. Empirically, our method outperforms the baselines that do not use group information, even when only 1-33% of points have group labels. We provide ablation studies to support the robustness and extensibility of our framework.
Trade-offs of Local SGD at Scale: An Empirical Study
Oct 15, 2021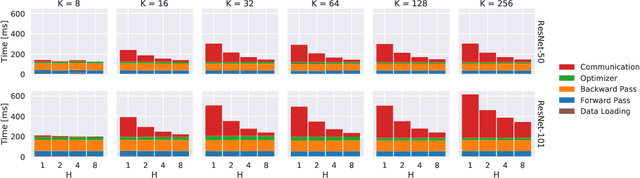
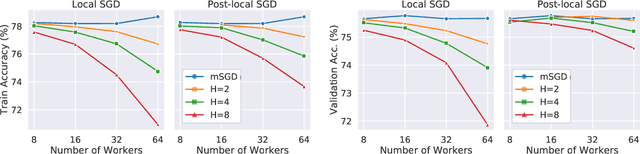
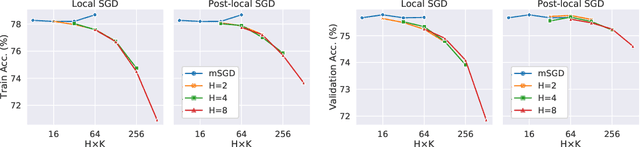
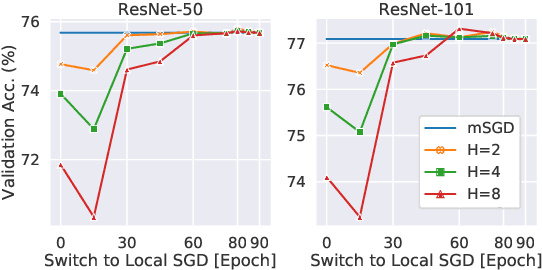
As datasets and models become increasingly large, distributed training has become a necessary component to allow deep neural networks to train in reasonable amounts of time. However, distributed training can have substantial communication overhead that hinders its scalability. One strategy for reducing this overhead is to perform multiple unsynchronized SGD steps independently on each worker between synchronization steps, a technique known as local SGD. We conduct a comprehensive empirical study of local SGD and related methods on a large-scale image classification task. We find that performing local SGD comes at a price: lower communication costs (and thereby faster training) are accompanied by lower accuracy. This finding is in contrast from the smaller-scale experiments in prior work, suggesting that local SGD encounters challenges at scale. We further show that incorporating the slow momentum framework of Wang et al. (2020) consistently improves accuracy without requiring additional communication, hinting at future directions for potentially escaping this trade-off.
Hierarchical Video Generation for Complex Data
Jun 04, 2021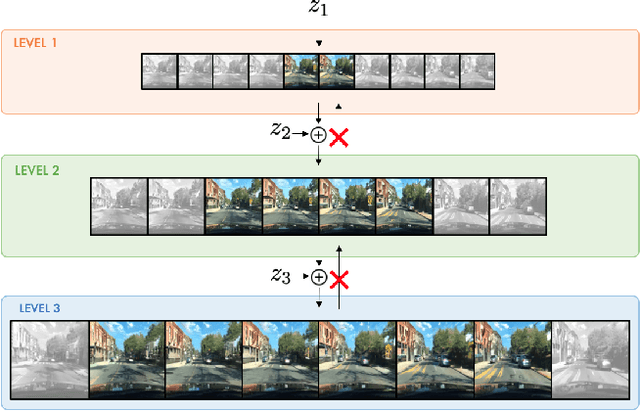
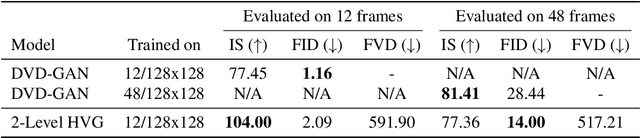
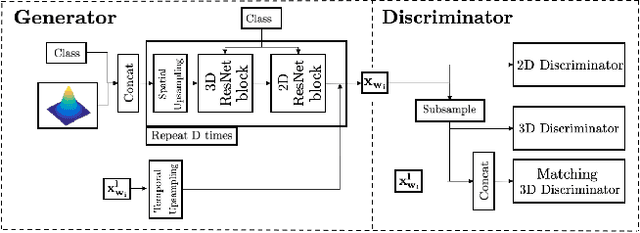
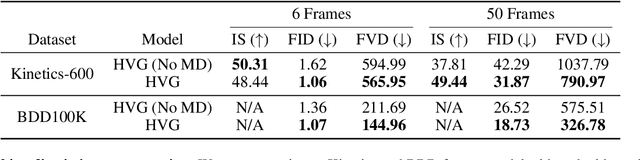
Videos can often be created by first outlining a global description of the scene and then adding local details. Inspired by this we propose a hierarchical model for video generation which follows a coarse to fine approach. First our model generates a low resolution video, establishing the global scene structure, that is then refined by subsequent levels in the hierarchy. We train each level in our hierarchy sequentially on partial views of the videos. This reduces the computational complexity of our generative model, which scales to high-resolution videos beyond a few frames. We validate our approach on Kinetics-600 and BDD100K, for which we train a three level model capable of generating 256x256 videos with 48 frames.
Semi-Supervised Learning of Visual Features by Non-Parametrically Predicting View Assignments with Support Samples
Apr 28, 2021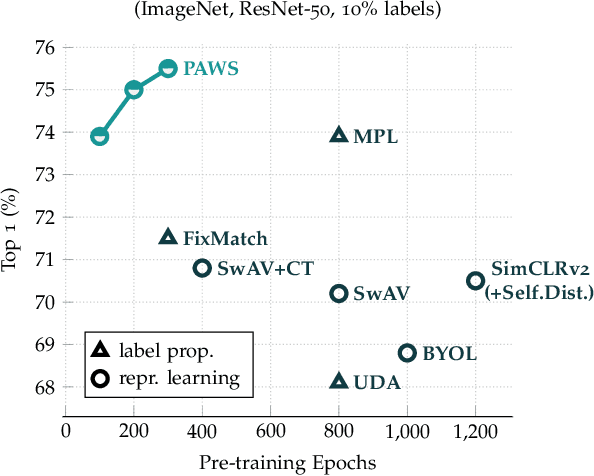
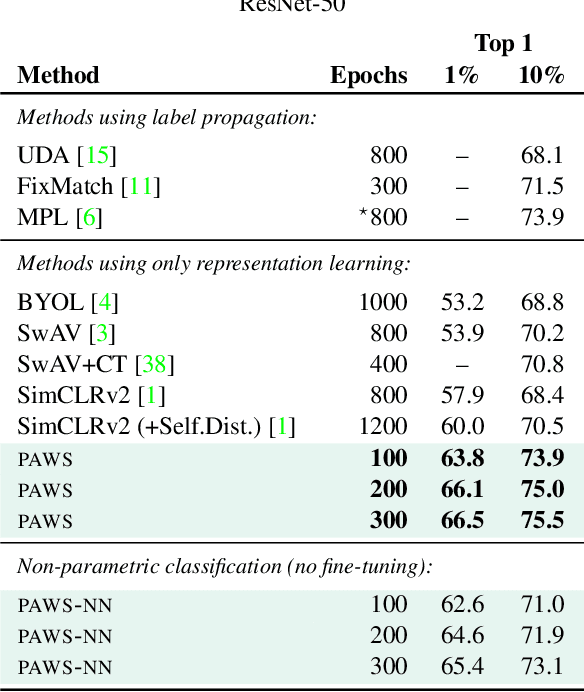
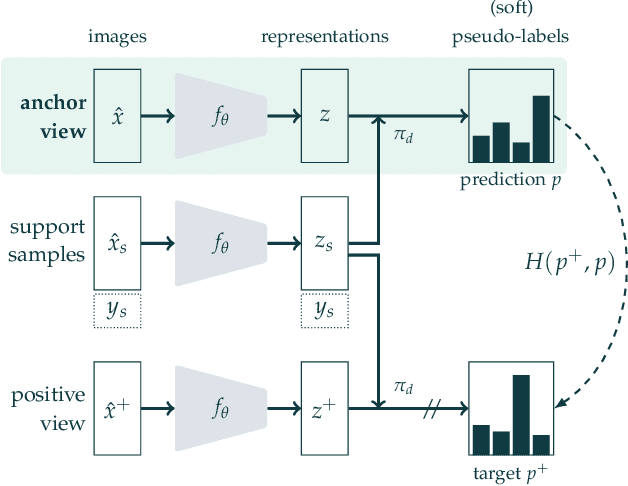
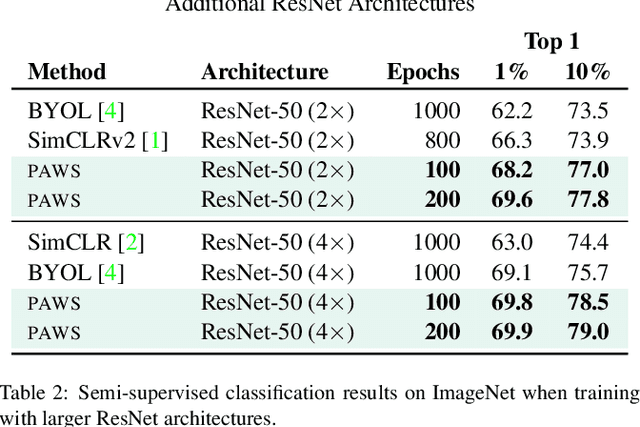
This paper proposes a novel method of learning by predicting view assignments with support samples (PAWS). The method trains a model to minimize a consistency loss, which ensures that different views of the same unlabeled instance are assigned similar pseudo-labels. The pseudo-labels are generated non-parametrically, by comparing the representations of the image views to those of a set of randomly sampled labeled images. The distance between the view representations and labeled representations is used to provide a weighting over class labels, which we interpret as a soft pseudo-label. By non-parametrically incorporating labeled samples in this way, PAWS extends the distance-metric loss used in self-supervised methods such as BYOL and SwAV to the semi-supervised setting. Despite the simplicity of the approach, PAWS outperforms other semi-supervised methods across architectures, setting a new state-of-the-art for a ResNet-50 on ImageNet trained with either 10% or 1% of the labels, reaching 75.5% and 66.5% top-1 respectively. PAWS requires 4x to 12x less training than the previous best methods.