 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to train your conditional GAN: An approach using geometrically structured latent manifolds
Nov 30, 2020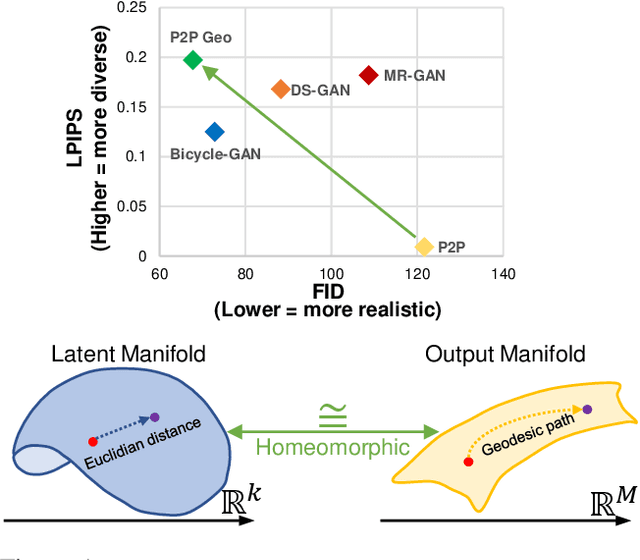


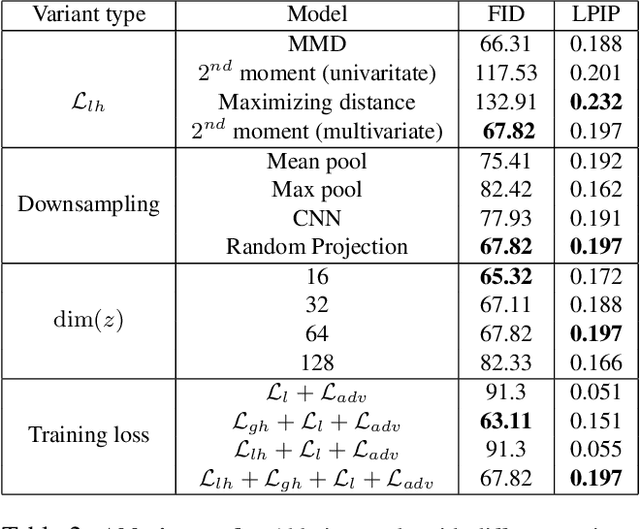
Conditional generative modeling typically requires capturing one-to-many mappings between the inputs and outputs. However, vanilla conditional GANs (cGAN) tend to ignore the variations of the latent seeds which results in mode-collapse. As a solution, recent works have moved towards comparatively expensive models for generating diverse outputs in a conditional setting. In this paper, we argue that the limited diversity of the vanilla cGANs is not due to a lack of capacity, but a result of non-optimal training schemes. We tackle this problem from a geometrical perspective and propose a novel training mechanism that increases both the diversity and the visual quality of the vanilla cGAN. The proposed solution does not demand architectural modifications and paves the way for more efficient architectures that target conditional generation in multi-modal spaces. We validate the efficacy of our model against a diverse set of tasks and show that the proposed solution is generic and effective across multiple datasets.
Conditional Generative Modeling via Learning the Latent Space
Oct 09, 2020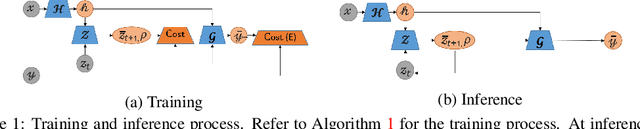
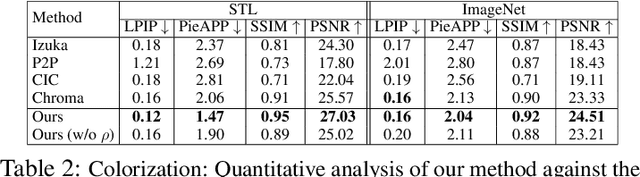
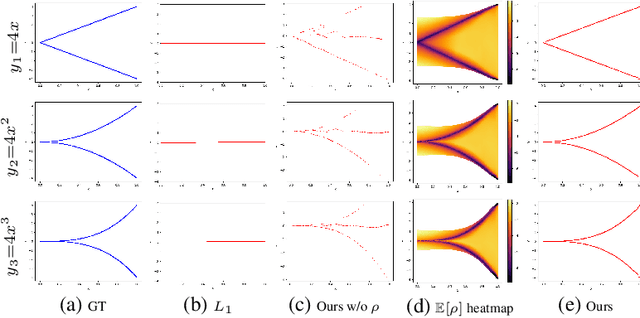
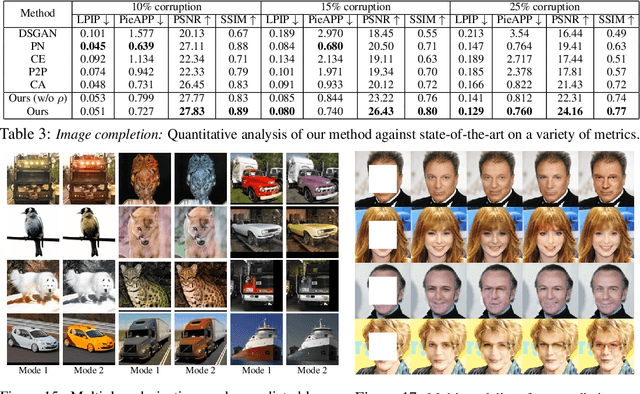
Although deep learning has achieved appealing results on several machine learning tasks, most of the models are deterministic at inference, limiting their application to single-modal settings. We propose a novel general-purpose framework for conditional generation in multimodal spaces, that uses latent variables to model generalizable learning patterns while minimizing a family of regression cost functions. At inference, the latent variables are optimized to find optimal solutions corresponding to multiple output modes. Compared to existing generative solutions, in multimodal spaces, our approach demonstrates faster and stable convergence, and can learn better representations for downstream tasks. Importantly, it provides a simple generic model that can beat highly engineered pipelines tailored using domain expertise on a variety of tasks, while generating diverse outputs. Our codes will be released.
Attention Guided Semantic Relationship Parsing for Visual Question Answering
Oct 05, 2020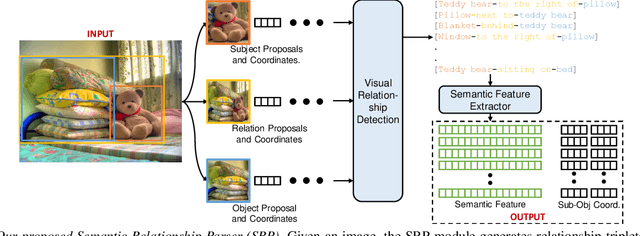
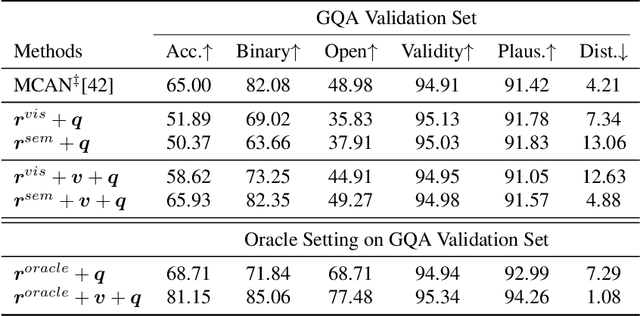
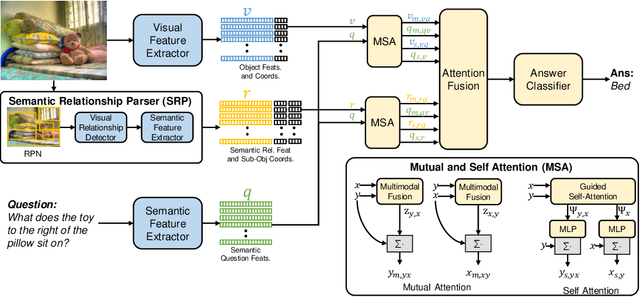
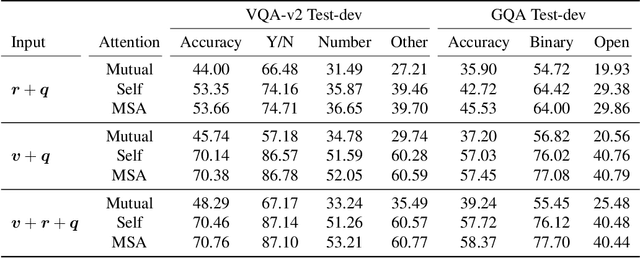
Humans explain inter-object relationships with semantic labels that demonstrate a high-level understanding required to perform complex Vision-Language tasks such as Visual Question Answering (VQA). However, existing VQA models represent relationships as a combination of object-level visual features which constrain a model to express interactions between objects in a single domain, while the model is trying to solve a multi-modal task. In this paper, we propose a general purpose semantic relationship parser which generates a semantic feature vector for each subject-predicate-object triplet in an image, and a Mutual and Self Attention (MSA) mechanism that learns to identify relationship triplets that are important to answer the given question. To motivate the significance of semantic relationships, we show an oracle setting with ground-truth relationship triplets, where our model achieves a ~25% accuracy gain over the closest state-of-the-art model on the challenging GQA dataset. Further, with our semantic parser, we show that our model outperforms other comparable approaches on VQA and GQA datasets.
Uncertainty Inspired RGB-D Saliency Detection
Sep 07, 2020
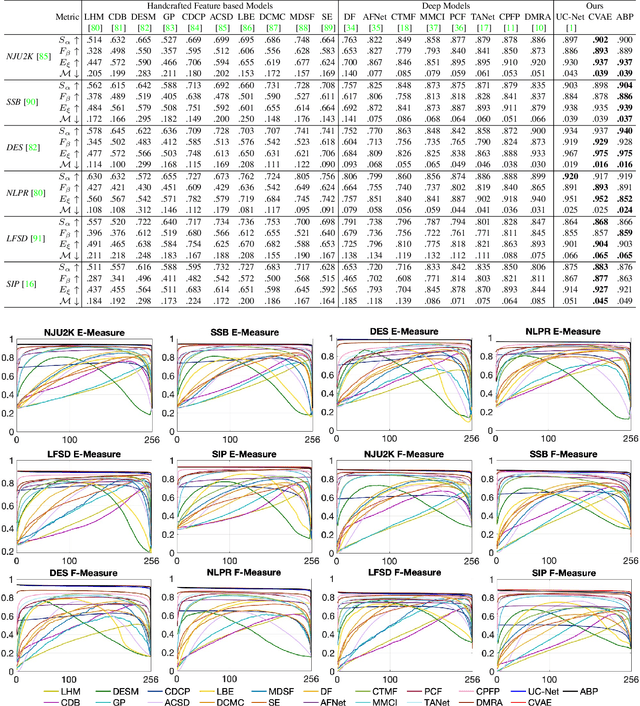
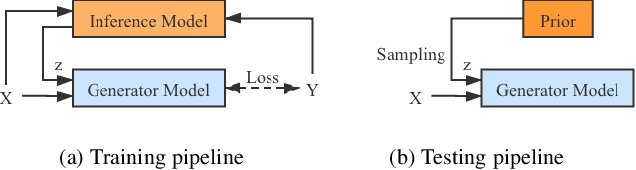

We propose the first stochastic framework to employ uncertainty for RGB-D saliency detection by learning from the data labeling process. Existing RGB-D saliency detection models treat this task as a point estimation problem by predicting a single saliency map following a deterministic learning pipeline. We argue that, however, the deterministic solution is relatively ill-posed. Inspired by the saliency data labeling process, we propose a generative architecture to achieve probabilistic RGB-D saliency detection which utilizes a latent variable to model the labeling variations. Our framework includes two main models: 1) a generator model, which maps the input image and latent variable to stochastic saliency prediction, and 2) an inference model, which gradually updates the latent variable by sampling it from the true or approximate posterior distribution. The generator model is an encoder-decoder saliency network. To infer the latent variable, we introduce two different solutions: i) a Conditional Variational Auto-encoder with an extra encoder to approximate the posterior distribution of the latent variable; and ii) an Alternating Back-Propagation technique, which directly samples the latent variable from the true posterior distribution. Qualitative and quantitative results on six challenging RGB-D benchmark datasets show our approach's superior performance in learning the distribution of saliency maps. The source code is publicly available via our project page: https://github.com/JingZhang617/UCNet.
Learning Noise-Aware Encoder-Decoder from Noisy Labels by Alternating Back-Propagation for Saliency Detection
Jul 23, 2020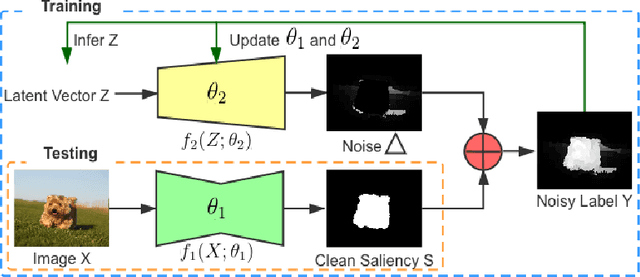
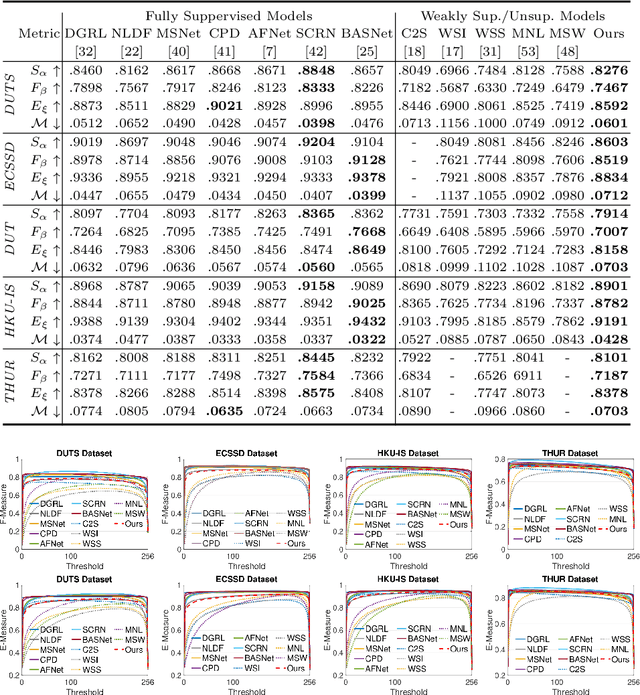
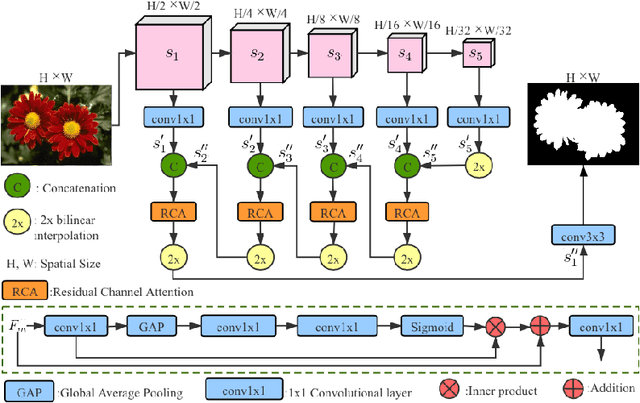
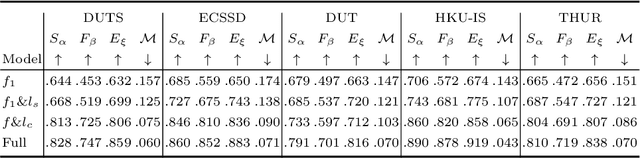
In this paper, we propose a noise-aware encoder-decoder framework to disentangle a clean saliency predictor from noisy training examples, where the noisy labels are generated by unsupervised handcrafted feature-based methods. The proposed model consists of two sub-models parameterized by neural networks: (1) a saliency predictor that maps input images to clean saliency maps, and (2) a noise generator, which is a latent variable model that produces noises from Gaussian latent vectors. The whole model that represents noisy labels is a sum of the two sub-models. The goal of training the model is to estimate the parameters of both sub-models, and simultaneously infer the corresponding latent vector of each noisy label. We propose to train the model by using an alternating back-propagation (ABP) algorithm, which alternates the following two steps: (1) learning back-propagation for estimating the parameters of two sub-models by gradient ascent, and (2) inferential back-propagation for inferring the latent vectors of training noisy examples by Langevin Dynamics. To prevent the network from converging to trivial solutions, we utilize an edge-aware smoothness loss to regularize hidden saliency maps to have similar structures as their corresponding images. Experimental results on several benchmark datasets indicate the effectiveness of the proposed model.
Dense-Resolution Network for Point Cloud Classification and Segmentation
May 14, 2020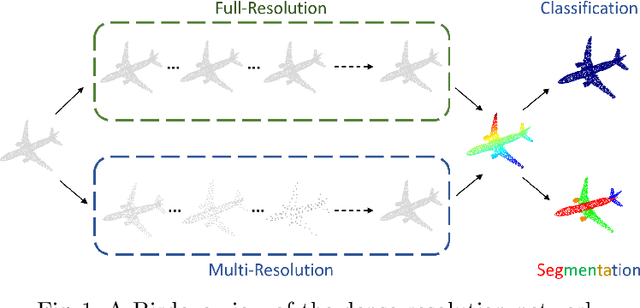
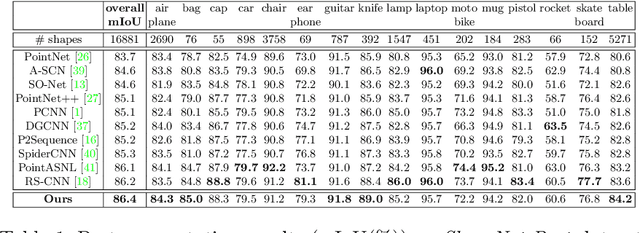
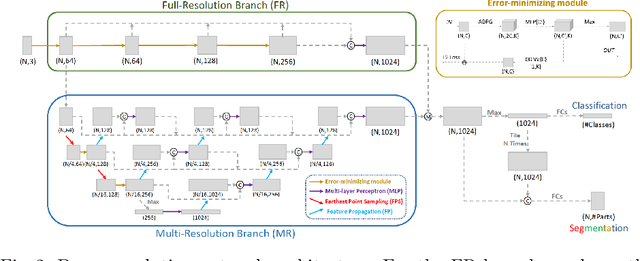
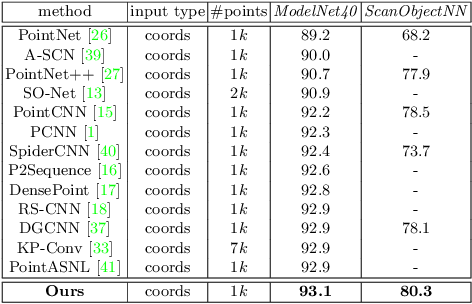
Point cloud analysis is attracting attention from Artificial Intelligence research since it can be extensively applied for robotics, Augmented Reality, self-driving, etc. However, it is always challenging due to problems such as irregularities, unorderedness, and sparsity. In this article, we propose a novel network named Dense-Resolution Network for point cloud analysis. This network is designed to learn local point features from point cloud in different resolutions. In order to learn local point groups more intelligently, we present a novel grouping algorithm for local neighborhood searching and an effective error-minimizing model for capturing local features. In addition to validating the network on widely used point cloud segmentation and classification benchmarks, we also test and visualize the performances of the components. Comparing with other state-of-the-art methods, our network shows superiority.
Attention Prior for Real Image Restoration
Apr 26, 2020

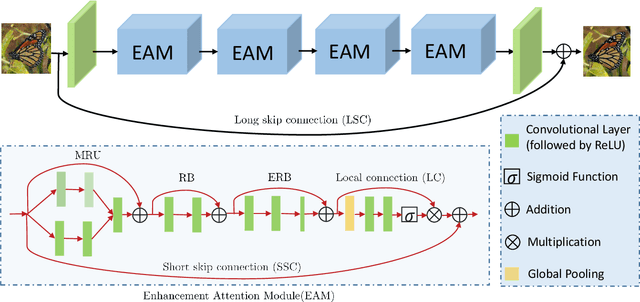

Deep convolutional neural networks perform better on images containing spatially invariant degradations, also known as synthetic degradations; however, their performance is limited on real-degraded photographs and requires multiple-stage network modeling. To advance the practicability of restoration algorithms, this paper proposes a novel single-stage blind real image restoration network (R$^2$Net) by employing a modular architecture. We use a residual on the residual structure to ease the flow of low-frequency information and apply feature attention to exploit the channel dependencies. Furthermore, the evaluation in terms of quantitative metrics and visual quality for four restoration tasks i.e. Denoising, Super-resolution, Raindrop Removal, and JPEG Compression on 11 real degraded datasets against more than 30 state-of-the-art algorithms demonstrate the superiority of our R$^2$Net. We also present the comparison on three synthetically generated degraded datasets for denoising to showcase the capability of our method on synthetics denoising. The codes, trained models, and results are available on https://github.com/saeed-anwar/R2Net.
UC-Net: Uncertainty Inspired RGB-D Saliency Detection via Conditional Variational Autoencoders
Apr 13, 2020
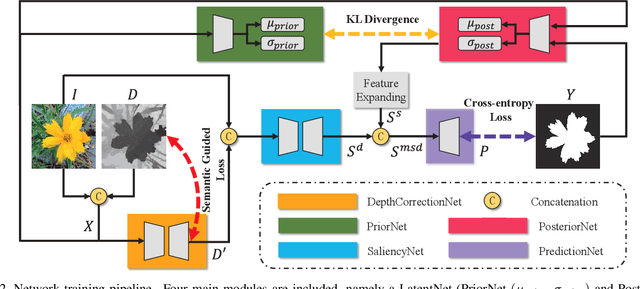
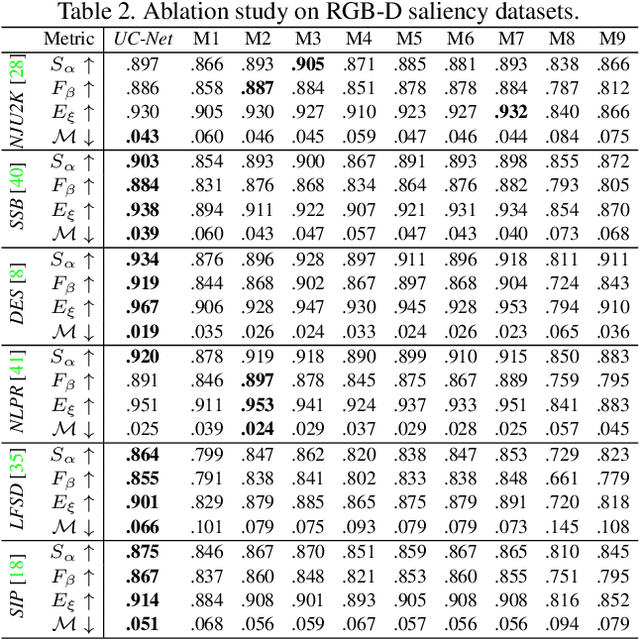
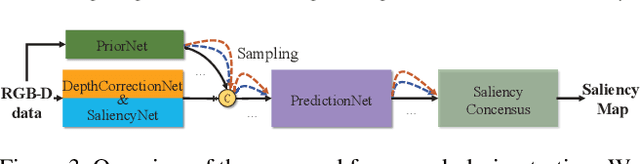
In this paper, we propose the first framework (UCNet) to employ uncertainty for RGB-D saliency detection by learning from the data labeling process. Existing RGB-D saliency detection methods treat the saliency detection task as a point estimation problem, and produce a single saliency map following a deterministic learning pipeline. Inspired by the saliency data labeling process, we propose probabilistic RGB-D saliency detection network via conditional variational autoencoders to model human annotation uncertainty and generate multiple saliency maps for each input image by sampling in the latent space. With the proposed saliency consensus process, we are able to generate an accurate saliency map based on these multiple predictions. Quantitative and qualitative evaluations on six challenging benchmark datasets against 18 competing algorithms demonstrate the effectiveness of our approach in learning the distribution of saliency maps, leading to a new state-of-the-art in RGB-D saliency detection.
How to Train Your Event Camera Neural Network
Apr 09, 2020
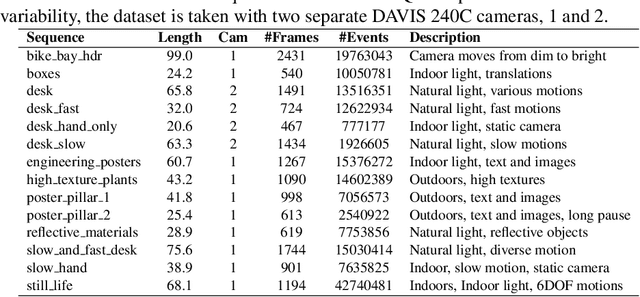
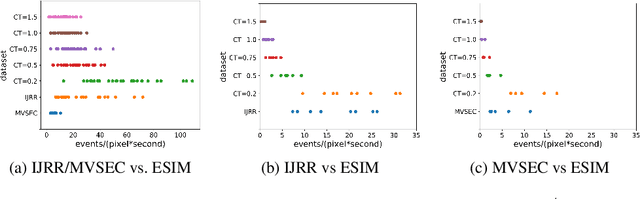
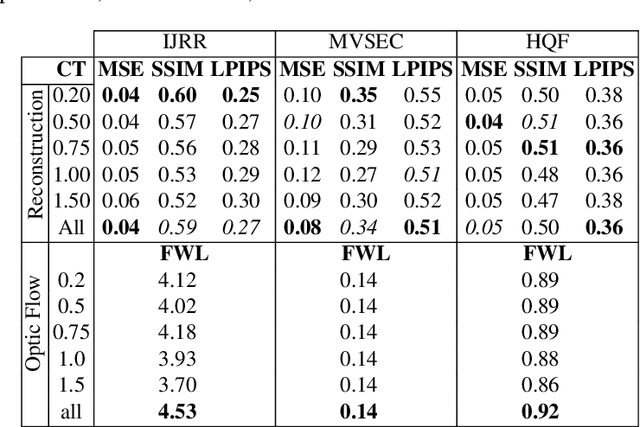
Event cameras are paradigm-shifting novel sensors that report asynchronous, per-pixel brightness changes called 'events' with unparalleled low latency. This makes them ideal for high speed, high dynamic range scenes where conventional cameras would fail. Recent work has demonstrated impressive results using Convolutional Neural Networks (CNNs) for video reconstruction and optic flow with events. We present strategies for improving training data for event based CNNs that result in 25-40% boost in performance of existing state-of-the-art (SOTA) video reconstruction networks retrained with our method, and up to 80% for optic flow networks. A challenge in evaluating event based video reconstruction is lack of quality groundtruth images in existing datasets. To address this, we present a new High Quality Frames (HQF) dataset, containing events and groundtruth frames from a DAVIS240C that are well-exposed and minimally motion-blurred. We evaluate our method on HQF + several existing major event camera datasets.
A Systematic Evaluation: Fine-Grained CNN vs. Traditional CNN Classifiers
Mar 24, 2020

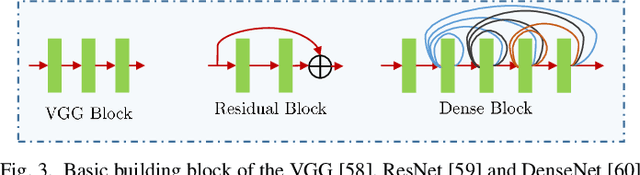
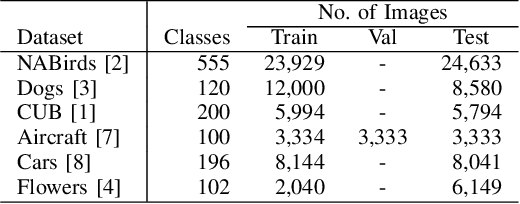
To make the best use of the underlying minute and subtle differences, fine-grained classifiers collect information about inter-class variations. The task is very challenging due to the small differences between the colors, viewpoint, and structure in the same class entities. The classification becomes more difficult due to the similarities between the differences in viewpoint with other classes and differences with its own. In this work, we investigate the performance of the landmark general CNN classifiers, which presented top-notch results on large scale classification datasets, on the fine-grained datasets, and compare it against state-of-the-art fine-grained classifiers. In this paper, we pose two specific questions: (i) Do the general CNN classifiers achieve comparable results to fine-grained classifiers? (ii) Do general CNN classifiers require any specific information to improve upon the fine-grained ones? Throughout this work, we train the general CNN classifiers without introducing any aspect that is specific to fine-grained datasets. We show an extensive evaluation on six datasets to determine whether the fine-grained classifier is able to elevate the baseline in their experiments.