 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperVis: Continuous Latent Visual Relational Graphs on the Lorentz Hyperboloid for Compositional Reasoning
Jun 04, 2026Vision-Language Models (VLMs) struggle with compositional reasoning that requires understanding inter-object relationships. A natural remedy is to inject explicit scene graph triplets $\langle s, p, o \rangle$ from an off-the-shelf scene graph generator (SGG), but we show this backfires: discrete text labels collide with the continuous visual modality, degrading GQA accuracy from 60.38\% to 58.86\%. We propose \textbf{HyperVis}, which bypasses the SGG semantic bottleneck entirely. From $N$ class-agnostic region proposals, we compute a dense $O(N^2)$ visual relation tensor via spatially-biased cross-attention, project it onto a Lorentz hyperboloid, and enforce hierarchy through spatial physics, namely IoA-driven entailment cones and exterior-angle repulsion. We discover that HyperVis contributes in two complementary ways: (1) as a \emph{training-time regularizer}, the hyperbolic relational losses shape LoRA representations that improve generative VQA (GQA 61.03\% vs.\ 57.21\% for LoRA fine-tuning without relational losses, recovering and surpassing the baseline); and (2) as an \emph{inference-time relational encoder}, hyperbolic prefix tokens boost discriminative compositional scoring (SugarCrepe 79.94\%, $+$6.25pp over baseline). The learned curvature stabilises at $κ{=}4.0$, an order of magnitude above prior hyperbolic VLMs where $κ$ typically collapses toward zero, indicating that continuous visual features genuinely require the exponential volume of strongly curved space. A controlled Euclidean ablation confirms this decomposition: the relational pipeline regularises LoRA comparably in flat space (GQA 60.81\%), but the compositionality gain is specifically hyperbolic (SugarCrepe $+$4.58pp over Euclidean), with entailment loss ${\sim}6{\times}$ higher in Euclidean training. Codes are available at TBA.
VReBERT: A Simple and Flexible Transformer for Visual Relationship Detection
Jun 18, 2022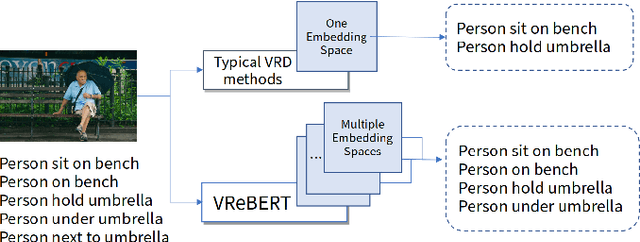
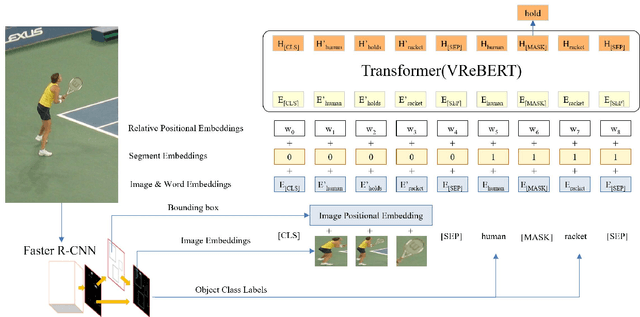
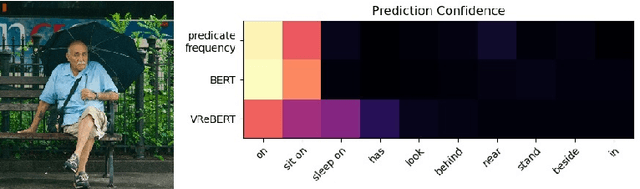
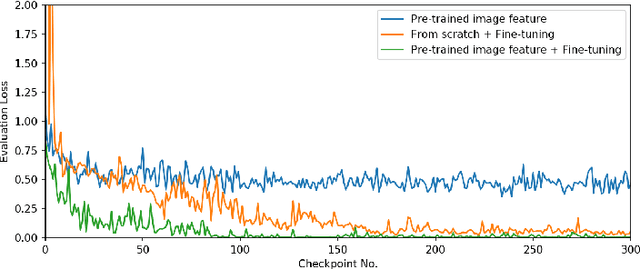
Visual Relationship Detection (VRD) impels a computer vision model to 'see' beyond an individual object instance and 'understand' how different objects in a scene are related. The traditional way of VRD is first to detect objects in an image and then separately predict the relationship between the detected object instances. Such a disjoint approach is prone to predict redundant relationship tags (i.e., predicate) between the same object pair with similar semantic meaning, or incorrect ones that have a similar meaning to the ground truth but are semantically incorrect. To remedy this, we propose to jointly train a VRD model with visual object features and semantic relationship features. To this end, we propose VReBERT, a BERT-like transformer model for Visual Relationship Detection with a multi-stage training strategy to jointly process visual and semantic features. We show that our simple BERT-like model is able to outperform the state-of-the-art VRD models in predicate prediction. Furthermore, we show that by using the pre-trained VReBERT model, our model pushes the state-of-the-art zero-shot predicate prediction by a significant margin (+8.49 R@50 and +8.99 R@100).
How You Start Matters for Generalization
Jun 17, 2022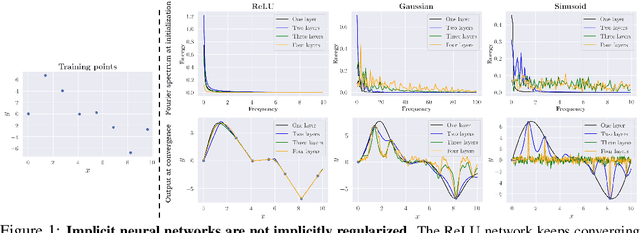
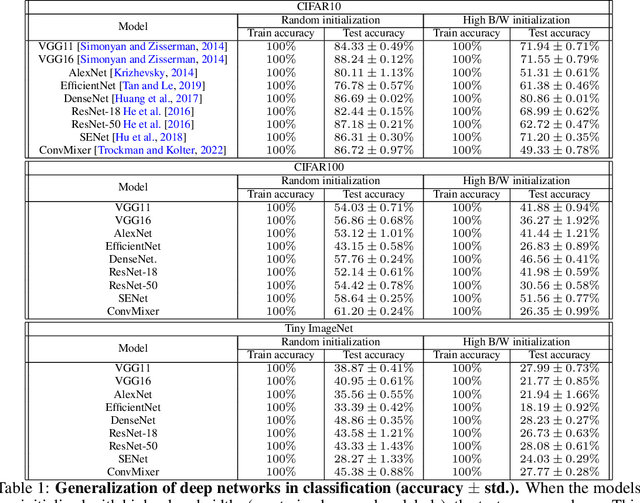
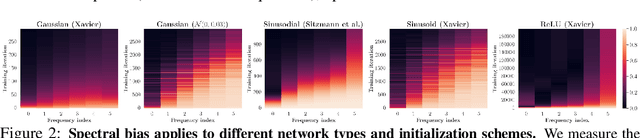
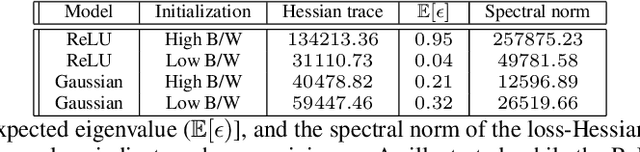
Characterizing the remarkable generalization properties of over-parameterized neural networks remains an open problem. In this paper, we promote a shift of focus towards initialization rather than neural architecture or (stochastic) gradient descent to explain this implicit regularization. Through a Fourier lens, we derive a general result for the spectral bias of neural networks and show that the generalization of neural networks is heavily tied to their initialization. Further, we empirically solidify the developed theoretical insights using practical, deep networks. Finally, we make a case against the controversial flat-minima conjecture and show that Fourier analysis grants a more reliable framework for understanding the generalization of neural networks.
Recursive Training for Zero-Shot Semantic Segmentation
Feb 26, 2021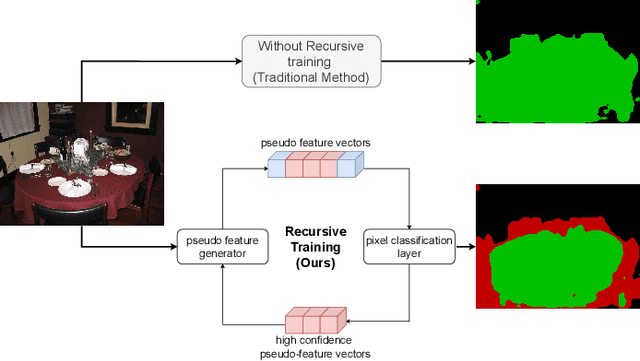
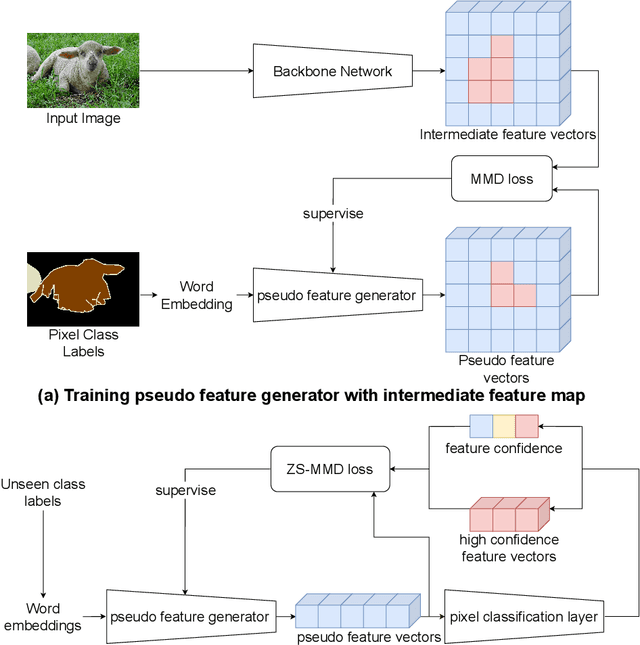

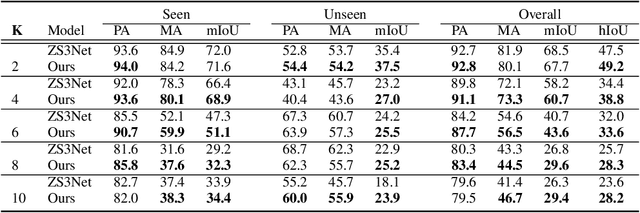
General purpose semantic segmentation relies on a backbone CNN network to extract discriminative features that help classify each image pixel into a 'seen' object class (ie., the object classes available during training) or a background class. Zero-shot semantic segmentation is a challenging task that requires a computer vision model to identify image pixels belonging to an object class which it has never seen before. Equipping a general purpose semantic segmentation model to separate image pixels of 'unseen' classes from the background remains an open challenge. Some recent models have approached this problem by fine-tuning the final pixel classification layer of a semantic segmentation model for a Zero-Shot setting, but struggle to learn discriminative features due to the lack of supervision. We propose a recursive training scheme to supervise the retraining of a semantic segmentation model for a zero-shot setting using a pseudo-feature representation. To this end, we propose a Zero-Shot Maximum Mean Discrepancy (ZS-MMD) loss that weighs high confidence outputs of the pixel classification layer as a pseudo-feature representation, and feeds it back to the generator. By closing-the-loop on the generator end, we provide supervision during retraining that in turn helps the model learn a more discriminative feature representation for 'unseen' classes. We show that using our recursive training and ZS-MMD loss, our proposed model achieves state-of-the-art performance on the Pascal-VOC 2012 dataset and Pascal-Context dataset.
Efficient Two-Stream Network for Violence Detection Using Separable Convolutional LSTM
Feb 21, 2021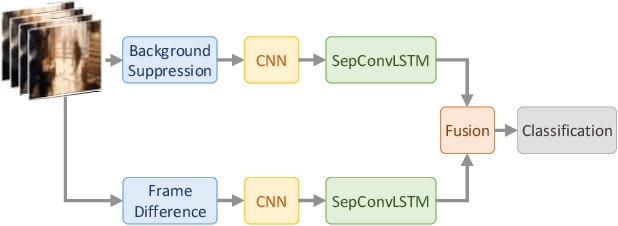

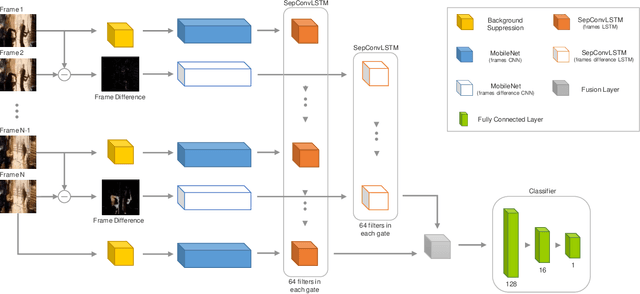
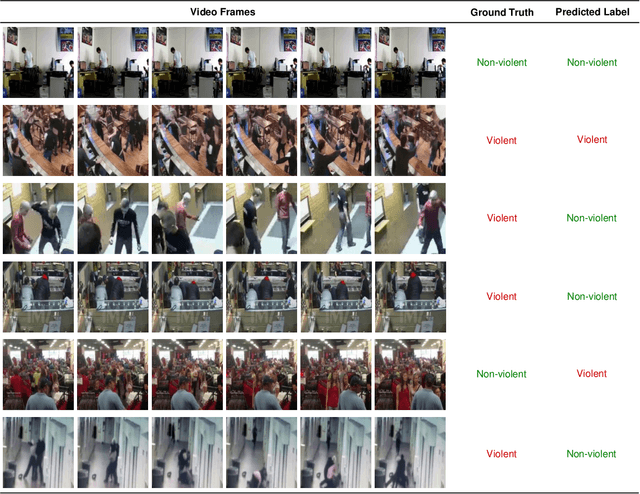
Automatically detecting violence from surveillance footage is a subset of activity recognition that deserves special attention because of its wide applicability in unmanned security monitoring systems, internet video filtration, etc. In this work, we propose an efficient two-stream deep learning architecture leveraging Separable Convolutional LSTM (SepConvLSTM) and pre-trained MobileNet where one stream takes in background suppressed frames as inputs and other stream processes difference of adjacent frames. We employed simple and fast input pre-processing techniques that highlight the moving objects in the frames by suppressing non-moving backgrounds and capture the motion in-between frames. As violent actions are mostly characterized by body movements these inputs help produce discriminative features. SepConvLSTM is constructed by replacing convolution operation at each gate of ConvLSTM with a depthwise separable convolution that enables producing robust long-range Spatio-temporal features while using substantially fewer parameters. We experimented with three fusion methods to combine the output feature maps of the two streams. Evaluation of the proposed methods was done on three standard public datasets. Our model outperforms the accuracy on the larger and more challenging RWF-2000 dataset by more than a 2% margin while matching state-of-the-art results on the smaller datasets. Our experiments lead us to conclude, the proposed models are superior in terms of both computational efficiency and detection accuracy.
Improving Action Quality Assessment using ResNets and Weighted Aggregation
Feb 21, 2021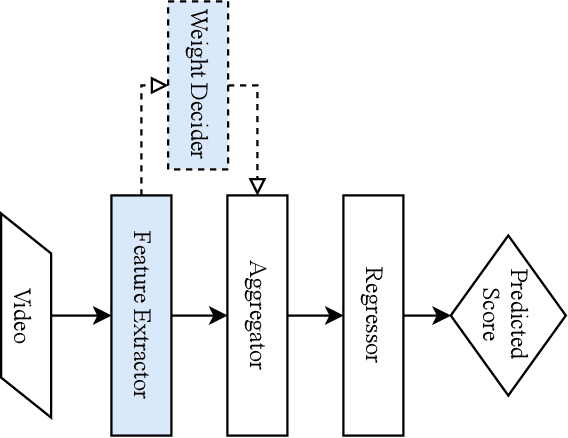
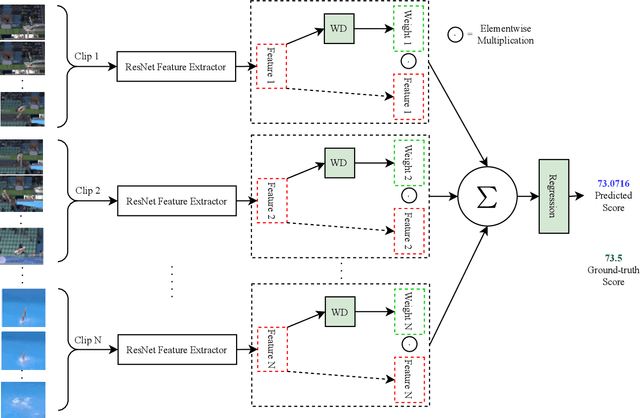
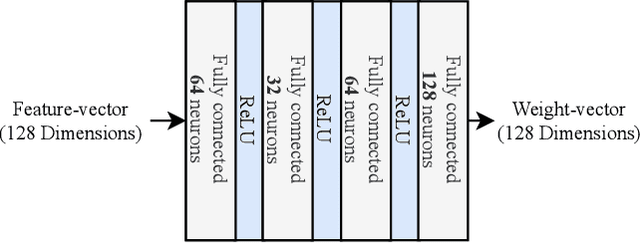
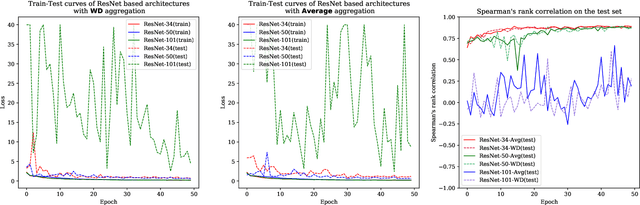
Action quality assessment (AQA) aims at automatically judging human action based on a video of the said action and assigning a performance score to it. The majority of works in the existing literature on AQA transform RGB videos to higher-level representations using C3D networks. These higher-level representations are used to perform action quality assessment. Due to the relatively shallow nature of C3D, the quality of extracted features is lower than what could be extracted using a deeper convolutional neural network. In this paper, we experiment with deeper convolutional neural networks with residual connections for learning representations for action quality assessment. We assess the effects of the depth and the input clip size of the convolutional neural network on the quality of action score predictions. We also look at the effect of using (2+1)D convolutions instead of 3D convolutions for feature extraction. We find that the current clip level feature representation aggregation technique of averaging is insufficient to capture the relative importance of features. To overcome this, we propose a learning-based weighted-averaging technique that can perform better. We achieve a new state-of-the-art Spearman's rank correlation of 0.9315 (an increase of 0.45%) on the MTL-AQA dataset using a 34 layer (2+1)D convolutional neural network with the capability of processing 32 frame clips, using our proposed aggregation technique.
How to train your conditional GAN: An approach using geometrically structured latent manifolds
Nov 30, 2020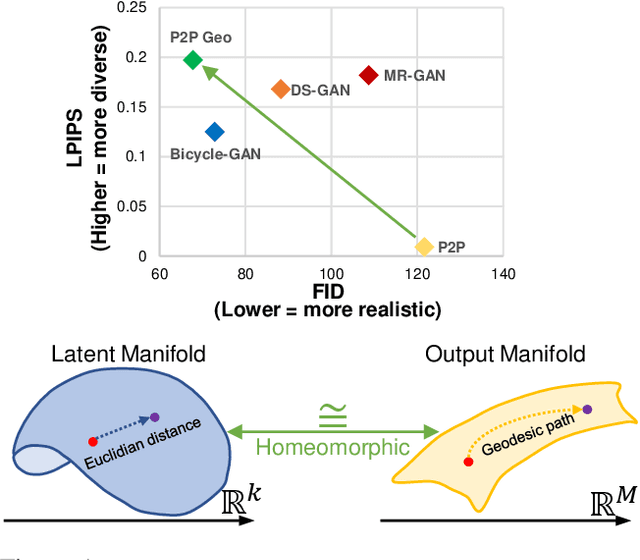


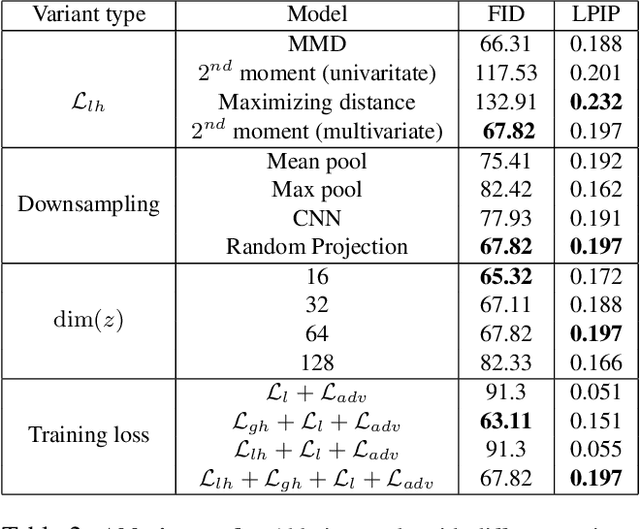
Conditional generative modeling typically requires capturing one-to-many mappings between the inputs and outputs. However, vanilla conditional GANs (cGAN) tend to ignore the variations of the latent seeds which results in mode-collapse. As a solution, recent works have moved towards comparatively expensive models for generating diverse outputs in a conditional setting. In this paper, we argue that the limited diversity of the vanilla cGANs is not due to a lack of capacity, but a result of non-optimal training schemes. We tackle this problem from a geometrical perspective and propose a novel training mechanism that increases both the diversity and the visual quality of the vanilla cGAN. The proposed solution does not demand architectural modifications and paves the way for more efficient architectures that target conditional generation in multi-modal spaces. We validate the efficacy of our model against a diverse set of tasks and show that the proposed solution is generic and effective across multiple datasets.
Attention Guided Semantic Relationship Parsing for Visual Question Answering
Oct 05, 2020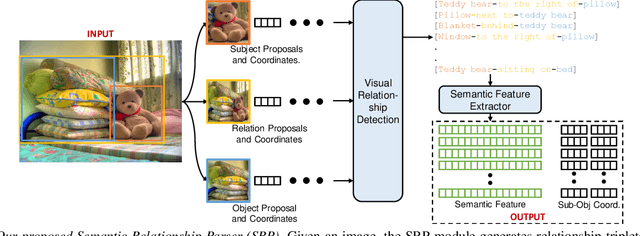
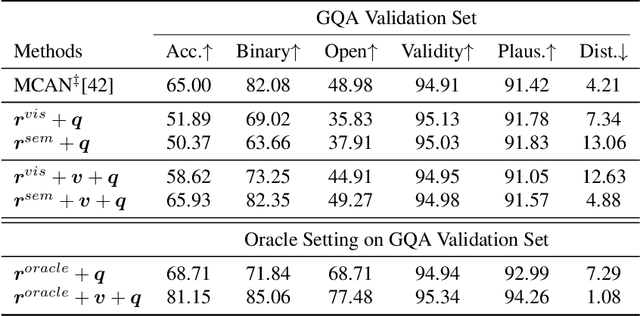
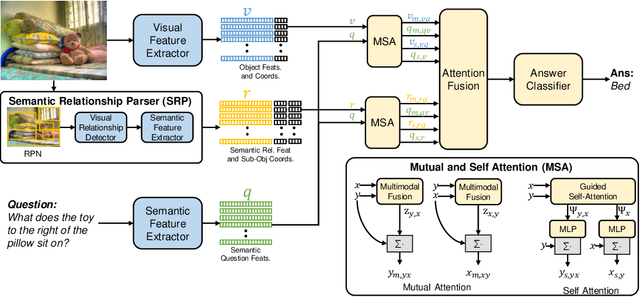
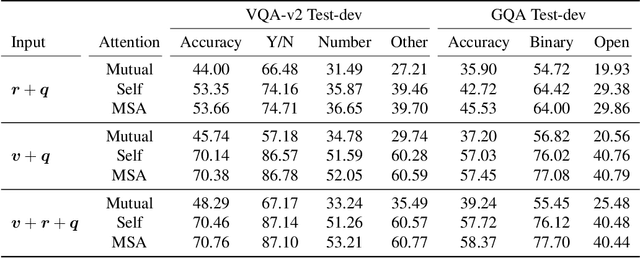
Humans explain inter-object relationships with semantic labels that demonstrate a high-level understanding required to perform complex Vision-Language tasks such as Visual Question Answering (VQA). However, existing VQA models represent relationships as a combination of object-level visual features which constrain a model to express interactions between objects in a single domain, while the model is trying to solve a multi-modal task. In this paper, we propose a general purpose semantic relationship parser which generates a semantic feature vector for each subject-predicate-object triplet in an image, and a Mutual and Self Attention (MSA) mechanism that learns to identify relationship triplets that are important to answer the given question. To motivate the significance of semantic relationships, we show an oracle setting with ground-truth relationship triplets, where our model achieves a ~25% accuracy gain over the closest state-of-the-art model on the challenging GQA dataset. Further, with our semantic parser, we show that our model outperforms other comparable approaches on VQA and GQA datasets.