 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifting Weak Supervision To Structured Prediction
Nov 24, 2022



Weak supervision (WS) is a rich set of techniques that produce pseudolabels by aggregating easily obtained but potentially noisy label estimates from a variety of sources. WS is theoretically well understood for binary classification, where simple approaches enable consistent estimation of pseudolabel noise rates. Using this result, it has been shown that downstream models trained on the pseudolabels have generalization guarantees nearly identical to those trained on clean labels. While this is exciting, users often wish to use WS for structured prediction, where the output space consists of more than a binary or multi-class label set: e.g. rankings, graphs, manifolds, and more. Do the favorable theoretical properties of WS for binary classification lift to this setting? We answer this question in the affirmative for a wide range of scenarios. For labels taking values in a finite metric space, we introduce techniques new to weak supervision based on pseudo-Euclidean embeddings and tensor decompositions, providing a nearly-consistent noise rate estimator. For labels in constant-curvature Riemannian manifolds, we introduce new invariants that also yield consistent noise rate estimation. In both cases, when using the resulting pseudolabels in concert with a flexible downstream model, we obtain generalization guarantees nearly identical to those for models trained on clean data. Several of our results, which can be viewed as robustness guarantees in structured prediction with noisy labels, may be of independent interest. Empirical evaluation validates our claims and shows the merits of the proposed method.
AutoML for Climate Change: A Call to Action
Oct 07, 2022

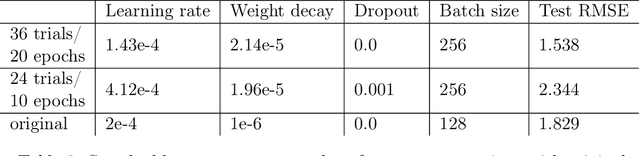

The challenge that climate change poses to humanity has spurred a rapidly developing field of artificial intelligence research focused on climate change applications. The climate change AI (CCAI) community works on a diverse, challenging set of problems which often involve physics-constrained ML or heterogeneous spatiotemporal data. It would be desirable to use automated machine learning (AutoML) techniques to automatically find high-performing architectures and hyperparameters for a given dataset. In this work, we benchmark popular AutoML libraries on three high-leverage CCAI applications: climate modeling, wind power forecasting, and catalyst discovery. We find that out-of-the-box AutoML libraries currently fail to meaningfully surpass the performance of human-designed CCAI models. However, we also identify a few key weaknesses, which stem from the fact that most AutoML techniques are tailored to computer vision and NLP applications. For example, while dozens of search spaces have been designed for image and language data, none have been designed for spatiotemporal data. Addressing these key weaknesses can lead to the discovery of novel architectures that yield substantial performance gains across numerous CCAI applications. Therefore, we present a call to action to the AutoML community, since there are a number of concrete, promising directions for future work in the space of AutoML for CCAI. We release our code and a list of resources at https://github.com/climate-change-automl/climate-change-automl.
AutoWS-Bench-101: Benchmarking Automated Weak Supervision with 100 Labels
Aug 30, 2022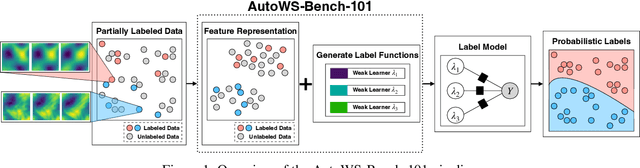
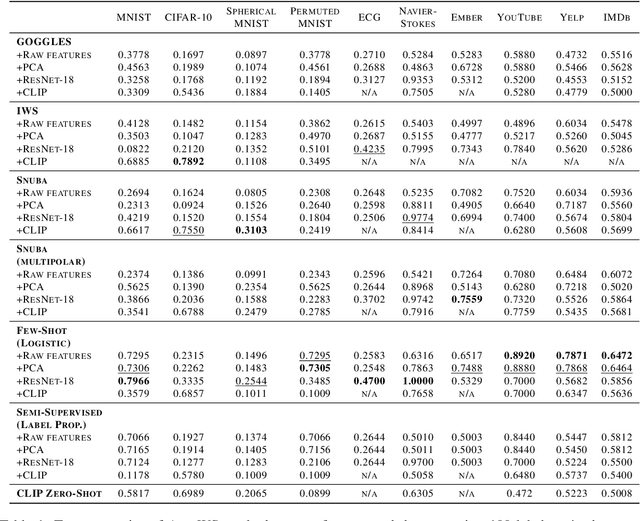
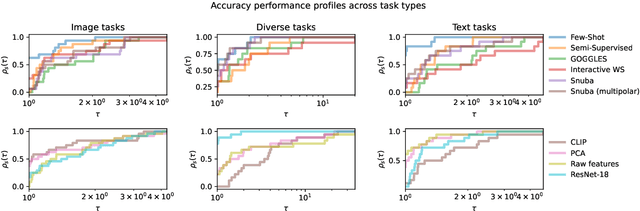
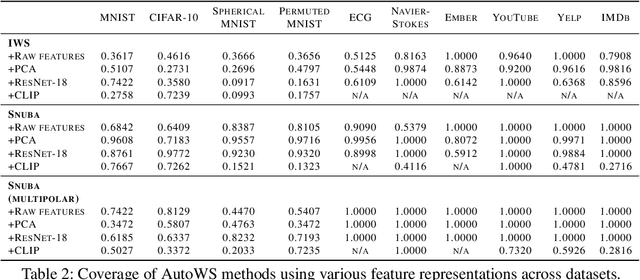
Weak supervision (WS) is a powerful method to build labeled datasets for training supervised models in the face of little-to-no labeled data. It replaces hand-labeling data with aggregating multiple noisy-but-cheap label estimates expressed by labeling functions (LFs). While it has been used successfully in many domains, weak supervision's application scope is limited by the difficulty of constructing labeling functions for domains with complex or high-dimensional features. To address this, a handful of methods have proposed automating the LF design process using a small set of ground truth labels. In this work, we introduce AutoWS-Bench-101: a framework for evaluating automated WS (AutoWS) techniques in challenging WS settings -- a set of diverse application domains on which it has been previously difficult or impossible to apply traditional WS techniques. While AutoWS is a promising direction toward expanding the application-scope of WS, the emergence of powerful methods such as zero-shot foundation models reveals the need to understand how AutoWS techniques compare or cooperate with modern zero-shot or few-shot learners. This informs the central question of AutoWS-Bench-101: given an initial set of 100 labels for each task, we ask whether a practitioner should use an AutoWS method to generate additional labels or use some simpler baseline, such as zero-shot predictions from a foundation model or supervised learning. We observe that in many settings, it is necessary for AutoWS methods to incorporate signal from foundation models if they are to outperform simple few-shot baselines, and AutoWS-Bench-101 promotes future research in this direction. We conclude with a thorough ablation study of AutoWS methods.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Generative Modeling Helps Weak Supervision (and Vice Versa)
Mar 22, 2022
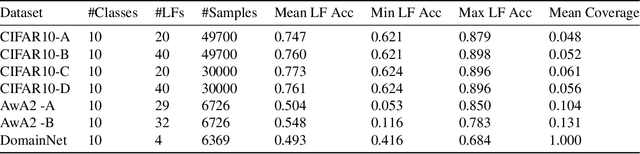
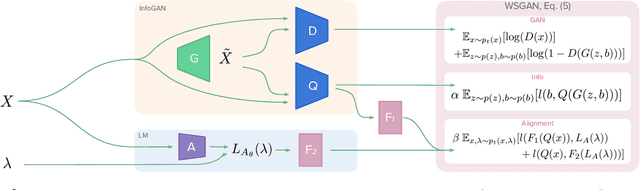
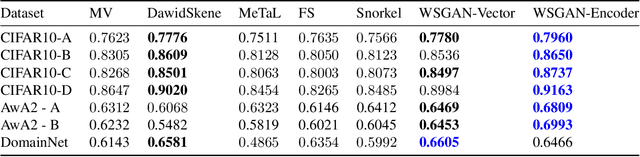
Many promising applications of supervised machine learning face hurdles in the acquisition of labeled data in sufficient quantity and quality, creating an expensive bottleneck. To overcome such limitations, techniques that do not depend on ground truth labels have been developed, including weak supervision and generative modeling. While these techniques would seem to be usable in concert, improving one another, how to build an interface between them is not well-understood. In this work, we propose a model fusing weak supervision and generative adversarial networks. It captures discrete variables in the data alongside the weak supervision derived label estimate. Their alignment allows for better modeling of sample-dependent accuracies of the weak supervision sources, improving the unobserved ground truth estimate. It is the first approach to enable data augmentation through weakly supervised synthetic images and pseudolabels. Additionally, its learned discrete variables can be inspected qualitatively. The model outperforms baseline weak supervision label models on a number of multiclass classification datasets, improves the quality of generated images, and further improves end-model performance through data augmentation with synthetic samples.
Universalizing Weak Supervision
Dec 07, 2021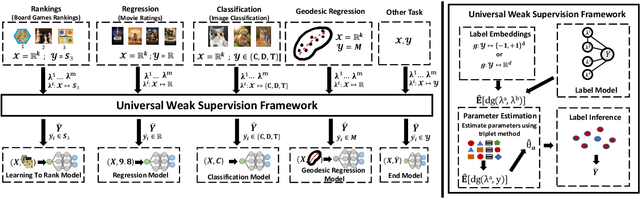
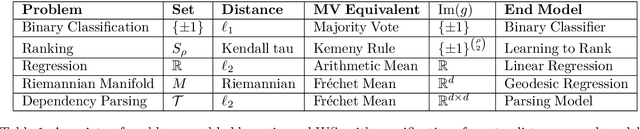
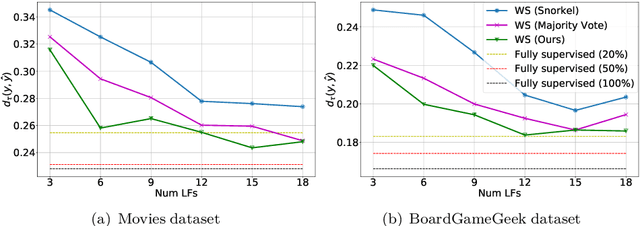
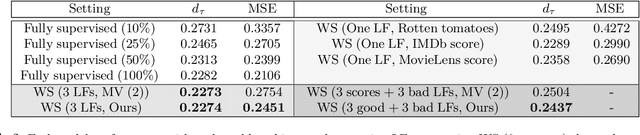
Weak supervision (WS) frameworks are a popular way to bypass hand-labeling large datasets for training data-hungry models. These approaches synthesize multiple noisy but cheaply-acquired estimates of labels into a set of high-quality pseudolabels for downstream training. However, the synthesis technique is specific to a particular kind of label, such as binary labels or sequences, and each new label type requires manually designing a new synthesis algorithm. Instead, we propose a universal technique that enables weak supervision over any label type while still offering desirable properties, including practical flexibility, computational efficiency, and theoretical guarantees. We apply this technique to important problems previously not tackled by WS frameworks including learning to rank, regression, and learning in hyperbolic manifolds. Theoretically, our synthesis approach produces a consistent estimator for learning a challenging but important generalization of the exponential family model. Experimentally, we validate our framework and show improvement over baselines in diverse settings including real-world learning-to-rank and regression problems along with learning on hyperbolic manifolds.
NAS-Bench-360: Benchmarking Diverse Tasks for Neural Architecture Search
Oct 26, 2021
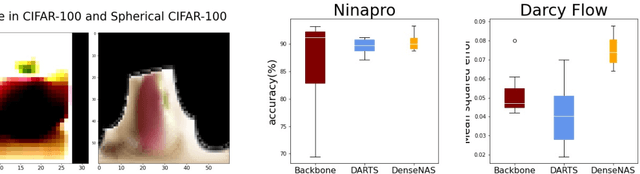
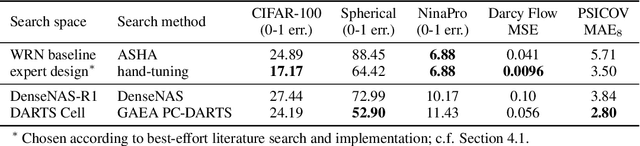
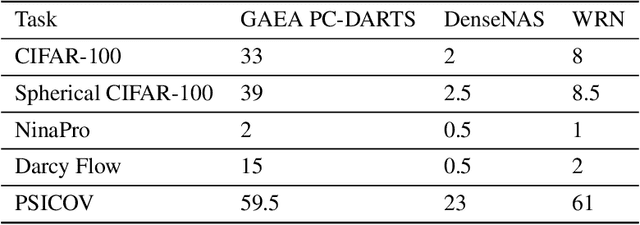
Most existing neural architecture search (NAS) benchmarks and algorithms prioritize performance on well-studied tasks, e.g., image classification on CIFAR and ImageNet. This makes the applicability of NAS approaches in more diverse areas inadequately understood. In this paper, we present NAS-Bench-360, a benchmark suite for evaluating state-of-the-art NAS methods for convolutional neural networks (CNNs). To construct it, we curate a collection of ten tasks spanning a diverse array of application domains, dataset sizes, problem dimensionalities, and learning objectives. By carefully selecting tasks that can both interoperate with modern CNN-based search methods but that are also far-afield from their original development domain, we can use NAS-Bench-360 to investigate the following central question: do existing state-of-the-art NAS methods perform well on diverse tasks? Our experiments show that a modern NAS procedure designed for image classification can indeed find good architectures for tasks with other dimensionalities and learning objectives; however, the same method struggles against more task-specific methods and performs catastrophically poorly on classification in non-vision domains. The case for NAS robustness becomes even more dire in a resource-constrained setting, where a recent NAS method provides little-to-no benefit over much simpler baselines. These results demonstrate the need for a benchmark such as NAS-Bench-360 to help develop NAS approaches that work well on a variety of tasks, a crucial component of a truly robust and automated pipeline. We conclude with a demonstration of the kind of future research our suite of tasks will enable. All data and code is made publicly available.
Rethinking Neural Operations for Diverse Tasks
Mar 29, 2021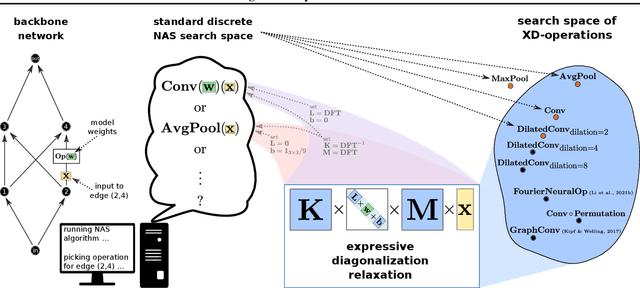
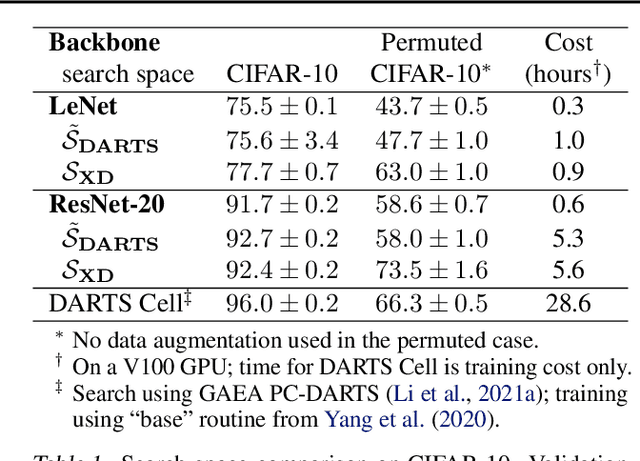
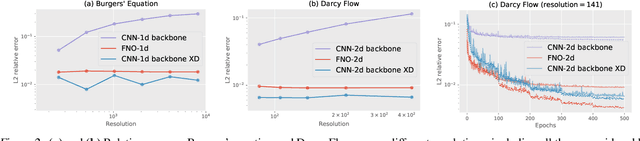

An important goal of neural architecture search (NAS) is to automate-away the design of neural networks on new tasks in under-explored domains. Motivated by this broader vision for NAS, we study the problem of enabling users to discover the right neural operations given data from their specific domain. We introduce a search space of neural operations called XD-Operations that mimic the inductive bias of standard multichannel convolutions while being much more expressive: we prove that XD-operations include many named operations across several application areas. Starting with any standard backbone network such as LeNet or ResNet, we show how to transform it into an architecture search space over XD-operations and how to traverse the space using a simple weight-sharing scheme. On a diverse set of applications--image classification, solving partial differential equations (PDEs), and sequence modeling--our approach consistently yields models with lower error than baseline networks and sometimes even lower error than expert-designed domain-specific approaches.
Decoding and Diversity in Machine Translation
Nov 26, 2020

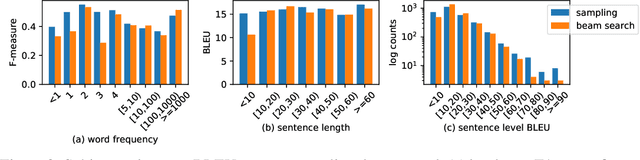
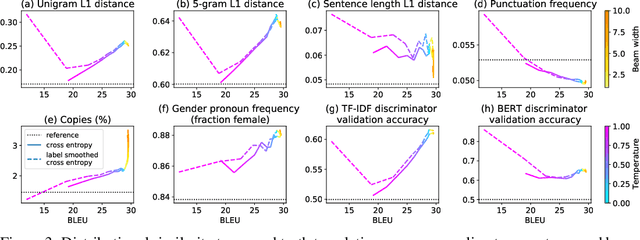
Neural Machine Translation (NMT) systems are typically evaluated using automated metrics that assess the agreement between generated translations and ground truth candidates. To improve systems with respect to these metrics, NLP researchers employ a variety of heuristic techniques, including searching for the conditional mode (vs. sampling) and incorporating various training heuristics (e.g., label smoothing). While search strategies significantly improve BLEU score, they yield deterministic outputs that lack the diversity of human translations. Moreover, search tends to bias the distribution of translated gender pronouns. This makes human-level BLEU a misleading benchmark in that modern MT systems cannot approach human-level BLEU while simultaneously maintaining human-level translation diversity. In this paper, we characterize distributional differences between generated and real translations, examining the cost in diversity paid for the BLEU scores enjoyed by NMT. Moreover, our study implicates search as a salient source of known bias when translating gender pronouns.
Model Weight Theft With Just Noise Inputs: The Curious Case of the Petulant Attacker
Dec 19, 2019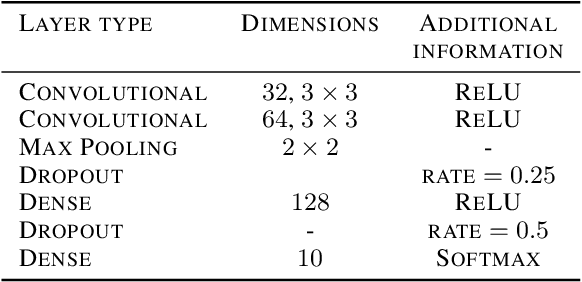
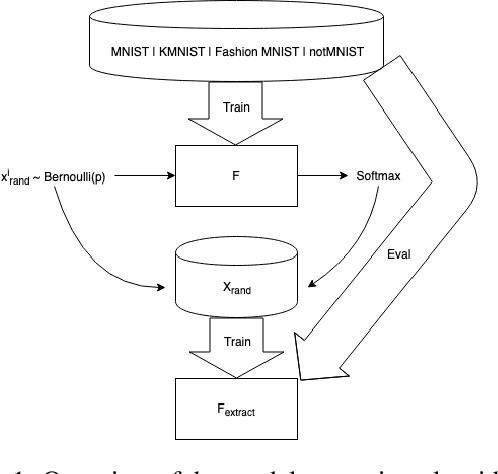

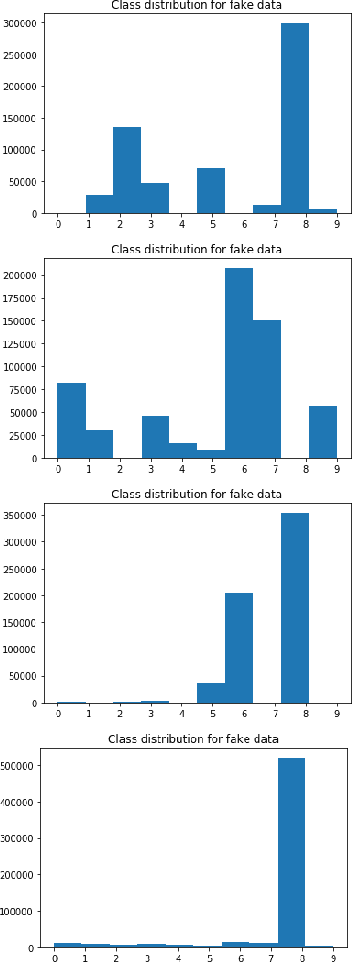
This paper explores the scenarios under which an attacker can claim that 'Noise and access to the softmax layer of the model is all you need' to steal the weights of a convolutional neural network whose architecture is already known. We were able to achieve 96% test accuracy using the stolen MNIST model and 82% accuracy using the stolen KMNIST model learned using only i.i.d. Bernoulli noise inputs. We posit that this theft-susceptibility of the weights is indicative of the complexity of the dataset and propose a new metric that captures the same. The goal of this dissemination is to not just showcase how far knowing the architecture can take you in terms of model stealing, but to also draw attention to this rather idiosyncratic weight learnability aspects of CNNs spurred by i.i.d. noise input. We also disseminate some initial results obtained with using the Ising probability distribution in lieu of the i.i.d. Bernoulli distribution.