 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptWise: Online Learning for Cost-Aware Prompt Assignment in Generative Models
May 24, 2025



The rapid advancement of generative AI models has provided users with numerous options to address their prompts. When selecting a generative AI model for a given prompt, users should consider not only the performance of the chosen model but also its associated service cost. The principle guiding such consideration is to select the least expensive model among the available satisfactory options. However, existing model-selection approaches typically prioritize performance, overlooking pricing differences between models. In this paper, we introduce PromptWise, an online learning framework designed to assign a sequence of prompts to a group of large language models (LLMs) in a cost-effective manner. PromptWise strategically queries cheaper models first, progressing to more expensive options only if the lower-cost models fail to adequately address a given prompt. Through numerical experiments, we demonstrate PromptWise's effectiveness across various tasks, including puzzles of varying complexity and code generation/translation tasks. The results highlight that PromptWise consistently outperforms cost-unaware baseline methods, emphasizing that directly assigning prompts to the most expensive models can lead to higher costs and potentially lower average performance.
AutoWS-Bench-101: Benchmarking Automated Weak Supervision with 100 Labels
Aug 30, 2022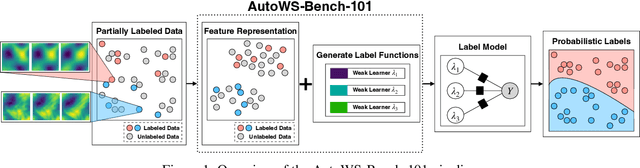
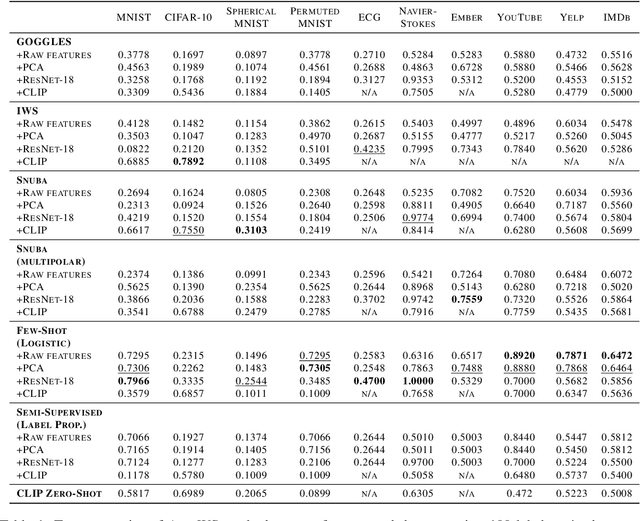
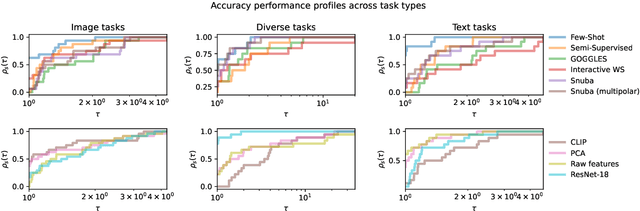
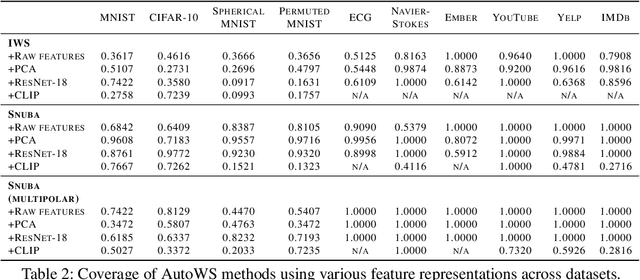
Weak supervision (WS) is a powerful method to build labeled datasets for training supervised models in the face of little-to-no labeled data. It replaces hand-labeling data with aggregating multiple noisy-but-cheap label estimates expressed by labeling functions (LFs). While it has been used successfully in many domains, weak supervision's application scope is limited by the difficulty of constructing labeling functions for domains with complex or high-dimensional features. To address this, a handful of methods have proposed automating the LF design process using a small set of ground truth labels. In this work, we introduce AutoWS-Bench-101: a framework for evaluating automated WS (AutoWS) techniques in challenging WS settings -- a set of diverse application domains on which it has been previously difficult or impossible to apply traditional WS techniques. While AutoWS is a promising direction toward expanding the application-scope of WS, the emergence of powerful methods such as zero-shot foundation models reveals the need to understand how AutoWS techniques compare or cooperate with modern zero-shot or few-shot learners. This informs the central question of AutoWS-Bench-101: given an initial set of 100 labels for each task, we ask whether a practitioner should use an AutoWS method to generate additional labels or use some simpler baseline, such as zero-shot predictions from a foundation model or supervised learning. We observe that in many settings, it is necessary for AutoWS methods to incorporate signal from foundation models if they are to outperform simple few-shot baselines, and AutoWS-Bench-101 promotes future research in this direction. We conclude with a thorough ablation study of AutoWS methods.