 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Graph-Based Retrieval for Large Language Models
Jan 04, 2025As large language models (LLMs) evolve, their ability to deliver personalized and context-aware responses offers transformative potential for improving user experiences. Existing personalization approaches, however, often rely solely on user history to augment the prompt, limiting their effectiveness in generating tailored outputs, especially in cold-start scenarios with sparse data. To address these limitations, we propose Personalized Graph-based Retrieval-Augmented Generation (PGraphRAG), a framework that leverages user-centric knowledge graphs to enrich personalization. By directly integrating structured user knowledge into the retrieval process and augmenting prompts with user-relevant context, PGraphRAG enhances contextual understanding and output quality. We also introduce the Personalized Graph-based Benchmark for Text Generation, designed to evaluate personalized text generation tasks in real-world settings where user history is sparse or unavailable. Experimental results show that PGraphRAG significantly outperforms state-of-the-art personalization methods across diverse tasks, demonstrating the unique advantages of graph-based retrieval for personalization.
Multi-LLM Text Summarization
Dec 20, 2024



In this work, we propose a Multi-LLM summarization framework, and investigate two different multi-LLM strategies including centralized and decentralized. Our multi-LLM summarization framework has two fundamentally important steps at each round of conversation: generation and evaluation. These steps are different depending on whether our multi-LLM decentralized summarization is used or centralized. In both our multi-LLM decentralized and centralized strategies, we have k different LLMs that generate diverse summaries of the text. However, during evaluation, our multi-LLM centralized summarization approach leverages a single LLM to evaluate the summaries and select the best one whereas k LLMs are used for decentralized multi-LLM summarization. Overall, we find that our multi-LLM summarization approaches significantly outperform the baselines that leverage only a single LLM by up to 3x. These results indicate the effectiveness of multi-LLM approaches for summarization.
GUI Agents: A Survey
Dec 18, 2024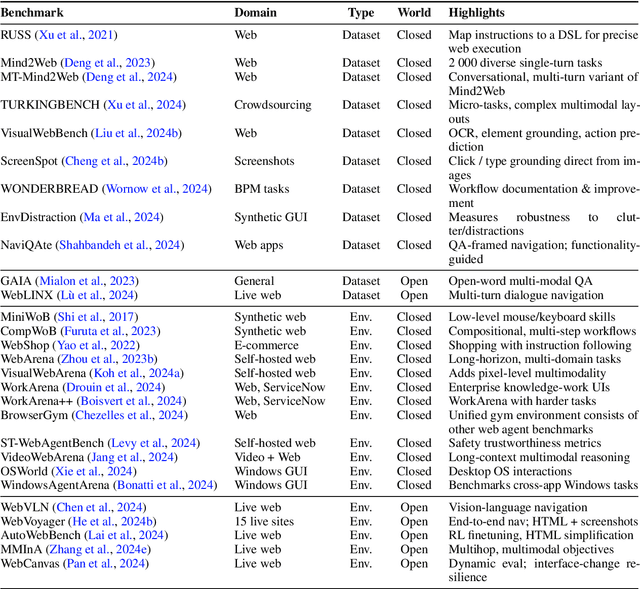
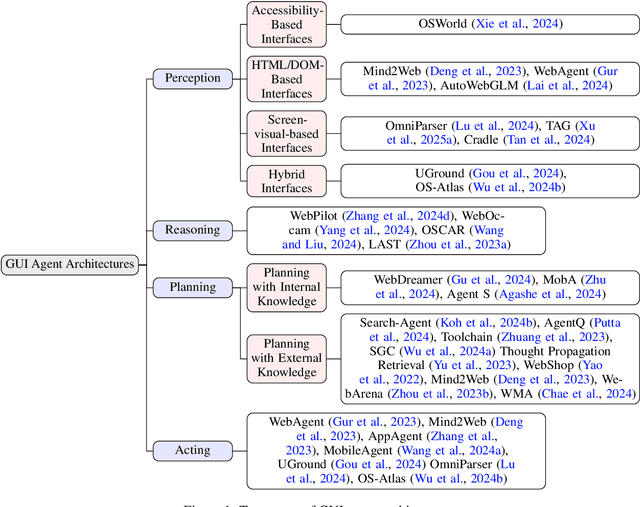

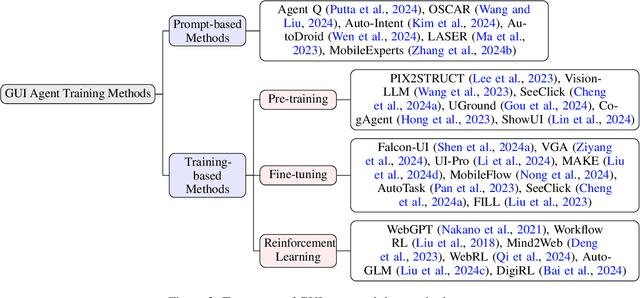
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
Personalized Multimodal Large Language Models: A Survey
Dec 03, 2024Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy. This paper presents a comprehensive survey on personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users, and discuss the techniques accordingly. Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used. Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.
GRS-QA -- Graph Reasoning-Structured Question Answering Dataset
Nov 01, 2024



Large Language Models (LLMs) have excelled in multi-hop question-answering (M-QA) due to their advanced reasoning abilities. However, the impact of the inherent reasoning structures on LLM M-QA performance remains unclear, largely due to the absence of QA datasets that provide fine-grained reasoning structures. To address this gap, we introduce the Graph Reasoning-Structured Question Answering Dataset (GRS-QA), which includes both semantic contexts and reasoning structures for QA pairs. Unlike existing M-QA datasets, where different reasoning structures are entangled together, GRS-QA explicitly captures intricate reasoning pathways by constructing reasoning graphs, where nodes represent textual contexts and edges denote logical flows. These reasoning graphs of different structures enable a fine-grained evaluation of LLM reasoning capabilities across various reasoning structures. Our empirical analysis reveals that LLMs perform differently when handling questions with varying reasoning structures. This finding facilitates the exploration of textual structures as compared with semantics.
CodeRosetta: Pushing the Boundaries of Unsupervised Code Translation for Parallel Programming
Oct 27, 2024



Recent advancements in Large Language Models (LLMs) have renewed interest in automatic programming language translation. Encoder-decoder transformer models, in particular, have shown promise in translating between different programming languages. However, translating between a language and its high-performance computing (HPC) extensions remains underexplored due to challenges such as complex parallel semantics. In this paper, we introduce CodeRosetta, an encoder-decoder transformer model designed specifically for translating between programming languages and their HPC extensions. CodeRosetta is evaluated on C++ to CUDA and Fortran to C++ translation tasks. It uses a customized learning framework with tailored pretraining and training objectives to effectively capture both code semantics and parallel structural nuances, enabling bidirectional translation. Our results show that CodeRosetta outperforms state-of-the-art baselines in C++ to CUDA translation by 2.9 BLEU and 1.72 CodeBLEU points while improving compilation accuracy by 6.05%. Compared to general closed-source LLMs, our method improves C++ to CUDA translation by 22.08 BLEU and 14.39 CodeBLEU, with 2.75% higher compilation accuracy. Finally, CodeRosetta exhibits proficiency in Fortran to parallel C++ translation, marking it, to our knowledge, as the first encoder-decoder model for this complex task, improving CodeBLEU by at least 4.63 points compared to closed-source and open-code LLMs.
A Survey of Small Language Models
Oct 25, 2024


Small Language Models (SLMs) have become increasingly important due to their efficiency and performance to perform various language tasks with minimal computational resources, making them ideal for various settings including on-device, mobile, edge devices, among many others. In this article, we present a comprehensive survey on SLMs, focusing on their architectures, training techniques, and model compression techniques. We propose a novel taxonomy for categorizing the methods used to optimize SLMs, including model compression, pruning, and quantization techniques. We summarize the benchmark datasets that are useful for benchmarking SLMs along with the evaluation metrics commonly used. Additionally, we highlight key open challenges that remain to be addressed. Our survey aims to serve as a valuable resource for researchers and practitioners interested in developing and deploying small yet efficient language models.
Large Generative Graph Models
Jun 07, 2024



Large Generative Models (LGMs) such as GPT, Stable Diffusion, Sora, and Suno are trained on a huge amount of language corpus, images, videos, and audio that are extremely diverse from numerous domains. This training paradigm over diverse well-curated data lies at the heart of generating creative and sensible content. However, all previous graph generative models (e.g., GraphRNN, MDVAE, MoFlow, GDSS, and DiGress) have been trained only on one dataset each time, which cannot replicate the revolutionary success achieved by LGMs in other fields. To remedy this crucial gap, we propose a new class of graph generative model called Large Graph Generative Model (LGGM) that is trained on a large corpus of graphs (over 5000 graphs) from 13 different domains. We empirically demonstrate that the pre-trained LGGM has superior zero-shot generative capability to existing graph generative models. Furthermore, our pre-trained LGGM can be easily fine-tuned with graphs from target domains and demonstrate even better performance than those directly trained from scratch, behaving as a solid starting point for real-world customization. Inspired by Stable Diffusion, we further equip LGGM with the capability to generate graphs given text prompts (Text-to-Graph), such as the description of the network name and domain (i.e., "The power-1138-bus graph represents a network of buses in a power distribution system."), and network statistics (i.e., "The graph has a low average degree, suitable for modeling social media interactions."). This Text-to-Graph capability integrates the extensive world knowledge in the underlying language model, offering users fine-grained control of the generated graphs. We release the code, the model checkpoint, and the datasets at https://lggm-lg.github.io/.
A structure-aware framework for learning device placements on computation graphs
May 23, 2024



Existing approaches for device placement ignore the topological features of computation graphs and rely mostly on heuristic methods for graph partitioning. At the same time, they either follow a grouper-placer or an encoder-placer architecture, which requires understanding the interaction structure between code operations. To bridge the gap between encoder-placer and grouper-placer techniques, we propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit using reinforcement learning. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into consideration the directed and acyclic nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and personalized graph partitioning jointly, using an unspecified number of groups. To train the entire framework, we utilize reinforcement learning techniques by employing the execution time of the suggested device placements to formulate the reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.
Structure Guided Prompt: Instructing Large Language Model in Multi-Step Reasoning by Exploring Graph Structure of the Text
Feb 20, 2024



Although Large Language Models (LLMs) excel at addressing straightforward reasoning tasks, they frequently struggle with difficulties when confronted by more complex multi-step reasoning due to a range of factors. Firstly, natural language often encompasses complex relationships among entities, making it challenging to maintain a clear reasoning chain over longer spans. Secondly, the abundance of linguistic diversity means that the same entities and relationships can be expressed using different terminologies and structures, complicating the task of identifying and establishing connections between multiple pieces of information. Graphs provide an effective solution to represent data rich in relational information and capture long-term dependencies among entities. To harness the potential of graphs, our paper introduces Structure Guided Prompt, an innovative three-stage task-agnostic prompting framework designed to improve the multi-step reasoning capabilities of LLMs in a zero-shot setting. This framework explicitly converts unstructured text into a graph via LLMs and instructs them to navigate this graph using task-specific strategies to formulate responses. By effectively organizing information and guiding navigation, it enables LLMs to provide more accurate and context-aware responses. Our experiments show that this framework significantly enhances the reasoning capabilities of LLMs, enabling them to excel in a broader spectrum of natural language scenarios.