 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks as Microscopes: A Call for Model Metrology
Jul 22, 2024Modern language models (LMs) pose a new challenge in capability assessment. Static benchmarks inevitably saturate without providing confidence in the deployment tolerances of LM-based systems, but developers nonetheless claim that their models have generalized traits such as reasoning or open-domain language understanding based on these flawed metrics. The science and practice of LMs requires a new approach to benchmarking which measures specific capabilities with dynamic assessments. To be confident in our metrics, we need a new discipline of model metrology -- one which focuses on how to generate benchmarks that predict performance under deployment. Motivated by our evaluation criteria, we outline how building a community of model metrology practitioners -- one focused on building tools and studying how to measure system capabilities -- is the best way to meet these needs to and add clarity to the AI discussion.
ChatGPT Doesn't Trust Chargers Fans: Guardrail Sensitivity in Context
Jul 10, 2024



While the biases of language models in production are extensively documented, the biases of their guardrails have been neglected. This paper studies how contextual information about the user influences the likelihood of an LLM to refuse to execute a request. By generating user biographies that offer ideological and demographic information, we find a number of biases in guardrail sensitivity on GPT-3.5. Younger, female, and Asian-American personas are more likely to trigger a refusal guardrail when requesting censored or illegal information. Guardrails are also sycophantic, refusing to comply with requests for a political position the user is likely to disagree with. We find that certain identity groups and seemingly innocuous information, e.g., sports fandom, can elicit changes in guardrail sensitivity similar to direct statements of political ideology. For each demographic category and even for American football team fandom, we find that ChatGPT appears to infer a likely political ideology and modify guardrail behavior accordingly.
Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
Jun 25, 2024



Memorization in language models is typically treated as a homogenous phenomenon, neglecting the specifics of the memorized data. We instead model memorization as the effect of a set of complex factors that describe each sample and relate it to the model and corpus. To build intuition around these factors, we break memorization down into a taxonomy: recitation of highly duplicated sequences, reconstruction of inherently predictable sequences, and recollection of sequences that are neither. We demonstrate the usefulness of our taxonomy by using it to construct a predictive model for memorization. By analyzing dependencies and inspecting the weights of the predictive model, we find that different factors influence the likelihood of memorization differently depending on the taxonomic category.
Transcendence: Generative Models Can Outperform The Experts That Train Them
Jun 17, 2024


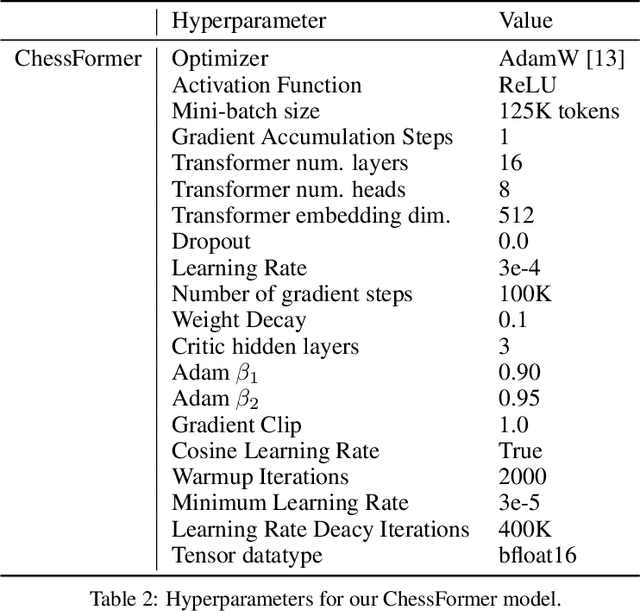
Generative models are trained with the simple objective of imitating the conditional probability distribution induced by the data they are trained on. Therefore, when trained on data generated by humans, we may not expect the artificial model to outperform the humans on their original objectives. In this work, we study the phenomenon of transcendence: when a generative model achieves capabilities that surpass the abilities of the experts generating its data. We demonstrate transcendence by training an autoregressive transformer to play chess from game transcripts, and show that the trained model can sometimes achieve better performance than all players in the dataset. We theoretically prove that transcendence is enabled by low-temperature sampling, and rigorously assess this experimentally. Finally, we discuss other sources of transcendence, laying the groundwork for future investigation of this phenomenon in a broader setting.
Knowing Your Nonlinearities: Shapley Interactions Reveal the Underlying Structure of Data
Mar 19, 2024Measuring nonlinear feature interaction is an established approach to understanding complex patterns of attribution in many models. In this paper, we use Shapley Taylor interaction indices (STII) to analyze the impact of underlying data structure on model representations in a variety of modalities, tasks, and architectures. Considering linguistic structure in masked and auto-regressive language models (MLMs and ALMs), we find that STII increases within idiomatic expressions and that MLMs scale STII with syntactic distance, relying more on syntax in their nonlinear structure than ALMs do. Our speech model findings reflect the phonetic principal that the openness of the oral cavity determines how much a phoneme varies based on its context. Finally, we study image classifiers and illustrate that feature interactions intuitively reflect object boundaries. Our wide range of results illustrates the benefits of interdisciplinary work and domain expertise in interpretability research.
Towards out-of-distribution generalization in large-scale astronomical surveys: robust networks learn similar representations
Nov 29, 2023The generalization of machine learning (ML) models to out-of-distribution (OOD) examples remains a key challenge in extracting information from upcoming astronomical surveys. Interpretability approaches are a natural way to gain insights into the OOD generalization problem. We use Centered Kernel Alignment (CKA), a similarity measure metric of neural network representations, to examine the relationship between representation similarity and performance of pre-trained Convolutional Neural Networks (CNNs) on the CAMELS Multifield Dataset. We find that when models are robust to a distribution shift, they produce substantially different representations across their layers on OOD data. However, when they fail to generalize, these representations change less from layer to layer on OOD data. We discuss the potential application of similarity representation in guiding model design, training strategy, and mitigating the OOD problem by incorporating CKA as an inductive bias during training.
Attribute Diversity Determines the Systematicity Gap in VQA
Nov 15, 2023



The degree to which neural networks can generalize to new combinations of familiar concepts, and the conditions under which they are able to do so, has long been an open question. In this work, we study the systematicity gap in visual question answering: the performance difference between reasoning on previously seen and unseen combinations of object attributes. To test, we introduce a novel diagnostic dataset, CLEVR-HOPE. We find that while increased quantity of training data does not reduce the systematicity gap, increased training data diversity of the attributes in the unseen combination does. In all, our experiments suggest that the more distinct attribute type combinations are seen during training, the more systematic we can expect the resulting model to be.
First Tragedy, then Parse: History Repeats Itself in the New Era of Large Language Models
Nov 08, 2023

Many NLP researchers are experiencing an existential crisis triggered by the astonishing success of ChatGPT and other systems based on large language models (LLMs). After such a disruptive change to our understanding of the field, what is left to do? Taking a historical lens, we look for guidance from the first era of LLMs, which began in 2005 with large $n$-gram models for machine translation. We identify durable lessons from the first era, and more importantly, we identify evergreen problems where NLP researchers can continue to make meaningful contributions in areas where LLMs are ascendant. Among these lessons, we discuss the primacy of hardware advancement in shaping the availability and importance of scale, as well as the urgent challenge of quality evaluation, both automated and human. We argue that disparities in scale are transient and that researchers can work to reduce them; that data, rather than hardware, is still a bottleneck for many meaningful applications; that meaningful evaluation informed by actual use is still an open problem; and that there is still room for speculative approaches.
TRAM: Bridging Trust Regions and Sharpness Aware Minimization
Oct 05, 2023



By reducing the curvature of the loss surface in the parameter space, Sharpness-aware minimization (SAM) yields widespread robustness improvement under domain transfer. Instead of focusing on parameters, however, this work considers the transferability of representations as the optimization target for out-of-domain generalization in a fine-tuning setup. To encourage the retention of transferable representations, we consider trust region-based fine-tuning methods, which exploit task-specific skills without forgetting task-agnostic representations from pre-training. We unify parameter- and representation-space smoothing approaches by using trust region bounds to inform SAM-style regularizers on both of these optimization surfaces. We propose Trust Region Aware Minimization (TRAM), a fine-tuning algorithm that optimizes for flat minima and smooth, informative representations without forgetting pre-trained structure. We find that TRAM outperforms both sharpness-aware and trust region-based optimization methods on cross-domain language modeling and cross-lingual transfer, where robustness to domain transfer and representation generality are critical for success. TRAM establishes a new standard in training generalizable models with minimal additional computation.
Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in MLMs
Sep 28, 2023



Most interpretability research in NLP focuses on understanding the behavior and features of a fully trained model. However, certain insights into model behavior may only be accessible by observing the trajectory of the training process. We present a case study of syntax acquisition in masked language models (MLMs) that demonstrates how analyzing the evolution of interpretable artifacts throughout training deepens our understanding of emergent behavior. In particular, we study Syntactic Attention Structure (SAS), a naturally emerging property of MLMs wherein specific Transformer heads tend to focus on specific syntactic relations. We identify a brief window in pretraining when models abruptly acquire SAS, concurrent with a steep drop in loss. This breakthrough precipitates the subsequent acquisition of linguistic capabilities. We then examine the causal role of SAS by manipulating SAS during training, and demonstrate that SAS is necessary for the development of grammatical capabilities. We further find that SAS competes with other beneficial traits during training, and that briefly suppressing SAS improves model quality. These findings offer an interpretation of a real-world example of both simplicity bias and breakthrough training dynamics.