 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom English to More Languages: Parameter-Efficient Model Reprogramming for Cross-Lingual Speech Recognition
Jan 19, 2023



In this work, we propose a new parameter-efficient learning framework based on neural model reprogramming for cross-lingual speech recognition, which can \textbf{re-purpose} well-trained English automatic speech recognition (ASR) models to recognize the other languages. We design different auxiliary neural architectures focusing on learnable pre-trained feature enhancement that, for the first time, empowers model reprogramming on ASR. Specifically, we investigate how to select trainable components (i.e., encoder) of a conformer-based RNN-Transducer, as a frozen pre-trained backbone. Experiments on a seven-language multilingual LibriSpeech speech (MLS) task show that model reprogramming only requires 4.2% (11M out of 270M) to 6.8% (45M out of 660M) of its original trainable parameters from a full ASR model to perform competitive results in a range of 11.9% to 8.1% WER averaged across different languages. In addition, we discover different setups to make large-scale pre-trained ASR succeed in both monolingual and multilingual speech recognition. Our methods outperform existing ASR tuning architectures and their extension with self-supervised losses (e.g., w2v-bert) in terms of lower WER and better training efficiency.
A Quantum Kernel Learning Approach to Acoustic Modeling for Spoken Command Recognition
Nov 02, 2022We propose a quantum kernel learning (QKL) framework to address the inherent data sparsity issues often encountered in training large-scare acoustic models in low-resource scenarios. We project acoustic features based on classical-to-quantum feature encoding. Different from existing quantum convolution techniques, we utilize QKL with features in the quantum space to design kernel-based classifiers. Experimental results on challenging spoken command recognition tasks for a few low-resource languages, such as Arabic, Georgian, Chuvash, and Lithuanian, show that the proposed QKL-based hybrid approach attains good improvements over existing classical and quantum solutions.
Residual Adapters for Few-Shot Text-to-Speech Speaker Adaptation
Oct 28, 2022



Adapting a neural text-to-speech (TTS) model to a target speaker typically involves fine-tuning most if not all of the parameters of a pretrained multi-speaker backbone model. However, serving hundreds of fine-tuned neural TTS models is expensive as each of them requires significant footprint and separate computational resources (e.g., accelerators, memory). To scale speaker adapted neural TTS voices to hundreds of speakers while preserving the naturalness and speaker similarity, this paper proposes a parameter-efficient few-shot speaker adaptation, where the backbone model is augmented with trainable lightweight modules called residual adapters. This architecture allows the backbone model to be shared across different target speakers. Experimental results show that the proposed approach can achieve competitive naturalness and speaker similarity compared to the full fine-tuning approaches, while requiring only $\sim$0.1% of the backbone model parameters for each speaker.
Maestro-U: Leveraging joint speech-text representation learning for zero supervised speech ASR
Oct 18, 2022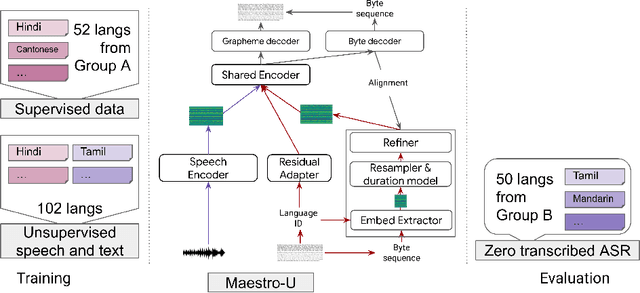
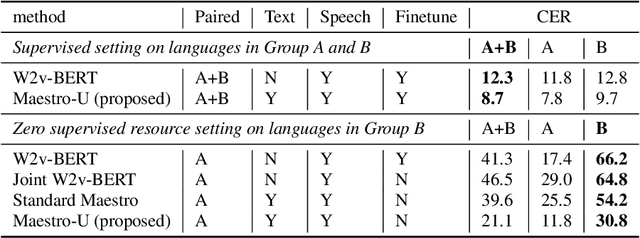
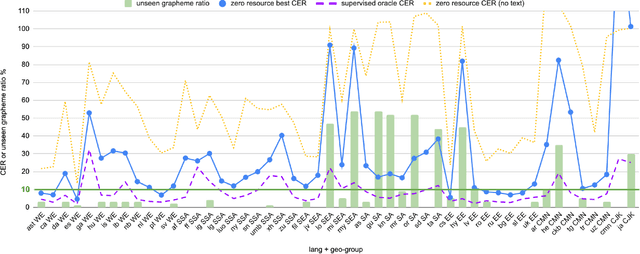
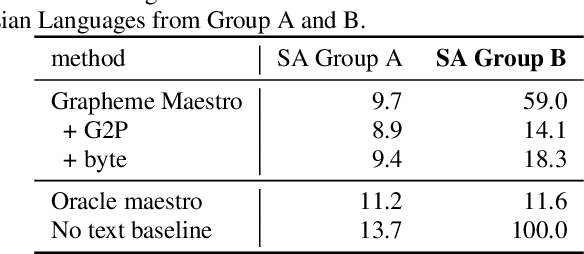
Training state-of-the-art Automated Speech Recognition (ASR) models typically requires a substantial amount of transcribed speech. In this work, we demonstrate that a modality-matched joint speech and text model can be leveraged to train a massively multilingual ASR model without any supervised (manually transcribed) speech for some languages. This paper explores the use of jointly learnt speech and text representations in a massively multilingual, zero supervised speech, real-world setting to expand the set of languages covered by ASR with only unlabeled speech and text in the target languages. Using the FLEURS dataset, we define the task to cover $102$ languages, where transcribed speech is available in $52$ of these languages and can be used to improve end-to-end ASR quality on the remaining $50$. First, we show that by combining speech representations with byte-level text representations and use of language embeddings, we can dramatically reduce the Character Error Rate (CER) on languages with no supervised speech from 64.8\% to 30.8\%, a relative reduction of 53\%. Second, using a subset of South Asian languages we show that Maestro-U can promote knowledge transfer from languages with supervised speech even when there is limited to no graphemic overlap. Overall, Maestro-U closes the gap to oracle performance by 68.5\% relative and reduces the CER of 19 languages below 15\%.
SpecGrad: Diffusion Probabilistic Model based Neural Vocoder with Adaptive Noise Spectral Shaping
Mar 31, 2022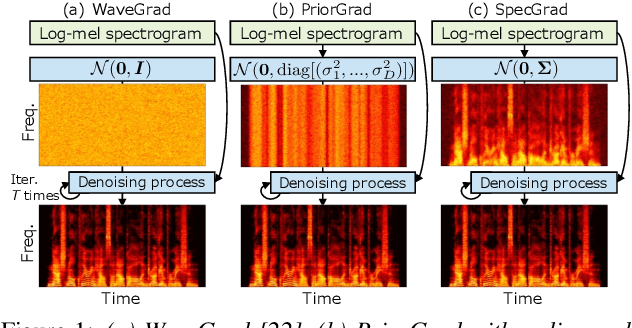
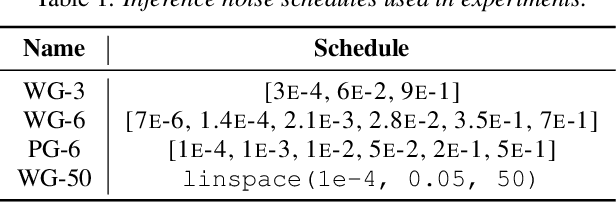
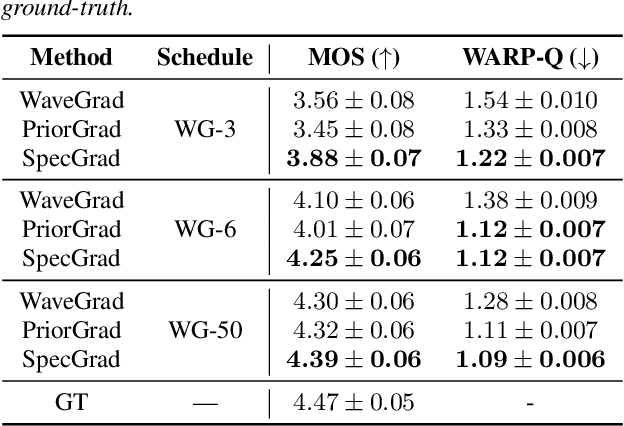
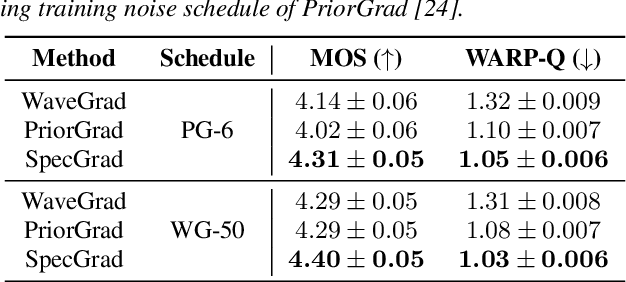
Neural vocoder using denoising diffusion probabilistic model (DDPM) has been improved by adaptation of the diffusion noise distribution to given acoustic features. In this study, we propose SpecGrad that adapts the diffusion noise so that its time-varying spectral envelope becomes close to the conditioning log-mel spectrogram. This adaptation by time-varying filtering improves the sound quality especially in the high-frequency bands. It is processed in the time-frequency domain to keep the computational cost almost the same as the conventional DDPM-based neural vocoders. Experimental results showed that SpecGrad generates higher-fidelity speech waveform than conventional DDPM-based neural vocoders in both analysis-synthesis and speech enhancement scenarios. Audio demos are available at wavegrad.github.io/specgrad/.
A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation
Oct 11, 2021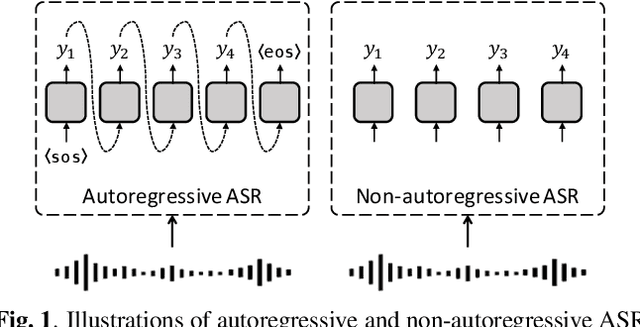

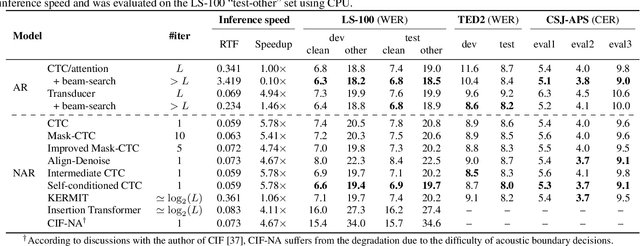
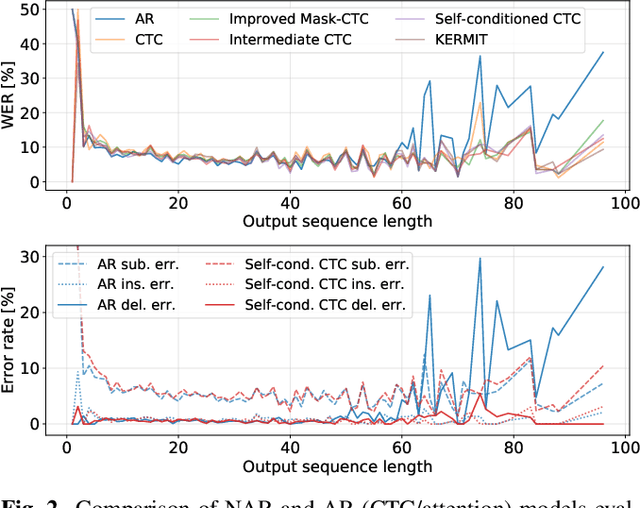
Non-autoregressive (NAR) models simultaneously generate multiple outputs in a sequence, which significantly reduces the inference speed at the cost of accuracy drop compared to autoregressive baselines. Showing great potential for real-time applications, an increasing number of NAR models have been explored in different fields to mitigate the performance gap against AR models. In this work, we conduct a comparative study of various NAR modeling methods for end-to-end automatic speech recognition (ASR). Experiments are performed in the state-of-the-art setting using ESPnet. The results on various tasks provide interesting findings for developing an understanding of NAR ASR, such as the accuracy-speed trade-off and robustness against long-form utterances. We also show that the techniques can be combined for further improvement and applied to NAR end-to-end speech translation. All the implementations are publicly available to encourage further research in NAR speech processing.
WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
Jun 19, 2021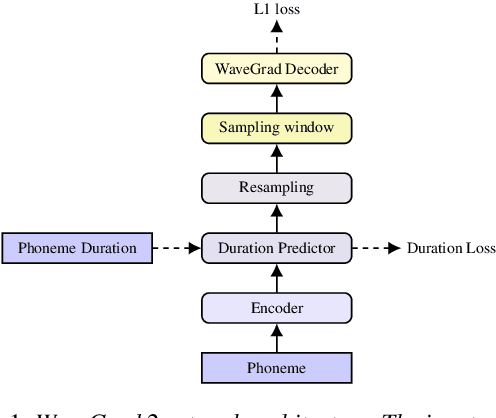
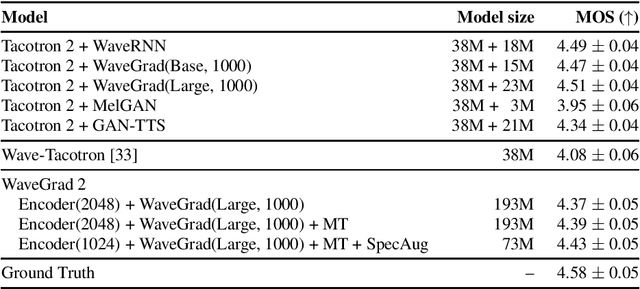
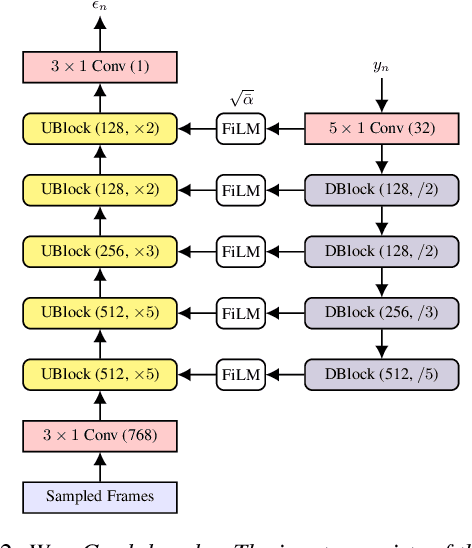

This paper introduces WaveGrad 2, a non-autoregressive generative model for text-to-speech synthesis. WaveGrad 2 is trained to estimate the gradient of the log conditional density of the waveform given a phoneme sequence. The model takes an input phoneme sequence, and through an iterative refinement process, generates an audio waveform. This contrasts to the original WaveGrad vocoder which conditions on mel-spectrogram features, generated by a separate model. The iterative refinement process starts from Gaussian noise, and through a series of refinement steps (e.g., 50 steps), progressively recovers the audio sequence. WaveGrad 2 offers a natural way to trade-off between inference speed and sample quality, through adjusting the number of refinement steps. Experiments show that the model can generate high fidelity audio, approaching the performance of a state-of-the-art neural TTS system. We also report various ablation studies over different model configurations. Audio samples are available at https://wavegrad.github.io/v2.
Focus on the present: a regularization method for the ASR source-target attention layer
Nov 02, 2020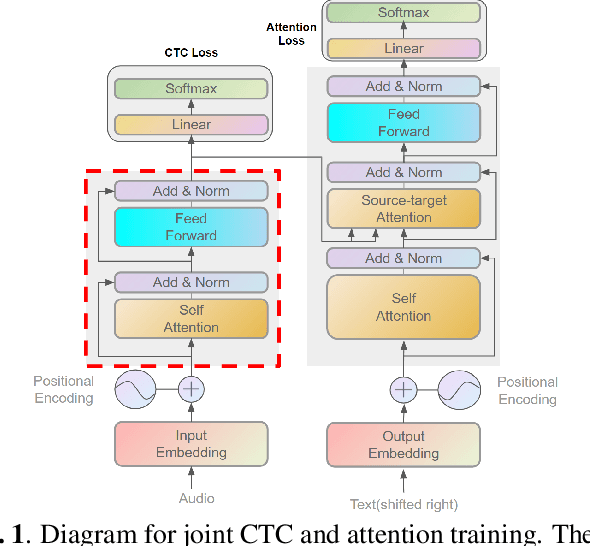
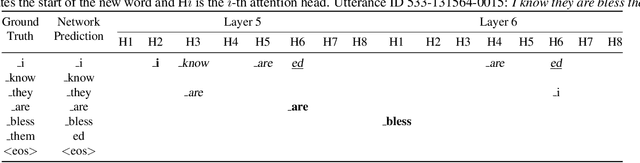


This paper introduces a novel method to diagnose the source-target attention in state-of-the-art end-to-end speech recognition models with joint connectionist temporal classification (CTC) and attention training. Our method is based on the fact that both, CTC and source-target attention, are acting on the same encoder representations. To understand the functionality of the attention, CTC is applied to compute the token posteriors given the attention outputs. We found that the source-target attention heads are able to predict several tokens ahead of the current one. Inspired by the observation, a new regularization method is proposed which leverages CTC to make source-target attention more focused on the frames corresponding to the output token being predicted by the decoder. Experiments reveal stable improvements up to 7\% and 13\% relatively with the proposed regularization on TED-LIUM 2 and LibriSpeech.
WaveGrad: Estimating Gradients for Waveform Generation
Sep 02, 2020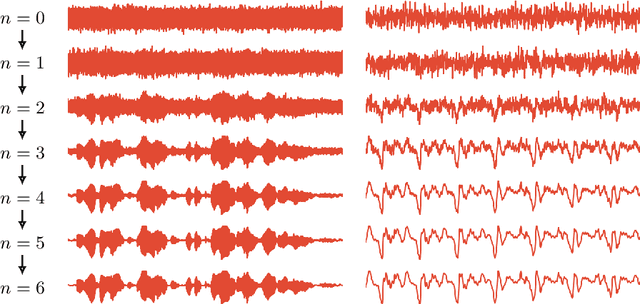
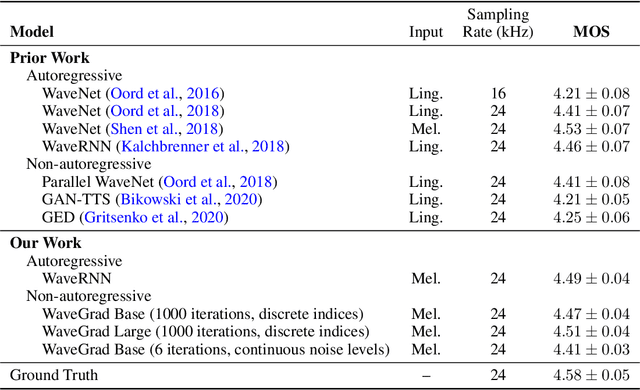
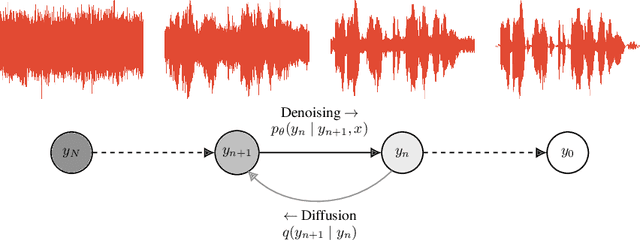

This paper introduces WaveGrad, a conditional model for waveform generation through estimating gradients of the data density. This model is built on the prior work on score matching and diffusion probabilistic models. It starts from Gaussian white noise and iteratively refines the signal via a gradient-based sampler conditioned on the mel-spectrogram. WaveGrad is non-autoregressive, and requires only a constant number of generation steps during inference. It can use as few as 6 iterations to generate high fidelity audio samples. WaveGrad is simple to train, and implicitly optimizes for the weighted variational lower-bound of the log-likelihood. Empirical experiments reveal WaveGrad to generate high fidelity audio samples matching a strong likelihood-based autoregressive baseline with less sequential operations.
Robust Training of Vector Quantized Bottleneck Models
May 18, 2020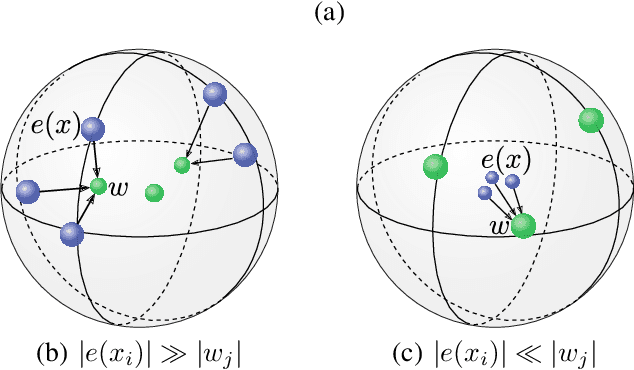
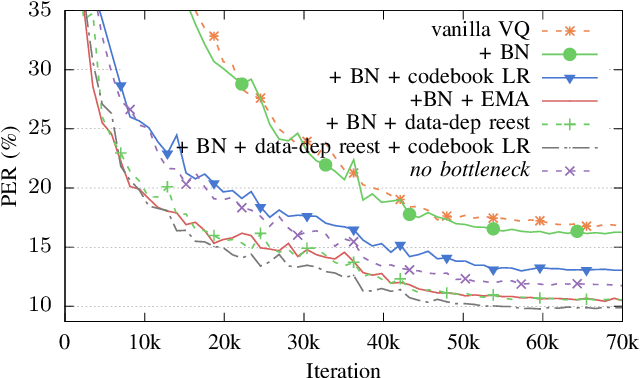
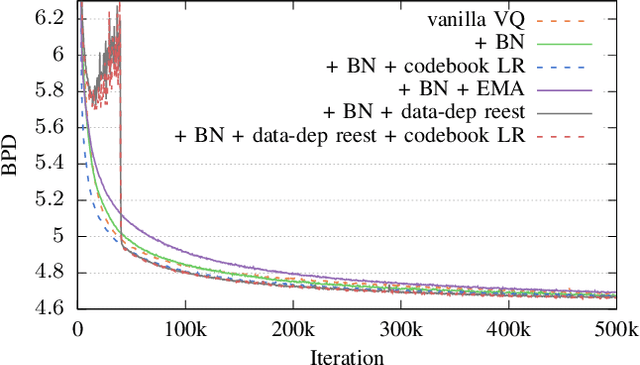

In this paper we demonstrate methods for reliable and efficient training of discrete representation using Vector-Quantized Variational Auto-Encoder models (VQ-VAEs). Discrete latent variable models have been shown to learn nontrivial representations of speech, applicable to unsupervised voice conversion and reaching state-of-the-art performance on unit discovery tasks. For unsupervised representation learning, they became viable alternatives to continuous latent variable models such as the Variational Auto-Encoder (VAE). However, training deep discrete variable models is challenging, due to the inherent non-differentiability of the discretization operation. In this paper we focus on VQ-VAE, a state-of-the-art discrete bottleneck model shown to perform on par with its continuous counterparts. It quantizes encoder outputs with on-line $k$-means clustering. We show that the codebook learning can suffer from poor initialization and non-stationarity of clustered encoder outputs. We demonstrate that these can be successfully overcome by increasing the learning rate for the codebook and periodic date-dependent codeword re-initialization. As a result, we achieve more robust training across different tasks, and significantly increase the usage of latent codewords even for large codebooks. This has practical benefit, for instance, in unsupervised representation learning, where large codebooks may lead to disentanglement of latent representations.