 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Instrumental Variable Regression for Deep Offline Policy Evaluation
May 21, 2021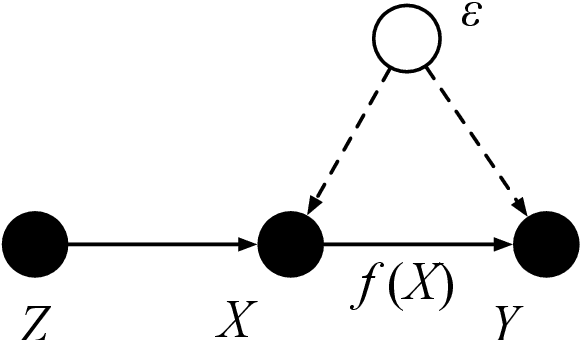
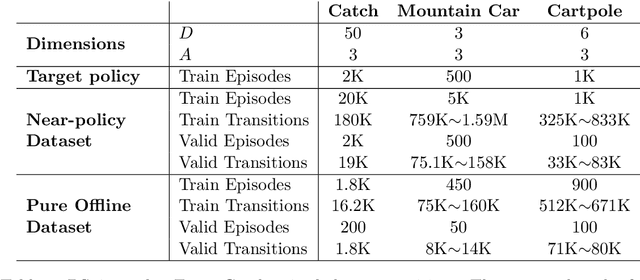
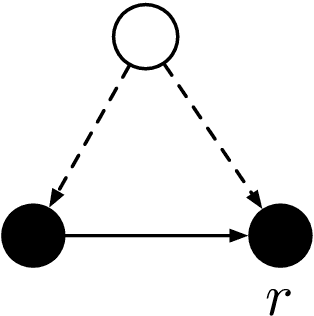
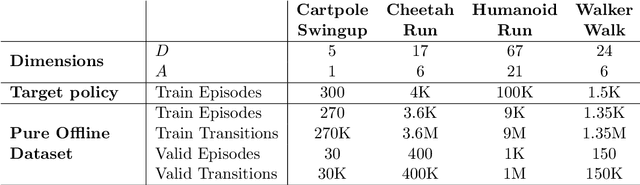
We show that the popular reinforcement learning (RL) strategy of estimating the state-action value (Q-function) by minimizing the mean squared Bellman error leads to a regression problem with confounding, the inputs and output noise being correlated. Hence, direct minimization of the Bellman error can result in significantly biased Q-function estimates. We explain why fixing the target Q-network in Deep Q-Networks and Fitted Q Evaluation provides a way of overcoming this confounding, thus shedding new light on this popular but not well understood trick in the deep RL literature. An alternative approach to address confounding is to leverage techniques developed in the causality literature, notably instrumental variables (IV). We bring together here the literature on IV and RL by investigating whether IV approaches can lead to improved Q-function estimates. This paper analyzes and compares a wide range of recent IV methods in the context of offline policy evaluation (OPE), where the goal is to estimate the value of a policy using logged data only. By applying different IV techniques to OPE, we are not only able to recover previously proposed OPE methods such as model-based techniques but also to obtain competitive new techniques. We find empirically that state-of-the-art OPE methods are closely matched in performance by some IV methods such as AGMM, which were not developed for OPE. We open-source all our code and datasets at https://github.com/liyuan9988/IVOPEwithACME.
Regularized Behavior Value Estimation
Mar 17, 2021
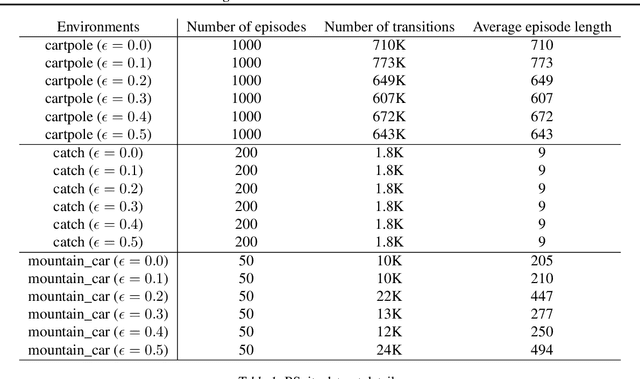
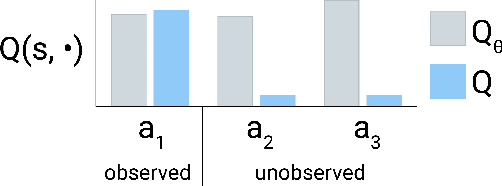
Offline reinforcement learning restricts the learning process to rely only on logged-data without access to an environment. While this enables real-world applications, it also poses unique challenges. One important challenge is dealing with errors caused by the overestimation of values for state-action pairs not well-covered by the training data. Due to bootstrapping, these errors get amplified during training and can lead to divergence, thereby crippling learning. To overcome this challenge, we introduce Regularized Behavior Value Estimation (R-BVE). Unlike most approaches, which use policy improvement during training, R-BVE estimates the value of the behavior policy during training and only performs policy improvement at deployment time. Further, R-BVE uses a ranking regularisation term that favours actions in the dataset that lead to successful outcomes. We provide ample empirical evidence of R-BVE's effectiveness, including state-of-the-art performance on the RL Unplugged ATARI dataset. We also test R-BVE on new datasets, from bsuite and a challenging DeepMind Lab task, and show that R-BVE outperforms other state-of-the-art discrete control offline RL methods.
Semi-supervised reward learning for offline reinforcement learning
Dec 12, 2020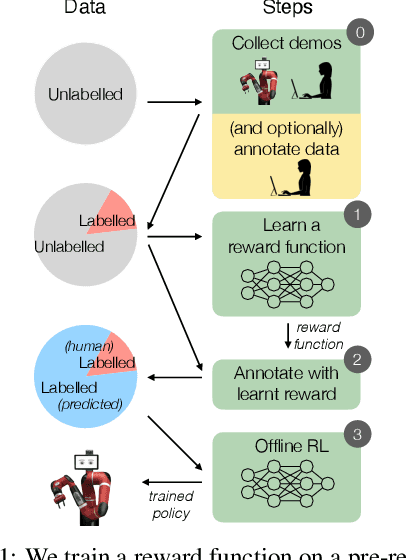
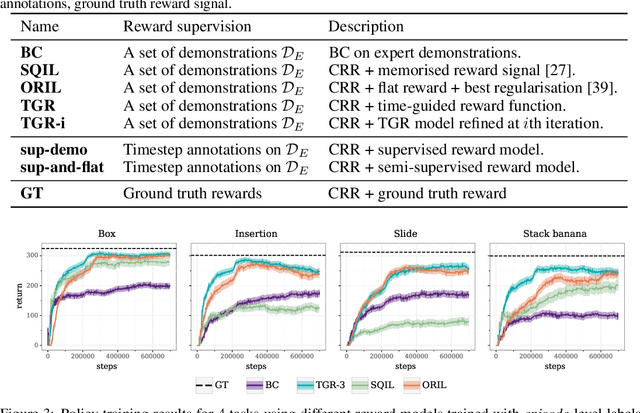

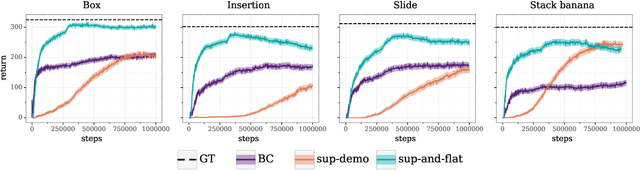
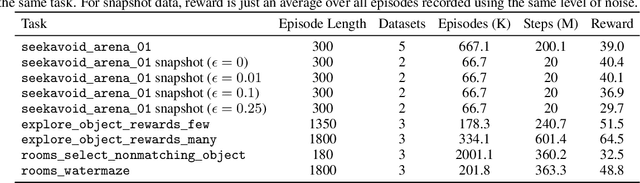
In offline reinforcement learning (RL) agents are trained using a logged dataset. It appears to be the most natural route to attack real-life applications because in domains such as healthcare and robotics interactions with the environment are either expensive or unethical. Training agents usually requires reward functions, but unfortunately, rewards are seldom available in practice and their engineering is challenging and laborious. To overcome this, we investigate reward learning under the constraint of minimizing human reward annotations. We consider two types of supervision: timestep annotations and demonstrations. We propose semi-supervised learning algorithms that learn from limited annotations and incorporate unlabelled data. In our experiments with a simulated robotic arm, we greatly improve upon behavioural cloning and closely approach the performance achieved with ground truth rewards. We further investigate the relationship between the quality of the reward model and the final policies. We notice, for example, that the reward models do not need to be perfect to result in useful policies.
Offline Learning from Demonstrations and Unlabeled Experience
Nov 27, 2020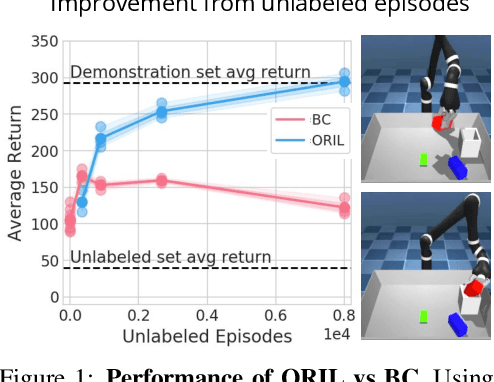
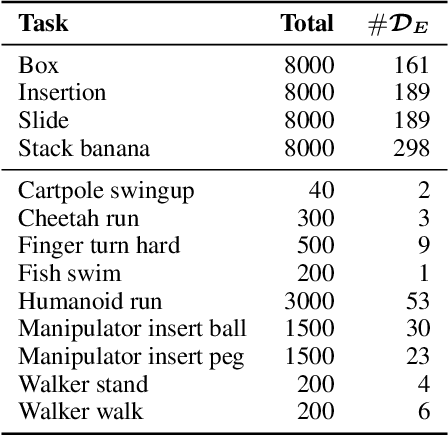
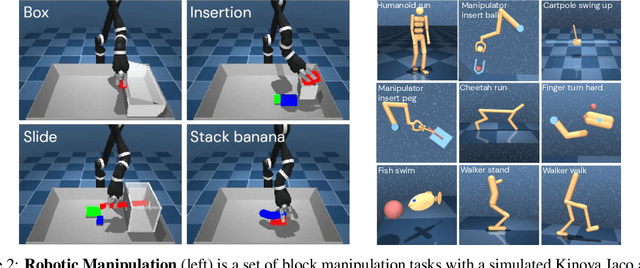

Behavior cloning (BC) is often practical for robot learning because it allows a policy to be trained offline without rewards, by supervised learning on expert demonstrations. However, BC does not effectively leverage what we will refer to as unlabeled experience: data of mixed and unknown quality without reward annotations. This unlabeled data can be generated by a variety of sources such as human teleoperation, scripted policies and other agents on the same robot. Towards data-driven offline robot learning that can use this unlabeled experience, we introduce Offline Reinforced Imitation Learning (ORIL). ORIL first learns a reward function by contrasting observations from demonstrator and unlabeled trajectories, then annotates all data with the learned reward, and finally trains an agent via offline reinforcement learning. Across a diverse set of continuous control and simulated robotic manipulation tasks, we show that ORIL consistently outperforms comparable BC agents by effectively leveraging unlabeled experience.
Large-scale multilingual audio visual dubbing
Nov 06, 2020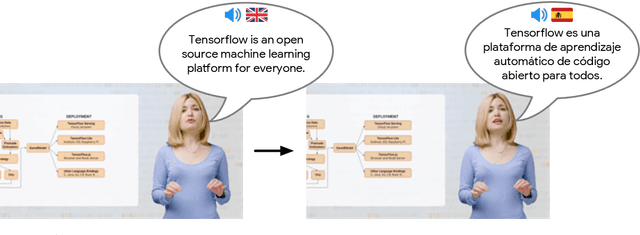
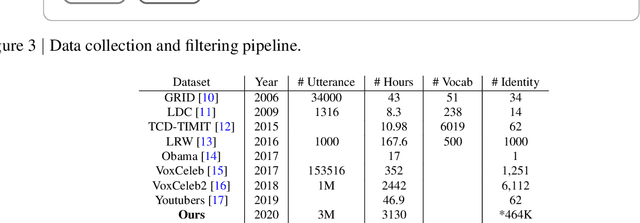
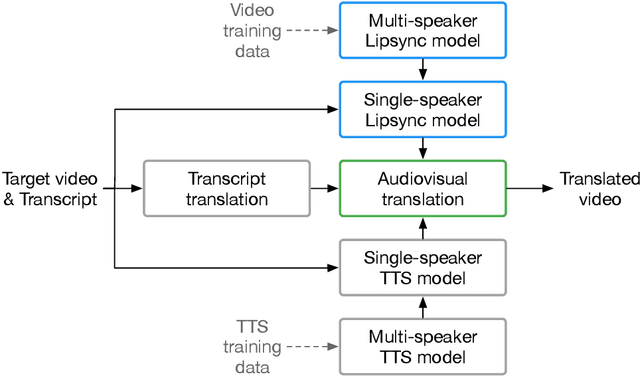
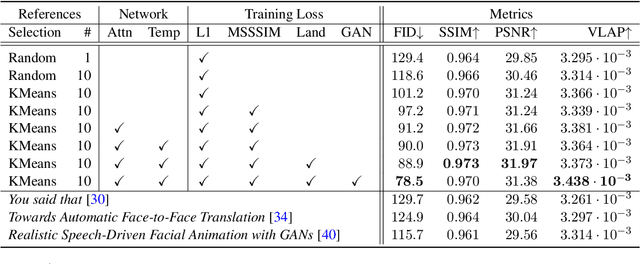
We describe a system for large-scale audiovisual translation and dubbing, which translates videos from one language to another. The source language's speech content is transcribed to text, translated, and automatically synthesized into target language speech using the original speaker's voice. The visual content is translated by synthesizing lip movements for the speaker to match the translated audio, creating a seamless audiovisual experience in the target language. The audio and visual translation subsystems each contain a large-scale generic synthesis model trained on thousands of hours of data in the corresponding domain. These generic models are fine-tuned to a specific speaker before translation, either using an auxiliary corpus of data from the target speaker, or using the video to be translated itself as the input to the fine-tuning process. This report gives an architectural overview of the full system, as well as an in-depth discussion of the video dubbing component. The role of the audio and text components in relation to the full system is outlined, but their design is not discussed in detail. Translated and dubbed demo videos generated using our system can be viewed at https://www.youtube.com/playlist?list=PLSi232j2ZA6_1Exhof5vndzyfbxAhhEs5
Learning Deep Features in Instrumental Variable Regression
Nov 01, 2020
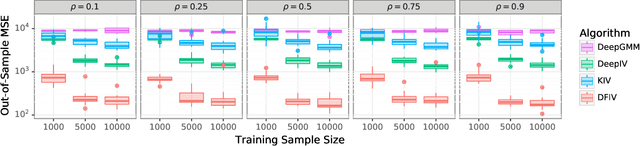

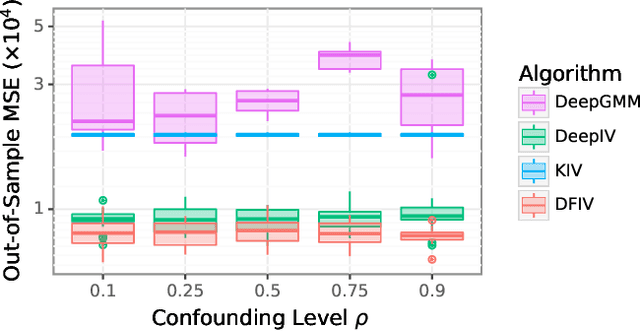
Instrumental variable (IV) regression is a standard strategy for learning causal relationships between confounded treatment and outcome variables from observational data by utilizing an instrumental variable, which affects the outcome only through the treatment. In classical IV regression, learning proceeds in two stages: stage 1 performs linear regression from the instrument to the treatment; and stage 2 performs linear regression from the treatment to the outcome, conditioned on the instrument. We propose a novel method, deep feature instrumental variable regression (DFIV), to address the case where relations between instruments, treatments, and outcomes may be nonlinear. In this case, deep neural nets are trained to define informative nonlinear features on the instruments and treatments. We propose an alternating training regime for these features to ensure good end-to-end performance when composing stages 1 and 2, thus obtaining highly flexible feature maps in a computationally efficient manner. DFIV outperforms recent state-of-the-art methods on challenging IV benchmarks, including settings involving high dimensional image data. DFIV also exhibits competitive performance in off-policy policy evaluation for reinforcement learning, which can be understood as an IV regression task.
Learning Compositional Neural Programs for Continuous Control
Jul 27, 2020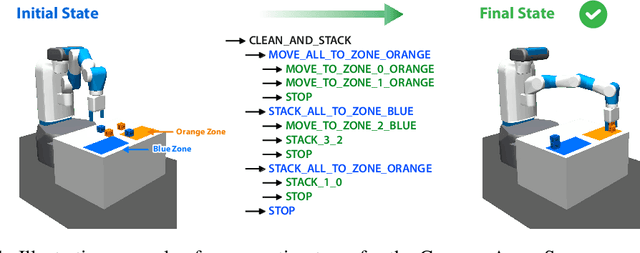

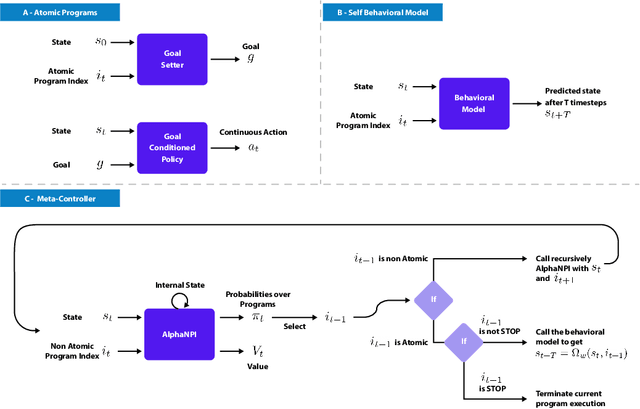
We propose a novel solution to challenging sparse-reward, continuous control problems that require hierarchical planning at multiple levels of abstraction. Our solution, dubbed AlphaNPI-X, involves three separate stages of learning. First, we use off-policy reinforcement learning algorithms with experience replay to learn a set of atomic goal-conditioned policies, which can be easily repurposed for many tasks. Second, we learn self-models describing the effect of the atomic policies on the environment. Third, the self-models are harnessed to learn recursive compositional programs with multiple levels of abstraction. The key insight is that the self-models enable planning by imagination, obviating the need for interaction with the world when learning higher-level compositional programs. To accomplish the third stage of learning, we extend the AlphaNPI algorithm, which applies AlphaZero to learn recursive neural programmer-interpreters. We empirically show that AlphaNPI-X can effectively learn to tackle challenging sparse manipulation tasks, such as stacking multiple blocks, where powerful model-free baselines fail.
Hyperparameter Selection for Offline Reinforcement Learning
Jul 17, 2020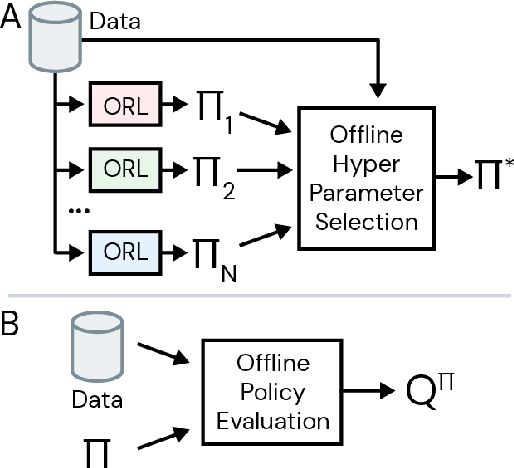
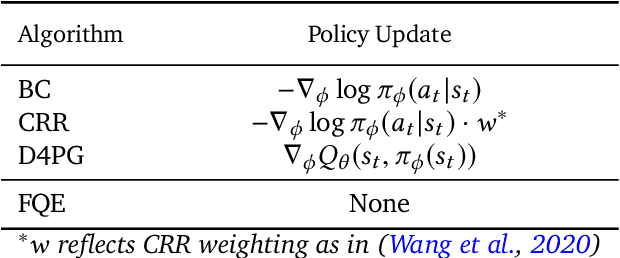
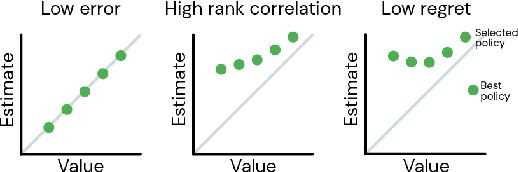
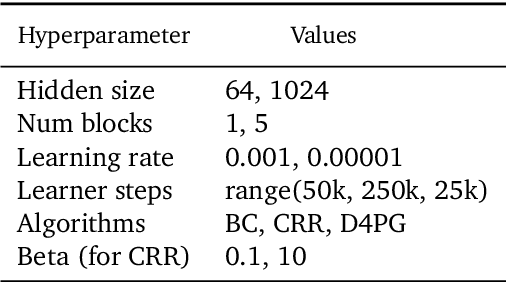
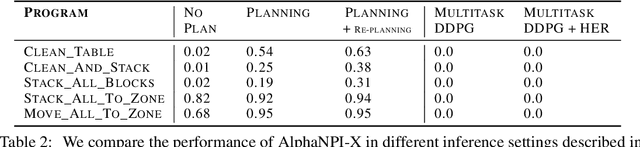
Offline reinforcement learning (RL purely from logged data) is an important avenue for deploying RL techniques in real-world scenarios. However, existing hyperparameter selection methods for offline RL break the offline assumption by evaluating policies corresponding to each hyperparameter setting in the environment. This online execution is often infeasible and hence undermines the main aim of offline RL. Therefore, in this work, we focus on \textit{offline hyperparameter selection}, i.e. methods for choosing the best policy from a set of many policies trained using different hyperparameters, given only logged data. Through large-scale empirical evaluation we show that: 1) offline RL algorithms are not robust to hyperparameter choices, 2) factors such as the offline RL algorithm and method for estimating Q values can have a big impact on hyperparameter selection, and 3) when we control those factors carefully, we can reliably rank policies across hyperparameter choices, and therefore choose policies which are close to the best policy in the set. Overall, our results present an optimistic view that offline hyperparameter selection is within reach, even in challenging tasks with pixel observations, high dimensional action spaces, and long horizon.
RL Unplugged: Benchmarks for Offline Reinforcement Learning
Jul 02, 2020
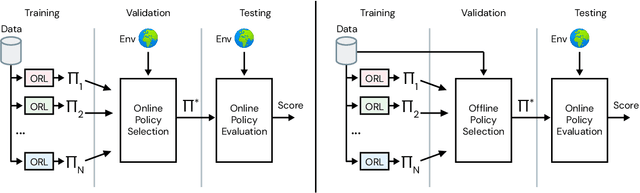
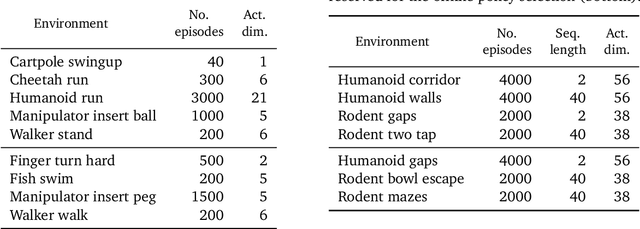
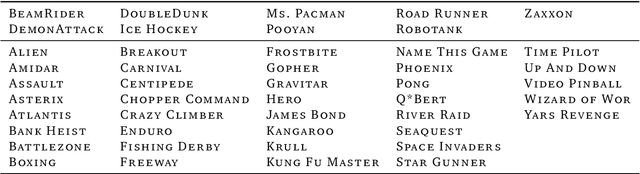
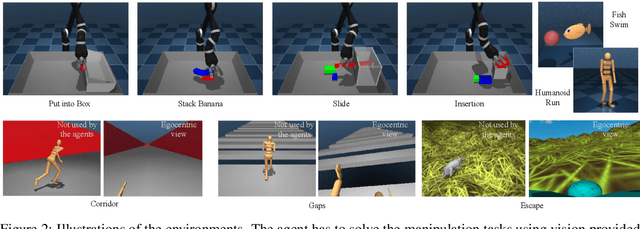
Offline methods for reinforcement learning have a potential to help bridge the gap between reinforcement learning research and real-world applications. They make it possible to learn policies from offline datasets, thus overcoming concerns associated with online data collection in the real-world, including cost, safety, or ethical concerns. In this paper, we propose a benchmark called RL Unplugged to evaluate and compare offline RL methods. RL Unplugged includes data from a diverse range of domains including games ({\em e.g.,} Atari benchmark) and simulated motor control problems ({\em e.g.,} DM Control Suite). The datasets include domains that are partially or fully observable, use continuous or discrete actions, and have stochastic vs. deterministic dynamics. We propose detailed evaluation protocols for each domain in RL Unplugged and provide an extensive analysis of supervised learning and offline RL methods using these protocols. We will release data for all our tasks and open-source all algorithms presented in this paper. We hope that our suite of benchmarks will increase the reproducibility of experiments and make it possible to study challenging tasks with a limited computational budget, thus making RL research both more systematic and more accessible across the community. Moving forward, we view RL Unplugged as a living benchmark suite that will evolve and grow with datasets contributed by the research community and ourselves. Our project page is available on github (https://git.io/JJUhd).
Critic Regularized Regression
Jun 26, 2020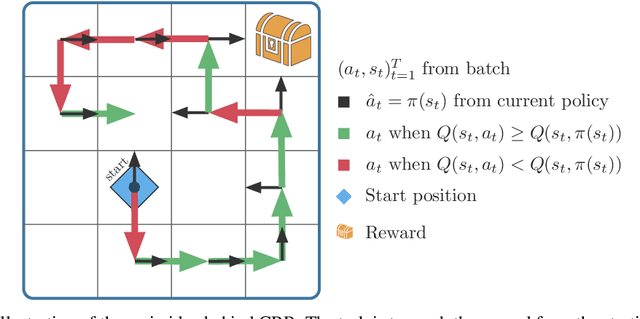


Offline reinforcement learning (RL), also known as batch RL, offers the prospect of policy optimization from large pre-recorded datasets without online environment interaction. It addresses challenges with regard to the cost of data collection and safety, both of which are particularly pertinent to real-world applications of RL. Unfortunately, most off-policy algorithms perform poorly when learning from a fixed dataset. In this paper, we propose a novel offline RL algorithm to learn policies from data using a form of critic-regularized regression (CRR). We find that CRR performs surprisingly well and scales to tasks with high-dimensional state and action spaces -- outperforming several state-of-the-art offline RL algorithms by a significant margin on a wide range of benchmark tasks.