 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
Variance-Reduced Conservative Policy Iteration
Dec 12, 2022
We study the sample complexity of reducing reinforcement learning to a sequence of empirical risk minimization problems over the policy space. Such reductions-based algorithms exhibit local convergence in the function space, as opposed to the parameter space for policy gradient algorithms, and thus are unaffected by the possibly non-linear or discontinuous parameterization of the policy class. We propose a variance-reduced variant of Conservative Policy Iteration that improves the sample complexity of producing a $\varepsilon$-functional local optimum from $O(\varepsilon^{-4})$ to $O(\varepsilon^{-3})$. Under state-coverage and policy-completeness assumptions, the algorithm enjoys $\varepsilon$-global optimality after sampling $O(\varepsilon^{-2})$ times, improving upon the previously established $O(\varepsilon^{-3})$ sample requirement.
Best of Both Worlds in Online Control: Competitive Ratio and Policy Regret
Nov 21, 2022


We consider the fundamental problem of online control of a linear dynamical system from two different viewpoints: regret minimization and competitive analysis. We prove that the optimal competitive policy is well-approximated by a convex parameterized policy class, known as a disturbance-action control (DAC) policies. Using this structural result, we show that several recently proposed online control algorithms achieve the best of both worlds: sublinear regret vs. the best DAC policy selected in hindsight, and optimal competitive ratio, up to an additive correction which grows sublinearly in the time horizon. We further conclude that sublinear regret vs. the optimal competitive policy is attainable when the linear dynamical system is unknown, and even when a stabilizing controller for the dynamics is not available a priori.
Multi-User Reinforcement Learning with Low Rank Rewards
Oct 11, 2022In this work, we consider the problem of collaborative multi-user reinforcement learning. In this setting there are multiple users with the same state-action space and transition probabilities but with different rewards. Under the assumption that the reward matrix of the $N$ users has a low-rank structure -- a standard and practically successful assumption in the offline collaborative filtering setting -- the question is can we design algorithms with significantly lower sample complexity compared to the ones that learn the MDP individually for each user. Our main contribution is an algorithm which explores rewards collaboratively with $N$ user-specific MDPs and can learn rewards efficiently in two key settings: tabular MDPs and linear MDPs. When $N$ is large and the rank is constant, the sample complexity per MDP depends logarithmically over the size of the state-space, which represents an exponential reduction (in the state-space size) when compared to the standard ``non-collaborative'' algorithms.
Adaptive Gradient Methods at the Edge of Stability
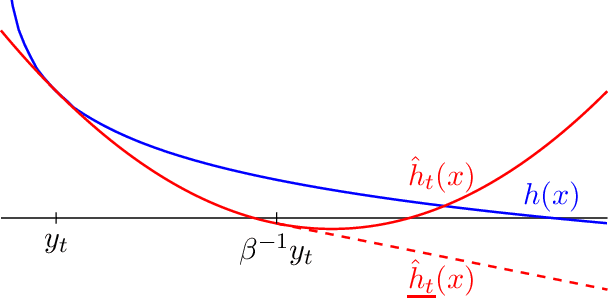
Jul 29, 2022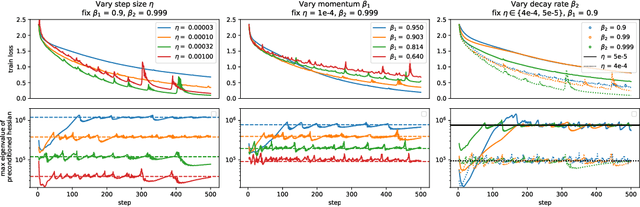
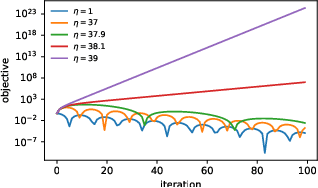

Very little is known about the training dynamics of adaptive gradient methods like Adam in deep learning. In this paper, we shed light on the behavior of these algorithms in the full-batch and sufficiently large batch settings. Specifically, we empirically demonstrate that during full-batch training, the maximum eigenvalue of the preconditioned Hessian typically equilibrates at a certain numerical value -- the stability threshold of a gradient descent algorithm. For Adam with step size $\eta$ and $\beta_1 = 0.9$, this stability threshold is $38/\eta$. Similar effects occur during minibatch training, especially as the batch size grows. Yet, even though adaptive methods train at the ``Adaptive Edge of Stability'' (AEoS), their behavior in this regime differs in a significant way from that of non-adaptive methods at the EoS. Whereas non-adaptive algorithms at the EoS are blocked from entering high-curvature regions of the loss landscape, adaptive gradient methods at the AEoS can keep advancing into high-curvature regions, while adapting the preconditioner to compensate. Our findings can serve as a foundation for the community's future understanding of adaptive gradient methods in deep learning.
Pushing the Efficiency-Regret Pareto Frontier for Online Learning of Portfolios and Quantum States
Feb 06, 2022
We revisit the classical online portfolio selection problem. It is widely assumed that a trade-off between computational complexity and regret is unavoidable, with Cover's Universal Portfolios algorithm, SOFT-BAYES and ADA-BARRONS currently constituting its state-of-the-art Pareto frontier. In this paper, we present the first efficient algorithm, BISONS, that obtains polylogarithmic regret with memory and per-step running time requirements that are polynomial in the dimension, displacing ADA-BARRONS from the Pareto frontier. Additionally, we resolve a COLT 2020 open problem by showing that a certain Follow-The-Regularized-Leader algorithm with log-barrier regularization suffers an exponentially larger dependence on the dimension than previously conjectured. Thus, we rule out this algorithm as a candidate for the Pareto frontier. We also extend our algorithm and analysis to a more general problem than online portfolio selection, viz. online learning of quantum states with log loss. This algorithm, called SCHRODINGER'S BISONS, is the first efficient algorithm with polylogarithmic regret for this more general problem.
Machine Learning for Mechanical Ventilation Control (Extended Abstract)
Nov 23, 2021Mechanical ventilation is one of the most widely used therapies in the ICU. However, despite broad application from anaesthesia to COVID-related life support, many injurious challenges remain. We frame these as a control problem: ventilators must let air in and out of the patient's lungs according to a prescribed trajectory of airway pressure. Industry-standard controllers, based on the PID method, are neither optimal nor robust. Our data-driven approach learns to control an invasive ventilator by training on a simulator itself trained on data collected from the ventilator. This method outperforms popular reinforcement learning algorithms and even controls the physical ventilator more accurately and robustly than PID. These results underscore how effective data-driven methodologies can be for invasive ventilation and suggest that more general forms of ventilation (e.g., non-invasive, adaptive) may also be amenable.
The Skellam Mechanism for Differentially Private Federated Learning
Oct 29, 2021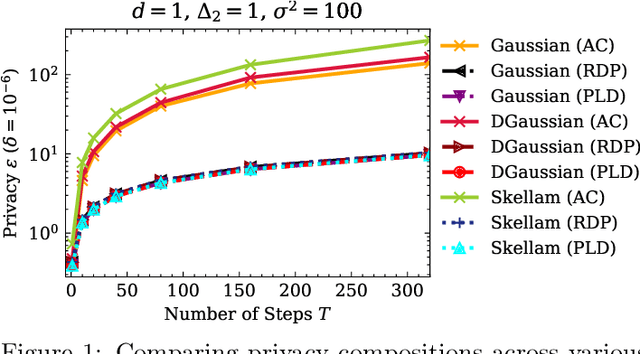
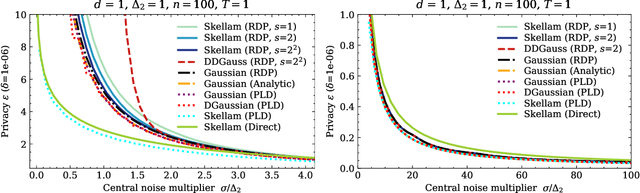
We introduce the multi-dimensional Skellam mechanism, a discrete differential privacy mechanism based on the difference of two independent Poisson random variables. To quantify its privacy guarantees, we analyze the privacy loss distribution via a numerical evaluation and provide a sharp bound on the R\'enyi divergence between two shifted Skellam distributions. While useful in both centralized and distributed privacy applications, we investigate how it can be applied in the context of federated learning with secure aggregation under communication constraints. Our theoretical findings and extensive experimental evaluations demonstrate that the Skellam mechanism provides the same privacy-accuracy trade-offs as the continuous Gaussian mechanism, even when the precision is low. More importantly, Skellam is closed under summation and sampling from it only requires sampling from a Poisson distribution -- an efficient routine that ships with all machine learning and data analysis software packages. These features, along with its discrete nature and competitive privacy-accuracy trade-offs, make it an attractive practical alternative to the newly introduced discrete Gaussian mechanism.
Online Target Q-learning with Reverse Experience Replay: Efficiently finding the Optimal Policy for Linear MDPs
Oct 19, 2021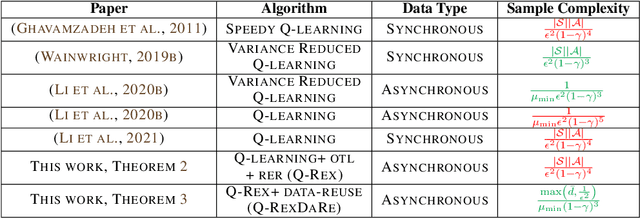
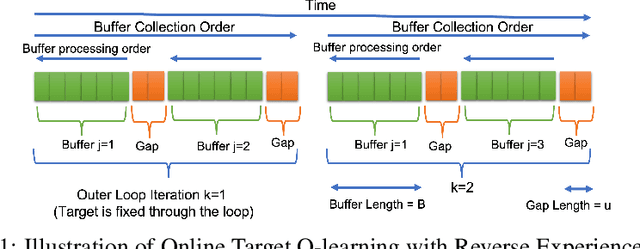

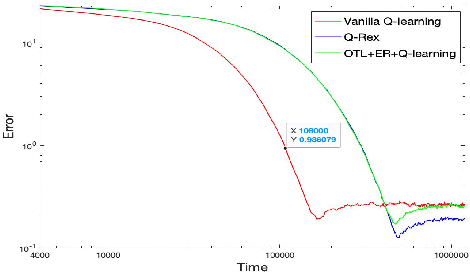
Q-learning is a popular Reinforcement Learning (RL) algorithm which is widely used in practice with function approximation (Mnih et al., 2015). In contrast, existing theoretical results are pessimistic about Q-learning. For example, (Baird, 1995) shows that Q-learning does not converge even with linear function approximation for linear MDPs. Furthermore, even for tabular MDPs with synchronous updates, Q-learning was shown to have sub-optimal sample complexity (Li et al., 2021;Azar et al., 2013). The goal of this work is to bridge the gap between practical success of Q-learning and the relatively pessimistic theoretical results. The starting point of our work is the observation that in practice, Q-learning is used with two important modifications: (i) training with two networks, called online network and target network simultaneously (online target learning, or OTL) , and (ii) experience replay (ER) (Mnih et al., 2015). While they have been observed to play a significant role in the practical success of Q-learning, a thorough theoretical understanding of how these two modifications improve the convergence behavior of Q-learning has been missing in literature. By carefully combining Q-learning with OTL and reverse experience replay (RER) (a form of experience replay), we present novel methods Q-Rex and Q-RexDaRe (Q-Rex + data reuse). We show that Q-Rex efficiently finds the optimal policy for linear MDPs (or more generally for MDPs with zero inherent Bellman error with linear approximation (ZIBEL)) and provide non-asymptotic bounds on sample complexity -- the first such result for a Q-learning method for this class of MDPs under standard assumptions. Furthermore, we demonstrate that Q-RexDaRe in fact achieves near optimal sample complexity in the tabular setting, improving upon the existing results for vanilla Q-learning.
Efficient Methods for Online Multiclass Logistic Regression
Oct 10, 2021
Multiclass logistic regression is a fundamental task in machine learning with applications in classification and boosting. Previous work (Foster et al., 2018) has highlighted the importance of improper predictors for achieving "fast rates" in the online multiclass logistic regression problem without suffering exponentially from secondary problem parameters, such as the norm of the predictors in the comparison class. While Foster et al. (2018) introduced a statistically optimal algorithm, it is in practice computationally intractable due to its run-time complexity being a large polynomial in the time horizon and dimension of input feature vectors. In this paper, we develop a new algorithm, FOLKLORE, for the problem which runs significantly faster than the algorithm of Foster et al.(2018) -- the running time per iteration scales quadratically in the dimension -- at the cost of a linear dependence on the norm of the predictors in the regret bound. This yields the first practical algorithm for online multiclass logistic regression, resolving an open problem of Foster et al.(2018). Furthermore, we show that our algorithm can be applied to online bandit multiclass prediction and online multiclass boosting, yielding more practical algorithms for both problems compared to the ones in Foster et al.(2018) with similar performance guarantees. Finally, we also provide an online-to-batch conversion result for our algorithm.