 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor3DLane: Learning to Regress 3D Anchors for Monocular 3D Lane Detection
Jan 06, 2023



Monocular 3D lane detection is a challenging task due to its lack of depth information. A popular solution to 3D lane detection is to first transform the front-viewed (FV) images or features into the bird-eye-view (BEV) space with inverse perspective mapping (IPM) and detect lanes from BEV features. However, the reliance of IPM on flat ground assumption and loss of context information makes it inaccurate to restore 3D information from BEV representations. An attempt has been made to get rid of BEV and predict 3D lanes from FV representations directly, while it still underperforms other BEV-based methods given its lack of structured representation for 3D lanes. In this paper, we define 3D lane anchors in the 3D space and propose a BEV-free method named Anchor3DLane to predict 3D lanes directly from FV representations. 3D lane anchors are projected to the FV features to extract their features which contain both good structural and context information to make accurate predictions. We further extend Anchor3DLane to the multi-frame setting to incorporate temporal information for performance improvement. In addition, we also develop a global optimization method that makes use of the equal-width property between lanes to reduce the lateral error of predictions. Extensive experiments on three popular 3D lane detection benchmarks show that our Anchor3DLane outperforms previous BEV-based methods and achieves state-of-the-art performances.
Super Sparse 3D Object Detection
Jan 05, 2023As the perception range of LiDAR expands, LiDAR-based 3D object detection contributes ever-increasingly to the long-range perception in autonomous driving. Mainstream 3D object detectors often build dense feature maps, where the cost is quadratic to the perception range, making them hardly scale up to the long-range settings. To enable efficient long-range detection, we first propose a fully sparse object detector termed FSD. FSD is built upon the general sparse voxel encoder and a novel sparse instance recognition (SIR) module. SIR groups the points into instances and applies highly-efficient instance-wise feature extraction. The instance-wise grouping sidesteps the issue of the center feature missing, which hinders the design of the fully sparse architecture. To further enjoy the benefit of fully sparse characteristic, we leverage temporal information to remove data redundancy and propose a super sparse detector named FSD++. FSD++ first generates residual points, which indicate the point changes between consecutive frames. The residual points, along with a few previous foreground points, form the super sparse input data, greatly reducing data redundancy and computational overhead. We comprehensively analyze our method on the large-scale Waymo Open Dataset, and state-of-the-art performance is reported. To showcase the superiority of our method in long-range detection, we also conduct experiments on Argoverse 2 Dataset, where the perception range ($200m$) is much larger than Waymo Open Dataset ($75m$). Code is open-sourced at https://github.com/tusen-ai/SST.
PredNAS: A Universal and Sample Efficient Neural Architecture Search Framework
Oct 26, 2022In this paper, we present a general and effective framework for Neural Architecture Search (NAS), named PredNAS. The motivation is that given a differentiable performance estimation function, we can directly optimize the architecture towards higher performance by simple gradient ascent. Specifically, we adopt a neural predictor as the performance predictor. Surprisingly, PredNAS can achieve state-of-the-art performances on NAS benchmarks with only a few training samples (less than 100). To validate the universality of our method, we also apply our method on large-scale tasks and compare our method with RegNet on ImageNet and YOLOX on MSCOCO. The results demonstrate that our PredNAS can explore novel architectures with competitive performances under specific computational complexity constraints.
YOLOV: Making Still Image Object Detectors Great at Video Object Detection
Aug 20, 2022
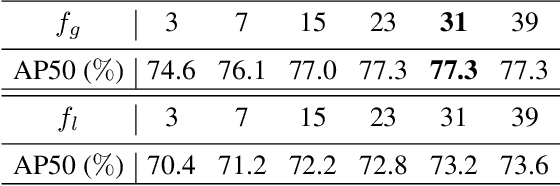
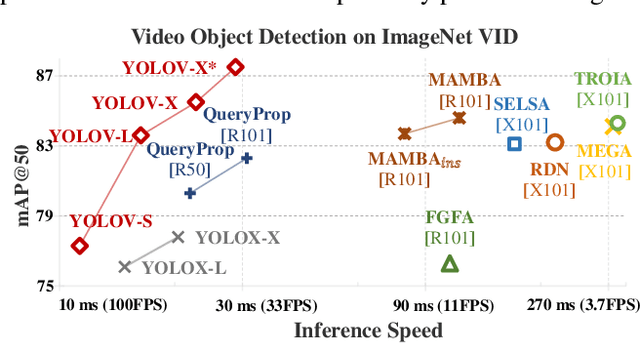

Video object detection (VID) is challenging because of the high variation of object appearance as well as the diverse deterioration in some frames. On the positive side, the detection in a certain frame of a video, compared with in a still image, can draw support from other frames. Hence, how to aggregate features across different frames is pivotal to the VID problem. Most of existing aggregation algorithms are customized for two-stage detectors. But, the detectors in this category are usually computationally expensive due to the two-stage nature. This work proposes a simple yet effective strategy to address the above concerns, which spends marginal overheads with significant gains in accuracy. Concretely, different from the traditional two-stage pipeline, we advocate putting the region-level selection after the one-stage detection to avoid processing massive low-quality candidates. Besides, a novel module is constructed to evaluate the relationship between a target frame and its reference ones, and guide the aggregation. Extensive experiments and ablation studies are conducted to verify the efficacy of our design, and reveal its superiority over other state-of-the-art VID approaches in both effectiveness and efficiency. Our YOLOX-based model can achieve promising performance (e.g., 87.5\% AP50 at over 30 FPS on the ImageNet VID dataset on a single 2080Ti GPU), making it attractive for large-scale or real-time applications. The implementation is simple, the demo code and models have been made available at https://github.com/YuHengsss/YOLOV .
Fully Sparse 3D Object Detection
Jul 20, 2022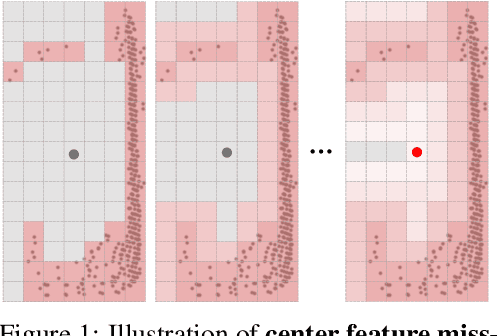
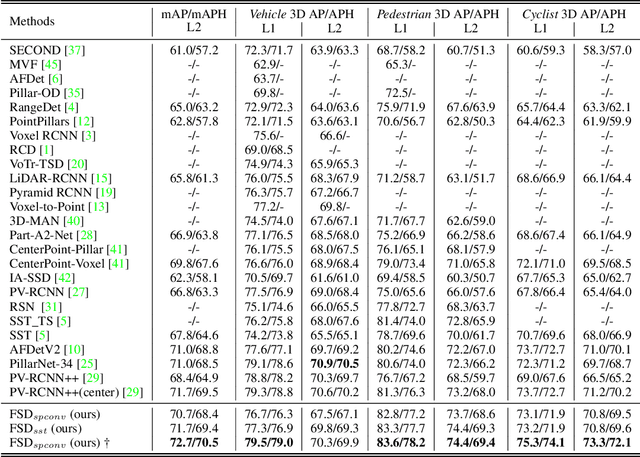
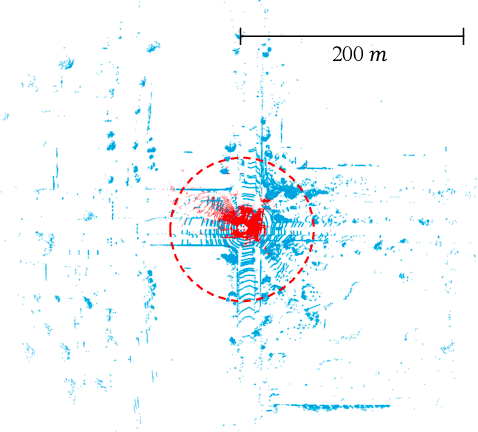
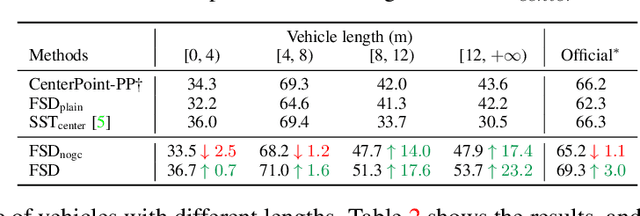
As the perception range of LiDAR increases, LiDAR-based 3D object detection becomes a dominant task in the long-range perception task of autonomous driving. The mainstream 3D object detectors usually build dense feature maps in the network backbone and prediction head. However, the computational and spatial costs on the dense feature map are quadratic to the perception range, which makes them hardly scale up to the long-range setting. To enable efficient long-range LiDAR-based object detection, we build a fully sparse 3D object detector (FSD). The computational and spatial cost of FSD is roughly linear to the number of points and independent of the perception range. FSD is built upon the general sparse voxel encoder and a novel sparse instance recognition (SIR) module. SIR first groups the points into instances and then applies instance-wise feature extraction and prediction. In this way, SIR resolves the issue of center feature missing, which hinders the design of the fully sparse architecture for all center-based or anchor-based detectors. Moreover, SIR avoids the time-consuming neighbor queries in previous point-based methods by grouping points into instances. We conduct extensive experiments on the large-scale Waymo Open Dataset to reveal the working mechanism of FSD, and state-of-the-art performance is reported. To demonstrate the superiority of FSD in long-range detection, we also conduct experiments on Argoverse 2 Dataset, which has a much larger perception range ($200m$) than Waymo Open Dataset ($75m$). On such a large perception range, FSD achieves state-of-the-art performance and is 2.4$\times$ faster than the dense counterpart.Codes will be released at https://github.com/TuSimple/SST.
GIFS: Neural Implicit Function for General Shape Representation
Apr 14, 2022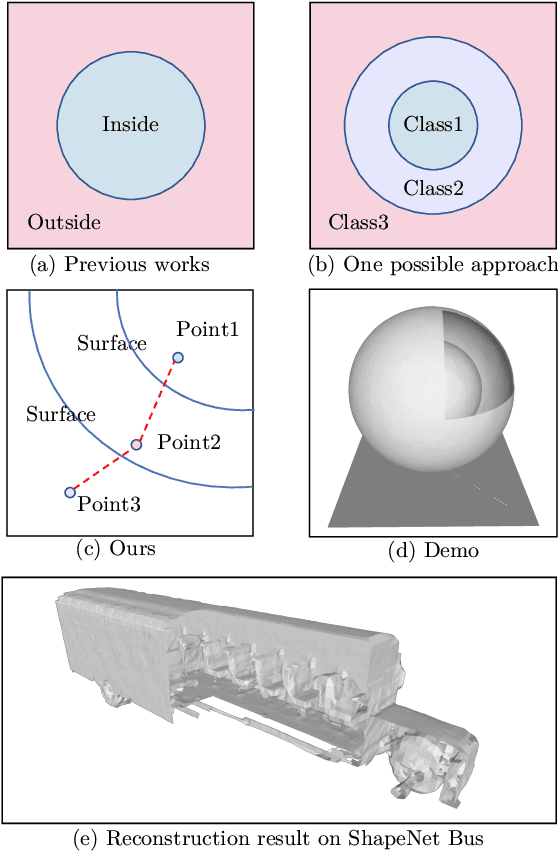
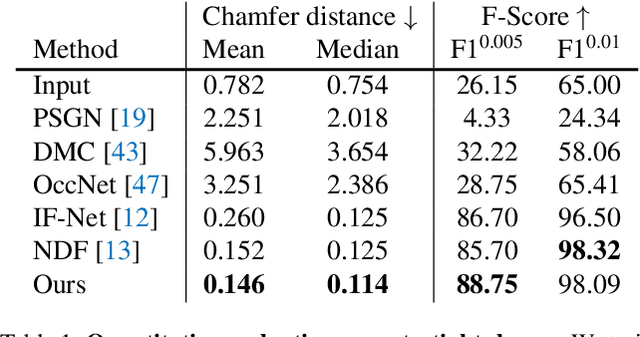
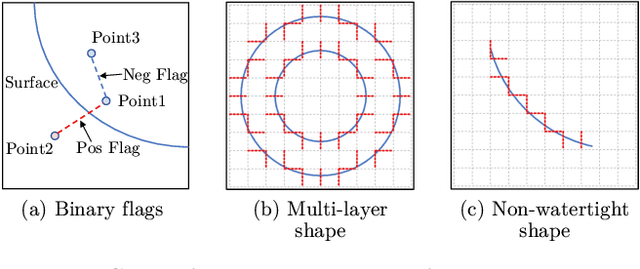
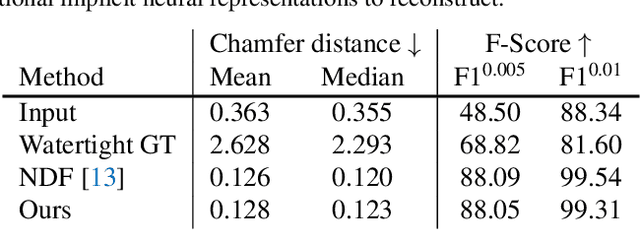
Recent development of neural implicit function has shown tremendous success on high-quality 3D shape reconstruction. However, most works divide the space into inside and outside of the shape, which limits their representing power to single-layer and watertight shapes. This limitation leads to tedious data processing (converting non-watertight raw data to watertight) as well as the incapability of representing general object shapes in the real world. In this work, we propose a novel method to represent general shapes including non-watertight shapes and shapes with multi-layer surfaces. We introduce General Implicit Function for 3D Shape (GIFS), which models the relationships between every two points instead of the relationships between points and surfaces. Instead of dividing 3D space into predefined inside-outside regions, GIFS encodes whether two points are separated by any surface. Experiments on ShapeNet show that GIFS outperforms previous state-of-the-art methods in terms of reconstruction quality, rendering efficiency, and visual fidelity. Project page is available at https://jianglongye.com/gifs .
Embracing Single Stride 3D Object Detector with Sparse Transformer
Dec 13, 2021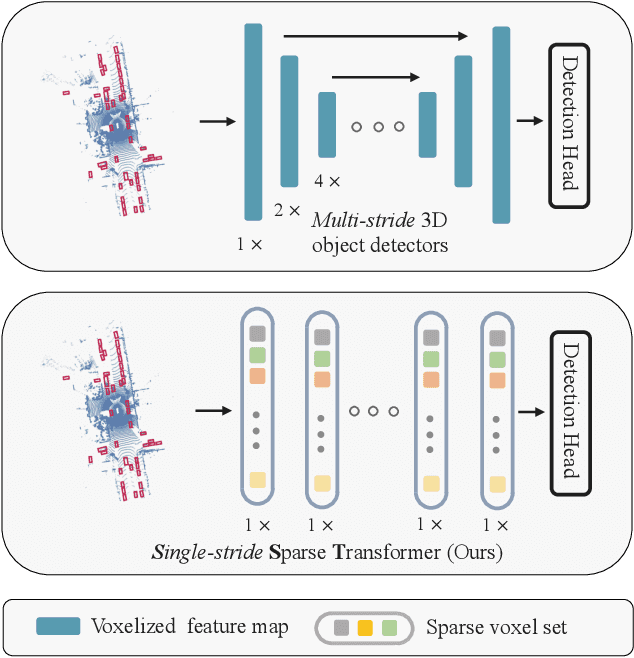
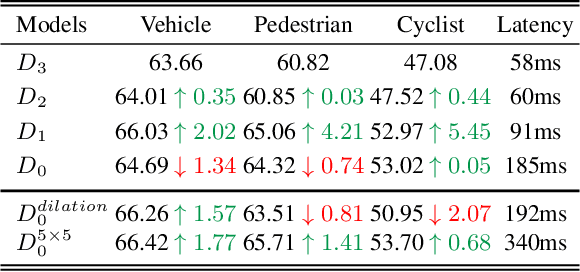
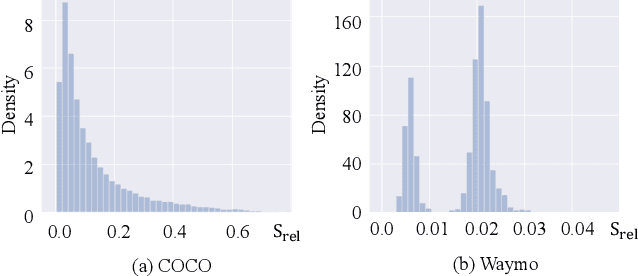
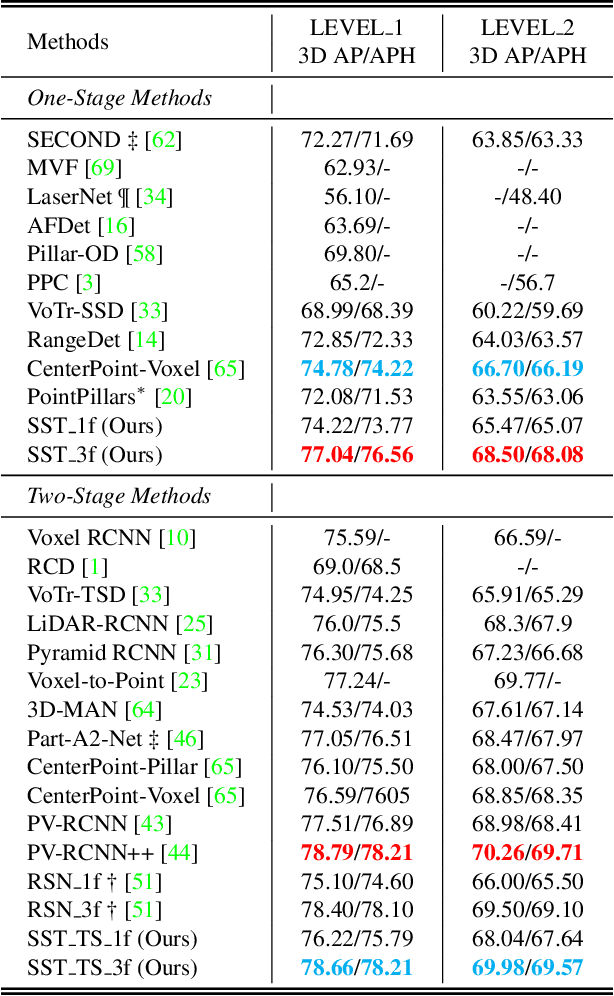
In LiDAR-based 3D object detection for autonomous driving, the ratio of the object size to input scene size is significantly smaller compared to 2D detection cases. Overlooking this difference, many 3D detectors directly follow the common practice of 2D detectors, which downsample the feature maps even after quantizing the point clouds. In this paper, we start by rethinking how such multi-stride stereotype affects the LiDAR-based 3D object detectors. Our experiments point out that the downsampling operations bring few advantages, and lead to inevitable information loss. To remedy this issue, we propose Single-stride Sparse Transformer (SST) to maintain the original resolution from the beginning to the end of the network. Armed with transformers, our method addresses the problem of insufficient receptive field in single-stride architectures. It also cooperates well with the sparsity of point clouds and naturally avoids expensive computation. Eventually, our SST achieves state-of-the-art results on the large scale Waymo Open Dataset. It is worth mentioning that our method can achieve exciting performance (83.8 LEVEL 1 AP on validation split) on small object (pedestrian) detection due to the characteristic of single stride. Codes will be released at https://github.com/TuSimple/SST
Immortal Tracker: Tracklet Never Dies
Nov 26, 2021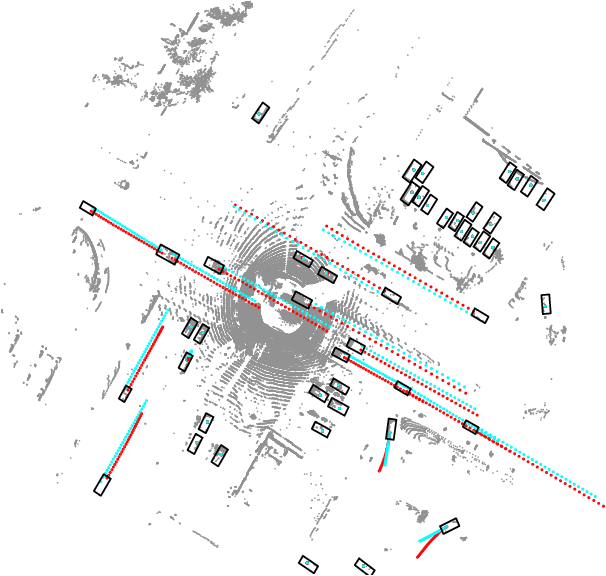

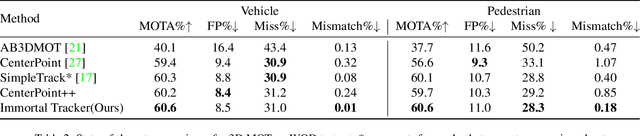
Previous online 3D Multi-Object Tracking(3DMOT) methods terminate a tracklet when it is not associated with new detections for a few frames. But if an object just goes dark, like being temporarily occluded by other objects or simply getting out of FOV, terminating a tracklet prematurely will result in an identity switch. We reveal that premature tracklet termination is the main cause of identity switches in modern 3DMOT systems. To address this, we propose Immortal Tracker, a simple tracking system that utilizes trajectory prediction to maintain tracklets for objects gone dark. We employ a simple Kalman filter for trajectory prediction and preserve the tracklet by prediction when the target is not visible. With this method, we can avoid 96% vehicle identity switches resulting from premature tracklet termination. Without any learned parameters, our method achieves a mismatch ratio at the 0.0001 level and competitive MOTA for the vehicle class on the Waymo Open Dataset test set. Our mismatch ratio is tens of times lower than any previously published method. Similar results are reported on nuScenes. We believe the proposed Immortal Tracker can offer a simple yet powerful solution for pushing the limit of 3DMOT. Our code is available at https://github.com/ImmortalTracker/ImmortalTracker.
Online Adaptation for Implicit Object Tracking and Shape Reconstruction in the Wild
Nov 24, 2021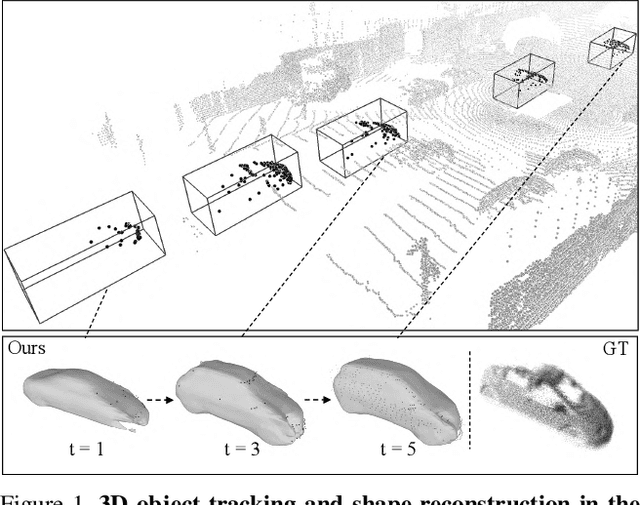
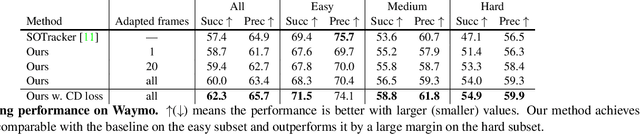
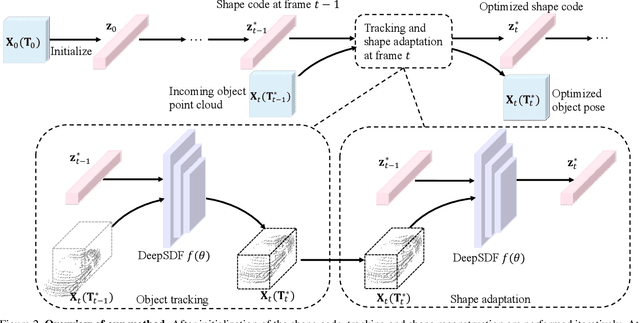
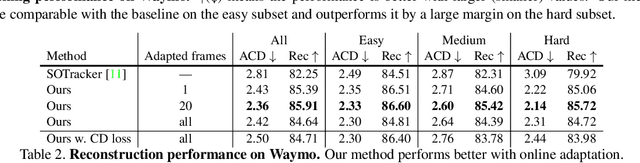
Tracking and reconstructing 3D objects from cluttered scenes are the key components for computer vision, robotics and autonomous driving systems. While recent progress in implicit function (e.g., DeepSDF) has shown encouraging results on high-quality 3D shape reconstruction, it is still very challenging to generalize to cluttered and partially observable LiDAR data. In this paper, we propose to leverage the continuity in video data. We introduce a novel and unified framework which utilizes a DeepSDF model to simultaneously track and reconstruct 3D objects in the wild. We online adapt the DeepSDF model in the video, iteratively improving the shape reconstruction while in return improving the tracking, and vice versa. We experiment with both Waymo and KITTI datasets, and show significant improvements over state-of-the-art methods for both tracking and shape reconstruction.
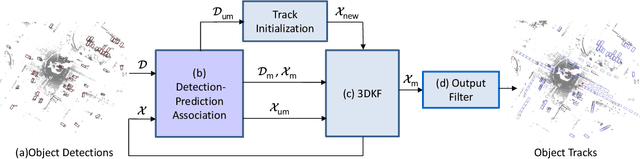
SimpleTrack: Understanding and Rethinking 3D Multi-object Tracking
Nov 18, 2021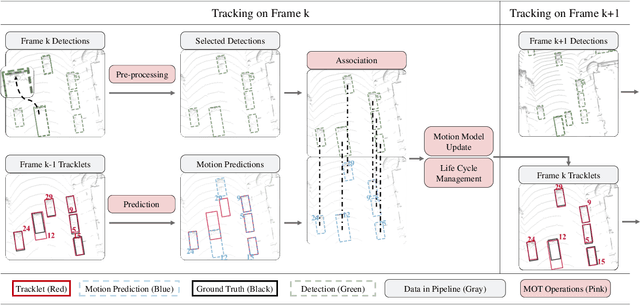
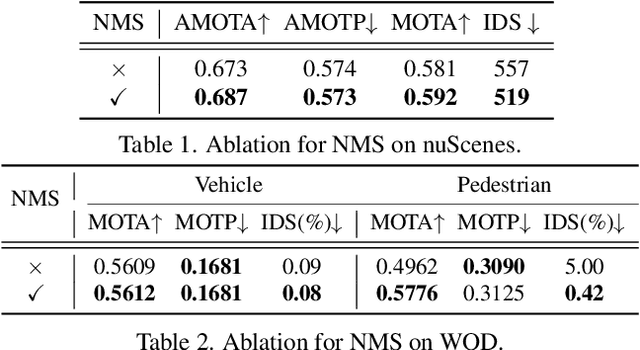
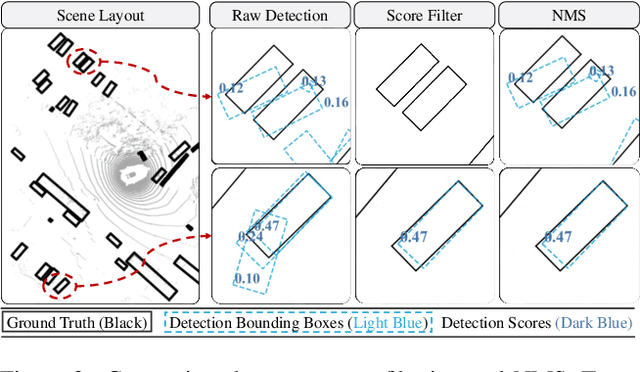
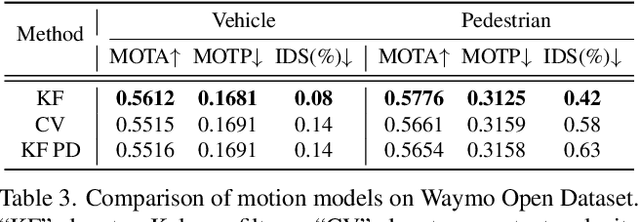
3D multi-object tracking (MOT) has witnessed numerous novel benchmarks and approaches in recent years, especially those under the "tracking-by-detection" paradigm. Despite their progress and usefulness, an in-depth analysis of their strengths and weaknesses is not yet available. In this paper, we summarize current 3D MOT methods into a unified framework by decomposing them into four constituent parts: pre-processing of detection, association, motion model, and life cycle management. We then ascribe the failure cases of existing algorithms to each component and investigate them in detail. Based on the analyses, we propose corresponding improvements which lead to a strong yet simple baseline: SimpleTrack. Comprehensive experimental results on Waymo Open Dataset and nuScenes demonstrate that our final method could achieve new state-of-the-art results with minor modifications. Furthermore, we take additional steps and rethink whether current benchmarks authentically reflect the ability of algorithms for real-world challenges. We delve into the details of existing benchmarks and find some intriguing facts. Finally, we analyze the distribution and causes of remaining failures in \name\ and propose future directions for 3D MOT. Our code is available at https://github.com/TuSimple/SimpleTrack.